目录
一、理论
一个例子:
二、代码
对于代码的解释:
1.fit函数:
2.predict函数:
三、实验结果
原因分析:
一、理论
朴素贝叶斯分类器基于贝叶斯定理进行分类,通过后验概率来判断将新数据归为哪一类。通过利用贝叶斯定理计算后验概率,并选择具有最高后验概率的类别作为预测结果,朴素贝叶斯分类器能够在考虑了先验概率和观察到的数据特征后,做出基于统计推断的分类决策,从而实现有效的分类。
步骤:
1.计算先验概率:先验概率表示了在没有任何其他信息的情况下,一个数据点属于每个类别的概率。
2.计算条件概率:条件概率表示了在给定某一类别的情况下,某个特征取某个值的概率。
3.计算后验概率:当有一个新的数据点需要分类时,朴素贝叶斯根据该数据点的特征值,利用贝叶斯定理计算每个类别的后验概率。后验概率表示了在考虑了新的观察结果后,每个类别的概率。
4.做出分类:根据计算得到的后验概率,选择具有最高后验概率的类别作为预测结果。
先验概率:
其中:ck是类别,D是数据数量,Dck是类别为ck的数据数量。
条件概率:
其中:Xi代表第i个特征,ai,j代表第i个特征中第j个类型,代表在类别为ck时,在第i个特征中的第j个类型的数量。
后验概率:
因为我们只需要分类,因为不同后验概率分母都相同,所以可以把分母去掉,只需要比较分子的大小即可,即:
其中:代表当前测试数据的每个类型为xi,在ck类别下的条件概率的连乘积。
可以看到公式简洁了不少。
一个例子:
假设数据集:
| 特征1 | 特征2 | 类别 |
|---|---|---|
| 1 | 1 | A |
| 1 | 0 | A |
| 0 | 1 | B |
| 0 | 1 | A |
| 1 | 0 | B |
现在预测一个特征1为1,特证2为1的测试元组是什么类别。
首先计算类别的先验概率和所有条件概率:
P(A)= 3/5,P(B)= 2/5
对于特征1:
P1(1∣A)= 2/3,P1(1 | B)= 1/2,
对于特征2:
P2(1 | A) = 2/3,P2(1 | B) = 1/2
然后计算预测为A和B的后验概率,并比较大小,得出结果
P(A|X) = P(A)*P1(1∣A)*P2(1 | A) = 4/15
P(B|X) = P(B)*P1(1 | B)*P2(1 | B) = 1/10
可以看到P(A|X)比较大,所以是A类
二、代码
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, f1_score, precision_score, recall_score class NaiveBayesClassifier:def __init__(self):self.class_prior = {} # 存储类别的先验概率self.feature_prob = {} # 存储特征在各个类别下的条件概率def fit(self, X, y):n_samples, n_features = X.shape # 获取样本数和特征数self.classes = np.unique(y) # 获取目标标签中的唯一类别值print("计算先验概率:")for c in self.classes:# 统计每个类别在目标标签中的出现次数,并除以样本总数,得到先验概率self.class_prior[c] = np.sum(y == c) / n_samplesprint("先验概率: 类别, 概率 "+repr(c)+" "+repr(self.class_prior[c]))# 外层循坏遍历类别,内层循环遍历每个特征,内层循环每次要计算出每个特征下不同取值的在当前类别下的条件概率,存放到[c][feature_index]下print("计算条件概率:")for c in self.classes:self.feature_prob[c] = {} # 初始化存储特征条件概率的字典for feature_index in range(n_features):# 对于每个特征,统计在当前类别下的取值及其出现次数,并除以总次数,得到条件概率# values是feature_index列中不同的取值,counts是这些不同取值的个数(在类别为C下的)values, counts = np.unique(X[y == c, feature_index], return_counts=True)self.feature_prob[c][feature_index] = dict(zip(values, counts / np.sum(counts)))#dict是变为以values和counts/np.sum的字典,zip就是一个方便的操作for i in range(len(counts)):print("条件概率:P(" + repr(values[i]) + "|" + repr(c) + ") = " + repr(self.feature_prob[c][feature_index][values[i]]))def predict(self, X):predictions = [] # 存储预测结果的列表#对于测试集中的每个元素cnt = 0for x in X:print("\n对于第" + repr(cnt) + "个测试集:")cnt+=1max_posterior_prob = -1 # 最大后验概率初始化为-1predicted_class = None # 预测类别初始化为空#对于每个类别for c in self.classes:# 计算后验概率,先验概率乘以各个特征的条件概率posterior_prob = self.class_prior[c]print("对于类别"+repr(c)+" = "+"[先验"+repr(self.class_prior[c])+"]", end = '')#对于每个特征for feature_index, feature_value in enumerate(x):if feature_value in self.feature_prob[c][feature_index]:print(" * [P("+ repr(feature_value) + "|" + repr(c) + ") = " + repr(self.feature_prob[c][feature_index][feature_value]) + "]", end = '')posterior_prob *= self.feature_prob[c][feature_index][feature_value]else:print(" * 1")# 更新预测值print(" = " + repr(posterior_prob))if posterior_prob > max_posterior_prob:max_posterior_prob = posterior_probpredicted_class = cpredictions.append(predicted_class) # 将预测结果添加到列表中return predictions # 返回预测结果列表data = {'outlook': ['sunny', 'sunny', 'overcast', 'rain', 'rain', 'rain', 'overcast', 'sunny', 'sunny', 'rain', 'rain', 'overcast', 'overcast', 'rain'],'temperature': ['hot', 'hot', 'hot', 'mild', 'cool', 'cool', 'cool', 'mild', 'cool', 'mild', 'mild', 'mild', 'hot', 'mid'],'humidity': ['high', 'high', 'high', 'high', 'normal', 'normal', 'normal', 'high', 'normal', 'normal', 'normal', 'high', 'normal', 'high'],'wind': ['weak', 'strong', 'weak', 'weak', 'weak', 'strong', 'strong', 'weak', 'weak', 'weak', 'strong', 'strong', 'weak', 'strong'],'playtennis': ['no', 'no', 'yes', 'yes', 'yes', 'no', 'yes', 'no', 'yes', 'yes', 'yes', 'yes', 'yes', 'no']
}
#创建DataFrame
df = pd.DataFrame(data)
X = df.drop('playtennis', axis=1)#axis=1删除列,=0删除行
y = df['playtennis']# 将数据集分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=3)
X_train = X_train.values#化为二维数组,便于遍历
X_test = X_test.values
y_train = y_train.values
y_test = y_test.valuesprint("训练集:")
for i in range(len(y_train)):print(repr(i)+": "+repr(X_train[i])+" "+repr(y_train[i]))
print("测试集:")
for i in range(len(y_test)):print(repr(i)+": "+repr(X_test[i])+" "+repr(y_test[i]))nb_classifier = NaiveBayesClassifier()
nb_classifier.fit(X_train, y_train)y_pred = nb_classifier.predict(X_test)
print("预测结果:")
for i in range(len(y_pred)):print(repr(i)+"正确,预测: "+repr(y_test[i])+", "+repr(y_pred[i]))accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred, pos_label='yes')
recall = recall_score(y_test, y_pred, pos_label='yes')
f1 = f1_score(y_test, y_pred, pos_label='yes')
print("准确率:", accuracy)
print("精确率:", precision)
print("召回率:", recall)
print("f1:", f1)
对于重要代码的解释:
1.fit函数:
训练测试集的主要代码,先把训练集中所有的条件概率和先验概率算出来,在后面的预测中会使用到。
先验概率:
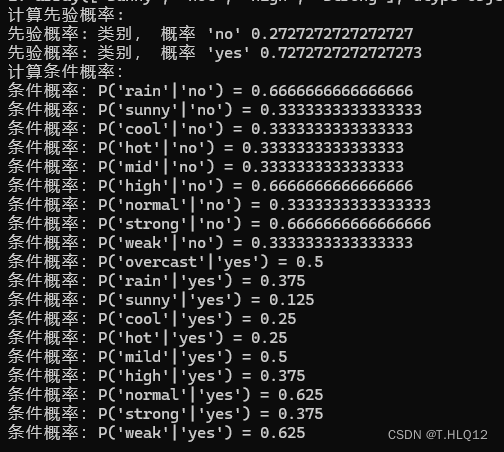
print("计算先验概率:")for c in self.classes:# 统计每个类别在目标标签中的出现次数,并除以样本总数,得到先验概率self.class_prior[c] = np.sum(y == c) / n_samplesprint("先验概率: 类别, 概率 "+repr(c)+" "+repr(self.class_prior[c]))所有条件概率:
print("计算条件概率:")for c in self.classes:self.feature_prob[c] = {} # 初始化存储特征条件概率的字典for feature_index in range(n_features):# 对于每个特征,统计在当前类别下的取值及其出现次数,并除以总次数,得到条件概率# values是feature_index列中不同的取值,counts是这些不同取值的个数(在类别为C下的)values, counts = np.unique(X[y == c, feature_index], return_counts=True)self.feature_prob[c][feature_index] = dict(zip(values, counts / np.sum(counts)))for i in range(len(counts)):print("条件概率:P(" + repr(values[i]) + "|" + repr(c) + ") = " + repr(self.feature_prob[c][feature_index][values[i]]))
结果:
2.predict函数:
这个函数用于测试集的预测,对于测试集中的每个元组,都要对于所有类别,计算一次该类别下的后验概率,然后选择所有类别中后验概率最大的,作为预测结果,而每个后验概率,通过该元组下的每个特征下的类型对应的条件概率的累乘和该类别的先验概率的乘积来确定。
对于每个元组:
for x in X:print("\n对于第" + repr(cnt) + "个测试集:")cnt+=1max_posterior_prob = -1 # 最大后验概率初始化为-1predicted_class = None # 预测类别初始化为空对于每个类别:
for c in self.classes:posterior_prob = self.class_prior[c]对于每个特征:
for feature_index, feature_value in enumerate(x):if feature_value in self.feature_prob[c][feature_index]:print(" * [P("+ repr(feature_value) + "|" + repr(c) + ") = " + repr(self.feature_prob[c][feature_index][feature_value]) + "]", end = '')posterior_prob *= self.feature_prob[c][feature_index][feature_value]else:print(" * 1")每次计算完后,维护最大值以及类型:
if posterior_prob > max_posterior_prob:max_posterior_prob = posterior_probpredicted_class = c每个元组计算完后,添加到预测数组中,最后返回预测数组即可。
三、实验结果
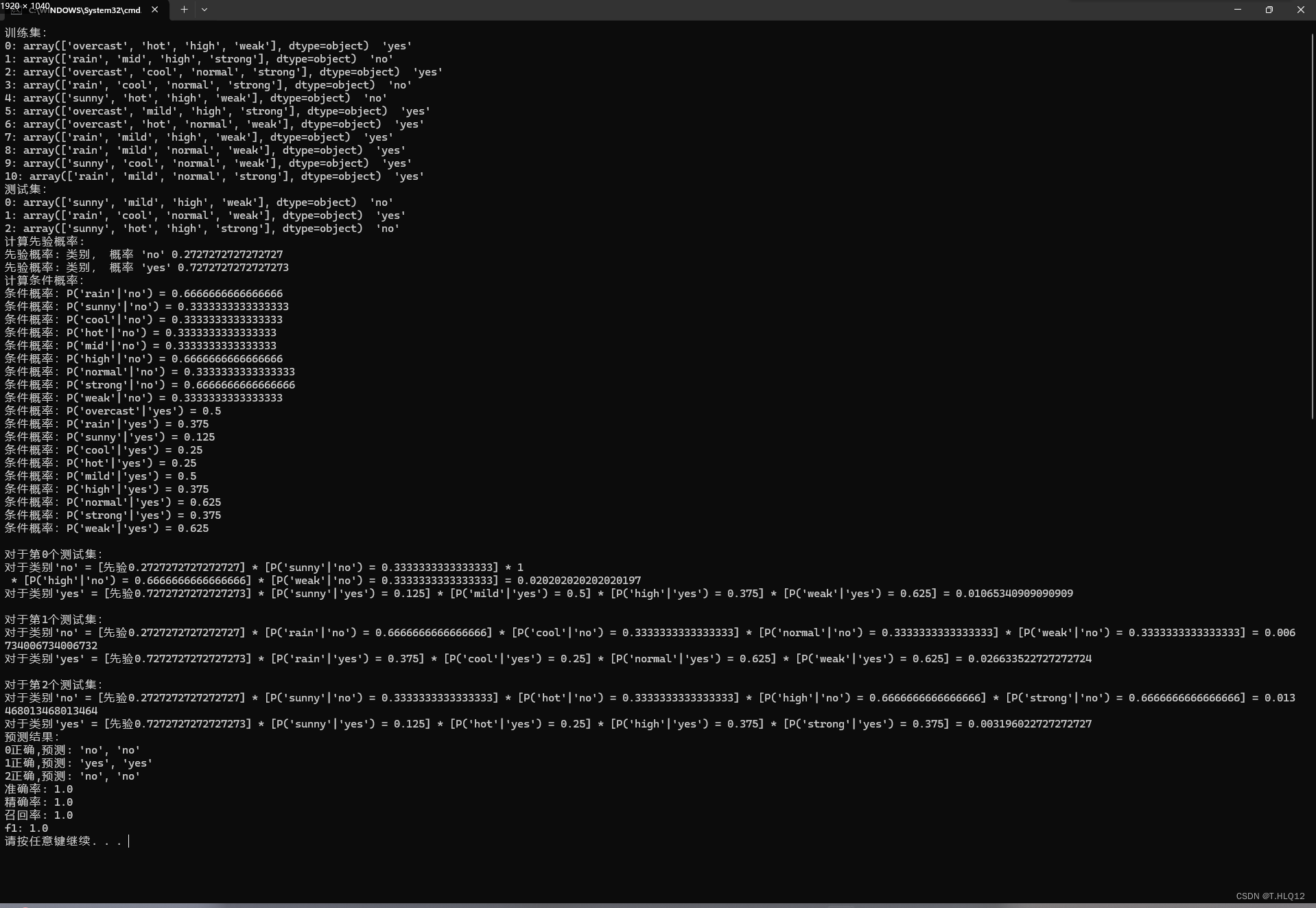
上图是最好的一个实验结果,所有指标为1,其他的实验结果准确率较低
原因分析:
这个训练集数据过小,但是特征和每个特征中的类型又比较多,再加上测试集一共就13条,数据使用不同的随机种子会使得一些测试集中的特征在不同类别下的条件概率没有出现过,因为没有出现过,直接就不处理这个特征了,就容易出现误差。
例如:
当随机种子为1时:

当随机种子为4时:

朴素贝叶斯分类器优缺点分析:
优点:
-
适用广:朴素贝叶斯算法在处理大规模数据时表现良好,适用于许多实际问题。
-
对小规模数据表现良好:即使在小规模数据集上,朴素贝叶斯分类器也能有好的结果。
-
对缺失数据不敏感:朴素贝叶斯算法对缺失数据不敏感,即使有部分特征缺失或者未出现,仍然可以有效地进行分类。
缺点:
-
假设过于简化:朴素贝叶斯假设特征之间相互独立,在现实中,数据一般难以是真正独立的,因此会导致结果不准确。
-
处理连续性特征较差:朴素贝叶斯算法通常假设特征是离散的,对于连续性特征的处理不够灵活,可能会影响分类性能。
![[通用人工智能] 论文分享:ElasticViT:基于冲突感知超网的快速视觉Transformer](https://img-blog.csdnimg.cn/direct/cd26178d936e468fa0002af1e1809778.png)