文章目录
- 系统问题分析
- 什么是异步化?
- 业务流程分析
- 标准异步化的业务流程
- 系统业务流程
- 线程池
- 为什么需要线程池?
- 线程池两种实现方式
- 线程池的参数
- 线程池的开发
- 项目异步化改造
系统问题分析
问题场景:调用的服务能力有限,或者接口的处理(或返回)时长较长时,就应该考虑异步化了
什么是异步化?
不用等一件事做完,就可以做另外一件事,等第一件事完成时,可以收到一个通知
业务流程分析
标准异步化的业务流程
- 当用户要进行耗时很长的操作时,点击提交后,不需要在界面空等,而是应该把这个任务保存到数据库中记录下来
- 用户要执行新任务时:
a. 任务提交成功:
ⅰ. 若程序存在空闲线程,可以立即执行此任务
ⅱ. 若所有线程均繁忙,任务将入队列等待处理
b. 任务提交失败:比如所有线程都在忙碌且任务队列满了
ⅰ.选择拒绝此任务,不再执行
ⅱ.通过查阅数据库记录,发现提交失败的任务,并在程序空闲时将这些任务取出执行 - 程序(线程)从任务队列中取出任务依次执行,每完成一项任务,就更新任务状态。
- 用户可以查询任务的执行状态,或者在任务执行成功或失败时接收通知(例如:发邮件、系统消息提示或短信),从而优化体验
- 对于复杂且包含多个环节的任务,在每个小任务完成时,要在程序(数据库中))记录任务的执行状态(进度)。
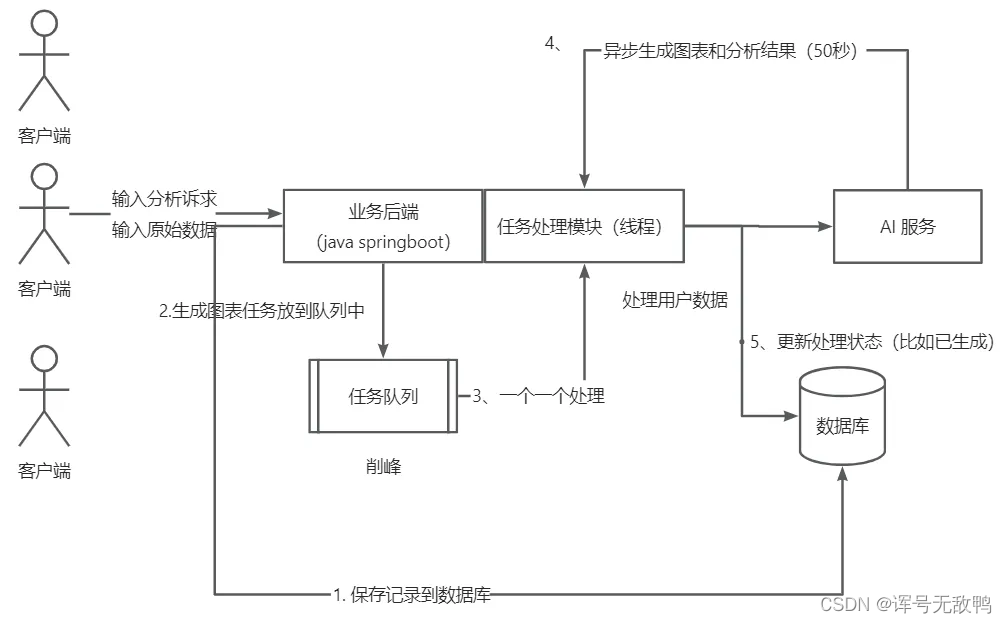
系统业务流程
- 用户点击智能分析页提交按钮时,先把图表立刻保存到数据库中(作为一个任务)
- 用户可以在图表管理查看所有图表(已生成的,生成中的,生成失败的)的信息和状态
- 用户可以修改生成失败的图表信息,点击重新生成,以尝试再次创建图表
问题分析?
- 任务队列的最大容量应该设置为多少
- 程序怎么从任务队列中取出任务去执行?这个任务队列的流程怎么实现?怎么保证程序最多同时执行多少个任务?
线程池实现
线程池
为什么需要线程池?
- 线程的管理比较复杂
- 任务存取比较复杂
- 线程池可以帮你轻松管理线程,协调任务的执行过程
线程池两种实现方式
- Spring中,可以用ThreadPoolTaskExrcutor配合@Async注解来实现(不推荐)
- 在Java中,可以使用JUC并发编程包中的ThreadPoolExecutor来实现非常灵活地自定义线程池
线程池的参数
java">public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler) {
现状:AI生成能力的并发是只允许4个任务同时去执行,AI能力允许20个任务排队
corePoolSize(核心线程数):正常情况下,我们的系统应该能同时工作的线程数
maximumPoolSize(最大线程数):极限情况下,我们的线程池所拥有的线程
keepAliveTime(空闲线程存活时间):非核心线程在没有任务的情况下,过多久要删除,从而释放无用的线程资源
unit(空闲线程存活时间的单位):分钟,秒
workQueue(工作队列):用于存放给线程执行的任务,存在一个队列的长度(一定要设置)
threadFactory(线程工厂):控制每个线程的生成,线程的属性
RejectedExecutionHandler(拒绝策略):任务队列满的时候,我们采取什么措施
线程池的开发
自定义线程池配置
java">package com.yupi.springbootinit.config;import org.jetbrains.annotations.NotNull;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ThreadFactory;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;@Configuration
public class ThreadPoolExecutorConfig {@Beanpublic ThreadPoolExecutor threadPoolExecutor(){// 创建一个线程工厂ThreadFactory threadFactory = new ThreadFactory(){// 初始化线程数为 1private int count = 1;// 创建一个新的线程@Override// 每当线程池需要创建新线程时,就会调用newThread方法// @NotNull Runnable r 表示方法参数 r 应该永远不为null,public Thread newThread(@NotNull Runnable r) {Thread thread = new Thread(r);thread.setName("线程" + count ++);return thread;}};// 创建一个新的线程池,线程池核心大小为2,最大线程数为4,// 非核心线程空闲时间为100秒,任务队列为阻塞队列,长度为4,使用自定义的线程工厂创建线ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(2,4,100, TimeUnit.SECONDS,new ArrayBlockingQueue<>(4),threadFactory);return threadPoolExecutor;}
}测试controller层(注意线上环境不要暴露出去)
java">package com.yupi.springbootinit.controller;import cn.hutool.json.JSONUtil;
import io.netty.handler.codec.serialization.ObjectEncoder;
import lombok.extern.slf4j.Slf4j;
import org.springframework.context.annotation.Profile;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;import javax.annotation.Resource;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ThreadPoolExecutor;/*** 队列测试controller*/
@RestController
@RequestMapping("/queue")
@Slf4j
@Profile({"dev","local"}) // 只在开发环境和本地环境生效
public class QueueController {@Resourceprivate ThreadPoolExecutor threadPoolExecutor;@GetMapping("/add")// 接收一个参数name,然后将任务添加到线程池中public void add(String name){// 使用CompletableFuture运行一个异步任务CompletableFuture.runAsync(()->{log.info("任务执行中:" + name + "执行人:" + Thread.currentThread().getName());try {// 让线程休眠10分钟,模拟长时间运行的任务Thread.sleep(600000);} catch (InterruptedException e) {throw new RuntimeException(e);} 异步任务在threadPoolExecutor中执行},threadPoolExecutor);}@GetMapping("/get")public String get(){Map<String, Object> map = new HashMap<>();int size = threadPoolExecutor.getQueue().size();map.put("队列长度",size);long taskCount = threadPoolExecutor.getTaskCount();map.put("任务总数",taskCount);long completedTaskCount = threadPoolExecutor.getCompletedTaskCount();map.put("已完成的任务总数",completedTaskCount);int activeCount = threadPoolExecutor.getActiveCount();map.put("正在工作的线程数",activeCount);return JSONUtil.toJsonStr(map);}
}项目异步化改造
java">/*** 智能分析(异步)** @param multipartFile* @param genChartByAiRequest* @param request* @return*/
@PostMapping("/gen/async")
public BaseResponse<BiResponse> genChartByAiAsync(@RequestPart("file") MultipartFile multipartFile,GenChartByAiRequest genChartByAiRequest, HttpServletRequest request) {String name = genChartByAiRequest.getName();String goal = genChartByAiRequest.getGoal();String chartType = genChartByAiRequest.getChartType();// 校验ThrowUtils.throwIf(StringUtils.isBlank(goal), ErrorCode.PARAMS_ERROR, "目标为空");ThrowUtils.throwIf(StringUtils.isNotBlank(name) && name.length() > 100, ErrorCode.PARAMS_ERROR, "名称过长");// 校验文件long size = multipartFile.getSize();String originalFilename = multipartFile.getOriginalFilename();// 校验文件大小final long ONE_MB = 1024 * 1024L;ThrowUtils.throwIf(size > ONE_MB, ErrorCode.PARAMS_ERROR, "文件超过 1M");// 校验文件大小缀 aaa.pngString suffix = FileUtil.getSuffix(originalFilename);final List<String> validFileSuffixList = Arrays.asList("xlsx", "xls");ThrowUtils.throwIf(!validFileSuffixList.contains(suffix), ErrorCode.PARAMS_ERROR, "文件后缀非法");User loginUser = userService.getLoginUser(request);// 限流判断,每个用户一个限流器redisLimiterManager.doRateLimit("genChartByAi_" + loginUser.getId());// 指定一个模型id(把id写死,也可以定义成一个常量)long biModelId = 1659171950288818178L;// 分析需求:// 分析网站用户的增长情况// 原始数据:// 日期,用户数// 1号,10// 2号,20// 3号,30// 构造用户输入StringBuilder userInput = new StringBuilder();userInput.append("分析需求:").append("\n");// 拼接分析目标String userGoal = goal;if (StringUtils.isNotBlank(chartType)) {userGoal += ",请使用" + chartType;}userInput.append(userGoal).append("\n");userInput.append("原始数据:").append("\n");// 压缩后的数据String csvData = ExcelUtils.excelToCsv(multipartFile);userInput.append(csvData).append("\n");// 先把图表保存到数据库中Chart chart = new Chart();chart.setName(name);chart.setGoal(goal);chart.setChartData(csvData);chart.setChartType(chartType);// 插入数据库时,还没生成结束,把生成结果都去掉
// chart.setGenChart(genChart);
// chart.setGenResult(genResult);// 设置任务状态为排队中chart.setStatus("wait");chart.setUserId(loginUser.getId());boolean saveResult = chartService.save(chart);ThrowUtils.throwIf(!saveResult, ErrorCode.SYSTEM_ERROR, "图表保存失败");// 在最终的返回结果前提交一个任务// todo 建议处理任务队列满了后,抛异常的情况(因为提交任务报错了,前端会返回异常)CompletableFuture.runAsync(() -> {// 先修改图表任务状态为 “执行中”。等执行成功后,修改为 “已完成”、保存执行结果;执行失败后,状态修改为 “失败”,记录任务失败信息。(为了防止同一个任务被多次执行)Chart updateChart = new Chart();updateChart.setId(chart.getId());// 把任务状态改为执行中updateChart.setStatus("running");boolean b = chartService.updateById(updateChart);// 如果提交失败(一般情况下,更新失败可能意味着你的数据库出问题了)if (!b) {handleChartUpdateError(chart.getId(), "更新图表执行中状态失败");return;}// 调用 AIString result = aiManager.doChat(biModelId, userInput.toString());String[] splits = result.split("【【【【【");if (splits.length < 3) {handleChartUpdateError(chart.getId(), "AI 生成错误");return;}String genChart = splits[1].trim();String genResult = splits[2].trim();// 调用AI得到结果之后,再更新一次Chart updateChartResult = new Chart();updateChartResult.setId(chart.getId());updateChartResult.setGenChart(genChart);updateChartResult.setGenResult(genResult);updateChartResult.setStatus("succeed");boolean updateResult = chartService.updateById(updateChartResult);if (!updateResult) {handleChartUpdateError(chart.getId(), "更新图表成功状态失败");}},threadPoolExecutor);BiResponse biResponse = new BiResponse();
// biResponse.setGenChart(genChart);
// biResponse.setGenResult(genResult);biResponse.setChartId(chart.getId());return ResultUtils.success(biResponse);
}
// 上面的接口很多用到异常,直接定义一个工具类
private void handleChartUpdateError(long chartId, String execMessage) {Chart updateChartResult = new Chart();updateChartResult.setId(chartId);updateChartResult.setStatus("failed");updateChartResult.setExecMessage(execMessage);boolean updateResult = chartService.updateById(updateChartResult);if (!updateResult) {log.error("更新图表失败状态失败" + chartId + "," + execMessage);
}