Apache Atlas部署安装
这里需要注意,需要从官网下载Atlas的源码,不要从git上分支去checkout,因为从分支checkout出来的代码,无法正常运行,这里小编使用针对Atlas-2.3.0源码进行编译.
mvn clean -DskipTests package -Pdist
部署前置条件
- Elastic7.x
- HBase2.x
- Kafla-2.x
- zookeeper-3.4.x
- Hive Metastore - 3.x
Atlas参数配置
#
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
########## Graph Database Configs ########## Graph Database#Configures the graph database to use. Defaults to JanusGraph
#atlas.graphdb.backend=org.apache.atlas.repository.graphdb.janus.AtlasJanusGraphDatabase# Graph Storage
# Set atlas.graph.storage.backend to the correct value for your desired storage
# backend. Possible values:
#
# hbase
# cassandra
# embeddedcassandra - Should only be set by building Atlas with -Pdist,embedded-cassandra-solr
# berkeleyje
#
# See the configuration documentation for more information about configuring the various storage backends.
#
atlas.graph.storage.backend=hbase2
atlas.graph.storage.hbase.table=apache_atlas_janus
# atlas.graph.storage.username=
# atlas.graph.storage.password=#Hbase
#For standalone mode , specify localhost
#for distributed mode, specify zookeeper quorum here
atlas.graph.storage.hostname=10.0.0.141:2181,10.0.0.140:2181,10.0.0.142:2181
atlas.graph.storage.hbase.regions-per-server=1#In order to use Cassandra as a backend, comment out the hbase specific properties above, and uncomment the
#the following properties
#atlas.graph.storage.clustername=
#atlas.graph.storage.port=# Gremlin Query Optimizer
#
# Enables rewriting gremlin queries to maximize performance. This flag is provided as
# a possible way to work around any defects that are found in the optimizer until they
# are resolved.
#atlas.query.gremlinOptimizerEnabled=true# Delete handler
#
# This allows the default behavior of doing "soft" deletes to be changed.
#
# Allowed Values:
# org.apache.atlas.repository.store.graph.v1.SoftDeleteHandlerV1 - all deletes are "soft" deletes
# org.apache.atlas.repository.store.graph.v1.HardDeleteHandlerV1 - all deletes are "hard" deletes
#
atlas.DeleteHandlerV1.impl=org.apache.atlas.repository.store.graph.v1.HardDeleteHandlerV1# Entity audit repository
#
# This allows the default behavior of logging entity changes to hbase to be changed.
#
# Allowed Values:
# org.apache.atlas.repository.audit.HBaseBasedAuditRepository - log entity changes to hbase
# org.apache.atlas.repository.audit.CassandraBasedAuditRepository - log entity changes to cassandra
# org.apache.atlas.repository.audit.NoopEntityAuditRepository - disable the audit repository
#
atlas.EntityAuditRepository.impl=org.apache.atlas.repository.audit.HBaseBasedAuditRepository# if Cassandra is used as a backend for audit from the above property, uncomment and set the following
# properties appropriately. If using the embedded cassandra profile, these properties can remain
# commented out.
# atlas.EntityAuditRepository.keyspace=atlas_audit
# atlas.EntityAuditRepository.replicationFactor=1# Graph Search Index
atlas.graph.index.search.backend=elasticsearch#Solr
#Solr cloud mode properties
atlas.graph.index.search.solr.mode=cloud
atlas.graph.index.search.solr.zookeeper-url=
atlas.graph.index.search.solr.zookeeper-connect-timeout=60000
atlas.graph.index.search.solr.zookeeper-session-timeout=60000
atlas.graph.index.search.solr.wait-searcher=false#Solr http mode properties
#atlas.graph.index.search.solr.mode=http
#atlas.graph.index.search.solr.http-urls=http://localhost:8983/solr# ElasticSearch support (Tech Preview)
# Comment out above solr configuration, and uncomment the following two lines. Additionally, make sure the
# hostname field is set to a comma delimited set of elasticsearch master nodes, or an ELB that fronts the masters.
#
# Elasticsearch does not provide authentication out of the box, but does provide an option with the X-Pack product
# https://www.elastic.co/products/x-pack/security
#
# Alternatively, the JanusGraph documentation provides some tips on how to secure Elasticsearch without additional
# plugins: https://docs.janusgraph.org/latest/elasticsearch.html
atlas.graph.index.search.hostname=10.0.0.79:9200,10.0.0.80:9200,10.0.0.141:9200
atlas.graph.index.search.elasticsearch.client-only=true# Solr-specific configuration property
atlas.graph.index.search.max-result-set-size=150######### Import Configs #########
#atlas.import.temp.directory=/temp/import######### Notification Configs #########
atlas.notification.embedded=false
atlas.kafka.data=${sys:atlas.home}/data/kafka
atlas.kafka.zookeeper.connect=10.0.0.141:2181,10.0.0.140:2181,10.0.0.142:2181/kafka
atlas.kafka.bootstrap.servers=10.0.0.141:9092,10.0.0.80:9092,10.0.0.79:9092
atlas.kafka.zookeeper.session.timeout.ms=400
atlas.kafka.zookeeper.connection.timeout.ms=200
atlas.kafka.zookeeper.sync.time.ms=20
atlas.kafka.auto.commit.interval.ms=1000
atlas.kafka.hook.group.id=atlasatlas.kafka.enable.auto.commit=false
atlas.kafka.auto.offset.reset=earliest
atlas.kafka.session.timeout.ms=30000
atlas.kafka.offsets.topic.replication.factor=1
atlas.kafka.poll.timeout.ms=1000atlas.notification.create.topics=true
atlas.notification.replicas=1
atlas.notification.topics=ATLAS_HOOK,ATLAS_ENTITIES
atlas.notification.log.failed.messages=true
atlas.notification.consumer.retry.interval=500
atlas.notification.hook.retry.interval=1000
# Enable for Kerberized Kafka clusters
#atlas.notification.kafka.service.principal=kafka/_HOST@EXAMPLE.COM
#atlas.notification.kafka.keytab.location=/etc/security/keytabs/kafka.service.keytab## Server port configuration
#atlas.server.http.port=21000
#atlas.server.https.port=21443######### Security Properties ########## SSL config
atlas.enableTLS=false#truststore.file=/path/to/truststore.jks
#cert.stores.credential.provider.path=jceks://file/path/to/credentialstore.jceks#following only required for 2-way SSL
#keystore.file=/path/to/keystore.jks# Authentication configatlas.authentication.method.kerberos=false
atlas.authentication.method.file=true#### ldap.type= LDAP or AD
atlas.authentication.method.ldap.type=none#### user credentials file
atlas.authentication.method.file.filename=${sys:atlas.home}/conf/users-credentials.properties### groups from UGI
#atlas.authentication.method.ldap.ugi-groups=true######## LDAP properties #########
#atlas.authentication.method.ldap.url=ldap://<ldap server url>:389
#atlas.authentication.method.ldap.userDNpattern=uid={0},ou=People,dc=example,dc=com
#atlas.authentication.method.ldap.groupSearchBase=dc=example,dc=com
#atlas.authentication.method.ldap.groupSearchFilter=(member=uid={0},ou=Users,dc=example,dc=com)
#atlas.authentication.method.ldap.groupRoleAttribute=cn
#atlas.authentication.method.ldap.base.dn=dc=example,dc=com
#atlas.authentication.method.ldap.bind.dn=cn=Manager,dc=example,dc=com
#atlas.authentication.method.ldap.bind.password=<password>
#atlas.authentication.method.ldap.referral=ignore
#atlas.authentication.method.ldap.user.searchfilter=(uid={0})
#atlas.authentication.method.ldap.default.role=<default role>######### Active directory properties #######
#atlas.authentication.method.ldap.ad.domain=example.com
#atlas.authentication.method.ldap.ad.url=ldap://<AD server url>:389
#atlas.authentication.method.ldap.ad.base.dn=(sAMAccountName={0})
#atlas.authentication.method.ldap.ad.bind.dn=CN=team,CN=Users,DC=example,DC=com
#atlas.authentication.method.ldap.ad.bind.password=<password>
#atlas.authentication.method.ldap.ad.referral=ignore
#atlas.authentication.method.ldap.ad.user.searchfilter=(sAMAccountName={0})
#atlas.authentication.method.ldap.ad.default.role=<default role>######### JAAS Configuration #########atlas.jaas.KafkaClient.loginModuleName = com.sun.security.auth.module.Krb5LoginModule
#atlas.jaas.KafkaClient.loginModuleControlFlag = required
#atlas.jaas.KafkaClient.option.useKeyTab = true
#atlas.jaas.KafkaClient.option.storeKey = true
#atlas.jaas.KafkaClient.option.serviceName = kafka
#atlas.jaas.KafkaClient.option.keyTab = /etc/security/keytabs/atlas.service.keytab
#atlas.jaas.KafkaClient.option.principal = atlas/_HOST@EXAMPLE.COM######### Server Properties #########
atlas.rest.address=http://localhost:21000
# If enabled and set to true, this will run setup steps when the server starts
#atlas.server.run.setup.on.start=false######### Entity Audit Configs #########
atlas.audit.hbase.tablename=apache_atlas_entity_audit
atlas.audit.zookeeper.session.timeout.ms=1000
atlas.audit.hbase.zookeeper.quorum=10.0.0.141:2181,10.0.0.140:2181,10.0.0.142:2181######### High Availability Configuration ########
atlas.server.ha.enabled=false
#### Enabled the configs below as per need if HA is enabled #####
#atlas.server.ids=id1
#atlas.server.address.id1=localhost:21000
#atlas.server.ha.zookeeper.connect=localhost:2181
#atlas.server.ha.zookeeper.retry.sleeptime.ms=1000
#atlas.server.ha.zookeeper.num.retries=3
#atlas.server.ha.zookeeper.session.timeout.ms=20000
## if ACLs need to be set on the created nodes, uncomment these lines and set the values ##
#atlas.server.ha.zookeeper.acl=<scheme>:<id>
#atlas.server.ha.zookeeper.auth=<scheme>:<authinfo>######### Atlas Authorization #########
atlas.authorizer.impl=simple
atlas.authorizer.simple.authz.policy.file=atlas-simple-authz-policy.json######### Type Cache Implementation ########
# A type cache class which implements
# org.apache.atlas.typesystem.types.cache.TypeCache.
# The default implementation is org.apache.atlas.typesystem.types.cache.DefaultTypeCache which is a local in-memory type cache.
#atlas.TypeCache.impl=######### Performance Configs #########
#atlas.graph.storage.lock.retries=10
#atlas.graph.storage.cache.db-cache-time=120000######### CSRF Configs #########
atlas.rest-csrf.enabled=true
atlas.rest-csrf.browser-useragents-regex=^Mozilla.*,^Opera.*,^Chrome.*
atlas.rest-csrf.methods-to-ignore=GET,OPTIONS,HEAD,TRACE
atlas.rest-csrf.custom-header=X-XSRF-HEADER############ KNOX Configs ################
#atlas.sso.knox.browser.useragent=Mozilla,Chrome,Opera
#atlas.sso.knox.enabled=true
#atlas.sso.knox.providerurl=https://<knox gateway ip>:8443/gateway/knoxsso/api/v1/websso
#atlas.sso.knox.publicKey=############ Atlas Metric/Stats configs ################
# Format: atlas.metric.query.<key>.<name>
atlas.metric.query.cache.ttlInSecs=900
#atlas.metric.query.general.typeCount=
#atlas.metric.query.general.typeUnusedCount=
#atlas.metric.query.general.entityCount=
#atlas.metric.query.general.tagCount=
#atlas.metric.query.general.entityDeleted=
#
#atlas.metric.query.entity.typeEntities=
#atlas.metric.query.entity.entityTagged=
#
#atlas.metric.query.tags.entityTags=######### Compiled Query Cache Configuration ########## The size of the compiled query cache. Older queries will be evicted from the cache
# when we reach the capacity.#atlas.CompiledQueryCache.capacity=1000# Allows notifications when items are evicted from the compiled query
# cache because it has become full. A warning will be issued when
# the specified number of evictions have occurred. If the eviction
# warning threshold <= 0, no eviction warnings will be issued.#atlas.CompiledQueryCache.evictionWarningThrottle=0######### Full Text Search Configuration ##########Set to false to disable full text search.
#atlas.search.fulltext.enable=true######### Gremlin Search Configuration ##########Set to false to disable gremlin search.
atlas.search.gremlin.enable=false########## Add http headers ############atlas.headers.Access-Control-Allow-Origin=*
#atlas.headers.Access-Control-Allow-Methods=GET,OPTIONS,HEAD,PUT,POST
#atlas.headers.<headerName>=<headerValue>######### UI Configuration ########atlas.ui.default.version=v1
修改部署atlas服务端环境信息,确保配置了HBASE_CONF_DIR环境变量信息之后,启动Atlas服务即可。这里需要注意Atlas服务首次启动服务时间较长,一般需要20分钟左右,才会初始化hbase和elastic索引数据,因此启动完Atlas之后,需要耐心等到。启动完成后,可以使用admin/admin账号登陆服务
Apache Hive元数据配置
1)在hive-site.xml文件中增加如下配置
<property><name>hive.exec.post.hooks</name><value>org.apache.atlas.hive.hook.HiveHook</value></property><property><name>hive.metastore.event.listeners</name><value>org.apache.atlas.hive.hook.HiveMetastoreHook</value></property>
2)解压apache-atlas-2.3.0-hive-hook.tar.gz文件,然后将该文件包下的atlas-plugin-classloader-2.3.0.jar和hive-bridge-shim-2.3.0.jar建立软连接到hive安装目录下的auxlib目录
[hdfs@citicbank-bdp-1a-02 server]$ tree apache-atlas-hive-hook-2.3.0
apache-atlas-hive-hook-2.3.0
├── hook
│ └── hive
│ ├── atlas-hive-plugin-impl
│ │ ├── atlas-client-common-2.3.0.jar
│ │ ├── atlas-client-v1-2.3.0.jar
│ │ ├── atlas-client-v2-2.3.0.jar
│ │ ├── atlas-common-2.3.0.jar
│ │ ├── atlas-intg-2.3.0.jar
│ │ ├── atlas-notification-2.3.0.jar
│ │ ├── commons-configuration-1.10.jar
│ │ ├── hive-bridge-2.3.0.jar
│ │ ├── jackson-annotations-2.11.3.jar
│ │ ├── jackson-core-2.11.3.jar
│ │ ├── jackson-databind-2.11.3.jar
│ │ ├── jersey-json-1.19.jar
│ │ ├── jersey-multipart-1.19.jar
│ │ ├── kafka_2.12-2.8.1.jar
│ │ └── kafka-clients-2.8.1.jar
│ ├── atlas-plugin-classloader-2.3.0.jar
│ └── hive-bridge-shim-2.3.0.jar
└── hook-bin└── import-hive.sh4 directories, 18 files
[hdfs@citicbank-bdp-1a-02 hive-3.2.0]$ ls -l auxlib/
total 0
lrwxrwxrwx 1 root root 88 May 25 15:01 atlas-plugin-classloader-2.3.0.jar -> /export/server/apache-atlas-hive-hook-2.3.0/hook/hive/atlas-plugin-classloader-2.3.0.jar
lrwxrwxrwx 1 root root 80 May 25 15:01 hive-bridge-shim-2.3.0.jar -> /export/server/apache-atlas-hive-hook-2.3.0/hook/hive/hive-bridge-shim-2.3.0.jar
3)拷贝atlas-application.proerpties文件到hive安装目录下的conf目录下,重启hms即可
Spark SQL血缘集成
1)下载kyuubi源码,编译如下模块
mvn clean package -pl :kyuubi-spark-lineage_2.12 -am -DskipTests
或者基于整个项目编译
mvn clean package -DskipTests -P mirror-cn -P spark-3.2 -P spark-hadoop-3.2
- 修改kyuubi-spark-lineage/pom.xml文件解决兼容性问题
<dependencyManagement><dependencies><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-core</artifactId><version>2.14.3</version></dependency><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId><version>2.14.3</version></dependency><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-annotations</artifactId><version>2.14.3</version></dependency></dependencies></dependencyManagement>
<properties>
...<dependency><groupId>com.sun.jersey</groupId><artifactId>jersey-client</artifactId><version>1.19</version></dependency><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-core</artifactId></dependency><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId></dependency><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-annotations</artifactId></dependency>...<build><plugins><plugin><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><version>${maven.plugin.scala.version}</version><executions><execution><id>scala-compile-first</id><phase>process-resources</phase><goals><goal>add-source</goal><goal>compile</goal></goals></execution></executions></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>3.2.1</version><executions><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><filters><filter><artifact>*:*</artifact><excludes><exclude>META-INF/*.SF</exclude><exclude>META-INF/*.DSA</exclude><exclude>META-INF/*.RSA</exclude></excludes></filter></filters><relocations><relocation><pattern>com.fasterxml.jackson.</pattern><shadedPattern>com.jdcloud.bigdata.hook.shade.com.fasterxml.jackson.</shadedPattern></relocation></relocations></configuration></execution></executions></plugin></plugins></build>
</properties>
3)配置spark-default.conf文件
spark.sql.queryExecutionListeners=org.apache.kyuubi.plugin.lineage.SparkOperationLineageQueryExecutionListener
spark.kyuubi.plugin.lineage.dispatchers=ATLAS
spark.atlas.rest.address=http://10.0.0.79:21000
spark.atlas.client.type=rest
spark.atlas.client.username=admin
spark.atlas.client.password=admin
spark.atlas.cluster.name=primary
spark.atlas.hook.spark.column.lineage.enabled=true
spark.kyuubi.plugin.lineage.skip.parsing.permanent.view.enabled=true
这里http://10.0.0.79:21000是部署的Atlas服务访问地址
3)拷贝atlas-application.proerpties文件到spark安装目录下的conf目录下,执行SQL,进行血缘测试
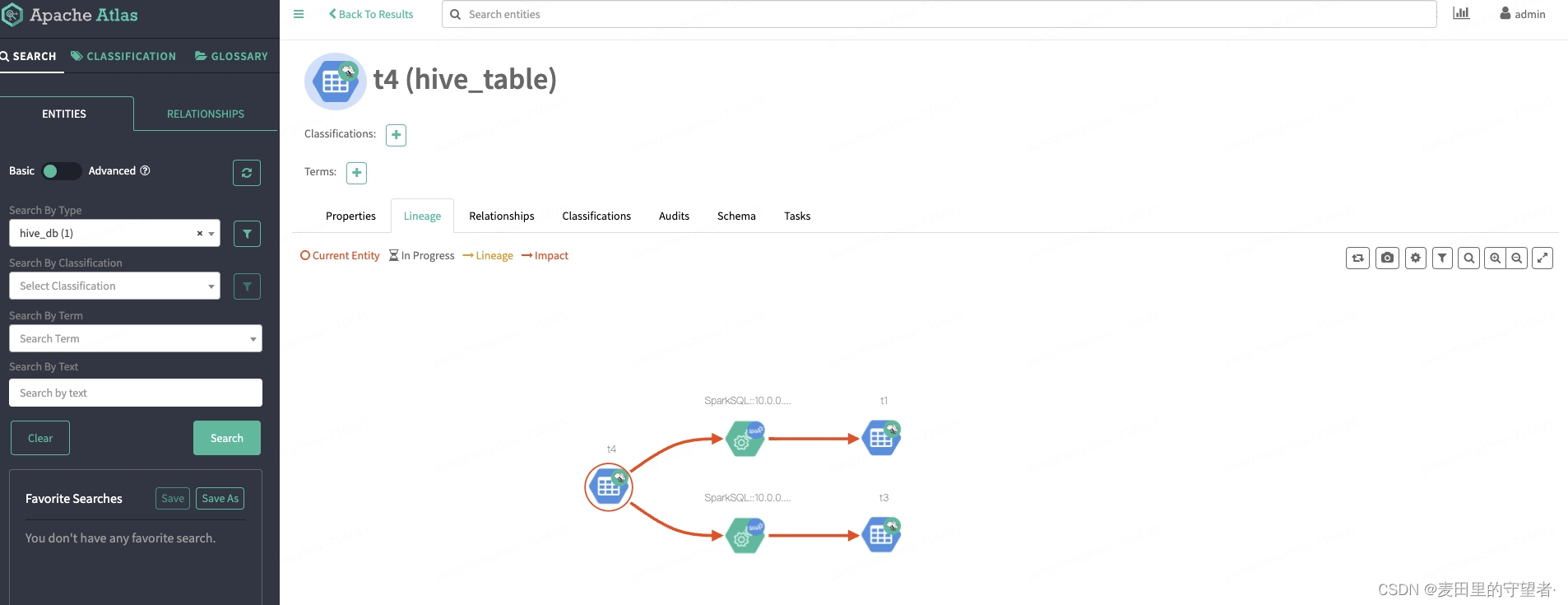
hbase 元数据集成
- 在hbase-site.xml文件中添加如下配置
</property><property><name>hbase.coprocessor.master.classes</name><value>com.jd.bigdata.hbase.hook.HBaseAtlasCoprocessor</value>
</property>
<property><name>hbase.coprocessor.region.classes</name><value>com.jd.bigdata.hbase.hook.HBaseAtlasCoprocessor</value>
</property>
- 解压apache-atlas-hbase-hook-2.3.0.tar.gz文件,然后将atlas-plugin-classloader-2.3.0.jar和hbase-bridge-shim-2.3.0.jar资源文件拷贝到hbase的安装目录下lib目录下创建软连接
tree apache-atlas-hbase-hook-2.3.0
apache-atlas-hbase-hook-2.3.0
├── hook
│ └── hbase
│ ├── atlas-hbase-plugin-impl
│ │ ├── atlas-client-common-2.3.0.jar
│ │ ├── atlas-client-v2-2.3.0.jar
│ │ ├── atlas-common-2.3.0.jar
│ │ ├── atlas-intg-2.3.0.jar
│ │ ├── atlas-notification-2.3.0.jar
│ │ ├── commons-collections-3.2.2.jar
│ │ ├── commons-configuration-1.10.jar
│ │ ├── commons-logging-1.1.3.jar
│ │ ├── hbase-bridge-2.3.0.jar
│ │ ├── jackson-annotations-2.11.3.jar
│ │ ├── jackson-core-2.11.3.jar
│ │ ├── jackson-databind-2.11.3.jar
│ │ ├── jackson-jaxrs-base-2.11.3.jar
│ │ ├── jackson-jaxrs-json-provider-2.11.3.jar
│ │ ├── jersey-bundle-1.19.jar
│ │ ├── jersey-json-1.19.jar
│ │ ├── jersey-multipart-1.19.jar
│ │ ├── jsr311-api-1.1.jar
│ │ ├── kafka_2.12-2.8.1.jar
│ │ └── kafka-clients-2.8.1.jar
│ ├── atlas-plugin-classloader-2.3.0.jar
│ └── hbase-bridge-shim-2.3.0.jar
└── hook-bin└── import-hbase.sh4 directories, 23 files3)拷贝atlas-application.proerpties文件到hbase安装目录下的conf目录下,执行DDL语句查看元数据采集

![[猫头虎分享21天微信小程序基础入门教程] 第20天:小程序的多媒体功能与图像处理](https://img-blog.csdnimg.cn/direct/33c9a34d74f247518c369b9d9e5aba3e.gif)


