土堆视频链接
1. 两大函数
1.1 dir函数
dir函数返回一个属性列表,其中列表的元素都是字符串格式。
- 对于模块对象:返回模块的所有属性(变量名和方法)
- 对于类对象:返回这个类的属性,以及其所有父类(包括父类的父类)的属性
- 对于其它对象(实例对象):返回这个实例对象的属性,实例对象类的属性,以及这个类的所有父类(包括父类的父类)的属性。
1.2 help() 函数
help() 函数用于查看函数或模块用途的详细说明。
输入:help(Dataset) 与 Dataset?? 有相同的作用;
2.数据集
torch.utils.data 是PyTorch提供的一个模块,用于处理和加载数据。该模块提供了一系列工具类和函数,用于创建、操作和批量加载数据集。
下面是 torch.utils.data 模块中一些常用的类和函数:
- Dataset: 定义了抽象的数据集类,用户可以通过继承该类来构建自己的数据集。Dataset 类提供了两个必须实现的方法:__getitem__ 用于访问单个样本,__len__ 用于返回数据集的大小。
- TensorDataset: 继承自 Dataset 类,用于将张量数据打包成数据集。它接受多个张量作为输入,并按照第一个输入张量的大小来确定数据集的大小。
- DataLoader: 数据加载器类,用于批量加载数据集。它接受一个数据集对象作为输入,并提供多种数据加载和预处理的功能,如设置批量大小、多线程数据加载和数据打乱等。
- Subset: 数据集的子集类,用于从数据集中选择指定的样本。
- random_split: 将一个数据集随机划分为多个子集,可以指定划分的比例或指定每个子集的大小。
- ConcatDataset: 将多个数据集连接在一起形成一个更大的数据集。
- get_worker_info: 获取当前数据加载器所在的进程信息。
3.tensorboard的使用:
TensorBoard是由Google开发的一个可视化工具,旨在帮助用户理解和调试深度学习模型的训练过程。PyTorch提供了一个名为SummaryWriter的接口,用于将各种类型的数据写入TensorBoard中。在TensorBoard中,用户可以通过直观的图表和可视化界面来浏览、比较和分析训练过程中的指标、学习曲线和特征图等信息。
在TensorBoard中,常见的可视化内容包括训练/验证损失曲线、学习率曲线、精度曲线、直方图和散点图等。通过这些可视化工具,用户可以更好地理解模型训练过程中的变化和趋势,进而采取合适的策略来优化模型性能和训练速度。
3.1 使用tensorboard.SummaryWriter.add_scaltar来可视化数据:
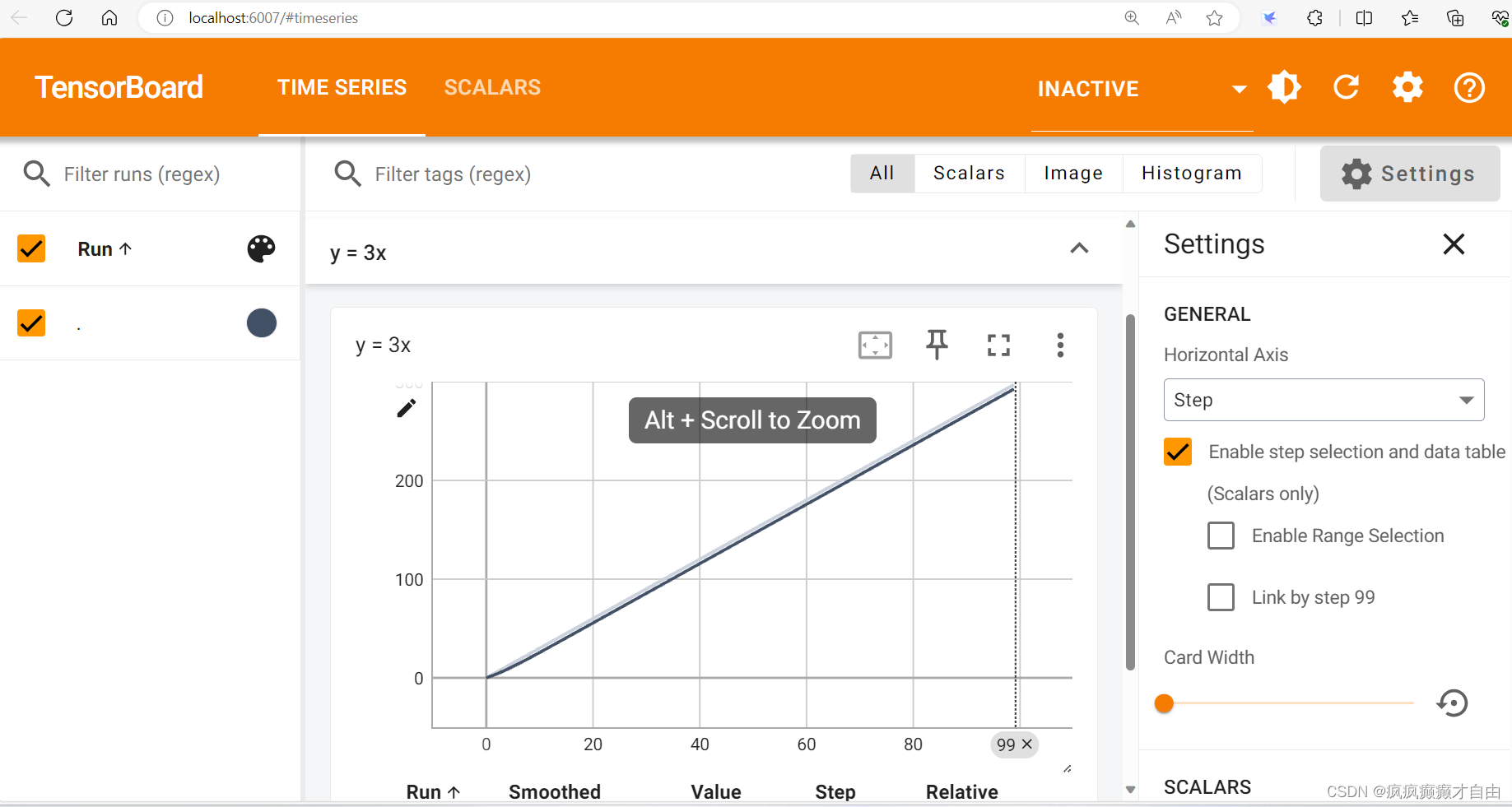
add_scalar()的使用(常用来绘制train/val loss):先创建一个SummaryWriter的实例,如writer = SummaryWriter('logs'),然后调用其方法,writer.add_scalar(tag, scalar, step)。最后记得关闭SummaryWriter。
from torch.utils.tensorboard import SummaryWriterwriter = SummaryWriter("logs")# writer.add_image()# y = x
for i in range(100):writer.add_scalar("y = 3x", 3*i, i)
'''
def add_scalar(self,tag,scalar_value,global_step=None,walltime=None,new_style=False,double_precision=False,):tag是标题,scalar_value是y轴,global_step是x轴
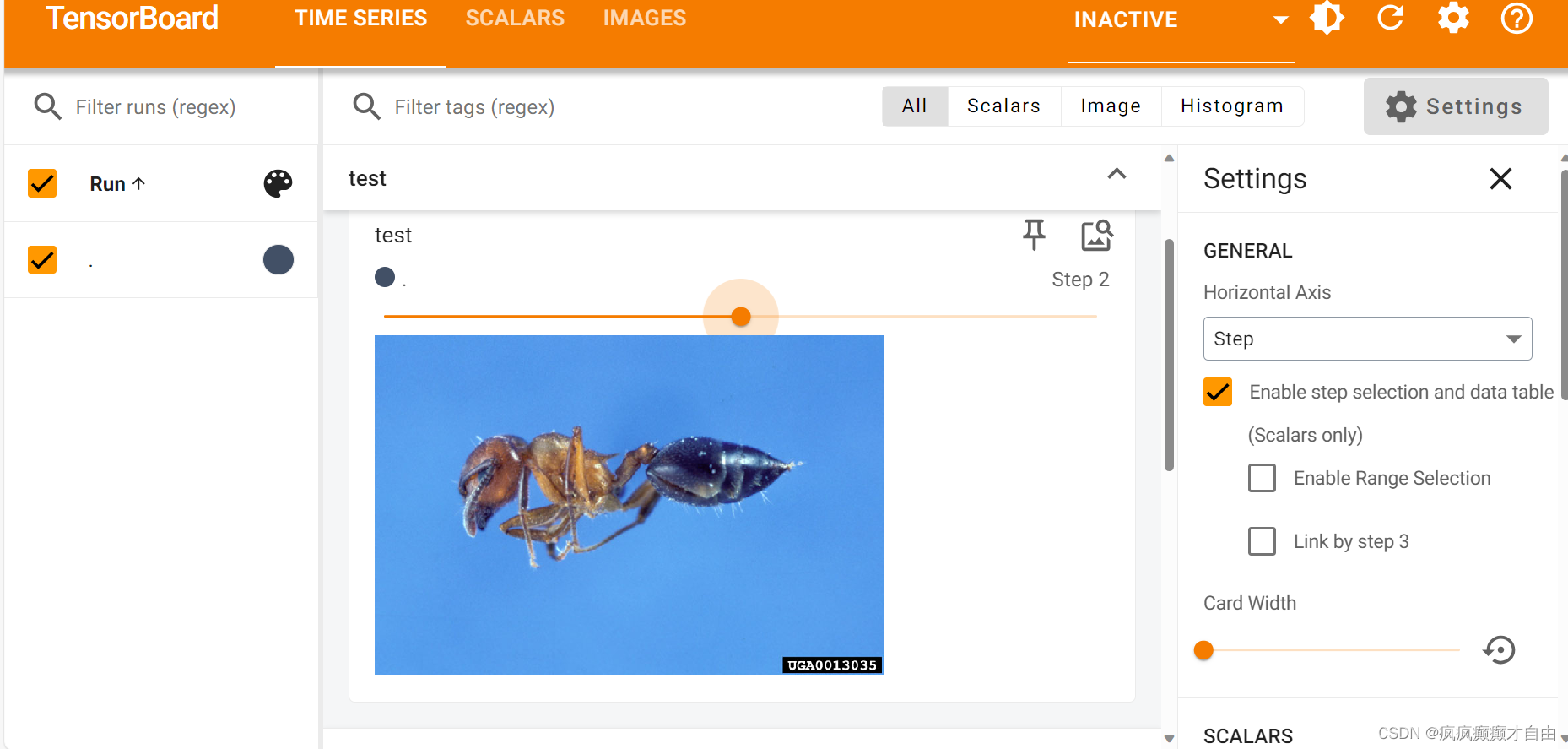
'''writer.close()在终端输入: tensorboard --logdir=logs --port=6007 可在浏览器中查看可视化图像:
注意:等号两边不能留有空格,logs是 SummaryWriter("logs") 保存的路径文件。
想安装某个模块,可以直接在Pycharm的项目终端中用pip命令安装:
例如: pip install tensorboard
3.2 使用tensorboard.SummaryWriter.add_image来显示图片:
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Imagewriter = SummaryWriter("logs")
img_path = r"E:\python_projects\Pytorch学习\小土堆学习\data\train\bees_image\85112639_6e860b0469.jpg"
img_PIL = Image.open(img_path)
img_array = np.array(img_PIL)print(type(img_array))
print(img_array.shape)writer.add_image("train", img_array, 1, dataformats='HWC')
'''def add_image(self, tag, img_tensor, global_step=None, walltime=None, dataformats="CHW"):
'''# y = x
for i in range(100):writer.add_scalar("y = 3x", 3*i, i)
'''
def add_scalar(self,tag,scalar_value,global_step=None,walltime=None,new_style=False,double_precision=False,):tag是标题,scalar_value是y轴,global_step是x轴
'''writer.close()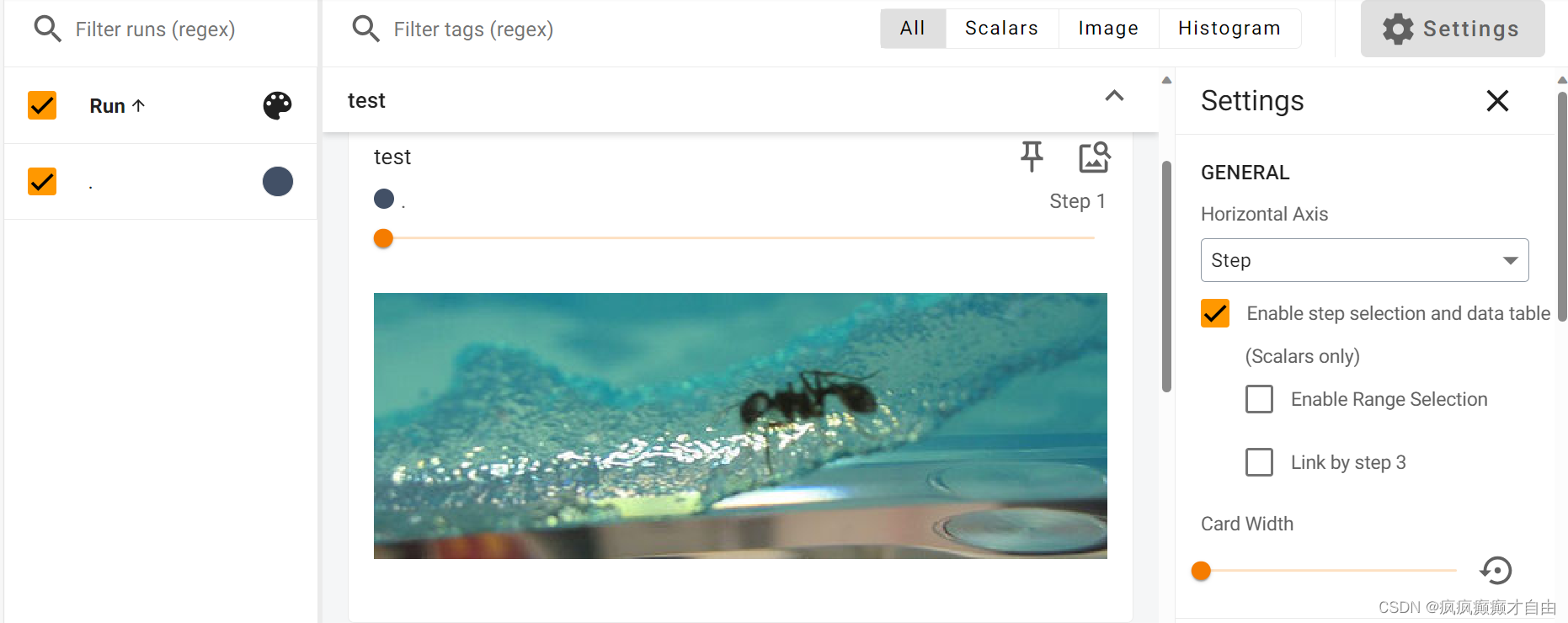
4. transforms
之前用的工具都来自torch.utils,本次课开始接触torchvision;
transforms主要作用是对图片进行变换
4.1 Pycharm的操作小技巧
在PyCharm中按住Ctrl键然后点击从外部引入的对象可以查看源码
在pycharm中查找某个功能的快捷键步骤:

可以使用PyCharm界面左侧的structure按钮查看transforms的结构:由许多类定义组成的模块。
open-cv的下载:在pycharm的终端输入:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple opencv-pythonopen-cv读出的图像是numpy类型
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms# 绝对路径:E:\python_projects\Pytorch学习\小土堆学习\dataset\train\ants\0013035.jpg
# 相对路径:dataset/train/ants/0013035.jpg
img_path = "dataset/train/ants/0013035.jpg"
PIL_img = Image.open(img_path)
print(type(PIL_img))'''
class ToTensor:Convert a PIL Image or ndarray to tensor and scale the values accordingly.
'''
tensor_trans = transforms.ToTensor() # 定义一个ToTensor实例,创建具体的工具
tensor_img = tensor_trans(PIL_img) #将PIL图像对象转化为tensor对象
print(type(tensor_img))writer = SummaryWriter("logs")
writer.add_image("Tensor_img", tensor_img)
'''def add_image(self, tag, img_tensor, global_step=None, walltime=None, dataformats="CHW"):
'''
writer.close()在终端输入:tensorboard --logdir=logs 可查看图片
4.2 小结:目前学过的3种打开图片并往SummaryWriter类传参的方式:
- PIL.Image.open打开(得到 PIL类型),np.array转换
- PIL.Image.open打开,transforms.ToTensor转换
- opencv打开(这个打开就是ndarray类型)

5. 实用技巧:
5.1 调用魔法函数 __call__
实例化一个类对象后,调用该实例化对象(后面不调用该类的其他方法,那么该实例化对象会自动调用魔法函数__call__

class Person:def __call__(self, name):print("__call__" + " hello " + name)def hello(self, name):print("hello" + name)person = Person()
person("Lisi")
person.hello("Zhansan")class Person2:def __init__(self, name):self.name = namedef __call__(self):print("__call__" + " hello " + self.name)def hello(self):print("hello" + self.name)person2 = Person2("LY")
person2.hello()
person2()
'''实例化一个类对象后,调用该实例化对象(后面不调用该类的其他方法,那么该实例化对象会自动调用魔法函数__call__'''
person2.__call__() 
5.2 pycharm小技巧,忽略大小写:

5.3 在自己写代码时注意什么,怎么进行学习:

6. torchvision 的数据集(datasets)的使用:
6.1 如何下载数据集
# first:下载数据集,下载的数据集中的图片是PIL类型
# import torchvision
#
# train_dataset = torchvision.datasets.CIFAR10(root="./CIFAR10_dataset", train=True, download=True)
# test_dataset = torchvision.datasets.CIFAR10(root="./CIFAR10_dataset", train=False, download=True)
#
# print(test_dataset[0])
#
# print("test_dataset.classes", test_dataset.classes)
#
# img, target = test_dataset[0]
# print("img", img)
# print("target", target)
# print("test_dataset.classes[target]", test_dataset.classes[target])
# img.show()6. 2 将下载的数据集的类型转化为tensor类型
# second:将下载的数据集的类型转化为tensor类型import torchvision
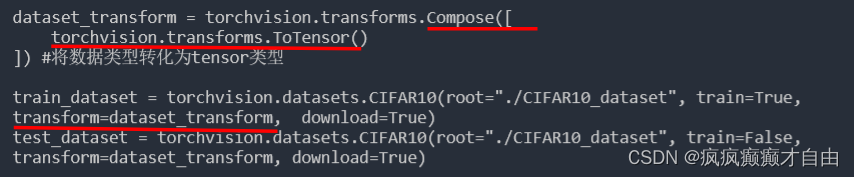
from torch.utils.tensorboard import SummaryWriterdataset_transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()
]) #将数据类型转化为tensor类型train_dataset = torchvision.datasets.CIFAR10(root="./CIFAR10_dataset", train=True, transform=dataset_transform, download=True)
test_dataset = torchvision.datasets.CIFAR10(root="./CIFAR10_dataset", train=False, transform=dataset_transform, download=True)# print(test_dataset[0]) #输出的是tensor类型writer = SummaryWriter("dataset_transformers_logs")
for i in range(10):img, target = test_dataset[i]writer.add_image("test_dataset", 

![[LitCTF 2023]Ping、[SWPUCTF 2021 新生赛]error、[NSSCTF 2022 Spring Recruit]babyphp](https://img-blog.csdnimg.cn/direct/6b6d326308094e4d8c84e8a97574c3f4.png)