目录
🍉简介
🍈K-means聚类模型详解
🍈K-means聚类的基本原理
🍈K-means聚类的优缺点
🍍优点
🍍缺点
🍈K-means聚类的应用场景
🍈K-means的改进和变体
🍈问题
🍍数据准备
🍍选择K值
🍍运行K-means聚类
🍍分析聚类结果
🍈完整代码实现
🍈代码解释
🍉简介
🍈K-means聚类模型详解
🍈K-means聚类的基本原理
- K-means聚类通过最小化样本到其所属簇中心的距离来实现数据的分组。具体而言,K-means的目标是将数据分成K个簇,并使每个簇中的数据点到其质心(centroid)的欧氏距离平方和最小。
假设我们有一个数据集${x_1, x_2, \ldots, x_n}$,其中每个数据点$x_i$是一个d维向量。我们需要将这些数据点分成K个簇${C_1, C_2, \ldots, C_K}$。K-means的优化目标可以表示为:
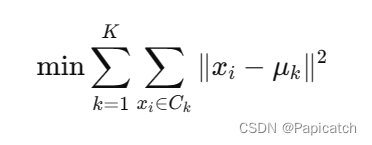
其中,$\mu_k$表示簇$C_k$的质心。
🍈K-means聚类的算法步骤
- 初始化:随机选择K个数据点作为初始质心。
- 分配簇:对于数据集中的每个数据点,计算其到各个质心的距离,并将其分配到距离最近的质心所在的簇。
- 更新质心:对于每个簇,计算所有分配到该簇的数据点的平均值,更新该簇的质心。
- 重复:重复步骤2和3,直到质心不再发生显著变化,或者达到预设的迭代次数。
🍈K-means聚类的优缺点
🍍优点
🍍缺点
- 需要预设K值:必须提前确定簇的数量K,且K值的选择对结果影响较大。
- 对初始质心敏感:初始质心的选择会影响最终结果,可能会陷入局部最优。
- 对噪声和异常值敏感:噪声和异常值可能会严重影响簇的结果。
🍈K-means聚类的应用场景
K-means聚类在实际中有广泛的应用,包括但不限于:
- 图像处理:如图像分割、颜色量化等。
- 市场营销:客户分群,根据消费行为将客户分成不同的群体。
- 文本处理:文档聚类,将相似的文档分在一起。
- 生物信息学:基因表达数据分析,将具有相似表达模式的基因分在一起。
🍈K-means的改进和变体
为了克服K-means的一些缺点,研究人员提出了许多改进和变体方法:
🍉K-means聚类算法示例
🍈问题
假设我们是一家电子商务公司,希望通过分析客户的购买行为,将客户分成不同的群体,以便进行有针对性的市场营销。我们拥有以下客户数据集:
- 客户ID
- 年龄
- 年收入(以美元计)
- 年消费额(以美元计)
🍍数据准备
首先,我们需要对数据进行预处理和标准化,因为不同特征的量纲可能会影响聚类效果。
python">import pandas as pd
from sklearn.preprocessing import StandardScaler# 创建示例数据集
data = {'CustomerID': [1, 2, 3, 4, 5],'Age': [25, 34, 45, 23, 35],'Annual Income (k$)': [15, 20, 35, 60, 45],'Spending Score (1-100)': [39, 81, 6, 77, 40]
}
df = pd.DataFrame(data)# 标准化特征
scaler = StandardScaler()
df[['Age', 'Annual Income (k$)', 'Spending Score (1-100)']] = scaler.fit_transform(df[['Age', 'Annual Income (k$)', 'Spending Score (1-100)']])
🍍选择K值
通常情况下,选择K值可以通过“肘部法则”来确定。我们绘制不同K值下的SSE(误差平方和)曲线,选择拐点作为K值。
python">from sklearn.cluster import KMeans
import matplotlib.pyplot as plt# 计算不同K值下的SSE
sse = []
for k in range(1, 11):kmeans = KMeans(n_clusters=k, random_state=0)kmeans.fit(df[['Age', 'Annual Income (k$)', 'Spending Score (1-100)']])sse.append(kmeans.inertia_)# 绘制肘部法则图
plt.figure(figsize=(8, 5))
plt.plot(range(1, 11), sse, marker='o')
plt.title('Elbow Method for Optimal K')
plt.xlabel('Number of clusters')
plt.ylabel('SSE')
plt.show()
假设通过肘部法则确定K值为3。
🍍运行K-means聚类
使用K-means算法对客户进行分群。
python"># 运行K-means聚类
kmeans = KMeans(n_clusters=3, random_state=0)
df['Cluster'] = kmeans.fit_predict(df[['Age', 'Annual Income (k$)', 'Spending Score (1-100)']])# 查看聚类结果
print(df)
🍍分析聚类结果
通过可视化和统计分析,我们可以更好地理解每个簇的特征。
python"># 可视化聚类结果
plt.figure(figsize=(8, 5))
plt.scatter(df['Annual Income (k$)'], df['Spending Score (1-100)'], c=df['Cluster'], cmap='viridis')
plt.scatter(kmeans.cluster_centers_[:, 1], kmeans.cluster_centers_[:, 2], s=300, c='red')
plt.title('Customer Segments')
plt.xlabel('Annual Income (k$)')
plt.ylabel('Spending Score (1-100)')
plt.show()
此外,我们可以查看每个簇的中心和簇内数据点的分布情况:
python"># 查看每个簇的中心
centroids = kmeans.cluster_centers_
print("Cluster Centers:\n", centroids)# 查看每个簇的样本数量
print(df['Cluster'].value_counts())
🍈完整代码实现
python">import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt# 创建示例数据集
data = {'CustomerID': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],'Age': [25, 34, 45, 23, 35, 64, 24, 29, 33, 55],'Annual Income (k$)': [15, 20, 35, 60, 45, 70, 18, 24, 50, 40],'Spending Score (1-100)': [39, 81, 6, 77, 40, 80, 20, 60, 54, 50]
}
df = pd.DataFrame(data)# 标准化特征
scaler = StandardScaler()
df[['Age', 'Annual Income (k$)', 'Spending Score (1-100)']] = scaler.fit_transform(df[['Age', 'Annual Income (k$)', 'Spending Score (1-100)']])# 计算不同K值下的SSE
sse = []
for k in range(1, 11):kmeans = KMeans(n_clusters=k, random_state=0)kmeans.fit(df[['Age', 'Annual Income (k$)', 'Spending Score (1-100)']])sse.append(kmeans.inertia_)# 绘制肘部法则图
plt.figure(figsize=(8, 5))
plt.plot(range(1, 11), sse, marker='o')
plt.title('Elbow Method for Optimal K')
plt.xlabel('Number of clusters')
plt.ylabel('SSE')
plt.show()# 根据肘部法则选择K值为3
k = 3# 运行K-means聚类
kmeans = KMeans(n_clusters=k, random_state=0)
df['Cluster'] = kmeans.fit_predict(df[['Age', 'Annual Income (k$)', 'Spending Score (1-100)']])# 查看聚类结果
print(df)# 可视化聚类结果
plt.figure(figsize=(8, 5))
plt.scatter(df['Annual Income (k$)'], df['Spending Score (1-100)'], c=df['Cluster'], cmap='viridis')
plt.scatter(kmeans.cluster_centers_[:, 1], kmeans.cluster_centers_[:, 2], s=300, c='red', marker='x')
plt.title('Customer Segments')
plt.xlabel('Annual Income (k$)')
plt.ylabel('Spending Score (1-100)')
plt.show()# 查看每个簇的中心
centroids = kmeans.cluster_centers_
print("Cluster Centers:\n", centroids)# 查看每个簇的样本数量
print(df['Cluster'].value_counts())


🍈代码解释
🍍导入必要的库:
pandas用于数据处理。numpy用于数值计算。StandardScaler用于标准化数据。KMeans用于K-means聚类。matplotlib用于数据可视化。
🍍创建示例数据集:
- 包含客户ID、年龄、年收入和消费评分。
🍍标准化特征:
- 使用
StandardScaler将特征缩放到相同的尺度,以提高聚类效果。
🍍选择K值:
- 使用肘部法则,通过计算不同K值下的SSE(误差平方和)来确定最佳K值。
- 绘制SSE随K值变化的曲线,选择拐点作为最佳K值。
🍍运行K-means聚类:
- 使用确定的K值运行K-means算法,对客户进行分群。
- 将分群结果添加到数据集中。
🍍可视化聚类结果:
- 绘制聚类结果的散点图,使用不同颜色表示不同的簇,并标出每个簇的质心。
🍍查看聚类结果:
- 打印每个簇的中心坐标和每个簇的样本数量,以更好地理解每个簇的特征。
希望这些能对刚学习算法的同学们提供些帮助哦!!!