引言
缓存的意义
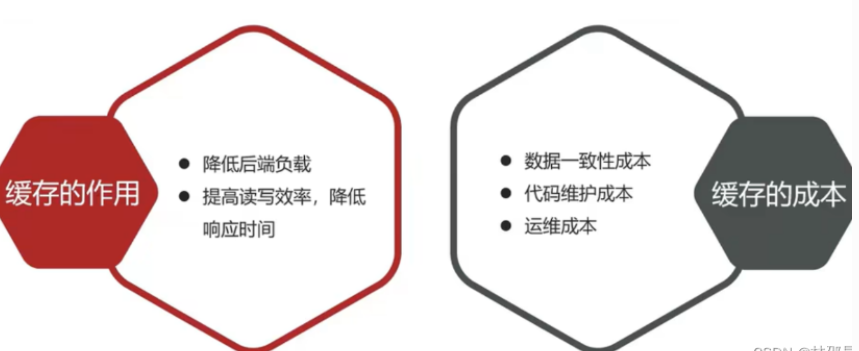
Redis作为一个NoSql数据库,被广泛的当作缓存数据库使用,所谓缓存,就是数据交换的缓冲区。使用缓存的具体原因有:
- 缓存数据存储于代码中,而代码运行在内存中,内存的读写性能远高于磁盘,通过缓存,可以大大降低用户访问并发量带来的服务器读写压力。
- 实际开发过程中,企业的数据量,少则几十万,多则上千万,如此大的数据量,如果没有缓存来作为“避震器”,系统是几乎撑不住的,所以企业会大量运用缓存技术。
缓存的分类
对于缓存,我们可以分为以下几类:
- 浏览器缓存:主要存在于浏览器端的缓存
- 应用层缓存:本地缓存(比如tomcat本地缓存)或缓存数据库(比如redis)
- 数据库缓存:在数据库中有一片空间是buffer pool,增删改查数据都会先加载到mysql的缓存中
- CPU缓存:当代计算机最大的问题是 cpu性能提升了,但内存读写速度没有跟上,所以为了适应当下的情况,增加了cpu的L1,L2,L3级的缓存
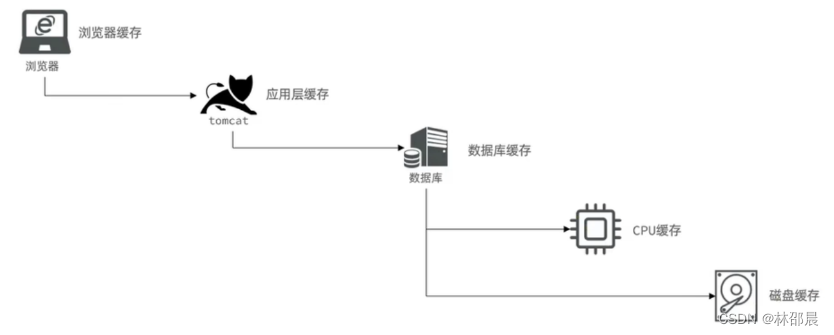
缓存模型
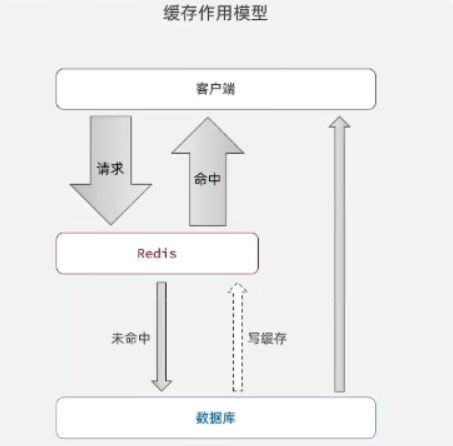
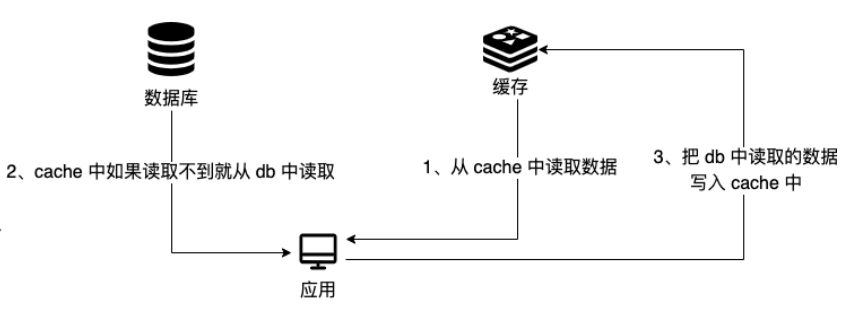
查询、添加缓存
一般情况下,在查询数据库之前,先查询缓存,如果缓存数据存在,就直接返回缓存数据,如果不存在,查询数据库,并将数据存入redis,具体的模型如下:
缓存淘汰
内存的空间是有限的,当我们向redis存储太多数据时,redis会对部分数据进行淘汰,淘汰数据的场景有:
- 内存淘汰:Redis自动进行,当redis内存达到设定的max-memery时,会自动触发淘汰机制,淘汰掉一些不重要的数据。
- 超时剔除:当对redis设置了过期时间TTL时,Redis会将超时的数据进行删除。
- 主动更新:通过手动调用方法把缓存删除掉,常用于解决缓存与数据库不一致的问题。
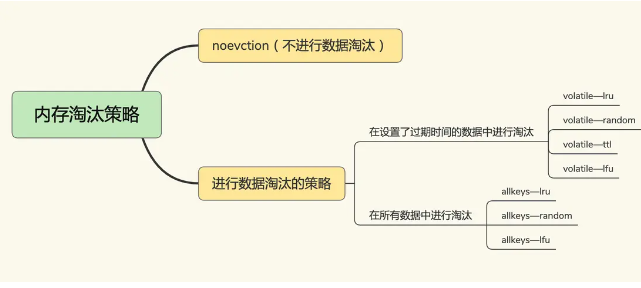
Redis自动进行内存淘汰时,主要有6+2种数据淘汰机制,可以分为以下三大类:
- 不淘汰数据
- noeviction ,不进行数据淘汰,当缓存被写满后,Redis不提供服务直接返回错误。
- 在设置过期时间的键值对中,
- volatile-random ,在设置过期时间的键值对中随机删除
- volatile-ttl ,在设置过期时间的键值对,基于过期时间的先后进行删除,越早过期的越先被删除。
- volatile-lru , 基于LRU(Least Recently Used) 算法筛选设置了过期时间的键值对, 最近最少使用的原则来筛选数据
- volatile-lfu ,使用 LFU( Least Frequently Used ) 算法选择设置了过期时间的键值对, 使用频率最少的键值对,来筛选数据。
- 在所有键值对中
- allkeys-random, 从所有键值对中随机选择并删除数据
- allkeys-lru, 使用 LRU 算法在所有数据中进行筛选
- allkeys-lfu, 使用 LFU 算法在所有数据中进行筛选
数据库缓存不一致解决方案
因为我们的缓存数据来自于数据库,而数据库的数据会随业务的需要而发生变化,当数据库中的数据变化,而缓存没有同步该数据,此时便会产生一致性问题。具体的解决策略有:
Cache Aside Pattern(旁路缓存模式)
该模式是平时使用比较多的一个缓存读写模式,比较适合读请求比较多的场景,在该模式中,需要同时维系db和cache,并且以db的结果为准。
写
先更新db,然后再直接删除cache
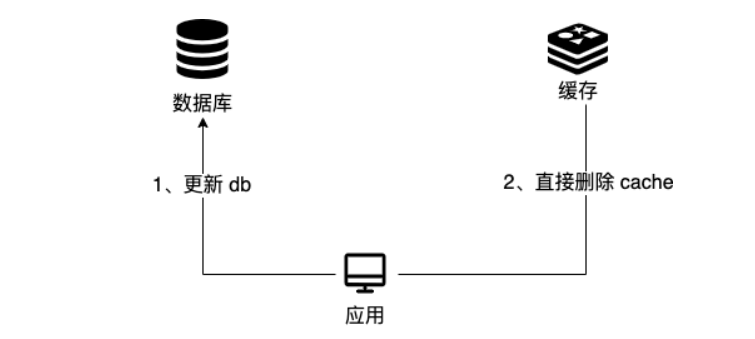
注意,不能先删除cache,在写db,因为在并发的情况下,可能存在,请求1删除缓存,然后写db,并且写db操作还没结束,这时请求2获取缓存,此时因为缓存被删除了,因此会从数据库读数据, 并存入缓存,这个时候的数据是未更新的,当请求2结束后,请求1写db结束,此时就会造成数据库和缓存中的数据不一致。

旁路缓存理论上来说,也会造成数据库和缓存不一致的问题,比如:请求 1 先写数据 A,请求 2 随后读数据 A 的话,就很有可能产生数据不一致性的问题。
这个过程可以简单描述为:

但这种概率很小,因为缓存的写入速度比数据库的写入速度快很多。
读
从cache中读取数据,读取到就直接返回。如果读取不到,从db中读取数据返回,然后再把数据放到cache中。
Cache Aside Pattern的缺陷
- 首次请求数据一定不在cache:这种情况可以先将热点数据提前放入cache中。
- 写操作比较频繁,会导致cache的数据被频繁删除,影响缓存命中率:更新db的时候同时更新cache,但是给缓存设置一个比较短的过期时间,保证即使数据不一致的话,影响也比较小。
Read/Write Through Pattern(读写穿透)
服务端把 cache 视为主要数据存储,从中读取数据并将数据写入其中。cache 服务负责将此数据读取和写入 db,从而减轻了应用程序的职责。这种策略比较少使用,因为Redis并没有提供cache将数据写入db的功能。
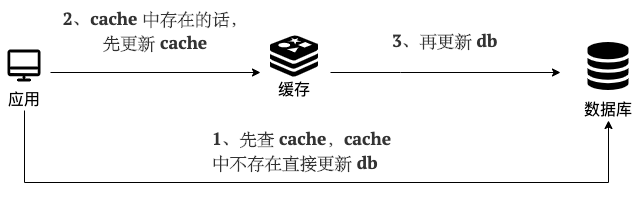
写(Write Through)
- 先查 cache,cache 中不存在,直接更新 db。
- cache 中存在,则先更新 cache,然后 cache 服务自己更新 db(同步更新 cache 和 db)。
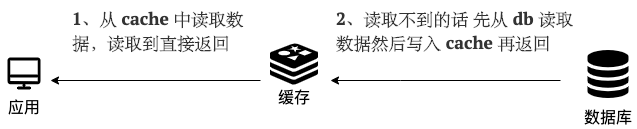
读(Read Through)
- 从 cache 中读取数据,读取到就直接返回 。
- 读取不到的话,先从 db 加载,写入到 cache 后返回响应。
缺陷
- 实现困难,如Redis并没有提供cache将数据写入db的功能
- 和Cache Aside Pattern一样,首次请求数据一定不在cache中
Write Behind Pattern(异步缓存写入)
与Read/Write Through Pattern相似,都是由cache服务来负责cache和db的读写,但是,Read/Write Through是同步更新cache和db,而Write Behind是只更新缓存,不直接更新db,改为异步批量的方式,更新db。
这种方式对数据一致性带来了更大的挑战,比如 cache 数据可能还没异步更新 db 的话,cache 服务可能就就挂掉了。这种策略在我们平时开发过程中也非常非常少见,但是不代表它的应用场景少,比如消息队列中消息的异步写入磁盘、MySQL 的 Innodb Buffer Pool 机制都用到了这种策略。
Write Behind Pattern 下 db 的写性能非常高,非常适合一些数据经常变化又对数据一致性要求没那么高的场景,比如浏览量、点赞量。
缓存常见的问题
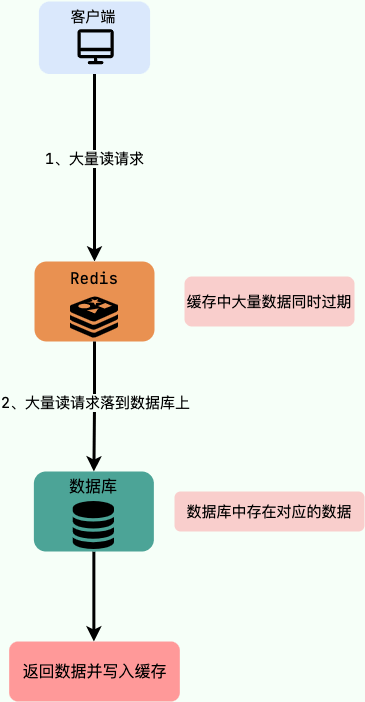
缓存雪崩
缓存雪崩,指缓存在同一时间大面积的生效(比如缓存数据过期),导致大量的请求都直接落到数据库上,给数据库造成了巨大的压力。此外,如果缓存服务器宕机也会导致缓存雪崩现象,导致所有的请求都落到了数据库上。
解决方法有:
- 采用Redis集群,避免单机出现问题导致整个缓存服务器无法使用。
- 限流,避免同时处理大量请求。
- 多级缓存,比如本地缓存+Redis缓存的组合,当Redis缓存出现问题时,可以从本地缓存中获取部分数据。
- 设置不同的生效时间比如随机设置缓存的失效时间。
- 缓存永不生效。
- 缓存预热,在程序启动后或运行过程中,主动将热点数据加载到缓存中。
缓存穿透
缓存穿透指大量请求的key是不合理的,根本不存在与缓存和数据库中,这就导致这些请求直接到了数据库,给数据库造成巨大压力。比如黑客故意制造一些非法的key发起大量请求,导致大量请求落到数据库,结果数据库上也没有查到对应的数据。
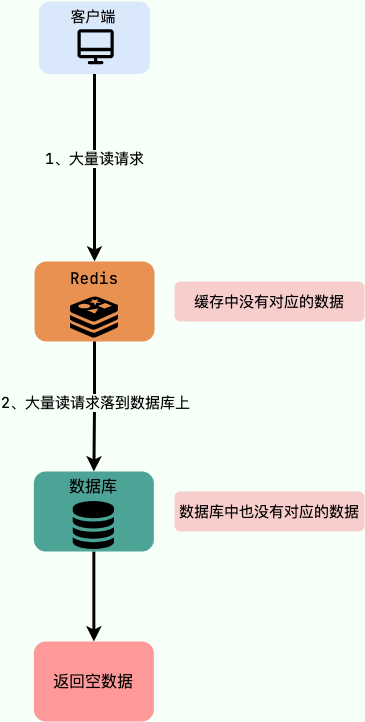
解决方法:
- 参数校验:对不合法的参数请求,直接抛出异常信息给客户端,比如查询的数据库id不能为0,手机格式不正确等。
- 缓存无效key:将这些无效的key设置到缓存中,并设置一个较短的过期时间。这种方法可以解决请求的key变化不频繁的情况。
- 接口限流。
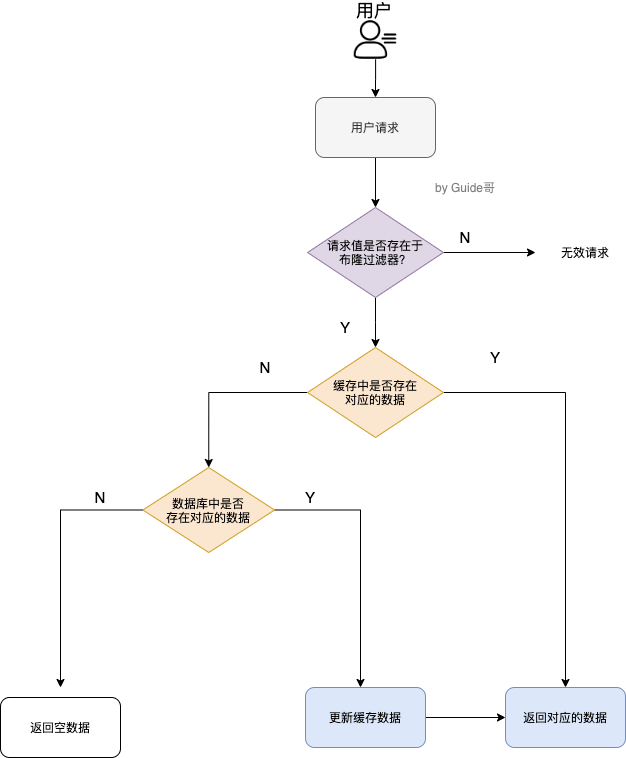
- 布隆过滤器:通过布隆过滤器判断一个给定数据是否存在于海量数据中。具体做法是:把所有可能存在的请求的值都存放在布隆过滤器中,当用户请求过来,先判断用户发来的请求的值是否存在于布隆过滤器中。不存在的话,直接返回请求参数错误信息给客户端,存在的话才会走下面的流程。
缓存击穿
缓存击穿,指请求的key对应的是热点数据,该数据存在于数据库中,但是不存在于缓存中(通常是因为缓存中的数据已经过期),这就会导致瞬时大量请求直接打到了数据库上,对数据库造成巨大压力。比如秒杀进行过程中,缓存中的某个秒杀商品数据过期,导致瞬时大量对该商品的请求直接落到数据库上,对数据库造成巨大压力。
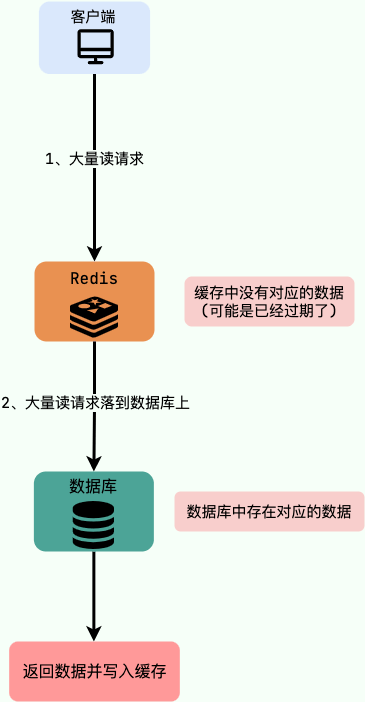
解决方法:
SpringBoot整合Redis实现缓存
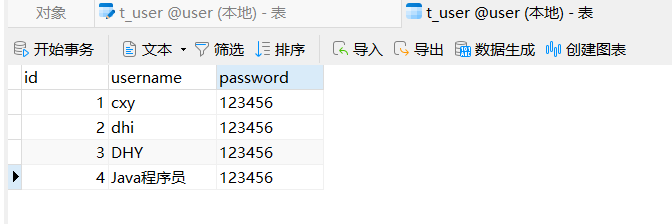
准备数据库数据
首先我们创建一个t_user表,并插入几条数据,用于后续的查询:
读缓存
创建User类和对应的UserMapper
@TableName(value = "t_user")
@Data
public class User implements Serializable {@TableId(type = IdType.AUTO)private Integer id;private String username;private String password;
}@Mapper
public interface UserMapper extends BaseMapper<User> {
}
UserService
@Service
public class UserService {// 过期时间private long ttl = 100L;@Autowiredprivate UserMapper userMapper;@Autowiredprivate RedisUtils redisUtils;public User getUserById(Integer id) {String key = "user:" + id;Object value = redisUtils.getKey(key);if (value != null) {// 缓存中存在该数据return (User) value;}// 缓存中不存在该数据, 从数据库中查询User userFromDB = getUserFromDB(id);if (userFromDB == null) {return null;}redisUtils.addKey(key, userFromDB, ttl);return userFromDB;}private User getUserFromDB(Integer id) {System.out.println("从数据库中查询====================");return userMapper.selectById(id);}
}添加一个测试方法:
package org.example;import org.example.pojo.User;
import org.example.service.UserService;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;@SpringBootTest
public class RedisCacheTest {@Autowiredprivate UserService userService;@Testpublic void testGetUserById() {User userById = userService.getUserById(1);System.out.println(userById);userById = userService.getUserById(1);System.out.println(userById);}
}执行测试方法,结果如下:

从上述内容中,可以看出,第一次查询时,因为数据不存在于缓存中,所以会查询数据库,第二次查询时,从缓存中查询到数据,直接返回。
但是这里涉及到一个序列化的问题,我们通过下载一些redis桌面可视化工具,查看这些数据,发现这些key和value都有一些奇怪的编码,如下图所示:
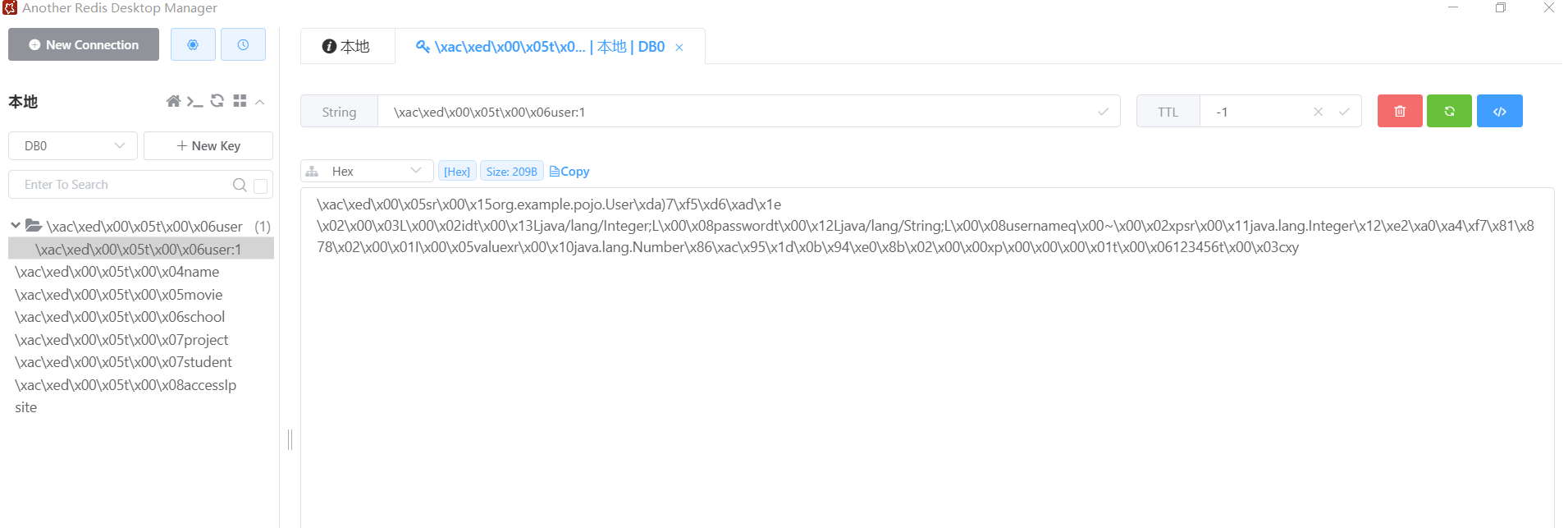
这是因为,默认情况下,redisTemplate使用JDK的序列化器(JdkSerializationRedisSerializer)对存储的对象进行序列哈和反序列化操作,这可能导致序列化结果不可读或占用较多的存储空间。因此,我们需要在配置redisTemplate的时候,设置对应的序列化器,我们修改上一章的RedisConfiguration类,修改结果如下:
package org.example.config;import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;@Configuration
public class RedisConfiguration {@Beanpublic RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();redisTemplate.setConnectionFactory(redisConnectionFactory);StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);ObjectMapper objectMapper = new ObjectMapper().enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);jackson2JsonRedisSerializer.setObjectMapper(objectMapper);// 设置key的序列化器为StringRedisSerializerredisTemplate.setKeySerializer(stringRedisSerializer);// 设置value的序列化器为Jackson2JsonRedisSerializerredisTemplate.setValueSerializer(jackson2JsonRedisSerializer);// 设置hash key的序列化器为StringRedisSerializerredisTemplate.setHashKeySerializer(stringRedisSerializer);// 设置hash value的序列化器为Jackson2JsonRedisSerializerredisTemplate.setHashValueSerializer(jackson2JsonRedisSerializer);// 完成其他配置后,初始化RedisTemplateredisTemplate.afterPropertiesSet();return redisTemplate;}
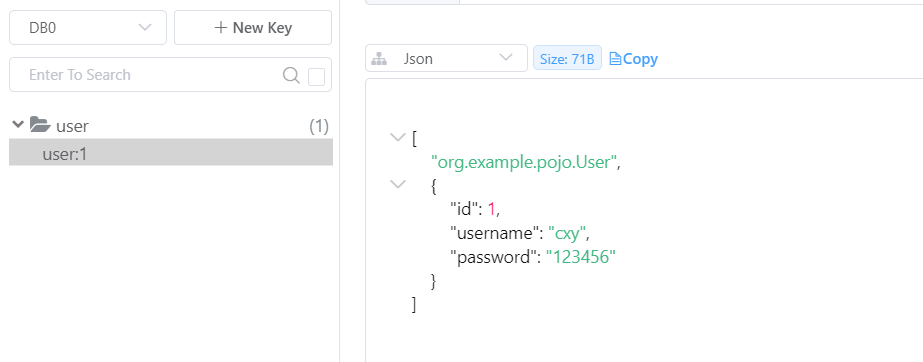
}我们将之前那些key全部删除掉,然后重新运行测试代码,结果如下:

通过redis可视化工具,也能清楚地看到每个key和value的结构和信息。
上面的代码,存在一些问题,当请求1查询id=1的用户,从缓存中查询不到时,会查询数据库,然后将数据更新到数据库,然后请求2查询id=1的用户,从缓存中查询到,便直接返回,这是理想的情况。但是,可能请求1查询数据库还没执行完,请求2过来了,此时缓存中没有id=1的用户,因此请求2也会去查询数据库。
比如我们修改getUserFromDB,加上Thread.sleep(2000),模拟数据库的查询较慢,然后修改测试代码,模拟多个请求同时查询id=1的用户的情况:
@Testpublic void testGetUserById() throws ExecutionException, InterruptedException {ExecutorService executorService = Executors.newFixedThreadPool(2);Callable<User> getUserTask = () -> userService.getUserById(1);Future<User> submit1 = executorService.submit(getUserTask);Future<User> submit2 = executorService.submit(getUserTask);System.out.println(submit1.get());System.out.println(submit2.get());}
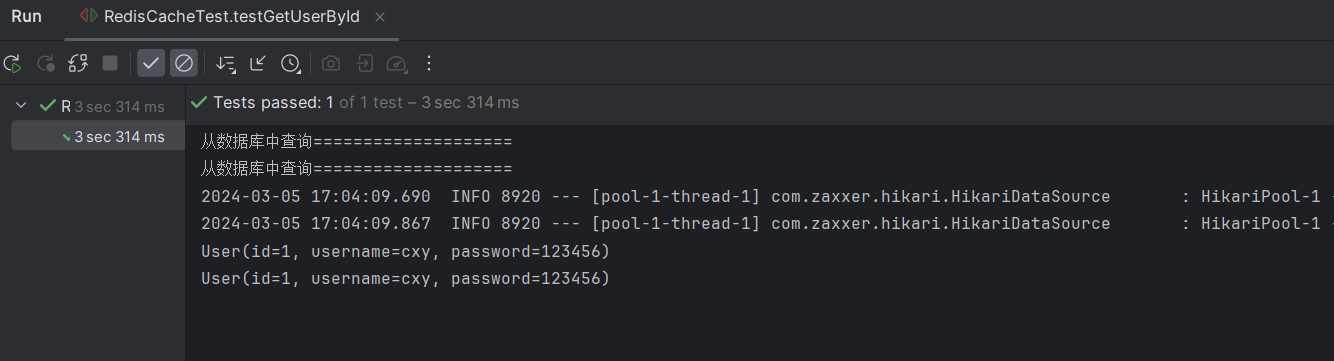
此时再次执行测试代码,结果如下:
解决上面的情况,方式就是加锁,我们修改UserService的代码如下,这里通过synchronized加锁,然后锁的对象使用key,这样可以将锁的粒度缩小一点。
public User getUserById(Integer id) {String key = "user:" + id;Object value = redisUtils.getKey(key);if (value != null) {// 缓存中存在该数据return (User) value;}User userFromDB = null;synchronized (key.intern()) {// 再次查询缓存value = redisUtils.getKey(key);if (value != null) {return (User) value;}// 缓存中不存在该数据, 从数据库中查询userFromDB = getUserFromDB(id);if (userFromDB == null) {return null;}redisUtils.addKey(key, userFromDB, ttl);}return userFromDB;}private User getUserFromDB(Integer id) {try {Thread.sleep(2000);} catch (Exception e) {e.printStackTrace();}System.out.println("从数据库中查询====================");return userMapper.selectById(id);}
重新运行测试方法,结果如下:

通过加锁,可以解决被访问多次的情况,但是这样的锁有一个问题,这个锁,只适用于单机的情况,当我们的服务部署在多台服务器上时,这些服务器上的应用,对应的JVM都不同,因此锁住的,不是同一个对象,后续会单独对分布式锁进行讲解,这里先不予讨论。
更新缓存
修改userService,添加修改用户的方法
public void updateUser(UpdateUserRequest updateUserRequest) {if (updateUserRequest.getId() == null) {return;}User user = getUserById(updateUserRequest.getId());if (user == null) {return;}if (StringUtils.isNotEmpty(updateUserRequest.getUsername())) {user.setUsername(updateUserRequest.getUsername());}if (StringUtils.isNotEmpty(updateUserRequest.getPassword())) {user.setPassword(updateUserRequest.getPassword());}// 先更新数据库int updateResult = userMapper.updateById(user);if (updateResult == 1) {// 更新成功,删除缓存redisUtils.removeKey("user:" + updateUserRequest.getId());}}
添加测试方法
@Testpublic void testUpdateUser() {UpdateUserRequest updateUserRequest = new UpdateUserRequest();updateUserRequest.setId(1);updateUserRequest.setPassword("12345");userService.updateUser(updateUserRequest);User userById = userService.getUserById(1);System.out.println(userById);}
测试结果如下

SpringBoot整合SpringCache+Redis
在上面的代码中,我们发现,和Redis查询的操作,和我们的业务代码糅合在一起, 不方便进行处理,如果后续我们缓存服务器从Redis改为其他缓存服务器,需要修改多处代码,不利于项目的扩展和维护。
SpringCache框架是Spring框架提供的一套基于注解的缓存解决方案,在应用程序中简化了缓存操作的管理和使用。它通过在方法上添加缓存注解,来实现自动缓存的功能,其常用注解有:
1)@Cacheable: 表示该方法返回结果可以被缓存,当方法被调用时,先检查缓存,如果缓存命中,直接返回缓存中的结果,不再执行方法体中的逻辑。
2) @CachePut:表示该方法的返回结果需要更新缓存,每次方法被调用后,都会将返回结果更新到缓存中。
3)@CacheEvit:表示该方法会清除缓存中的数据,可以用于在更新或删除数据时清除相应的缓存。
整合SpringCache
添加Spring Cache的依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-cache</artifactId></dependency>
在启动类上加上注解开启缓存
@SpringBootApplication
@EnableCaching
public class RedisApp {public static void main(String[] args) {SpringApplication.run(RedisApp.class, args);}
}测试Cacheable和CacheEvict
我们在userService类上,加上两个方法,用于测试Cacheable和CacheEvit注解。
添加getUserById2方法,该方法中的逻辑为查询数据库操作
@Cacheable(value = "user", key = "#id")public User getUserById2(Integer id) {System.out.println("从数据库中查询==============");return userMapper.selectById(id);}
然后添加一个测试方法
@Autowiredprivate UserService userService;@Testpublic void testGetUserById() {System.out.println(userService.getUserById2(1));System.out.println(userService.getUserById2(1));}
测试结果如下,第一次查询时,查询数据库,第二次直接查询缓存。

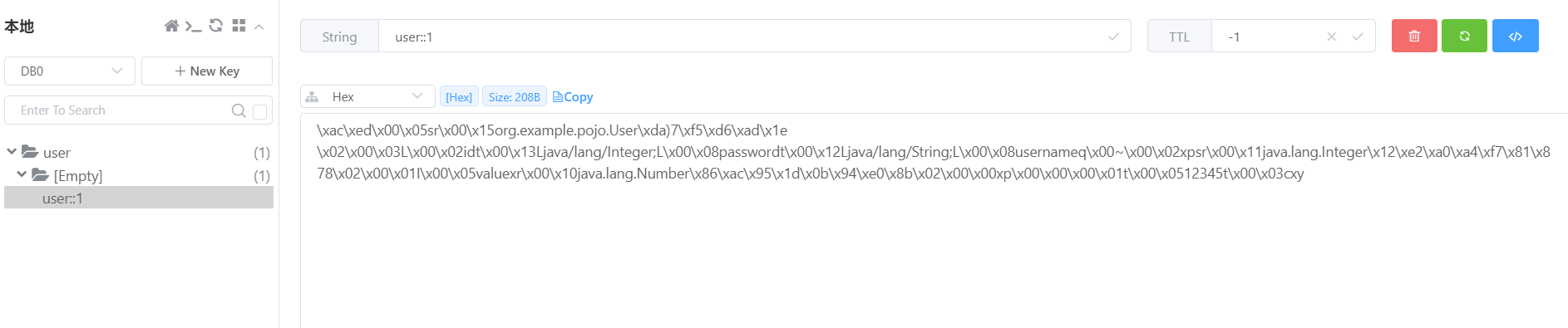
然后我们查看reids缓存,发现这个key的值是user::1,这个和我们之前定义的不太相同,而且没有过期时间,除此之外,这个value的值,序列化有问题
我们修改RedisConfiguration,添加RedisCacheConfiguration的相关配置
package org.example.config;import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.cache.RedisCacheConfiguration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.RedisSerializationContext;
import org.springframework.data.redis.serializer.StringRedisSerializer;import java.time.Duration;@Configuration
public class RedisConfiguration {@Beanpublic RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();redisTemplate.setConnectionFactory(redisConnectionFactory);StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);ObjectMapper objectMapper = new ObjectMapper().enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);jackson2JsonRedisSerializer.setObjectMapper(objectMapper);// 设置key的序列化器为StringRedisSerializerredisTemplate.setKeySerializer(stringRedisSerializer);// 设置value的序列化器为Jackson2JsonRedisSerializerredisTemplate.setValueSerializer(jackson2JsonRedisSerializer);// 设置hash key的序列化器为StringRedisSerializerredisTemplate.setHashKeySerializer(stringRedisSerializer);// 设置hash value的序列化器为Jackson2JsonRedisSerializerredisTemplate.setHashValueSerializer(jackson2JsonRedisSerializer);// 完成其他配置后,初始化RedisTemplateredisTemplate.afterPropertiesSet();return redisTemplate;}@Beanpublic RedisCacheConfiguration redisCacheConfiguration(){Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);ObjectMapper objectMapper = new ObjectMapper().enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);jackson2JsonRedisSerializer.setObjectMapper(objectMapper);//相当于new了一个RedisCacheConfigurationRedisCacheConfiguration configuration = RedisCacheConfiguration.defaultCacheConfig();configuration = configuration.serializeValuesWith// 指定value序列化器(RedisSerializationContext.SerializationPair.fromSerializer(jackson2JsonRedisSerializer))// 指定 key的TTL.entryTtl(Duration.ofSeconds(100))// 指定前缀.prefixCacheNameWith("user::");return configuration;}
}删除原先的缓存,然后重新运行测试代码,然后查看缓存信息,结果如下:
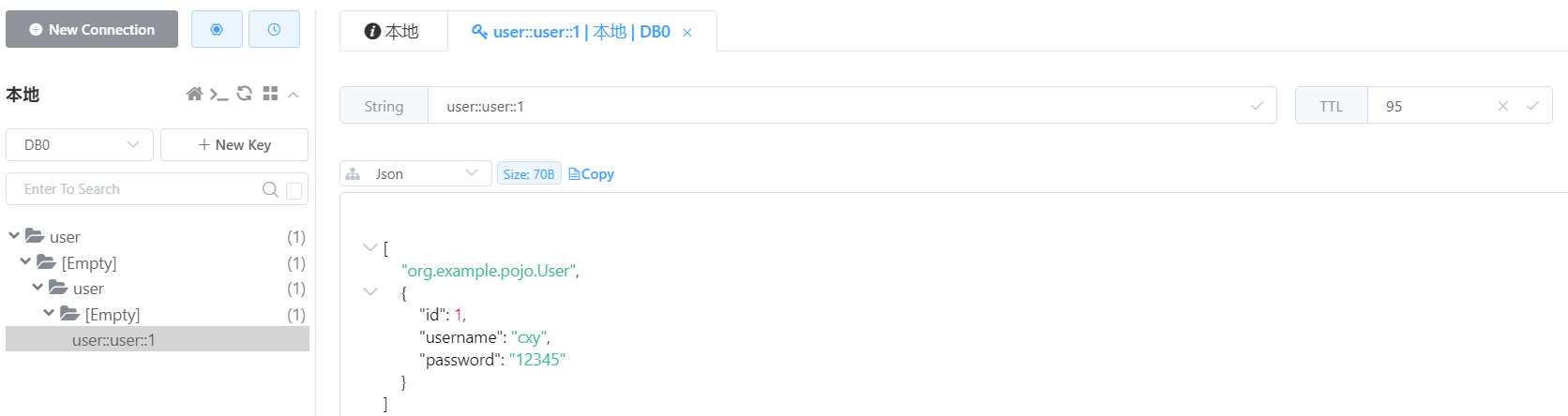
此时过期时间和序列化均设置成功。但这样配置还有一些问题,通过这种全局配置,所有cache key的TTL都一样,实际开发中,不同的cache key可能需要的TTL都不同,我们修改RedisConfiguration,为不同的key配置上不同的过期时间
package org.example.config;import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.boot.autoconfigure.cache.RedisCacheManagerBuilderCustomizer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.cache.RedisCacheConfiguration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.RedisSerializationContext;
import org.springframework.data.redis.serializer.StringRedisSerializer;import java.time.Duration;
import java.util.HashMap;
import java.util.Map;@Configuration
public class RedisConfiguration {@Beanpublic RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();redisTemplate.setConnectionFactory(redisConnectionFactory);StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);ObjectMapper objectMapper = new ObjectMapper().enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);jackson2JsonRedisSerializer.setObjectMapper(objectMapper);// 设置key的序列化器为StringRedisSerializerredisTemplate.setKeySerializer(stringRedisSerializer);// 设置value的序列化器为Jackson2JsonRedisSerializerredisTemplate.setValueSerializer(jackson2JsonRedisSerializer);// 设置hash key的序列化器为StringRedisSerializerredisTemplate.setHashKeySerializer(stringRedisSerializer);// 设置hash value的序列化器为Jackson2JsonRedisSerializerredisTemplate.setHashValueSerializer(jackson2JsonRedisSerializer);// 完成其他配置后,初始化RedisTemplateredisTemplate.afterPropertiesSet();return redisTemplate;}@Beanpublic RedisCacheManagerBuilderCustomizer redisCacheManagerBuilderCustomizer() {Jackson2JsonRedisSerializer<Object> jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer<>(Object.class);ObjectMapper objectMapper = new ObjectMapper().enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);jackson2JsonRedisSerializer.setObjectMapper(objectMapper);return (builder) -> {Map<String, RedisCacheConfiguration> cacheConfigurations = new HashMap<>();cacheConfigurations.put("user",RedisCacheConfiguration.defaultCacheConfig().entryTtl(Duration.ofSeconds(60)).serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(jackson2JsonRedisSerializer)));cacheConfigurations.put("product",RedisCacheConfiguration.defaultCacheConfig().entryTtl(Duration.ofSeconds(120)).serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(jackson2JsonRedisSerializer)));builder.withInitialCacheConfigurations(cacheConfigurations);};}}
运行结果如下:
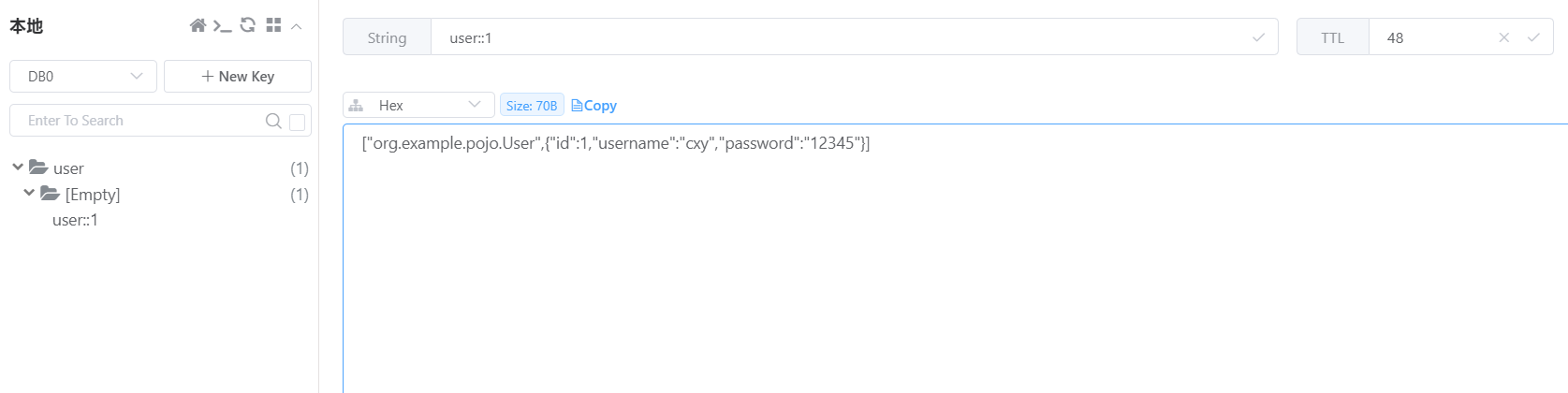
接着,我们测试CacheEvict,首先在userService中添加一个更新方法
@CacheEvict(value = "user", key = "#updateUserRequest.id")public void updateUser2(UpdateUserRequest updateUserRequest) {if (updateUserRequest.getId() == null) {return;}User user = getUserById2(updateUserRequest.getId());if (user == null) {return;}if (StringUtils.isNotEmpty(updateUserRequest.getUsername())) {user.setUsername(updateUserRequest.getUsername());}if (StringUtils.isNotEmpty(updateUserRequest.getPassword())) {user.setPassword(updateUserRequest.getPassword());}// 先更新数据库userMapper.updateById(user);}然后添加测试方法:
@Testpublic void testUpdateUser() {UpdateUserRequest updateUserRequest = new UpdateUserRequest();updateUserRequest.setId(1);updateUserRequest.setPassword("123456");userService.updateUser2(updateUserRequest);}