提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 摘要
- Abstract
- 文献阅读:在视频中使用时间卷积和半监督训练进行三维人体姿态估计
- 1、文献摘要
- 2、提出方法
- 2.1、时间扩张卷积模型
- 2.2、半监督方法
- 2.3、与传统方法的比较
- 2.4、对称卷积与随机卷积
- 3、实验结果
- 3.1、评判标准
- 3.2、评判结果
- 4、公式分析
- 4.1、加权均方误差 (Weighted Mean Per-Joint Position Error, WMPJPE)
- 4.2、扩张卷积 (Dilated Convolution)
- 4.3、 因果卷积 (Causal Convolution)
- 5、总结
- VideoPose3D项目
- 项目结构
- run.py脚本的解读
- 实验结果
- 总结
摘要
本周主要阅读了CVPR文章, 3D human pose estimation in video with temporal convolutions and semi-supervised training。这是一种基于二维关键点和扩张时间卷积的全卷积模型,用于有效估计视频中的三维人体姿态,除此之外,还提出了一种名为“反投影”的半监督训练方法,该方法能够利用未标记的视频数据来增强模型的学习效果,这一过程不仅提高了模型对未标记数据的利用效率,而且显著提升了学习性能。除了阅读文献之外,还学习了文献所包含的相关代码知识。
Abstract
This week, I mainly read the CVPR paper titled “3D human pose estimation in video with temporal convolutions and semi-supervised training.” This paper introduces a fully convolutional model based on dilated temporal convolutions over 2D keypoints, which is effective for estimating 3D human poses in videos. In addition to the model, the authors propose a semi-supervised training method known as “back-projection,” which leverages unlabeled video data to enhance the model’s learning efficacy. This approach not only improves the model’s utilization of unlabeled data but also significantly boosts its learning performance. Apart from the literature review, I also studied the code knowledge included in the paper.
文献阅读:在视频中使用时间卷积和半监督训练进行三维人体姿态估计
Title: 3D human pose estimation in video with temporal convolutions and semi-supervised training
Author:Dario Pavllo、Christoph Feichtenhofer、David Grangier、David Grangier
From:2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
1、文献摘要
文章介绍了一种基于二维关键点和扩张时间卷积的全卷积模型,用于有效估计视频中的三维人体姿态。此外,文章还提出了一种名为“反投影”的半监督训练方法,该方法能够利用未标记的视频数据来增强模型的学习效果。具体而言,反投影方法包括以下步骤:首先对未标记视频进行二维关键点预测;然后基于这些关键点估计三维姿态;最终,将估计的三维姿态信息反投射回原始的二维关键点,以此来优化预测结果。这一过程不仅提高了模型对未标记数据的利用效率,而且显著提升了学习性能。在有监督学习的设置下,所提出的全卷积模型在Human3.6M数据集上实现了平均每关节位置误差比先前最佳结果低6毫米的突破,这代表了约11%的错误率降低。同时,在HumanEva-I数据集上也观察到了明显的性能提升。此外,使用反投影方法的实验结果表明,即使在标注数据稀缺的情况下,该方法也能轻松超越以往半监督设置下的最佳成果,为三维姿态估计领域的发展提供了新的可能性。
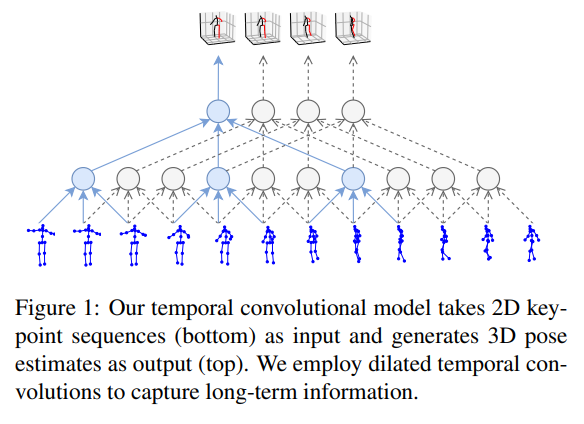
2、提出方法
2.1、时间扩张卷积模型
文章中提出时间扩张卷积模型的网络结构,该结构是一种基于卷积神经网络的3D人体姿态估计模型,该模型采用了一种全卷积架构,它以一连串的二维姿态作为输入,并通过时间卷积进行转换,能够处理序列输入并输出3D姿态。该模型还采用了残差连接和B-ResNet风格的块,这些块通过一个跳过连接进行包围。每个块首先进行1D卷积操作,然后进行卷积操作,其中卷积核大小为W,卷积因子为D = W B。此外,该模型还包括一个全局轨迹预测网络,用于预测相机空间的全局轨迹,将该轨迹添加到姿态后,再将其投影回2D。这两个网络具有相同的架构,但不共享权重。该模型需要相机的内参参数,这通常可从商业摄像机中获得。
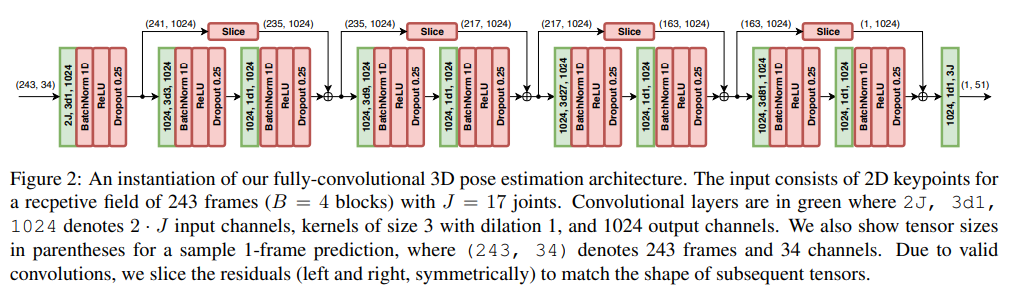
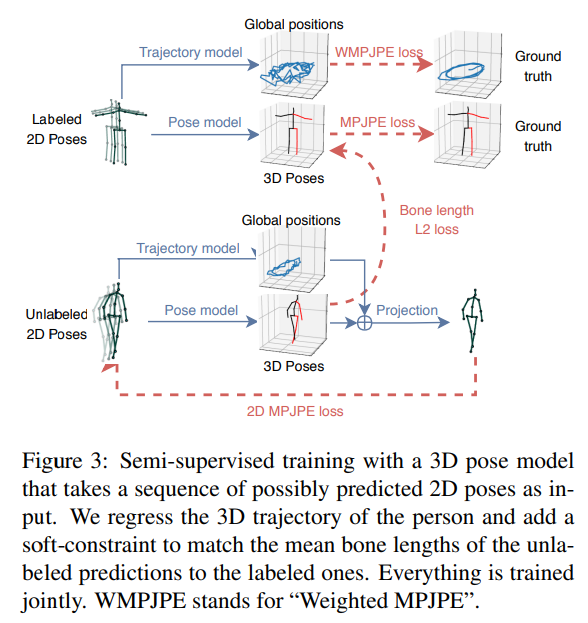
2.2、半监督方法
文章中的半监督方法是通过使用未标记的数据来训练模型,以提高模型的泛化能力和减少过拟合。具体来说,文中提到了一种半监督学习方法,即使用未标记的视频数据来训练模型。这种方法利用了未标记数据的丰富性,帮助模型更好地理解视频中的运动和变化,从而提高模型的性能。此外,文中还提到了一种半监督学习方法,即使用未标记的视频数据来训练模型。这种方法利用了未标记数据的丰富性,帮助模型更好地理解视频中的运动和变化,从而提高模型的性能。这两种方法都是半监督学习的一部分,它们利用了未标记数据的丰富性来提高模型的性能。
2.3、与传统方法的比较
对于人体姿态估计的方法,传统的方法需要根据以下方法来实现:一,通过特征工程等手工设计的特征来描述人体姿态。这些特征可能包括边缘、角点、纹理或基于模型的描述符;二,通过检测图像中的特定点(如关节或肢体的端点),并跟踪这些点在视频序列中随时间的变化;三,利用关于人体结构和关节约束的先验知识来推导姿态。这可能包括几何约束、运动学约束或概率模型。
文章提出的时间卷积及半监督方法方法在3D人体姿态估计任务中相比传统方法具有显著优势。该方法利用深度学习技术,特别是全卷积网络和扩张时间卷积,自动化地从视频中提取特征,并有效地利用时间序列信息来提高姿态估计的准确性。这种方法不仅减少了对手工设计特征的依赖,还通过端到端的学习框架简化了姿态估计的流程。此外,文章中提出的半监督学习方法——反投影,能够在标记数据受限的情况下提升模型性能,进一步增强了模型的泛化能力。在计算效率方面,该方法通过优化的卷积操作减少了计算资源的消耗,同时保持了高效的推理速度,这对于实时应用场景尤为重要。
2.4、对称卷积与随机卷积
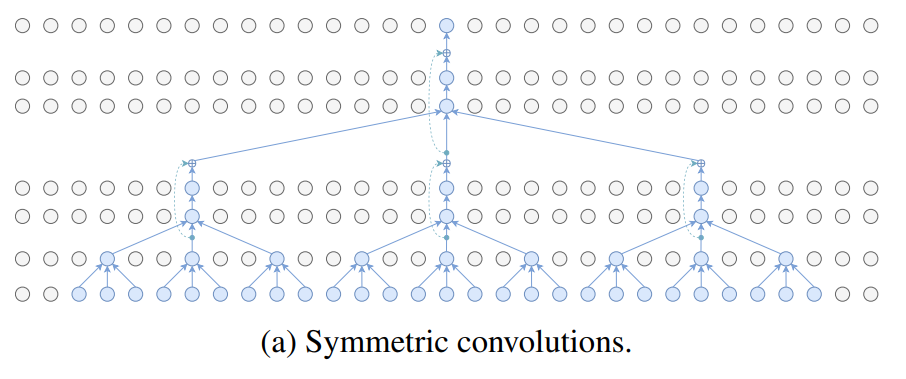
对称卷积:对称卷积是一种常规的卷积操作,它在序列数据的两侧应用相同的滤波器。这意味着滤波器不仅关注序列的当前位置,还关注过去和未来的相关信息。这种操作使得模型能够捕捉到序列中的长期依赖关系。然而,由于对称卷积需要考虑未来的信息,因此在处理时间序列数据时可能会产生一些问题,例如无法实时生成结果。
由于对称卷积考虑了序列数据的过去和未来信息,它在捕捉长期依赖关系方面可能更有效。这使得对称卷积在某些任务中可能获得更高的准确性和更好的性能。然而,由于其对未来信息的依赖,它可能不适合实时处理时间序列数据。对称卷积的计算复杂度与序列的长度成线性关系,因为它需要处理序列的全部长度。对于较长的序列,对称卷积的计算复杂度可能会较高。
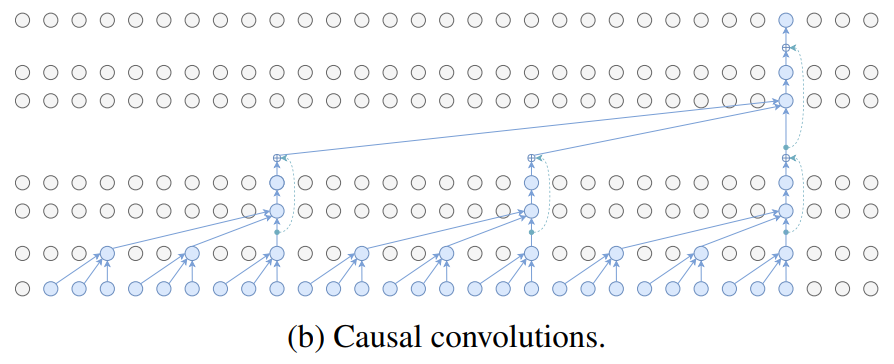
因果卷积是一种特殊的卷积操作,它只关注序列数据的过去信息,不考虑未来的数据。这种操作使得模型能够实时处理时间序列数据,因为每一步的输出都只依赖于过去的输入。然而,由于因果卷积不能获取未来的信息,因此它在捕捉长期依赖关系方面可能不如对称卷积。
因果卷积只关注序列数据的过去信息,因此它适合实时处理时间序列数据。但由于它不考虑未来的数据,所以在捕捉长期依赖关系方面可能不如对称卷积。这可能导致在某些任务中性能稍低于对称卷积。因果卷积的计算复杂度与序列的长度无关,因为它只需要处理序列的已知部分。这使得因果卷积在处理长序列时具有较低的计算复杂度。
3、实验结果
3.1、评判标准
- Protocol 1(MPJPE):这是评估模型性能的最直观方法。它计算的是预测的关节位置与地面实况关节位置之间的欧式距离的平均值,以毫米为单位。在这个协议中,不对预测的姿态进行任何对齐操作。
- Protocol 2(P-MPJPE):这个协议首先将预测的姿态与地面实况姿态进行对齐,通过对齐后的姿态计算平均关节位置误差。对齐过程包括翻译、旋转和缩放操作,使得预测的姿态与地面实况姿态尽可能一致。然后计算对齐后的姿态的平均关节位置误差。
- Protocol 3:这个协议将预测的姿态与地面实况姿态进行对齐,但是不进行任何翻译、旋转或缩放。它直接计算预测的姿态与地面实况姿态之间的平均关节位置误差。
3.2、评判结果
下表展示了作者们提出的卷积模型在两种不同评估协议下的结果。该模型在两种协议下的平均误差均低于其他所有方法,且不依赖于额外数据(如许多其他方法所使用的那样)。在Protocol 1下,作者们的模型比之前的最佳结果平均误差低6mm,相当于11%的误差减少。值得注意的是,从前最佳的评判结果使用了地面实况框,而文章的模型没有。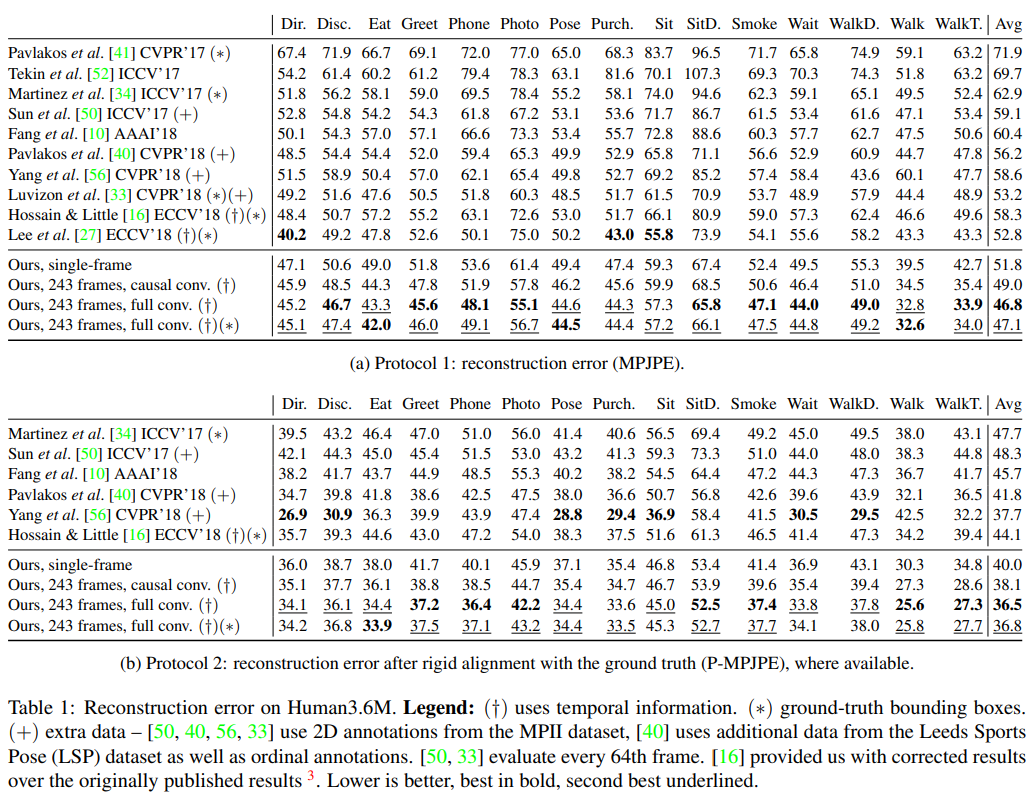
比较了考虑时间信息的卷积模型与单帧基线模型在预测3D姿态时的速度误差(MPJVE),即3D姿态序列的一阶导数的均方误差(MPJPE),下表表明所提出的时序模型在预测速度上显著优于单帧模型,平均降低了76%的MPJVE,从而生成更平滑的姿态序列。

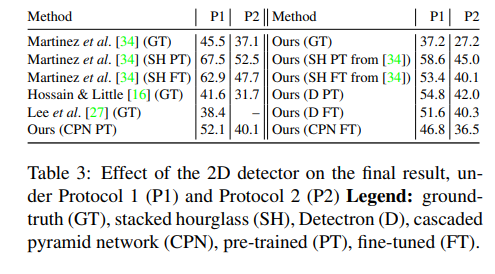
下表展示了使用不同的2D检测器(包括ground-truth poses、hourglass-network predictions、Detectron和CPN)时,模型在协议1(P1)和协议2(P2)下的性能,Mask R-CNN和CPN的性能优于stacked hourglass network,可能是由于更高的热图分辨率和更强的特征组合。
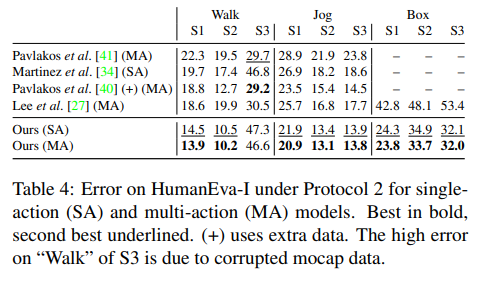
在HumanEva-I数据集上,针对单个动作(SA)和多个动作(MA)模型的评估结果,包括在协议2下的性能,模型在HumanEva-I数据集上取得了比之前方法更好的性能,证明了模型在较小数据集上的泛化能力。
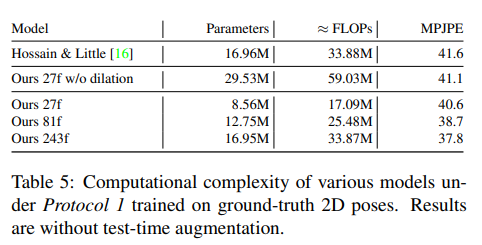
列出了Hossain & Little 的LSTM模型和不同版本的卷积模型在模型参数数量、浮点运算次数(FLOPs)以及在协议1下训练的MPJPE结果,模型在计算复杂性较低的情况下实现了更低的MPJPE,特别是在使用扩张卷积时,模型的复杂性仅随感受野的对数增加。
4、公式分析
4.1、加权均方误差 (Weighted Mean Per-Joint Position Error, WMPJPE)
这个公式定义了一个加权的均方误差(WMPJPE),用于在半监督学习方法中评估和优化3D姿态估计。其中,f(x) 表示从2D关键点估计得到的3D姿态,y 表示对应的真实3D姿态,yz 是相机空间中真实姿态的深度(即从根关节到该关节的z坐标)。这个加权方案考虑到了距离相机更远的关节对于姿态估计的重要性,因为这些关节的精确估计对于整体姿态的准确性至关重要。
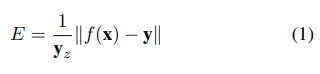
4.2、扩张卷积 (Dilated Convolution)
扩张卷积是一种特殊类型的卷积,其中卷积核的元素不是紧密排列的,而是以某种间隔分布,间隔中填入了零。这种结构允许网络以更少的参数和计算量捕捉更广泛的上下文信息。这里,f 是输入信号,ℎD是经过扩张的卷积核,D 是扩张率(dilation factor),n 和 m 是位置索引,M 是卷积核的宽度的一半。
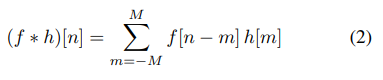
4.3、 因果卷积 (Causal Convolution)
因果卷积是一种特殊的卷积,它保证了输出不会依赖于未来的输入值,这对于时间序列数据是必要的,因为它保持了时间上的因果关系。这里, f 是输入信号,ℎC是因果卷积核,n 和 m 是位置索引,M 是卷积核的宽度。在补充材料的A.1节中,作者可能还讨论了这些卷积的实现细节和它们在模型中的具体应用,包括如何通过扩张卷积增加模型的感受野,同时保持计算效率。这些卷积操作在处理时间序列数据,尤其是在视频帧序列的3D人体姿态估计中非常有用。
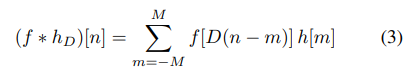
5、总结
文献引入了一种简单的全卷积模型,用于视频中的三维人体姿态估计。作者提出的架构通过在二维关键点轨迹上使用扩张卷积来利用时间信息。这项工作的第二个贡献是反投影,这是一种半监督训练方法,当标注数据稀缺时可以提高性能。该方法与无标签视频一起工作,仅需要内在相机参数,使其在实际场景中具有实用性,例如户外运动等难以进行动作捕捉的场景。文献的全卷积架构在流行的Human3.6M数据集上的平均关节误差比之前最好的结果提高了6毫米,相当于相对减少了11%,并且在HumanEva-I上也显示出了改进。反投影可以在只有5K个或更少的有注释帧可用的情况下,相比于一个强大的基线,将三维姿态估计精度提高大约10毫米N-MPJPE(15毫米MPJPE)。
VideoPose3D项目
项目结构
- checkpoint:通常包含预训练模型的权重文件或训练过程中保存的检查点(checkpoints),这些文件用于在训练中断后恢复训练或用于模型推断。
- common:这个目录包含项目中多个地方使用的通用代码,如工具函数、数据加载器或基础类。
- data:此目录可能包含与数据相关的代码,例如数据集类、数据预处理脚本或数据加载器。
- detectron2:Detectron2是一个由Facebook AI
Research开发的用于目标检测和分割的深度学习框架。这个目录可能包含与Detectron2集成相关的代码,用于2D关键点检测。 - images:这个目录可能用于存储项目中使用的图像文件,例如示例输入图像或生成的可视化图像。
- inference:包含与模型推断相关的代码,如用于从视频或图像中估计3D人体姿态的脚本。
- DATASETS.md:一个Markdown文件,描述了项目使用的数据集,包括数据集的来源、结构和如何使用。
- DOCUMENTATION.md:一个Markdown文件,提供项目的文档,包括安装指南、用户手册或开发者文档。
- INFERENCE.md:一个Markdown文件,包含有关如何使用模型进行推断(例如3D姿态估计)的说明。
- README.md:项目的主要Markdown文件,通常包含项目描述、安装指南、快速开始说明和其他重要信息。
- run.py:项目的主执行脚本,可能用于启动训练、推断或其他核心功能。
run.py脚本的解读
- 创建检查点目录:尝试创建一个名为args.checkpoint的目录,用于存放模型的检查点文件。如果目录创建失败,除非是因为目录已存在,否则会抛出一个运行时错误。
try:os.makedirs(args.checkpoint)
except OSError as e:if e.errno != errno.EEXIST:raise RuntimeError('Unable to create checkpoint directory:', args.checkpoint)
- 加载数据集:根据提供的参数args.dataset,脚本会加载不同的数据集。这里以Human3.6M数据集为例,如果参数匹配,它会实例化一个Human36mDataset对象。
dataset_path = 'data/data_3d_' + args.dataset + '.npz'
if args.dataset == 'h36m':from common.h36m_dataset import Human36mDatasetdataset = Human36mDataset(dataset_path)
elif args.dataset.startswith('humaneva'):from common.humaneva_dataset import HumanEvaDatasetdataset = HumanEvaDataset(dataset_path)
elif args.dataset.startswith('custom'):from common.custom_dataset import CustomDatasetdataset = CustomDataset('data/data_2d_' + args.dataset + '_' + args.keypoints + '.npz')
else:raise KeyError('Invalid dataset')
- 数据预处理:循环遍历数据集中的所有主题(subjects)和动作(actions),对每个动作的动画数据进行预处理。
print('Preparing data...')
for subject in dataset.subjects():for action in dataset[subject].keys():anim = dataset[subject][action]if 'positions' in anim:positions_3d = []for cam in anim['cameras']:pos_3d = world_to_camera(anim['positions'], R=cam['orientation'], t=cam['translation'])pos_3d[:, 1:] -= pos_3d[:, :1] # Remove global offsetpositions_3d.append(pos_3d)anim['positions_3d'] = positions_3d
- 加载2D检测结果:加载了2D关键点检测结果,这些结果是从视频帧中检测到的人体关节位置。
keypoints = np.load('data/data_2d_' + args.dataset + '_' + args.keypoints + '.npz', allow_pickle=True)
keypoints_metadata = keypoints['metadata'].item()
keypoints_symmetry = keypoints_metadata['keypoints_symmetry']
kps_left, kps_right = list(keypoints_symmetry[0]), list(keypoints_symmetry[1])
joints_left, joints_right = list(dataset.skeleton().joints_left()), list(dataset.skeleton().joints_right())
keypoints = keypoints['positions_2d'].item()
- 模型初始化:代码根据参数初始化了3D姿态估计模型。如果指定了优化选项并且没有启用密集过滤器,且步长为1,则使用优化版本的模型。
filter_widths = [int(x) for x in args.architecture.split(',')]
if not args.disable_optimizations and not args.dense and args.stride == 1:model_pos_train = TemporalModelOptimized1f()
else:model_pos_train = TemporalModel()
实验结果
- 运行代码及参数:
python run.py -k cpn_ft_h36m_dbb -arc 3,3,3,3,3 -c checkpoint --evaluate pretrained_h36m_cpn.bin --render --viz-subject S11 --viz-action Walking --viz-camera 0 --viz-video "/path/to/videos/S11/Videos/Walking.54138969.mp4" --viz-output output.gif --viz-size 3 --viz-downsample 2 --viz-limit 60- 结果:
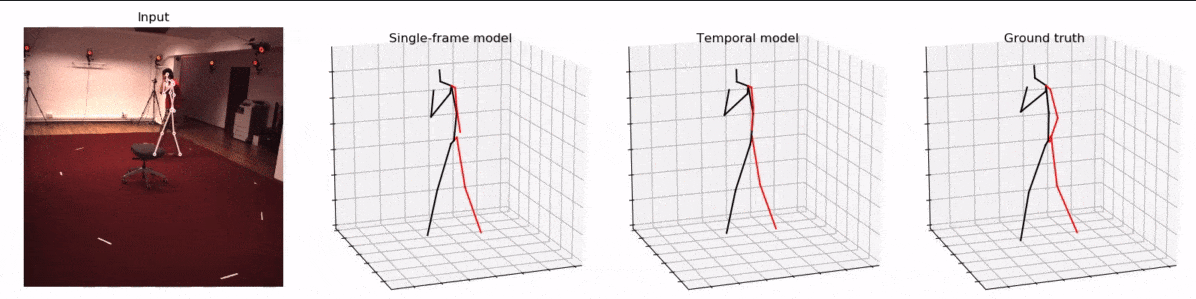
总结
本周主要阅读了CVPR文章, 3D human pose estimation in video with temporal convolutions and semi-supervised training。这是一种基于二维关键点和扩张时间卷积的全卷积模型,用于有效估计视频中的三维人体姿态,除此之外,还提出了一种名为“反投影”的半监督训练方法,该方法能够利用未标记的视频数据来增强模型的学习效果,这一过程不仅提高了模型对未标记数据的利用效率,而且显著提升了学习性能。除了阅读文献之外,还学习了文献所包含的相关代码知识,使用代码中,存在些许问题,只能使用官方提供的数据,自己的测试视频无法通过,正在排查问题。