介绍
数据集说明
此数据集包含与员工有关的综合属性集合,从人口统计细节到与工作相关的因素。该分析的主要目的是预测员工流动率并辨别导致员工流失的潜在因素。
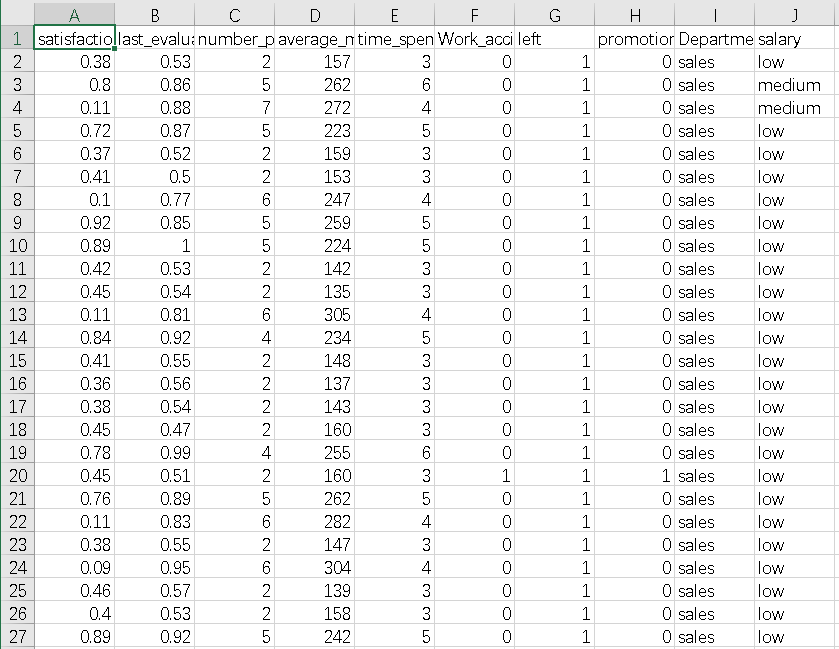
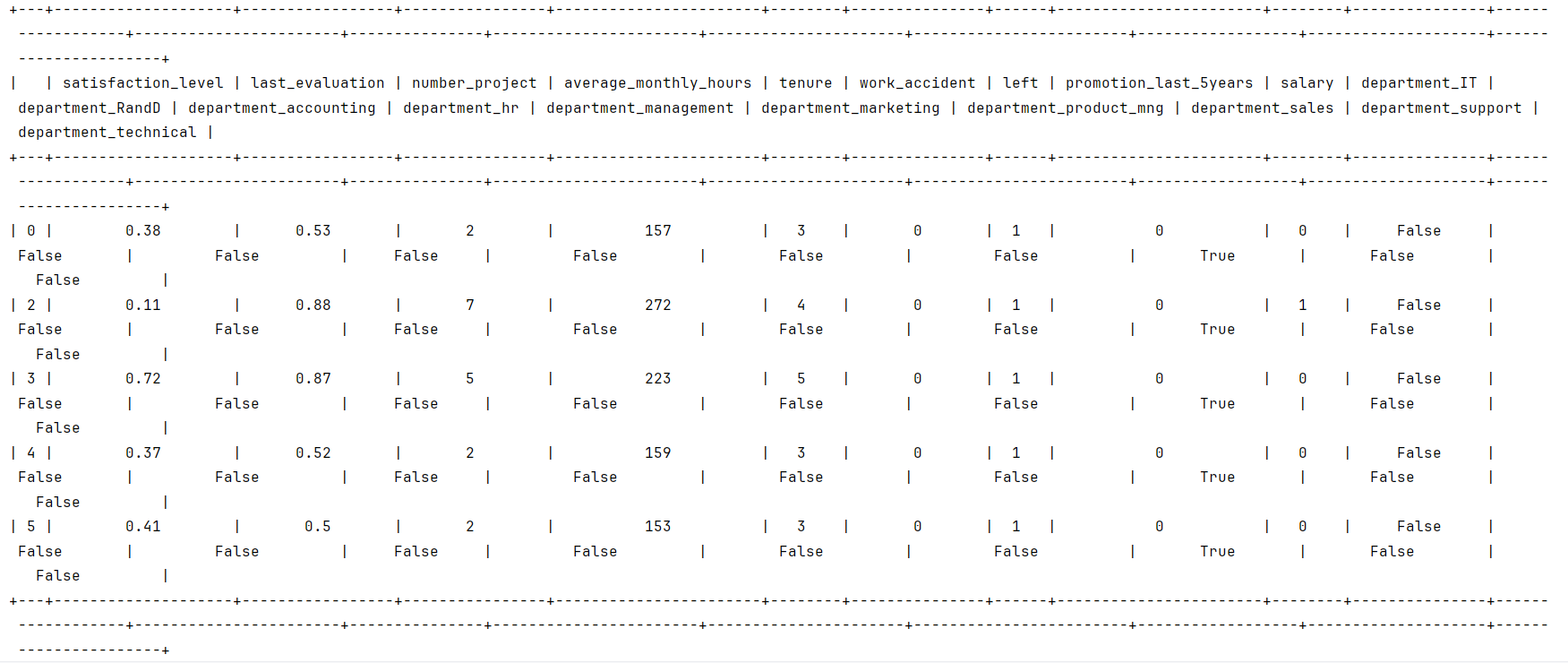
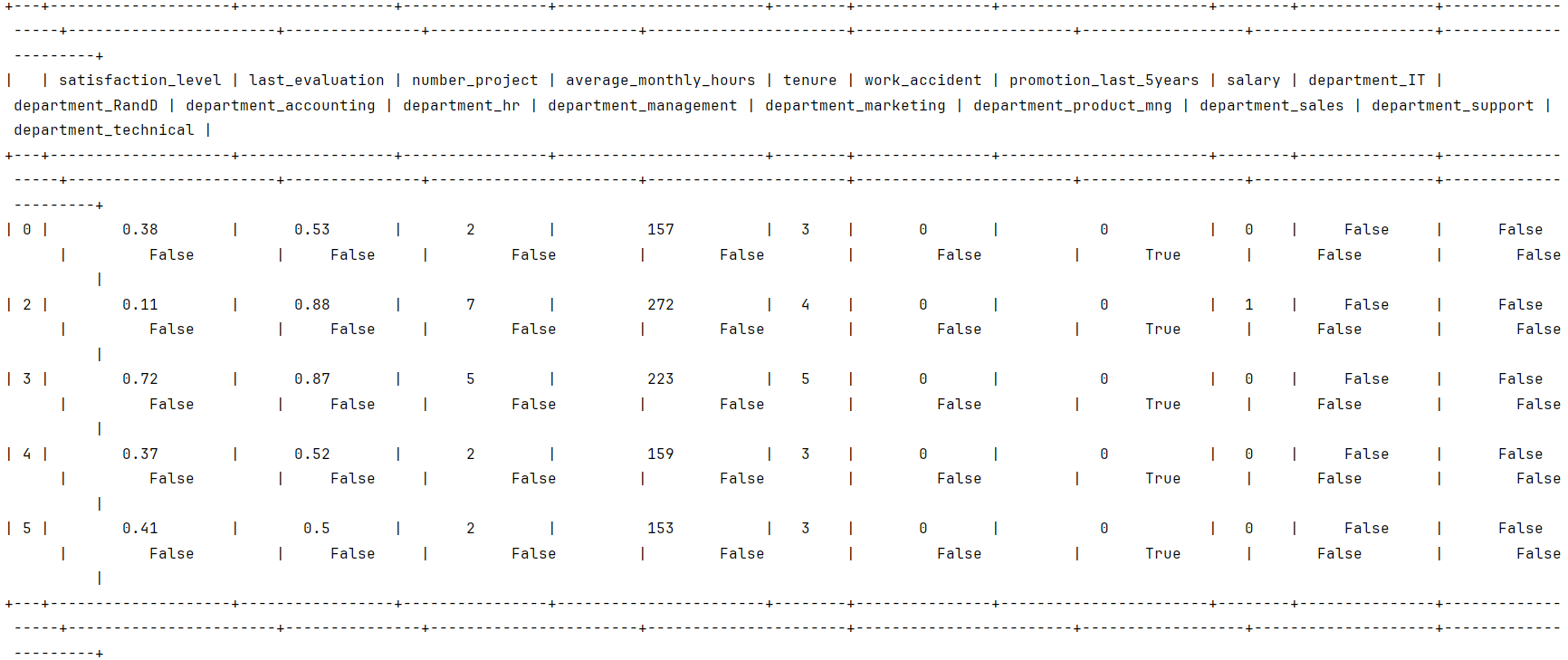
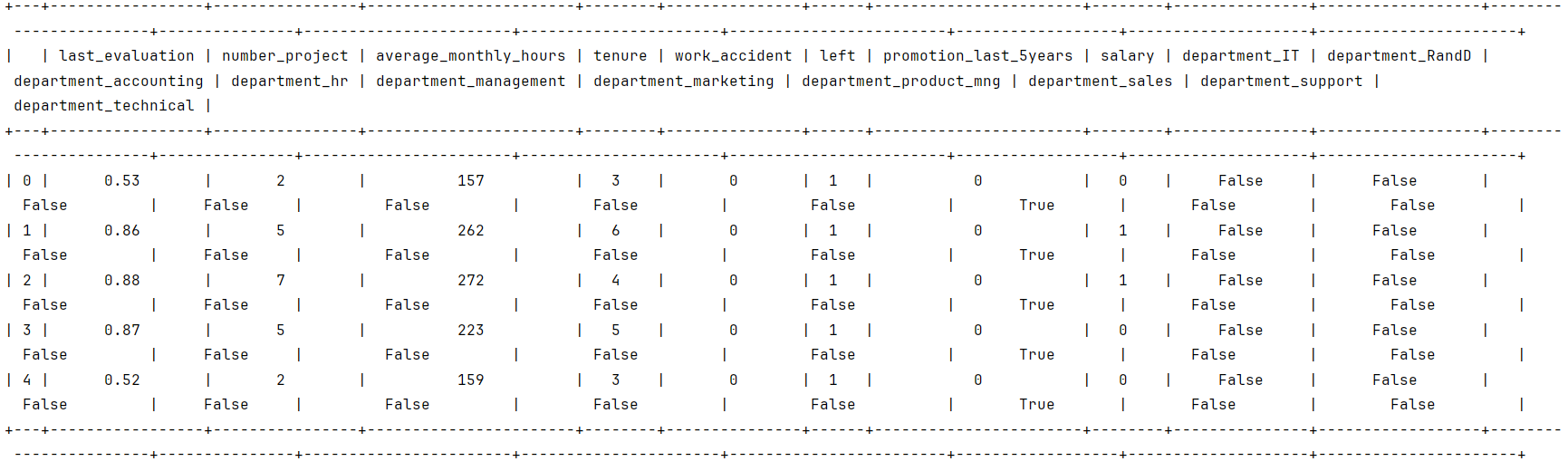
在这个数据集中,有14,999行,10列,以及这些变量:满意度、上次评估、项目数量、平均每月小时数、时间花费公司、工伤事故、最近 5 次促销、年、部门、工资。
| 变量 | 描述 |
|---|---|
| satisfaction_level | 员工报告的工作满意度[0-1] |
| last_evaluation | 员工最近一次绩效考核得分[0-1] |
| number_project | 员工参与的项目数量 |
| average_monthly_hours | 员工每月工作的平均小时数 |
| time_spend_company | 员工在公司工作时间(年) |
| Work_accident | 员工在工作中是否发生过事故 |
| left | 员工是否离开了公司 |
| promotion_last_5years | 员工在过去五年内是否获得过晋升 |
| Department | 员工部门 |
| salary | 员工工资(美元) |
数据预览
项目介绍
这个项目的主要目标是利用机器学习技术来预测员工流失。
最初,我采用了两种建模方法:逻辑回归(建模A)和基于树的模型(建模B)。在建模B中,我同时使用了决策树和随机森林。然而,考虑到建模B的高性能,我担心潜在的数据泄露,这可能导致夸大的分数。因此,我进行了特征工程,并在随后的一轮分析中完善了建模。
值得注意的是,我用类似教程的方法构建了这本笔记本,以确保初学者仍然可以访问和理解它。因此,我在过程的每个阶段都包含了详细的解释。
理解业务场景和问题
萨利福特汽车公司的人力资源部门想采取一些措施来提高公司员工的满意度。他们从员工那里收集数据,但现在他们不知道如何处理这些数据。他们将我们称为数据分析专家,并要求我们基于对数据的理解提供数据驱动的建议。他们有以下问题:什么可能会让员工离开公司?
在这个项目中,我们的目标是分析人力资源部门收集的数据,并建立一个模型来预测员工是否会离开公司。
如果我们能预测员工离职的可能性,就有可能找出导致他们离职的因素。因为寻找、面试和雇佣新员工既耗时又昂贵,所以增加员工保留率对公司是有益的。
导入包并加载数据集
导入包
# 用于数据操作
import numpy as np
import pandas as pd# 用于数据可视化
import matplotlib.pyplot as plt
import seaborn as sns
import tabulate as tabulate# 用于在数据框中显示所有列
pd.set_option('display.max_columns', None)# 用于数据建模
from xgboost import XGBClassifier
from xgboost import XGBRegressor
from xgboost import plot_importancefrom sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier# 用于度量和其它的功能
from sklearn.model_selection import GridSearchCV, train_test_split
from sklearn.metrics import accuracy_score, precision_score, recall_score,\
f1_score, confusion_matrix, ConfusionMatrixDisplay, classification_report
from sklearn.metrics import roc_auc_score, roc_curve
from sklearn.tree import plot_tree
加载数据集
python"># 加载数据集
df0 = pd.read_csv("./data/HR_capstone_dataset.csv")
显示数据
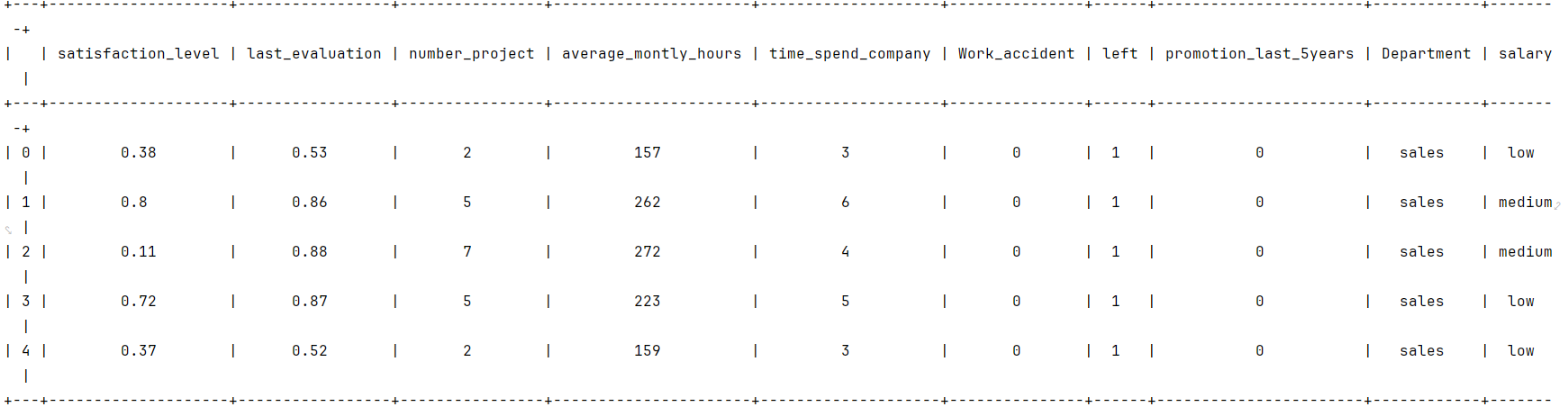
python"># 显示数据框的前几行
df0.head()
数据探索(初始EDA和数据清理)
- 理解变量
- 清理数据集(缺失数据、冗余数据、异常值)
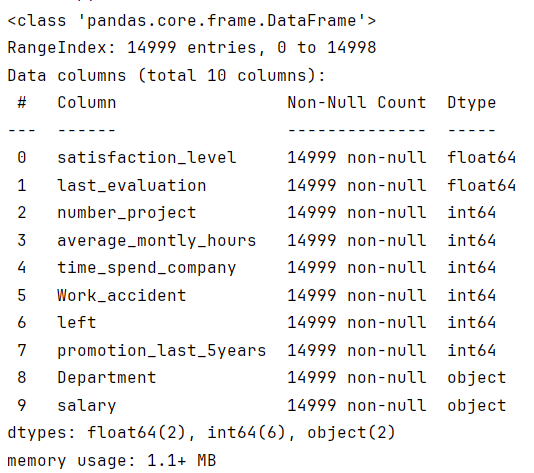
收集数据的基本信息
python"># 数据的基本信息
df0.info()
收集有关数据的描述性统计信息
python"># 关于数据的描述性统计
df0.describe()
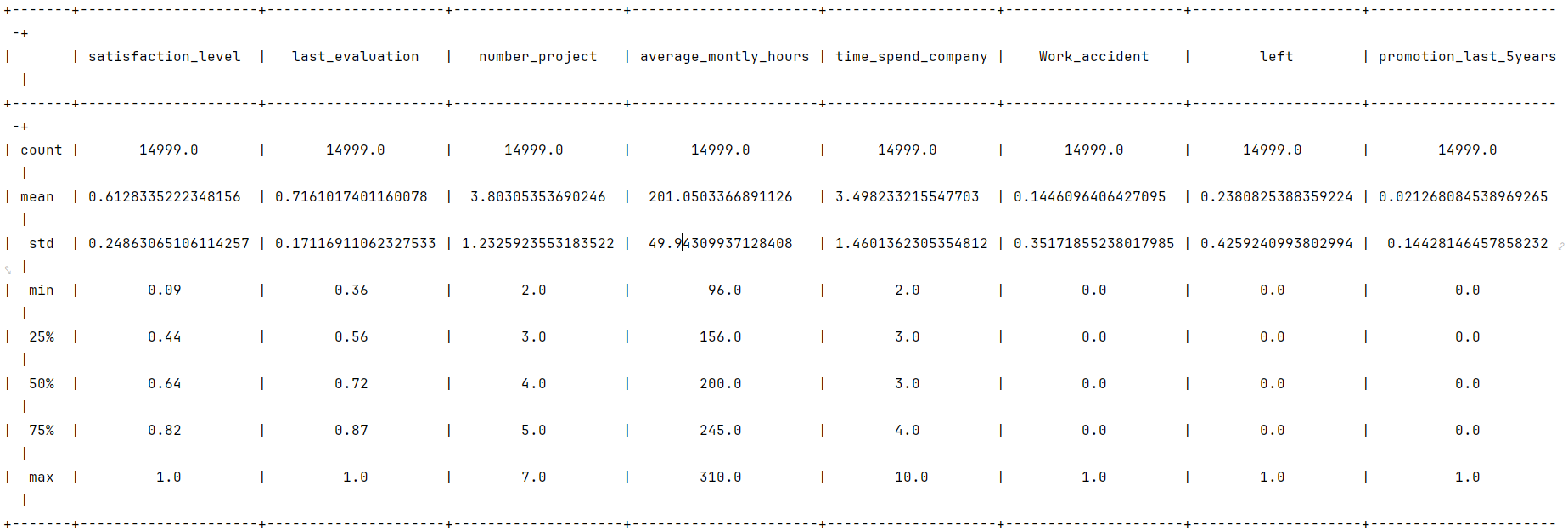
重命名列
python"># 显示所有列名
df0.columns

python"># 根据需要重命名列
df0 = df0.rename(columns={'Work_accident': 'work_accident','average_montly_hours': 'average_monthly_hours','time_spend_company': 'tenure','Department': 'department'})
df0.columns

检查缺失值
python"># 检查缺失值
df0.isna().sum()
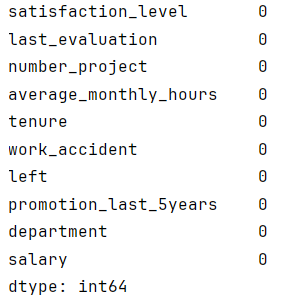
数据中没有缺失值。
检查重复
python">df0.duplicated().sum()
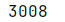
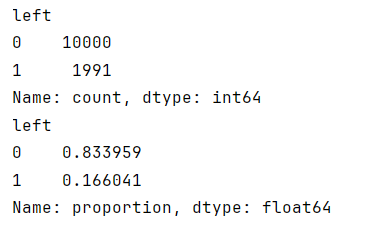
3008行包含重复项,这是20%的数据。
python"># 根据需要检查一些包含重复项的行
df0[df0.duplicated()].head()

python"># 删除重复项并根据需要将结果数据框保存在一个新变量中
df1 = df0.drop_duplicates(keep='first')# 根据需要显示新数据框的前几行
df1.head()
 检查离群值
检查离群值
python">plt.figure(figsize=(6,6))
plt.title('Boxplot to detect outliers for tenure', fontsize=12)
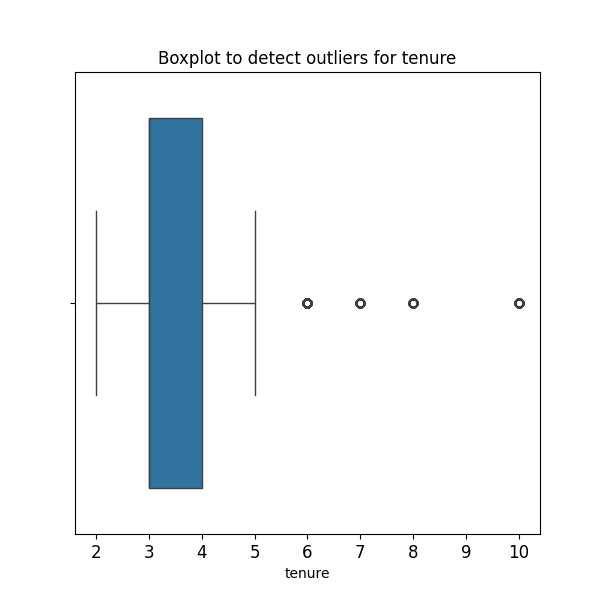
上面的箱线图显示,在任期变量中存在异常值。
调查数据中有多少行包含保留期列中的离群值将会很有帮助。
python"># 确定包含异常值的行数# 计算“任期”的第25个百分位数
percentile25 = df1['tenure'].quantile(0.25)# 计算“任期”的第75个百分位数
percentile75 = df1['tenure'].quantile(0.75)# 计算“任期”的四分位数范围
iqr = percentile75 - percentile25# 定义' 任期 '中非离群值的上限和下限
upper_limit = percentile75 + 1.5 * iqr
lower_limit = percentile25 - 1.5 * iqr
print("Lower limit:", lower_limit)
print("Upper limit:", upper_limit)# 确定在“任期”中包含异常值的数据子集
outliers = df1[(df1['tenure'] > upper_limit) | (df1['tenure'] < lower_limit)]# 计算数据中有多少行包含“任期”中的异常值
print("Number of rows in the data containing outliers in `tenure`:", len(outliers))

现在开始了解有多少员工离职,以及这个数字占所有员工的百分比。
python"># 得到离开和留下来的人数
print(df1['left'].value_counts())# 得到离开和留下来的人的百分比
print(df1['left'].value_counts(normalize=True))
数据可视化
根据项目比较留下来的员工和离开的员工
python"># 根据需要创建一个绘图
# 设置图形和轴
fig, ax = plt.subplots(1, 2, figsize = (22,8))# 创建一个箱形图,显示“项目”的“月平均工作时间”分布,比较留下来的员工和离开的员工
sns.boxplot(data=df1, x='average_monthly_hours', y='number_project', hue='left', orient="h", ax=ax[0])
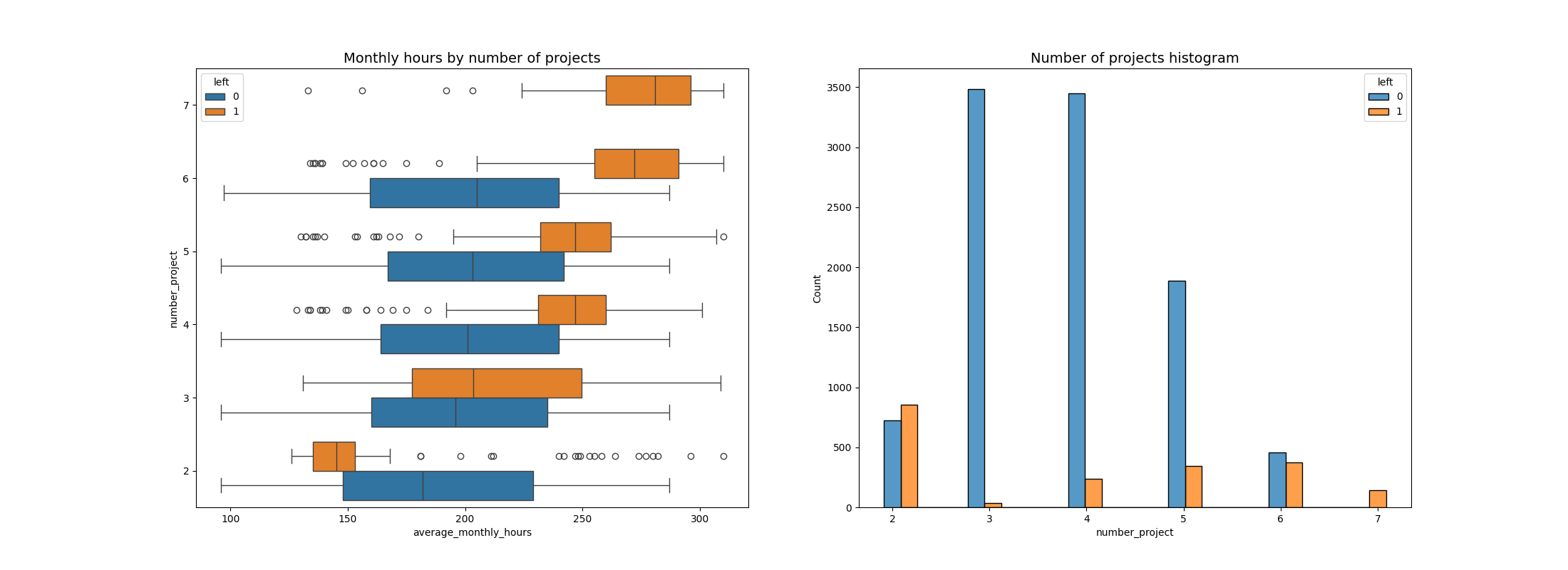
有两组员工离开了公司:(A)那些工作时间比同样数量项目的同事少得多的人,(B)那些工作时间多得多的人。A组的人,有可能是被解雇的。也有可能这个群体包括那些已经辞职的员工,他们被分配的工作时间更少,因为他们已经准备离开了。对于B组的人来说,我们有理由推断他们可能会戒烟。B组的人可能对他们所从事的项目贡献很大;他们可能是他们项目的最大贡献者。
每个拥有7个项目的人都离开了公司,这一组和那些拥有6个项目的人的四分位数范围是每月255-295个小时——比其他任何一组都要多。
员工的最佳项目数量似乎是3-4个。在这些队列中,离开/留下的比例非常小。
如果我们假设每周工作40小时,每年有两周的假期,那么周一到周五工作的员工每月的平均工作时数= 50周*每周40小时/ 12个月=每月166.67小时。这意味着,除了参与两个项目的员工之外,每个小组——甚至那些没有离开公司的人——的工作时间都比这要长得多。看来这里的员工都工作过度了。
python"># 获得7个项目的员工的停留/离开的价值计数
df1[df1['number_project']==7]['left'].value_counts
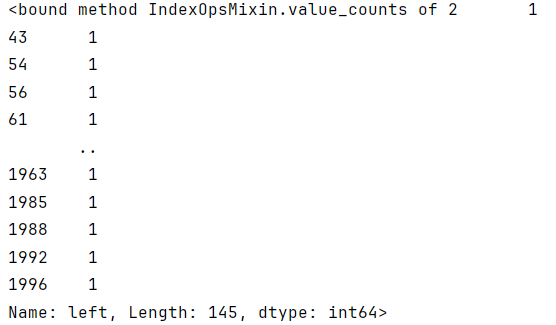
这证实了7个项目的所有员工都离开了。
平均每月工作时间和满意度
现在让我们来看看平均每月工作时间和满意度。
python"># 创建“平均月工作时间”和“满意度”的散点图,比较留下的员工和离开的员工
plt.figure(figsize=(16, 9))
sns.scatterplot(data=df1, x='average_monthly_hours', y='satisfaction_level', hue='left', alpha=0.4)
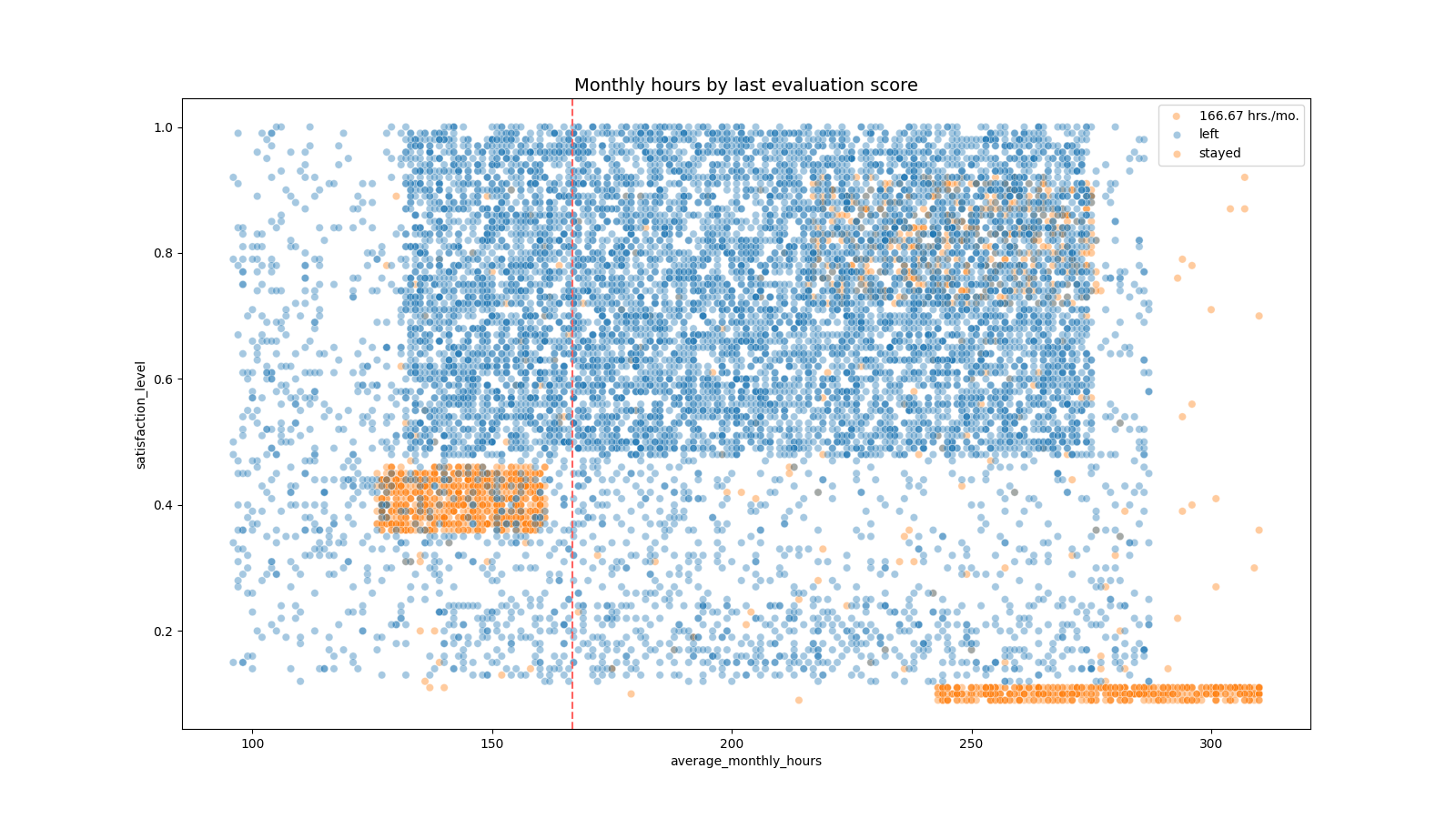
上面的散点图显示,有相当多的员工每月工作240-315小时。每月315小时,一年下来每周超过75小时。这可能与他们的满意度接近于零有关。
该图还显示了另一组离开的人,他们有更多的正常工作时间。即便如此,他们的满意度也只有0.4左右。很难推测他们离开的原因。考虑到许多同龄人的工作时间比他们长,他们可能会感到压力。这种压力可能会降低他们的满意度。
最后,有一组人每月工作210-280小时,他们的满意度在0.7-0.9之间。
根据任期比较留下来的员工和离开的员工
python"># 设置图形和轴
fig, ax = plt.subplots(1, 2, figsize = (22,8))# 创建一个箱形图,显示按任期划分的“满意度”分布,比较留下来的员工和离开的员工
sns.boxplot(data=df1, x='satisfaction_level', y='tenure', hue='left', orient="h", ax=ax[0])
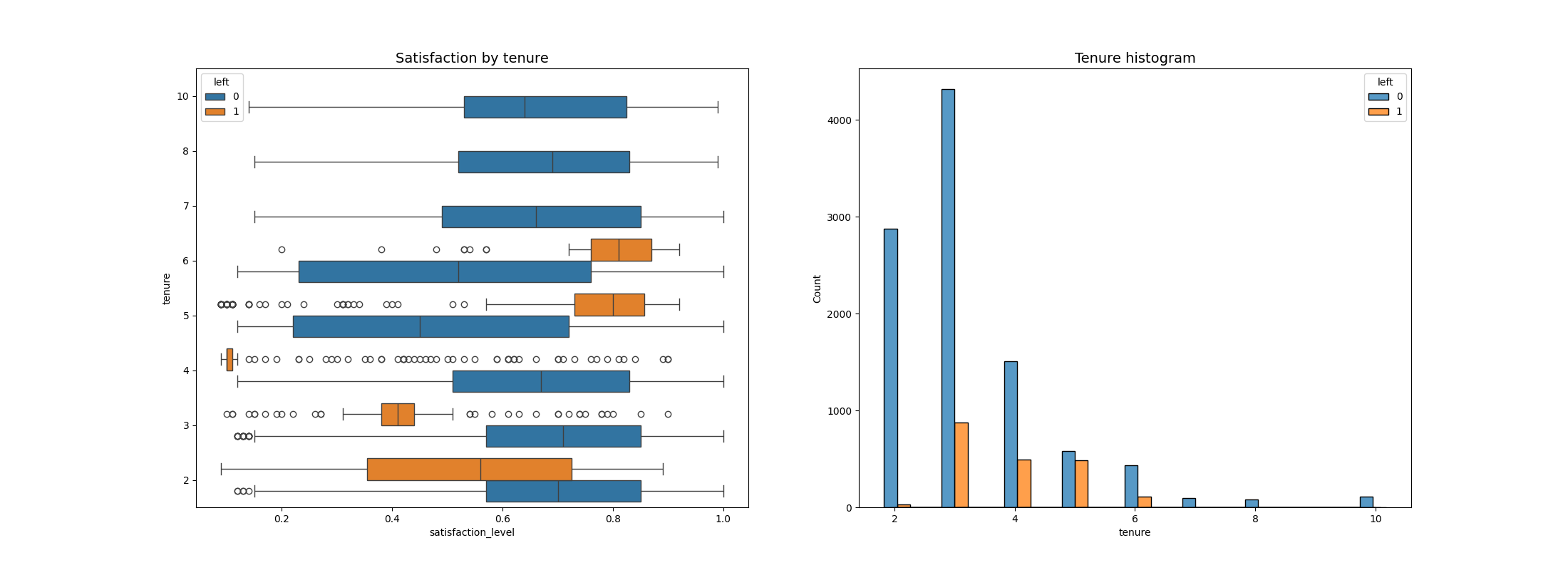
从这张图中我们可以得出许多观察结果。
离职的员工一般分为两类:任期较短的不满意员工和任期较长的非常满意员工。
离职四年的员工满意度似乎异常低。如果可能的话,我们有必要调查一下公司政策的变化,看看这些变化是否会特别影响到4岁以下的员工。
任职时间最长的员工没有离职。他们的满意度与留下来的新员工一致。
直方图显示,长期雇员相对较少。有可能他们是职位更高、收入更高的员工。
计算离职和留任员工满意度的平均值和中位数
python"># 计算离职和留任员工满意度的平均值和中位数
df1.groupby(['left'])['satisfaction_level'].agg(['mean', 'median'])

正如预期的那样,离职员工的满意度均值和中位数得分低于留下来的员工。有趣的是,在留下来的员工中,平均满意度得分似乎略低于中位数。这表明那些留下来的人的满意度可能会向左转。
python"># 设置图形和轴
fig, ax = plt.subplots(1, 2, figsize = (22,8))# 定义短期雇员
tenure_short = df1[df1['tenure'] < 7]
# 定义长期雇员
tenure_long = df1[df1['tenure'] > 6]# 绘制短期直方图# 绘制长期柱状图
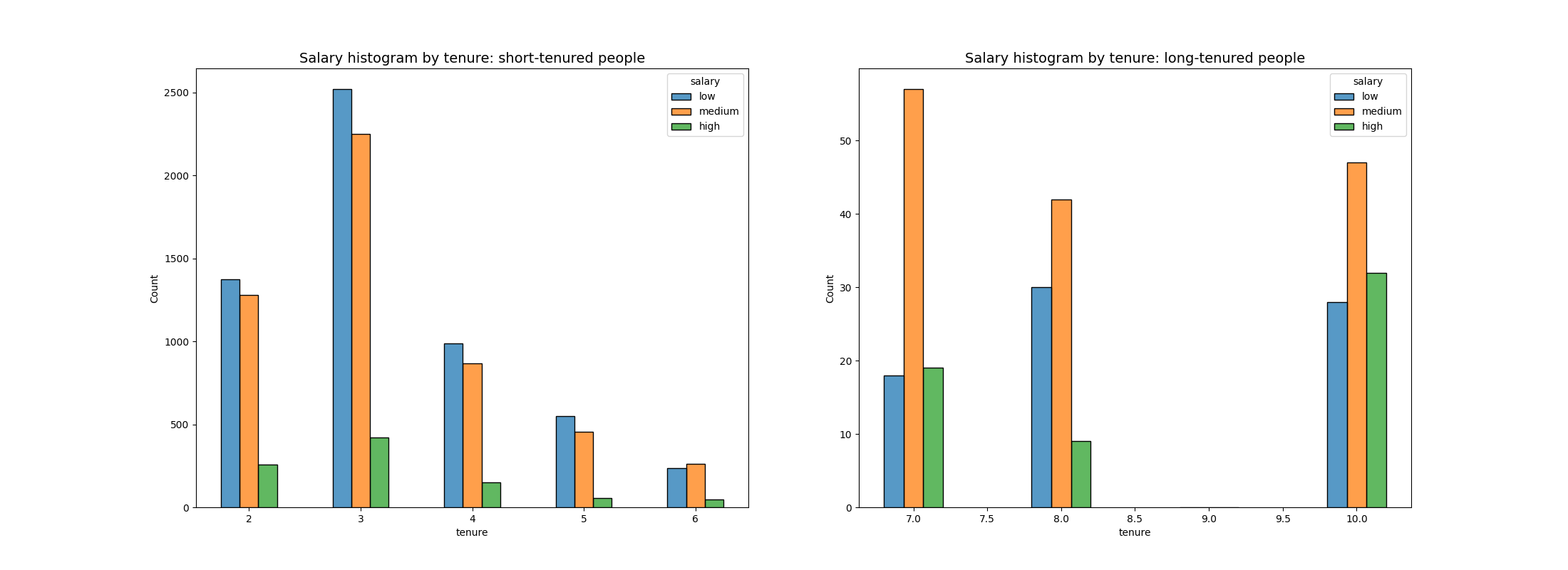
上面的图表显示,长期任职的员工中,高薪员工的比例并不高。
月平均工作时间和上次评估
python"># 创建“月平均工作时间”与“上次评估”的散点图
plt.figure(figsize=(16, 9))
sns.scatterplot(data=df1, x='average_monthly_hours', y='last_evaluation', hue='left', alpha=0.4)
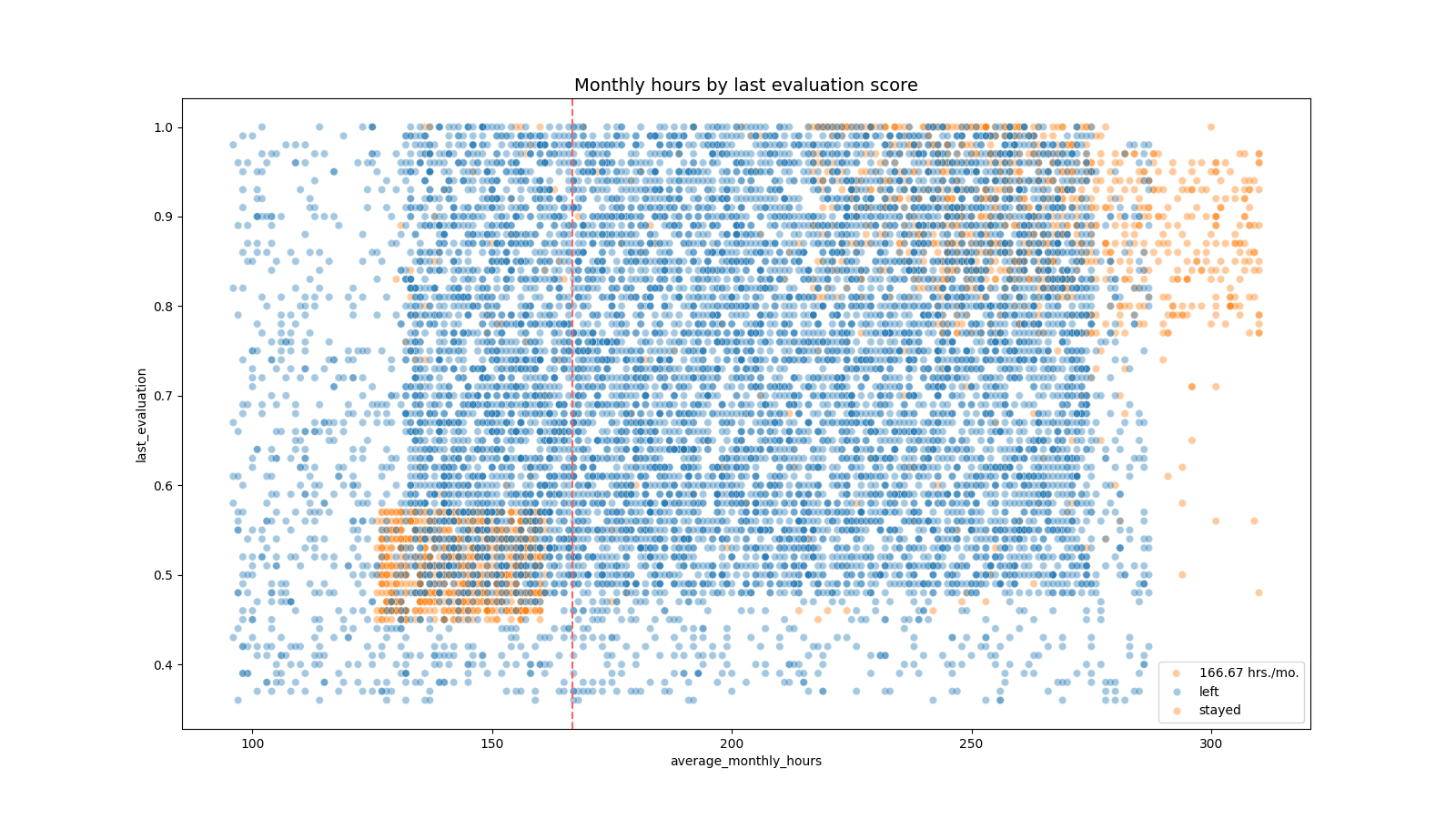
从上面的散点图可以观察到:
散点图显示了两组离职的员工:一组工作时间过长的员工,他们的工作表现非常好;另一组员工的工作时间略低于名义月平均166.67小时,评估得分较低。
工作时间和评估分数之间似乎存在相关性。
左上象限的员工比例并不高;但是长时间工作并不能保证一个好的评估分数。
这家公司的大多数员工每月工作超过167个小时。
平均月工作时间和最近5年的晋升之间的关系
python"># 创建图表来检验“平均月工作时间”和“最近5年的晋升”之间的关系
plt.figure(figsize=(16, 3))
sns.scatterplot(data=df1, x='average_monthly_hours', y='promotion_last_5years', hue='left', alpha=0.4)

上图显示了以下内容:在过去五年中得到提升的员工很少离开,很少有工作时间最长的员工得到晋升,所有离职的员工都是工作时间最长的。
根据部门比较留下来的员工和离开的员工
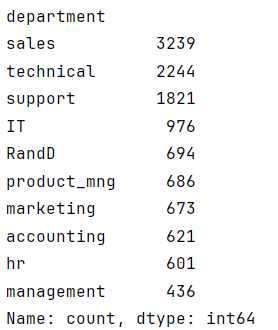
显示每个部门的计数
python"># 显示每个部门的计数
df1["department"].value_counts()
python"># 创建堆叠直方图,比较离职员工和未离职员工的部门分布
plt.figure(figsize=(11,8))
sns.histplot(data=df1, x='department', hue='left', discrete=1,hue_order=[0, 1], multiple='dodge', shrink=.5)
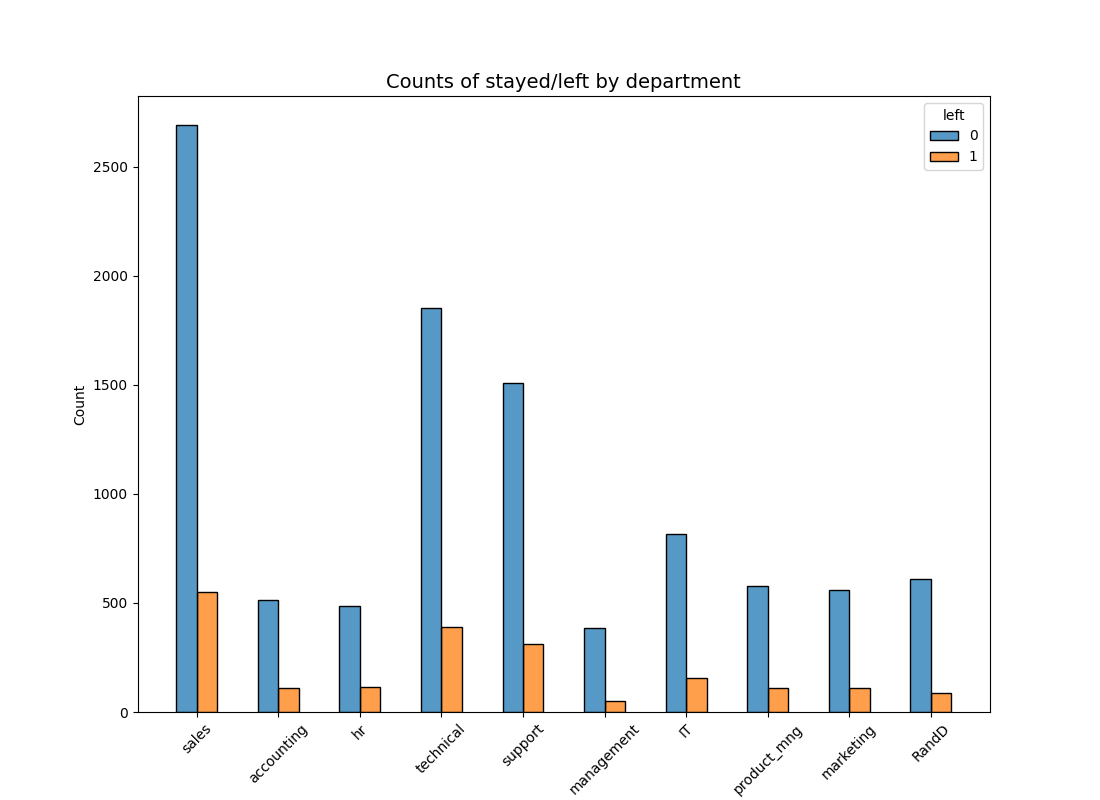
似乎没有哪个部门的员工离职率和留职率有显著差异。
项目数、月工作时间、考核分数三者关系
python"># 绘制相关热图
numeric_columns = df1.select_dtypes(include=['float64', 'int64']).columns
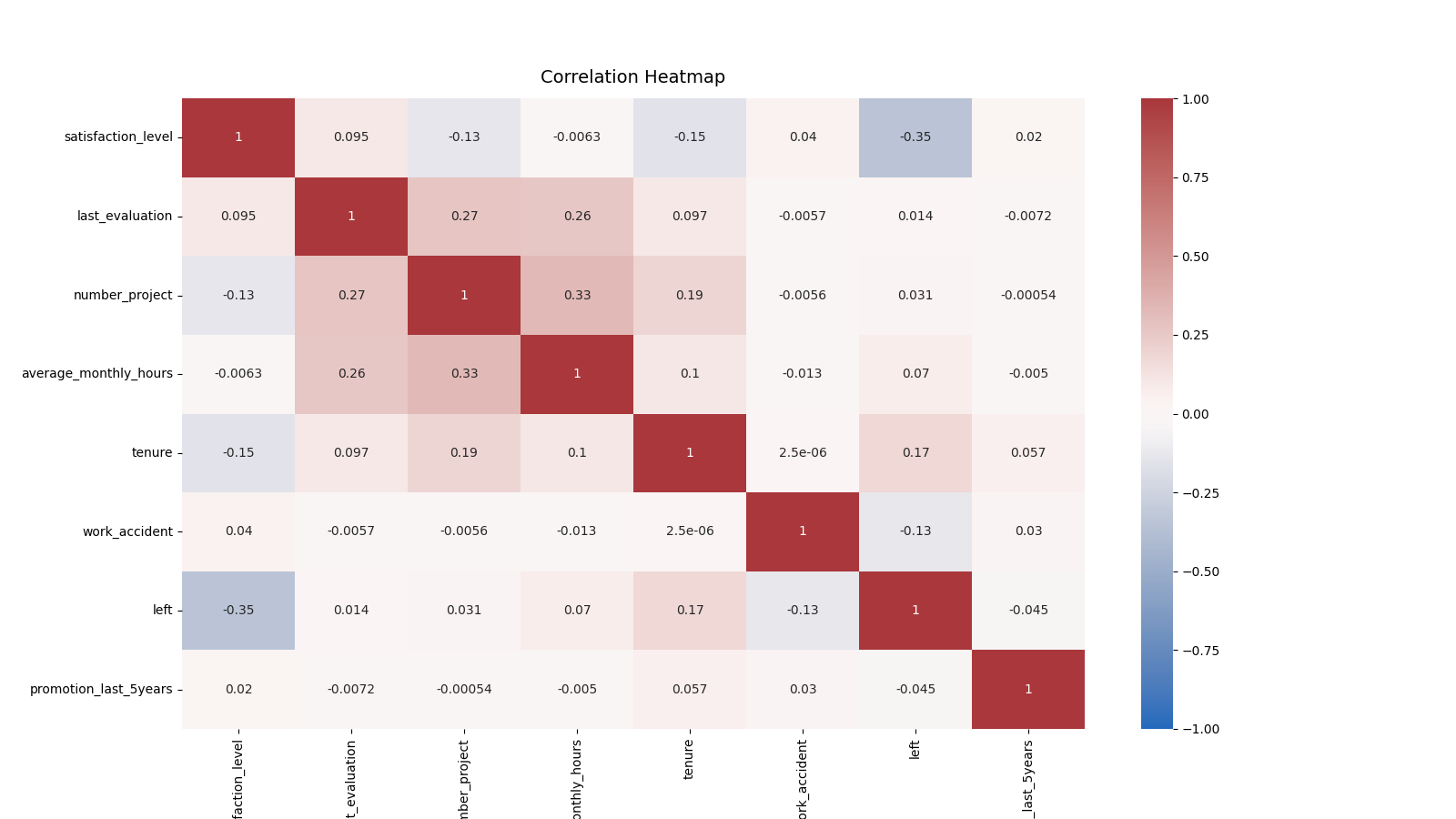
相关热图证实了项目数、月工作时间、考核分数三者之间存在一定的正相关关系,员工是否离职与员工满意度呈负相关关系。
关键的见解
看来由于管理不善,员工正在离开公司。离职与较长的工作时间、许多项目以及较低的满意度有关。长时间工作却得不到晋升或良好的评估分数是令人不满意的。这家公司有相当多的员工可能已经筋疲力尽了。此外,如果一名员工在公司工作了六年以上,他们往往不会离开。
建立模型
拟合使用两个或多个独立变量预测结果变量的模型
检查模型假设
评估模型
确定预测任务的类型
我们的目标是预测员工是否离开公司,这是一个分类结果变量。这个任务涉及到分类。更具体地说,这涉及到二元分类,因为结果变量left可以是1(表示员工离开)或0(表示员工没有离开)。
确定最适合此任务的模型类型
由于我们想要预测的变量(员工是否离开公司)是分类的,我们可以构建一个逻辑回归模型,或者一个基于树的机器学习模型。
因此,我们可以采用以下两种方法之一。或者,如果我们愿意,我们可以实现两者并确定它们如何比较。
建模方法A: Logistic回归模型
逻辑回归
请注意,二项逻辑回归适合这个任务,因为它涉及到二元分类。
在拆分数据之前,我们对非数字变量进行编码。有两个:部门和工资。
部门是一个分类变量,这意味着我们可以对它进行模拟。
薪水也是绝对的,但也是顺序的。类别有一个层次结构,所以最好不要设置这个列,而是将级别转换为数字,0-2。
python"># 复制数据
df_enc = df1.copy()# 将“工资”列编码为有序数字类别
df_enc['salary'] = (df_enc['salary'].astype('category').cat.set_categories(['low', 'medium', 'high']).cat.codes
)

数据集的热图
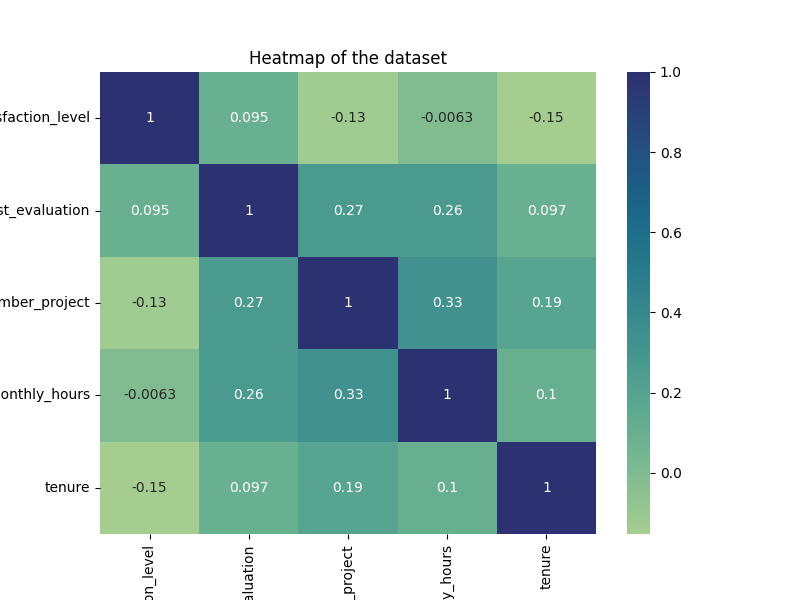
python"># 创建一个热图来可视化变量的相关程度
plt.figure(figsize=(8, 6))
sns.heatmap(df_enc[['satisfaction_level', 'last_evaluation', 'number_project', 'average_monthly_hours', 'tenure']].corr(), annot=True, cmap="crest")
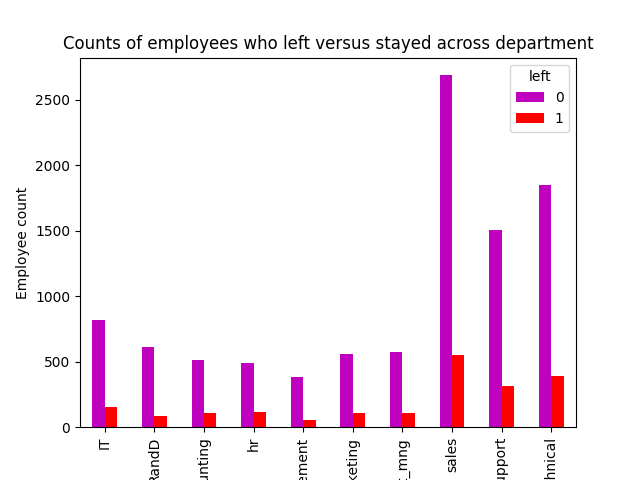
各部门离职和留职员工的数量
python"># 创建一个堆叠图来可视化整个部门的员工数量,比较那些离开和没有离开的员工
# 图例中,0(紫色)代表没有离职的员工,1(红色)代表离职的员工
pd.crosstab(df1['department'], df1['left']).plot(kind ='bar',color='mr')
plt.title('Counts of employees who left versus stayed across department')
考虑到逻辑回归如何受到异常值的影响,现在最好删除我们在之前的任期专栏中发现的异常值。
python"># 选择保留期中没有离群值的行,并将结果数据框保存在一个新变量中
df_logreg = df_enc[(df_enc['tenure'] >= lower_limit) & (df_enc['tenure'] <= upper_limit)]# 显示新数据的前几行
df_logreg.head()
分离结果变量,也就是我们希望模型预测的变量。
python"># 隔离结果变量
y = df_logreg['left']# 显示结果变量的前几行
y.head()

选择我们想要在模型中使用的特征。考虑一下哪些变量可以帮助我们预测结果变量,左边。
python"># 选择您想要在模型中使用的特性
X = df_logreg.drop('left', axis=1)# 显示所选特性的前几行
X.head()
将数据分为训练集和测试集。
python"># 将数据分成训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, stratify=y, random_state=42)
构造逻辑回归模型并拟合到训练数据集。
python"># 构建逻辑回归模型并拟合到训练数据集
log_clf = LogisticRegression(random_state=42, max_iter=500).fit(X_train, y_train)
检验逻辑回归模型:利用模型对测试集进行预测。
python"># 使用逻辑回归模型对测试集进行预测
y_pred = log_clf.predict(X_test)
创建混淆矩阵以可视化逻辑回归模型的结果。
python"># 计算混淆矩阵的值
log_cm = confusion_matrix(y_test, y_pred, labels=log_clf.classes_)
# 创建混淆矩阵的显示# 情节混淆矩阵
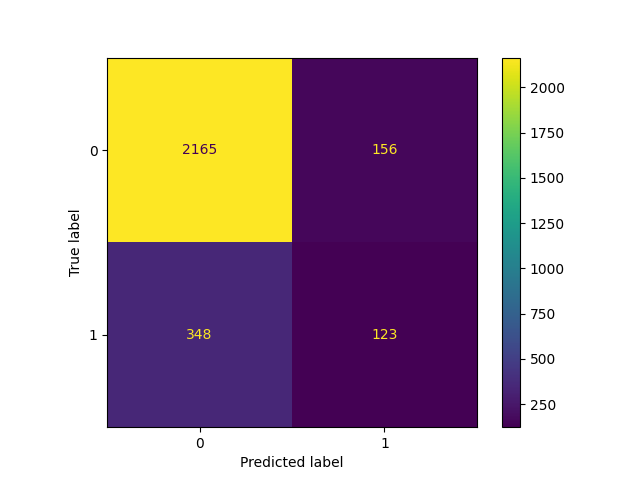
说明:
- 左上象限显示真阴性的数量。
- 右上象限显示误报的数量。
- 左下象限显示假阴性的数量。
- 右下象限显示真阳性的数量。
**真否定:**模型准确预测的没有离开的人数没有离开。
**误报:**没有离开模型的人数被错误地预测为离开。
**假阴性:**模型预测不准确的离开人数没有离开
**真正的积极因素:**离开模型的人数被准确地预测为离开
一个完美的模型会产生所有真阴性和真阳性,没有假阴性或假阳性。
现在,我们创建一个分类报告,其中包括精度、召回率、f1-score和准确性指标,以评估逻辑回归模型的性能。需要检查数据中的类平衡。换句话说,检查左列中的值计数。由于这是一个二元分类任务,类平衡告诉我们如何解释准确性指标。
python">df_logreg['left'].value_counts(normalize=True)
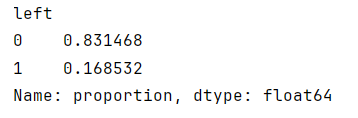
大约有83%-17%的分歧。所以数据不是完全平衡的,但也不是太不平衡。如果失衡更严重,我们可能需要重新采样数据以使其更加平衡。在这种情况下,我们可以在不修改类平衡的情况下使用这些数据并继续评估模型。
python"># 为逻辑回归模型创建分类报告
target_names = ['Predicted would not leave', 'Predicted would leave']
print(classification_report(y_test, y_pred, target_names=target_names))
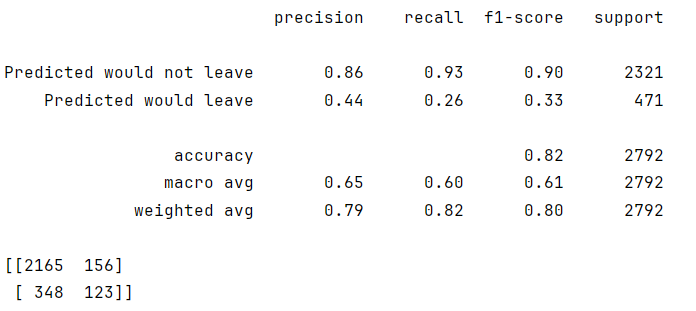
上面的分类报告显示,逻辑回归模型的准确率为79%,召回率为82%,f1得分为80%(所有加权平均值),准确率为82%。然而,如果预测员工离职是最重要的,那么得分就会明显降低。
建模方法B:基于树的模型
该方法涵盖了决策树和随机森林的实现。
数据处理
隔离结果变量
python"># 隔离结果变量
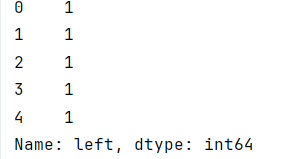
y = df_enc['left']
# 显示“y”的前几行
y.head()
print(y.head())
选择特性
python"># 选择特性
X = df_enc.drop('left', axis=1)
# 显示“X”的前几行
X.head()
将数据分成训练集、验证集和测试集
python"># 拆分数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, stratify=y, random_state=0)
决策树-第1轮
我们构建了一个决策树模型,并建立了交叉验证的网格搜索来穷举搜索最佳模型参数。
python"># 实例化模型
tree = DecisionTreeClassifier(random_state=0)
# 指定一个要搜索的超参数字典
cv_params = {'max_depth':[4, 6, 8, None],'min_samples_leaf': [2, 5, 1],'min_samples_split': [2, 4, 6]}
# 分配要捕获的评分指标的字典# 实例化GridSearch
将决策树模型拟合到训练数据中
python">tree1.fit(X_train, y_train)
确定决策树参数的最优值
python"># 检查最佳参数
tree1.best_params_

识别决策树模型在训练集上获得的最佳AUC分数
python"># 检查简历上的最佳AUC分数
tree1.best_score_
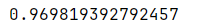
这是一个很强的AUC得分,说明这个模型可以很好地预测哪些员工会离开。
接下来,我们可以编写一个函数,它将帮助我们从网格搜索中提取所有分数。
python">def make_results(model_name: str, model_object, metric: str):'''参数:model_name (string): 您希望在输出表中调用的模型model_object: 合适的GridSearchCV对象metric (string): 精度、召回率、f1、准确度或auc返回一个pandas df,其中包含F1、召回率、精度、准确度和auc分数,对于在所有验证折叠中具有最佳平均“度量”分数的模型。'''# 创建字典,将输入指标映射到GridSearchCV中的实际指标名称metric_dict = {'auc': 'mean_test_roc_auc','precision': 'mean_test_precision','recall': 'mean_test_recall','f1': 'mean_test_f1','accuracy': 'mean_test_accuracy'}# 从CV中获取所有结果并将它们放入df中# 将df的行与最大(度量)分数隔离开来# 从该行提取准确性、精度、召回率和f1分数# 创建结果表return table
使用函数从网格搜索中获得所有分数
python"># 获取所有简历分数
tree1_cv_results = make_results('decision tree cv', tree1, 'auc')
tree1_cv_results

所有这些来自决策树模型的分数都是良好模型性能的有力指标。
回想一下,决策树容易受到过拟合的影响,而随机森林通过合并多个树来进行预测来避免过拟合。接下来我们可以构造一个随机森林模型。
随机森林-第1轮
我们建立了一个随机森林模型,并建立了交叉验证的网格搜索,以穷举地搜索最佳模型参数。
python"># 实例化模型
rf = RandomForestClassifier(random_state=0)
# 指定一个要搜索的超参数字典
cv_params = {'max_depth': [3,5, None],'max_features': [1.0],'max_samples': [0.7, 1.0],'min_samples_leaf': [1,2,3],'min_samples_split': [2,3,4],'n_estimators': [300, 500],}
# 分配要捕获的评分指标的字典# 实例化GridSearch将随机森林模型拟合到训练数据中
python">rf1.fit(X_train, y_train)
识别随机森林模型在训练集上获得的最佳AUC分数
python"># 检查简历上的最佳AUC分数
rf1.best_score_
确定随机森林模型参数的最优值
python"># 检查最佳参数
rf1.best_params_

收集决策树和随机森林模型在训练集上的评价分数
python"># 获取所有简历分数
rf1_cv_results = make_results('random forest cv', rf1, 'auc')
print(tree1_cv_results)
print(rf1_cv_results)

随机森林模型的评价分数优于决策树模型,但召回率除外(随机森林模型的召回率分数大约低0.001,这是可以忽略不计的)。这表明随机森林模型在很大程度上优于决策树模型。
接下来,我们可以在测试集上评估最终模型。
现在我们定义一个函数,从模型的预测中获得所有分数。
python">def get_scores(model_name: str, model, X_test_data, y_test_data):'''生成一个考试成绩表.In:model_name (string): 您希望在输出表中如何命名您的模型model: 一个合适的GridSearchCV对象X_test_data: numpy数组的X_test数据y_test_data: Numpy数组的y_test数据Out: 模型的精度、召回率、f1、准确度和AUC分数'''preds = model.best_estimator_.predict(X_test_data)auc = roc_auc_score(y_test_data, preds)accuracy = accuracy_score(y_test_data, preds)precision = precision_score(y_test_data, preds)recall = recall_score(y_test_data, preds)f1 = f1_score(y_test_data, preds)return table
现在我们用性能最好的模型对测试集进行预测
python"># 对测试数据进行预测
rf1_test_scores = get_scores('random forest1 test', rf1, X_test, y_test)
rf1_test_scores

测试分数与验证分数非常相似,这很好。这似乎是一个强有力的模式。由于此测试集仅用于此模型,因此您可以更加确信,您的模型在此数据上的性能代表了它在未见过的新数据上的性能。
工程特性
我们可能会对高评估分数持怀疑态度。有可能发生一些数据泄漏。数据泄漏是当我们使用不应该在训练期间使用的数据来训练我们的模型时,或者因为它出现在测试数据中,或者因为它不是我们期望在实际部署模型时拥有的数据。使用泄露的数据训练模型可能会得到一个不现实的分数,而这个分数在生产中是无法复制的。
在这种情况下,公司很可能不会报告所有员工的满意度。也有可能average_monthly_hours列是某些数据泄漏的来源。如果员工已经决定辞职,或者已经被管理层确定为要被解雇的人,他们的工作时间可能会减少。
第一轮决策树和随机森林模型包括所有变量作为特征。下一轮将结合特征工程来构建改进的模型。
我们可以通过删除satisfaction_level并创建一个新特性来大致捕获员工是否过度工作来继续。我们可以把这个新功能称为过度工作。它是一个二元变量。
python"># 删除' satisfaction_level '并将结果数据框保存在新变量中
df2 = df_enc.drop('satisfaction_level', axis=1)
# 显示新数据的前几行
df2.head()
python"># 创建“过度工作”列。目前,它与月平均工作时间相同。
df2['overworked'] = df2['average_monthly_hours']
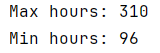
# 检查月平均工时最大值和最小值
print('Max hours:', df2['overworked'].max())
print('Min hours:', df2['overworked'].min())
166.67是每年工作50周,每周工作5天,每天工作8小时的人每月的平均工作时数。
你可以把平均每月工作超过175小时定义为过度工作。
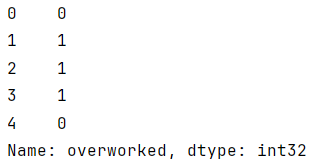
要使过度使用的列变为二进制,可以使用布尔掩码重新分配列。
python"># 将每周工作超过175小时定义为“过度工作”
df2['overworked'] = (df2['overworked'] > 175).astype(int)
# 显示新列的前几行
df2['overworked'].head()
数据处理
删除average_monthly_hours列
python"># 删除' average_monthly_hours '列
df2 = df2.drop('average_monthly_hours', axis=1)
# 显示结果数据的前几行
df2.head()
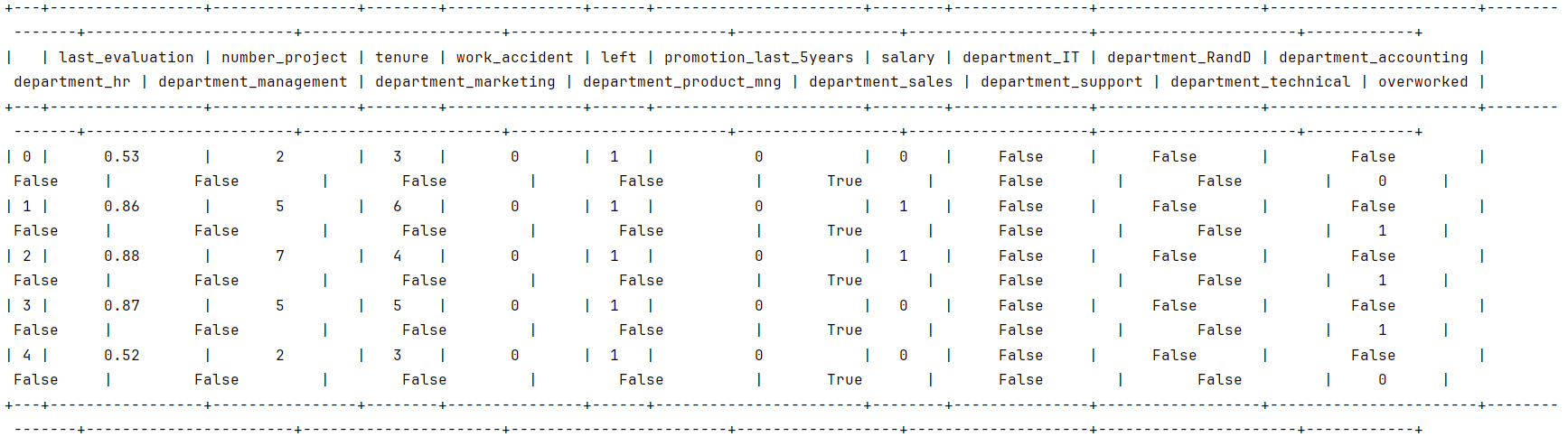
隔离特性和目标变量
python"># 隔离结果变量
y = df2['left']
# 选择特性
X = df2.drop('left', axis=1)
将数据分成训练集和测试集
python"># 创建测试数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, stratify=y, random_state=0)
决策树-第2轮
python"># 实例化模型
tree = DecisionTreeClassifier(random_state=0)
# 指定一个要搜索的超参数字典
cv_params = {'max_depth':[4, 6, 8, None],'min_samples_leaf': [2, 5, 1],'min_samples_split': [2, 4, 6]}
# 分配要捕获的评分指标的字典# 实例化GridSearch将决策树模型拟合到训练数据中
python">tree2.fit(X_train, y_train)
确定决策树参数的最优值
python"># 检查最佳参数
tree2.best_params_

识别决策树模型在训练集上获得的最佳AUC分数
python"># 检查简历上的最佳AUC分数
tree2.best_score_
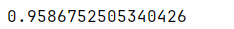
即使没有满意度和详细的工作时间数据,这种模式也表现得非常好。
接下来,我们检查其他分数。
python"># 获取所有简历分数
tree2_cv_results = make_results('decision tree2 cv', tree2, 'auc')
print(tree1_cv_results)
print(tree2_cv_results)

其他一些分数下降了。这是意料之中的,因为在这一轮模型中考虑的功能较少。不过,成绩还是很不错的。
随机森林-第2轮
python"># 实例化模型
rf = RandomForestClassifier(random_state=0)
# 指定一个要搜索的超参数字典
cv_params = {'max_depth': [3,5, None],'max_features': [1.0],'max_samples': [0.7, 1.0],'min_samples_leaf': [1,2,3],'min_samples_split': [2,3,4],'n_estimators': [300, 500],}
# 分配要捕获的评分指标的字典# 实例化GridSearch将随机森林模型拟合到训练数据中
python">rf2.fit(X_train, y_train)
识别随机森林模型在训练集上获得的最佳AUC分数
python"># 检查简历上的最佳AUC分数
rf2.best_score_
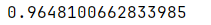
确定随机森林模型参数的最优值
python"># 检查最佳参数
rf2.best_params_

收集决策树和随机森林模型在训练集上的评价分数
python"># 获取所有简历分数
rf2_cv_results = make_results('random forest2 cv', rf2, 'auc')
print(tree2_cv_results)
print(rf2_cv_results)

同样,分数略有下降,但如果使用AUC作为决定性指标,随机森林比决策树表现得更好。
现在我们在测试集上给冠军模型打分。
python"># 对测试数据进行预测
rf2_test_scores = get_scores('random forest2 test', rf2, X_test, y_test)
rf2_test_scores

这似乎是一个稳定的,性能良好的最终模型。
现在我们绘制一个混淆矩阵来可视化它在测试集上的预测效果。
混淆矩阵
python"># 为混淆矩阵生成值数组
preds = rf2.best_estimator_.predict(X_test)
cm = confusion_matrix(y_test, preds, labels=rf2.classes_)
# 情节混淆矩阵
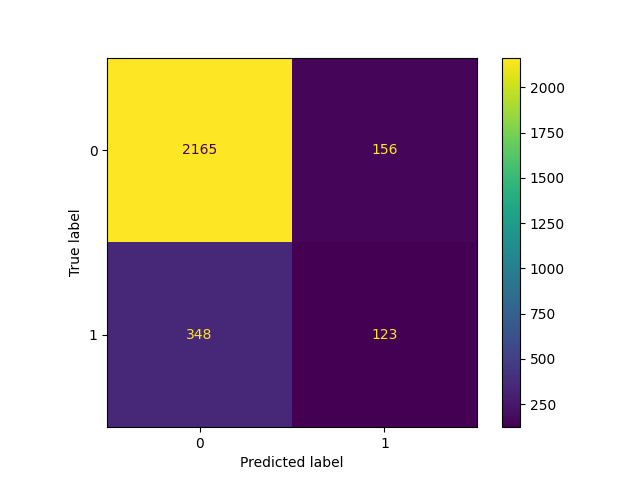
该模型预测的假阳性多于假阴性,这意味着一些员工可能会被认为有辞职或被解雇的风险,而事实并非如此。但这仍然是一个强有力的模式。
出于探索的目的,我们可能想要检查决策树模型的分裂和随机森林模型中最重要的特征。
决策树分裂
python"># 绘制树
plt.figure(figsize=(85,20))
请注意,通过树图像可检查分割。
决策树特征重要性
python">tree2_importances = pd.DataFrame(tree2.best_estimator_.feature_importances_,columns=['gini_importance'],index=X.columns)
# 只提取重要度> 0的特征
决策树:员工离职的特征重要性
python">#决策树:员工离职的特征重要性
sns.barplot(data=tree2_importances, x="gini_importance", y=tree2_importances.index, orient='h')
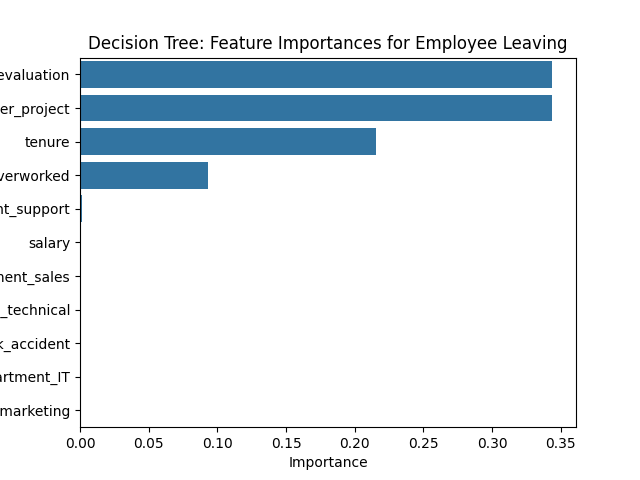
面的柱状图显示,在这个决策树模型中,last_evaluation、number_project、tenure和overworked按此顺序具有最高的重要性。这些变量在预测结果变量(左)时最有帮助。
随机森林特征重要性
现在,我们绘制随机森林模型的特征重要性。
python"># 获取功能重要性
feat_impt = rf2.best_estimator_.feature_importances_
# 获取前10个特征的索引
ind = np.argpartition(rf2.best_estimator_.feature_importances_, -10)[-10:]
# 获取前10个特性的列标签
feat = X.columns[ind]
# 过滤' feat_impt '以包含最重要的10个功能
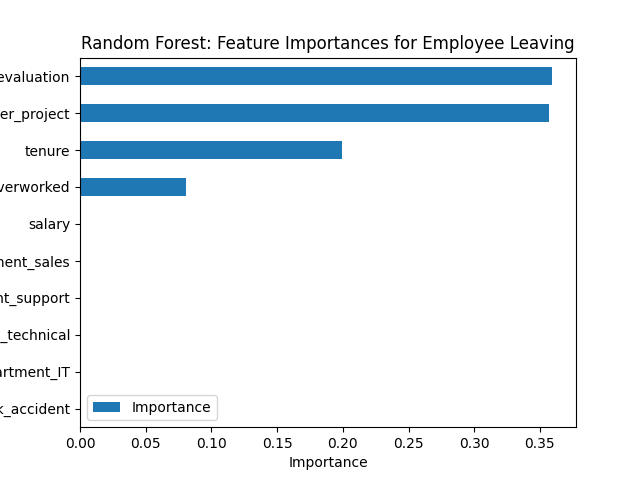
结论
召回评估指标
- AUC为ROC曲线下面积;它还考虑了模型对随机正例的排序高于随机负例的概率。
- 精确度衡量的是预测为真而实际为真的数据点的比例,换句话说,就是预测为真正的数据点的比例。
- 召回度量的是在所有实际为真数据点中,被预测为真数据点的比例。换句话说,它衡量的是正确分类的阳性比例。
- 准确性衡量被正确分类的数据点的比例。
- F1-score是准确率和召回率的总和。
模型结果总结
逻辑回归
逻辑回归模型在测试集上的精密度为80%,召回率为83%,f1分数为80%(所有加权平均值),准确率为83%。
基于树的机器学习
经过特征工程处理,决策树模型在测试集上的AUC为93.8%,准确率为87.0%,召回率为90.4%,f1-score为88.7%,准确率为96.2%。随机森林模型略优于决策树模型。
建议,后续步骤
模型和从模型中提取的特征重要性证实了该公司的员工过度工作。
为留住员工,可向持份者提出以下建议:
- 限制员工可以从事的项目数量。
- 考虑提拔那些在公司工作了至少四年的员工,或者进一步调查为什么四年任期的员工如此不满意。
- 要么奖励工作时间较长的员工,要么不要求他们这样做。
- 如果员工不熟悉公司的加班费政策,告诉他们。如果对工作量和休假的期望不明确,那就把它们弄清楚。
- 在公司范围内和团队内部进行讨论,以全面了解和解决公司的工作文化,在特定的情况下。
- 高评价分数不应该留给每月工作200小时以上的员工。考虑一个比例尺度来奖励那些贡献更多/付出更多努力的员工。
下一个步骤
对数据泄露仍有一些担忧可能是合理的。考虑从数据中删除last_evaluation后预测会发生什么变化可能是谨慎的做法。有可能评估不经常执行,在这种情况下,如果没有这个功能,能够预测员工的保留率将是有用的。也有可能是评估分数决定了员工是离开还是留下,在这种情况下,调整并尝试预测绩效分数可能是有用的。满意度分数也是如此。