一、搜索树
在真正学习Map和Set之前,我们有必要先来了解一种树型结构:二叉搜索树!
1、概念
二叉搜索树又被称为【二叉排序树】,顾名思义,这是一颗排好序的树!它或者是一颗空树,或者是具有以下性质的二叉树:
1、若它的左子树不为空,则左子树上的所有节点的值都小于根节点的值
2、若它的右子树不为空,则右子树上的所有结点的值都大于根节点的值
3、它的左右子树也分别为二叉搜索树
观察此图,可以发现,这这棵树的【中序遍历】序列是一个有序序列!
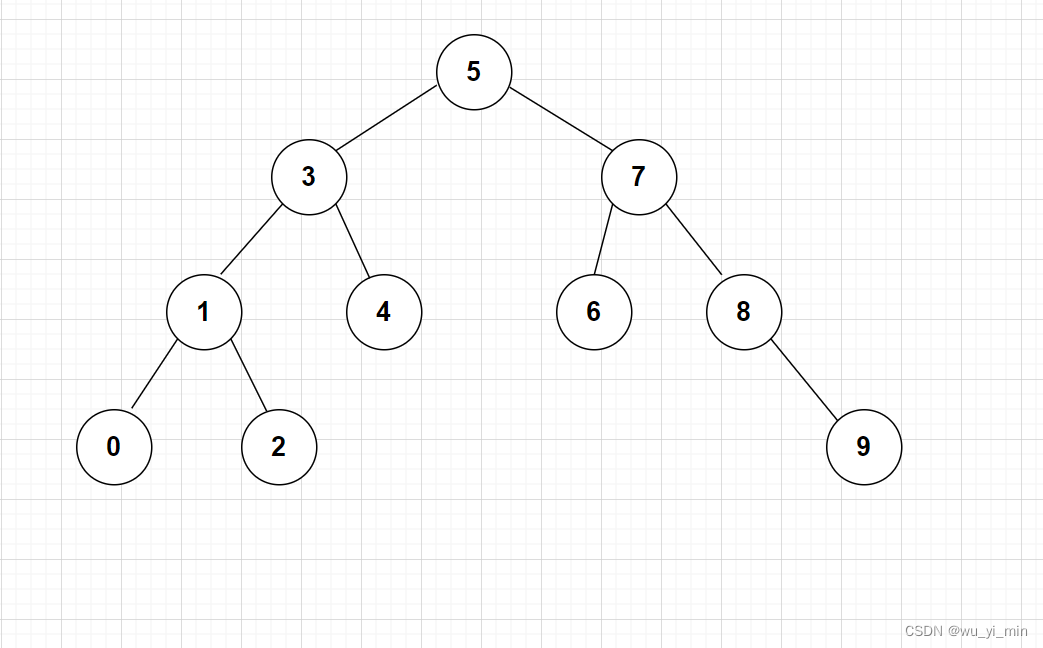
2、 查找关键字方法:
【基本思想】
根据二叉搜索树的性质,我们可以知道,对于每一颗树,根节点的左子树元素都【小于】根节点元素,根节点的右子树元素都【大于】根节点元素。
那么,在查找关键字的时候,不必每次都遍历整棵二叉树,首先,【先比较】根节点元素和关键字的大小:
1、根节点元素【大于】关键字:找左子树
2、根节点元素【小于】关键字:找右子树
3、根节点元素【等于】关键字:返回根节点
【代码实现】
public TreeNode search(int key){if(root==null){return null;}TreeNode cur=root;while (cur!=null){if(cur.val>key){//根节点元素 比 关键字 大,找左子树cur=cur.left;}else if(cur.val<key){//根节点元素 比 关键字 小,找右子树cur=cur.right;}else{//根节点元素 等于 关键字return cur;}}//没有找到return null;} 3、插入元素方法:
【基本思想】
在实现这个方法之前,有一点需要我们知道:搜索二叉树不能拥有相同的数据!因此,当插入的数据在二叉树已经拥有的情况下,无法进行插入!
插入原理:
1、创建一个新节点,新节点的值即插入元素的值
2、先判断整棵树的的根节点是否为空,如果为空,直接将新节点赋值给root
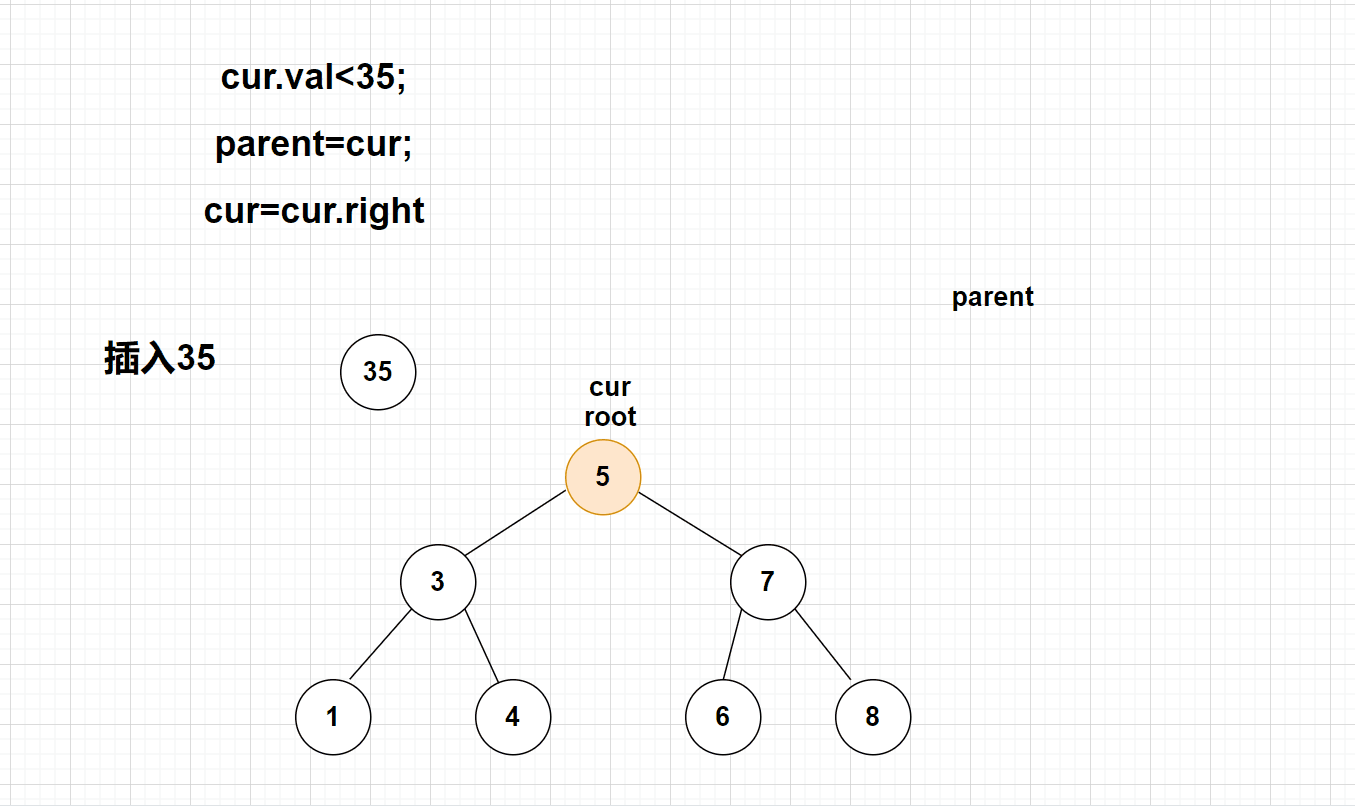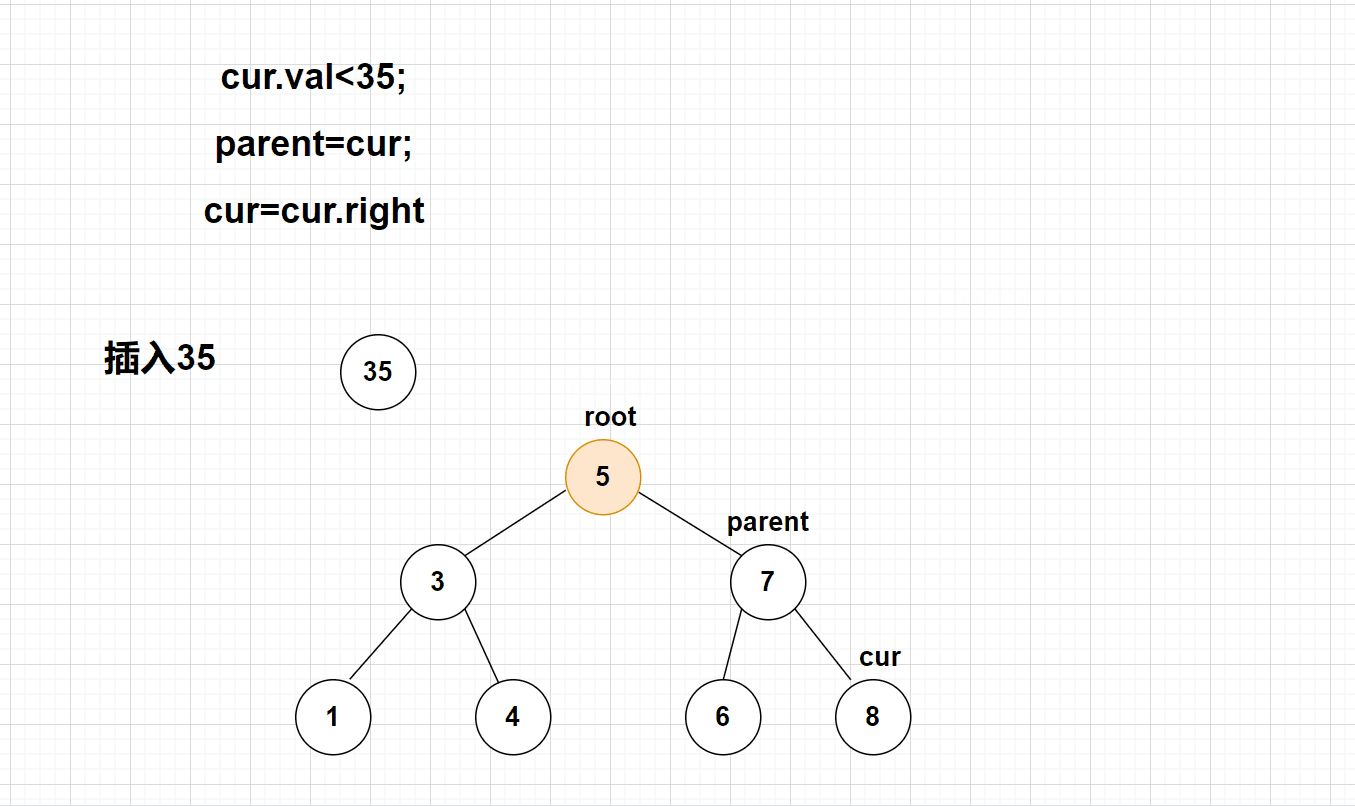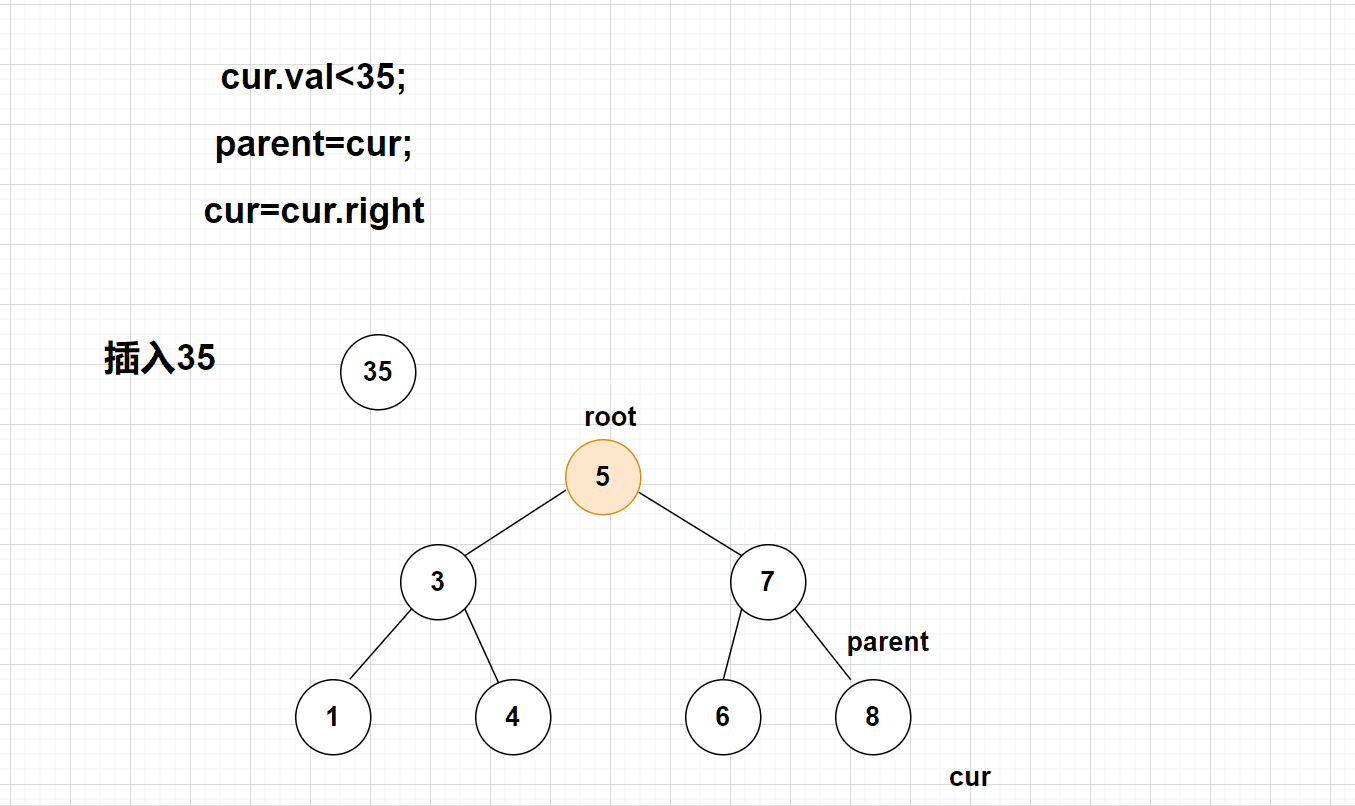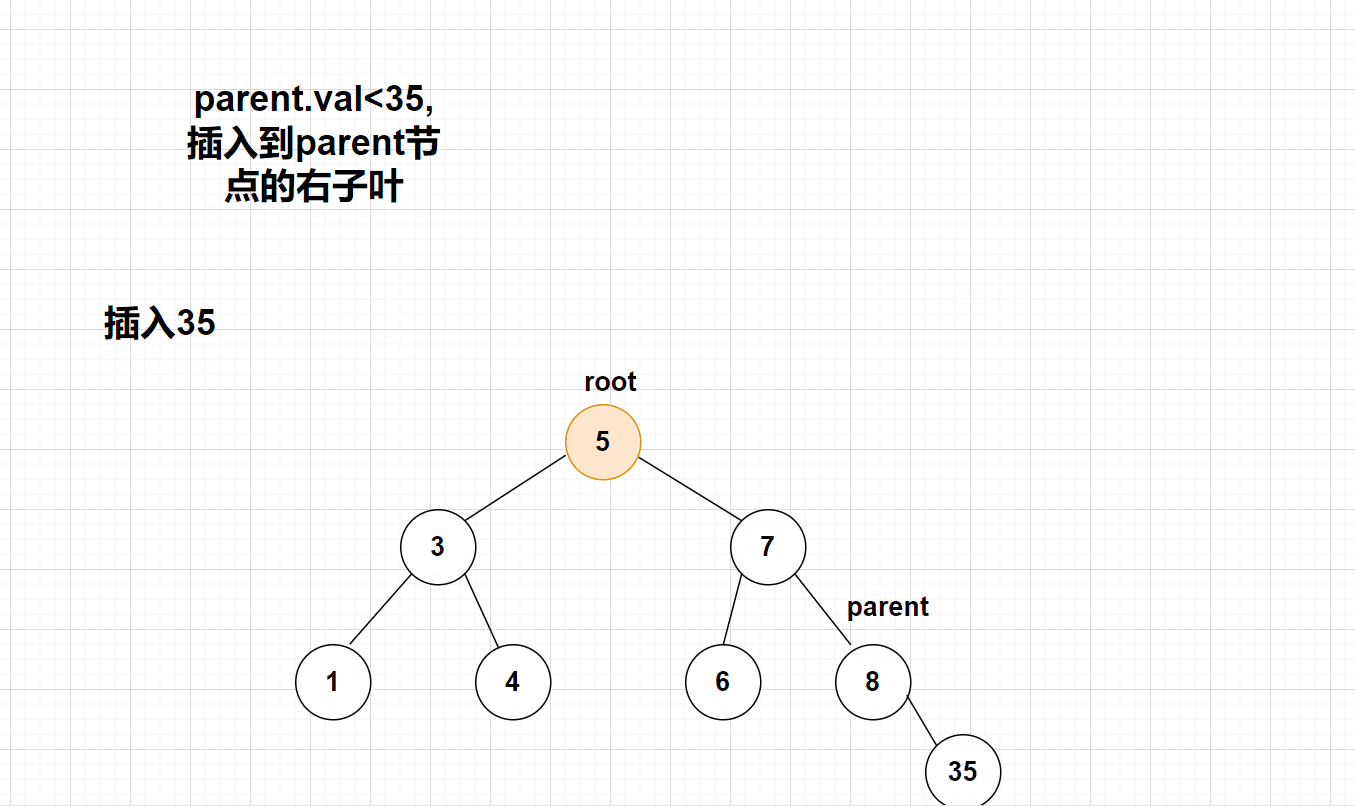
3、创建cur和parent,cur找到空节点!parent定位cur的父亲节点!
4、根据父亲节点元素大小和插入元素的大小,判断新节点插入到父亲节点的左子叶或者右子叶
【动画演示】
【代码实现】
//插入数据方法public void insert(int val) {TreeNode node = new TreeNode(val);//当根节点为空if (root == null) {root = node;return;}//根节点不为空TreeNode cur = root;TreeNode parent = null;while (cur != null) {parent = cur;if (cur.val > val) {cur = cur.left;} else if (cur.val < val) {cur = cur.right;} else {//遇到相同的数据,不能插入!return;}}//此时cur==null,插入数据if (parent.val > val) {//根节点元素大于val,插入左节点parent.left = node;} else {//根节点元素小于val,插入右节点parent.right = node;}}
4、删除关键字方法:
【基本思想】
在删除【关键字】之前,首先我们需要找到该关键字,创建变量cur定位关键字所在的节点!创建parent定位cur的父亲节点!
在cur找到关键字之后,删除关键字主要划分为三种情况:
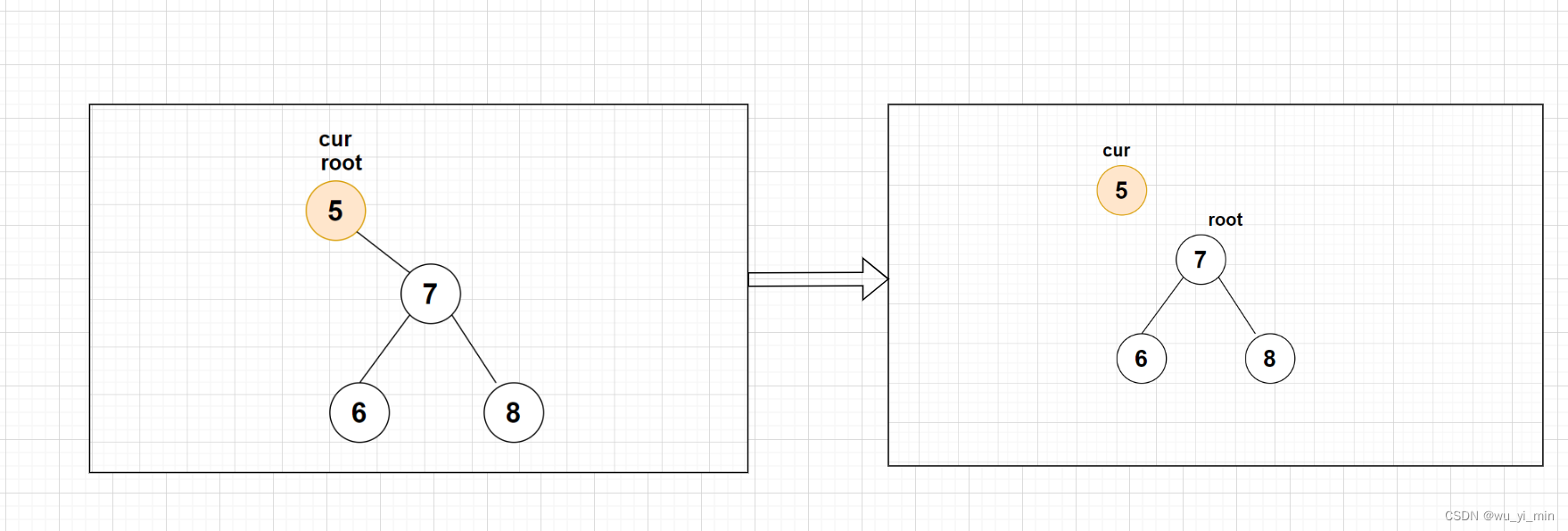
1、cur.left==null:
【情况1】:cur为根节点root,此时只需要将根节点root替换为cur.left即可!
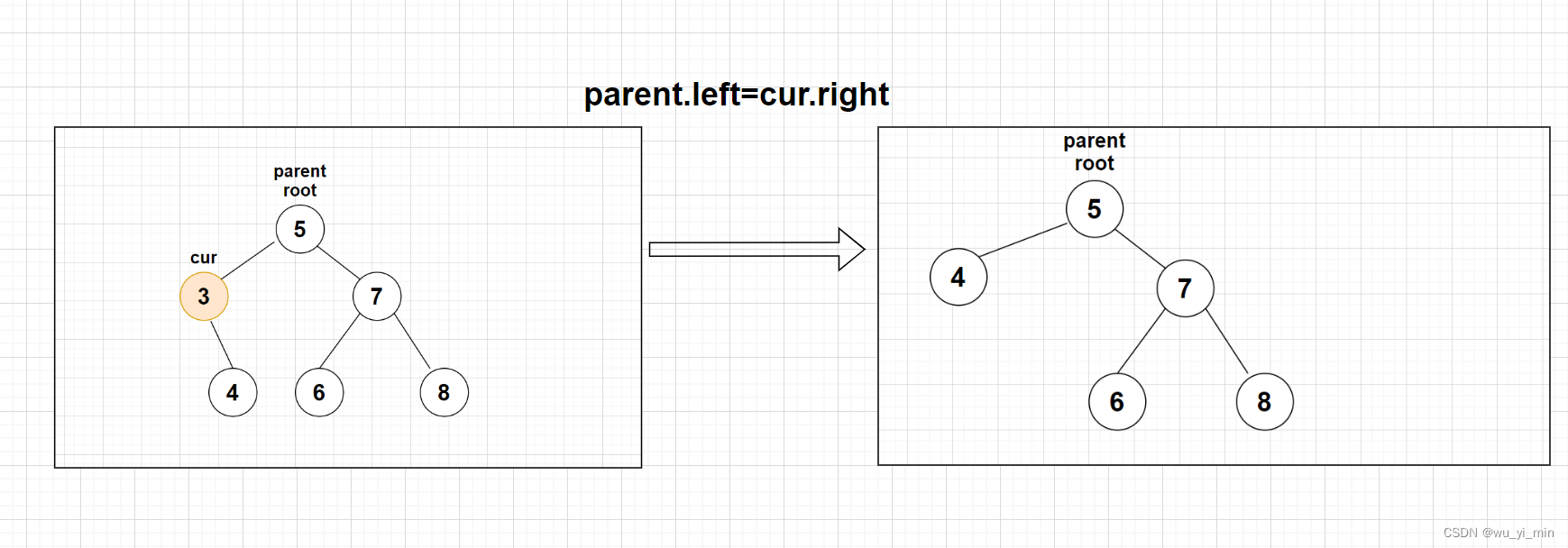
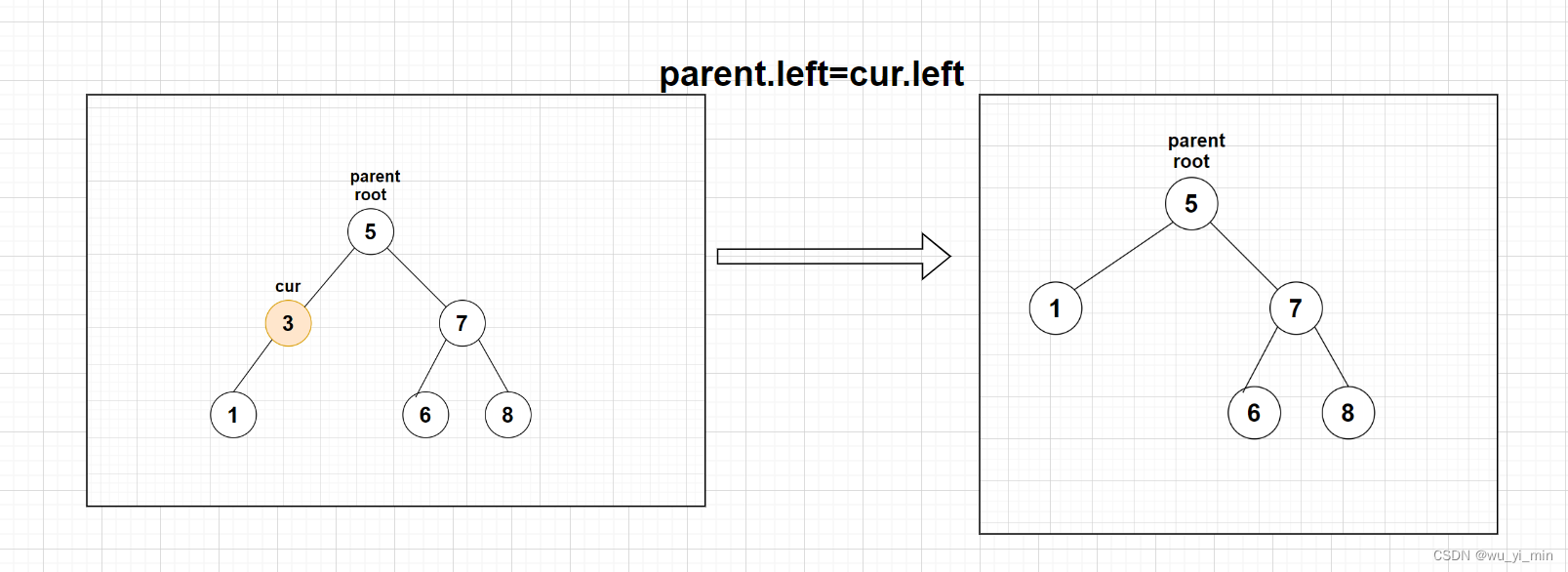
【情况2】:cur不是根节点root,cur是parent(父亲节点)的左子叶节点 ,此时只需要将parent的左子树替换为cur的右子树即可!
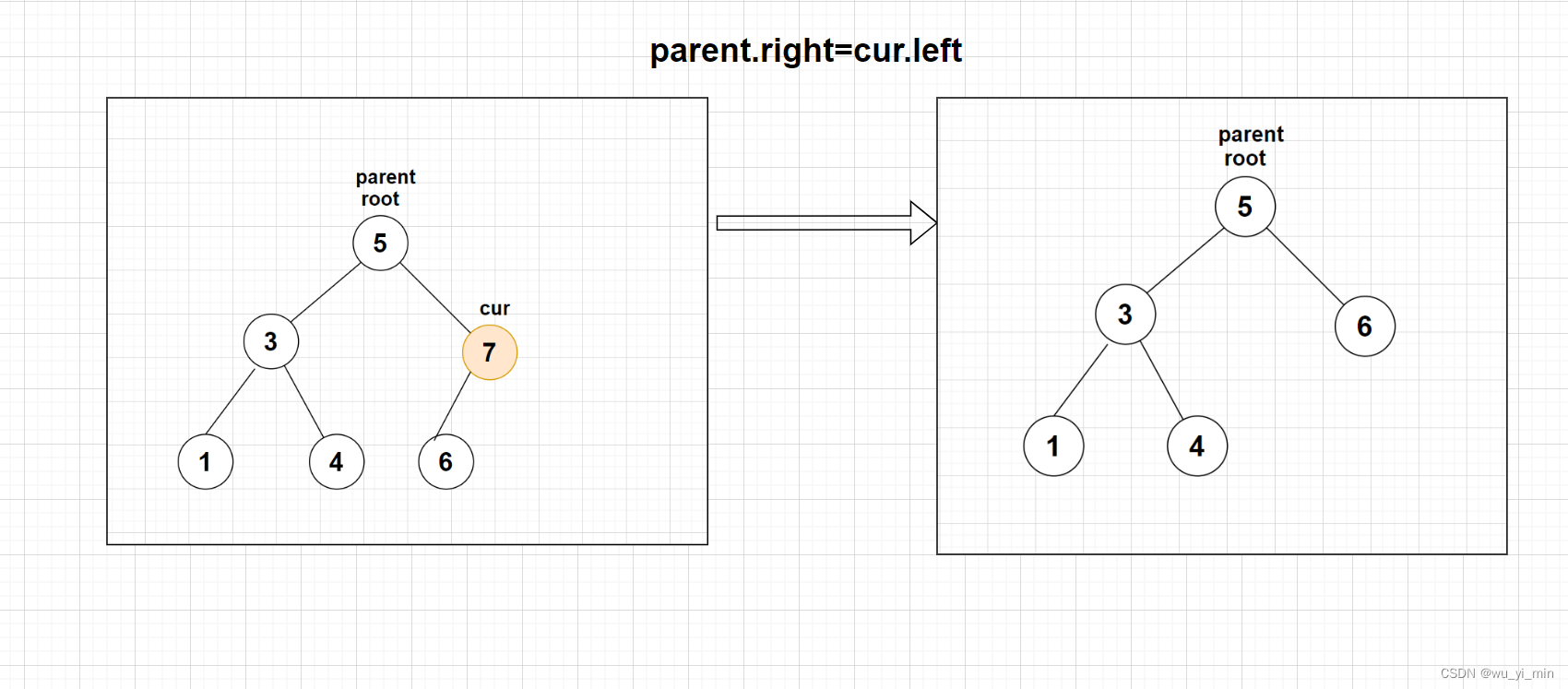
【情况3】:cur不是根节点root,cur是parent(父亲节点)的右子叶节点,此时只需要parent的右子树替换为cur的右子树即可
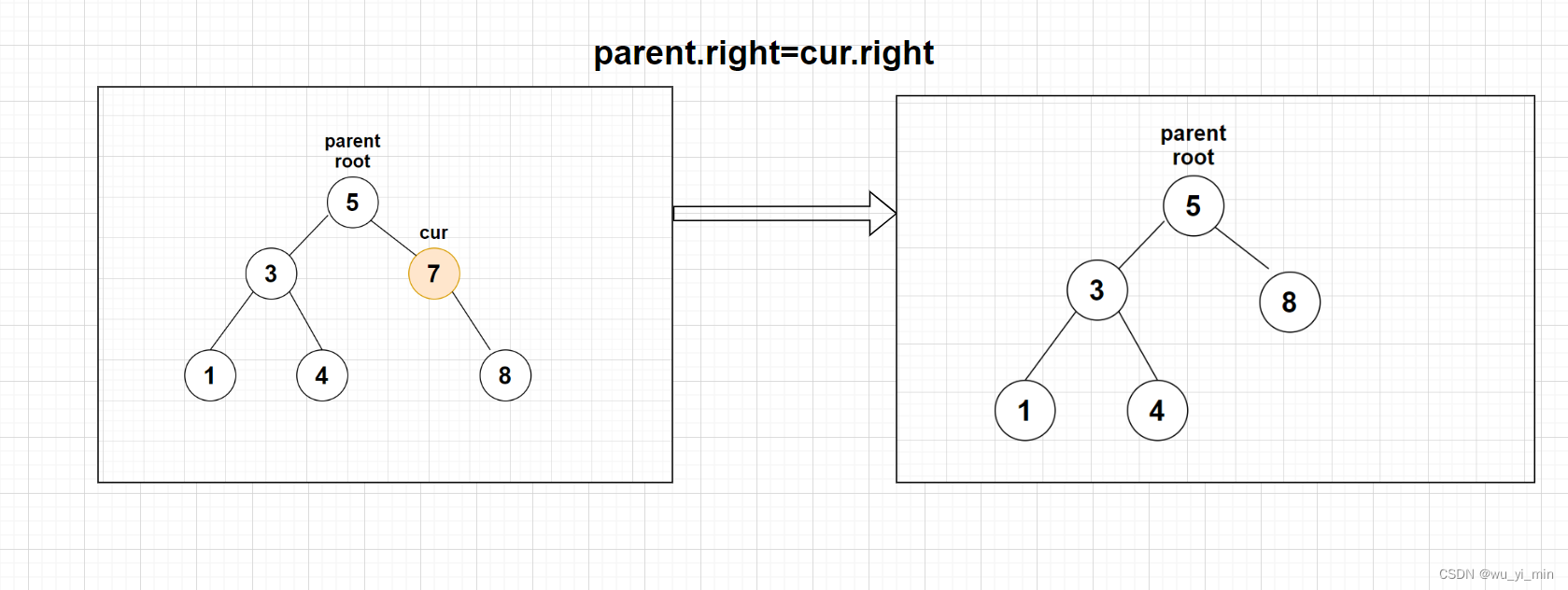
2、cur.right==null
【情况1】:cur是根节点root,此时只需要将根节点root替换为cur.left即可
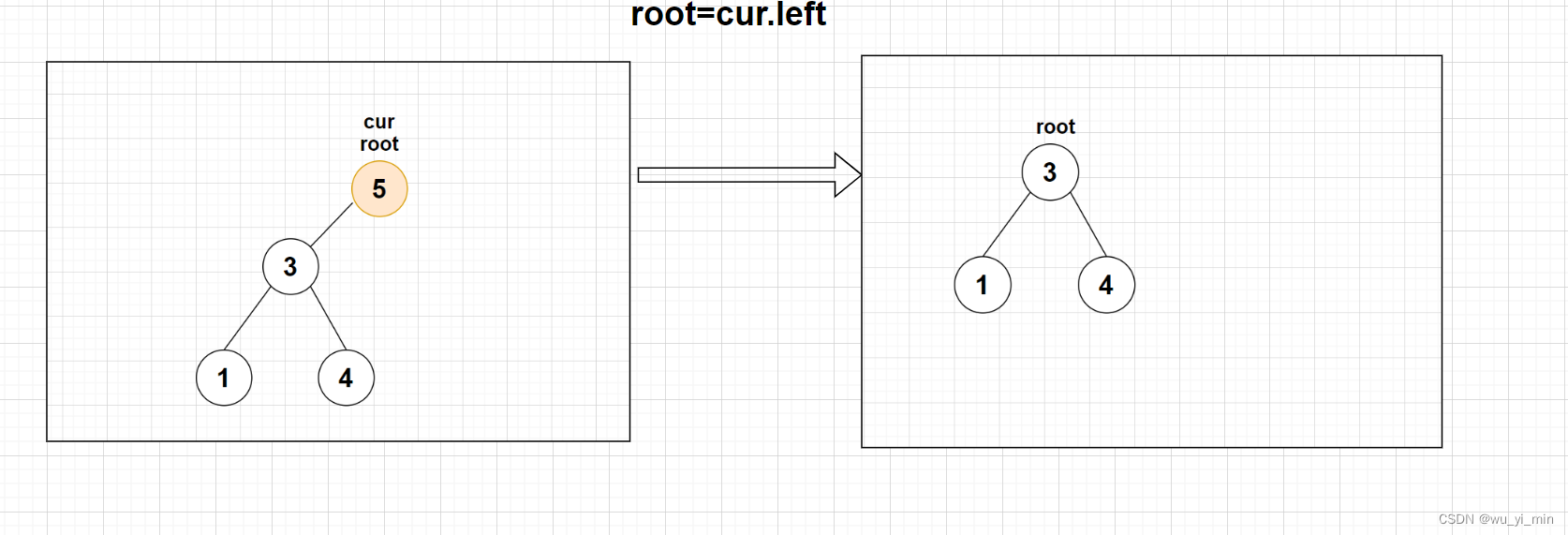
【情况2】:cur不是根节点root,cur是parent(父亲节点)的左子叶节点,此时只需要将parent的左子树替换为cur的左子树即可
【情况3】:cur不是根节点root,cur是parent(父亲节点)的右子叶节点,此时只需要将parent的右子树替换为cur的左子树即可
3、cur.left==null && cur.right==null
如果cur的左右节点都不为空,那么我们就不能直接删除该节点,如果直接删除,后面的节点很难有序连接起来!因此,我们使用【替换法】
以此为例子,此时要删除cur这个节点,它的值为60,那么,我们可以先在cur的右子树中寻找该树的【最小值】节点,同时删除该【最小值】节点!将这个【最小值】赋值给【cur.val】,这样,并不会影响整棵树为二叉搜索树的性质!
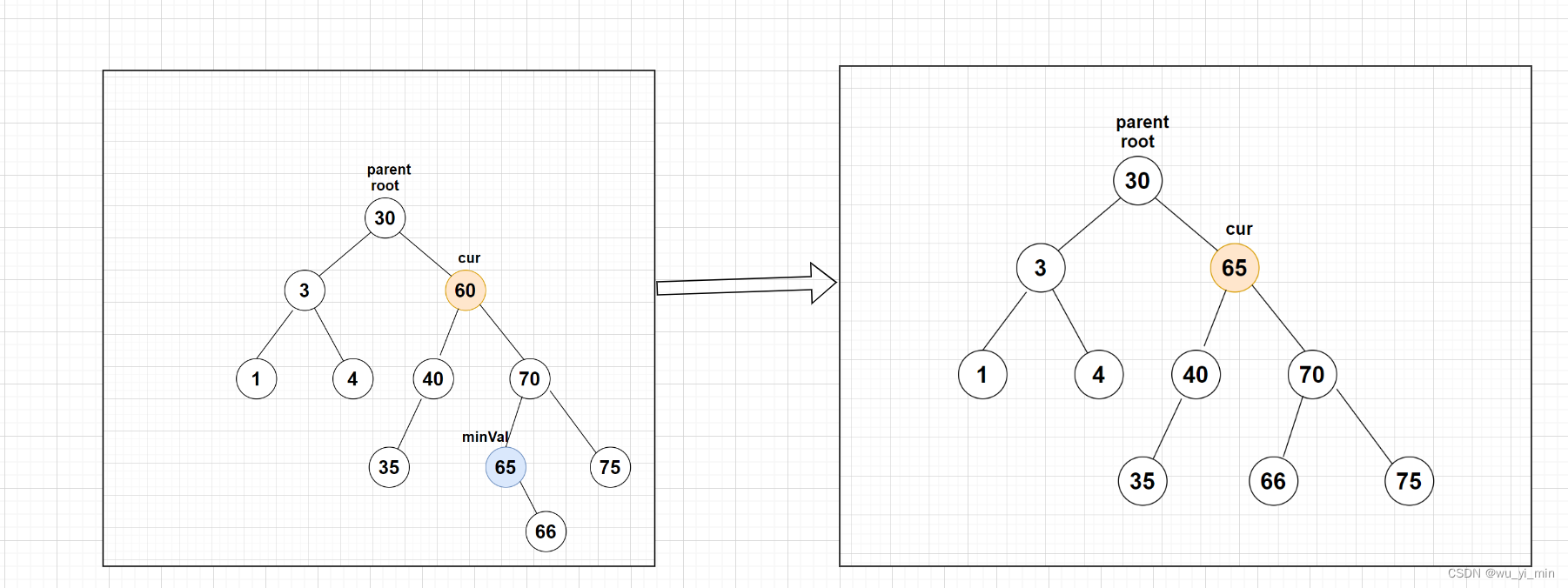
那么该如何找到右子树的最小值节点?这里我们创建变量target来定位该最小值节点,使用targetP来定位target的父亲节点!
首先,我们知道,对于二叉搜索树,其最小值节点一定在该树的最左边! 因此,我们只需要使target不断往树的左边遍历,直至找到某一个节点,该节点不存在在左子叶,此时该节点即为我们需要的最小值节点!
找到该节点后,替换时因为需要删除最小值节点,因此划分为两种情况:
【情况1】:target为targetP(父亲节点)的左子叶节点,此时删除最小值节点,只需要将targetP的左子树替换为target的右子树即可
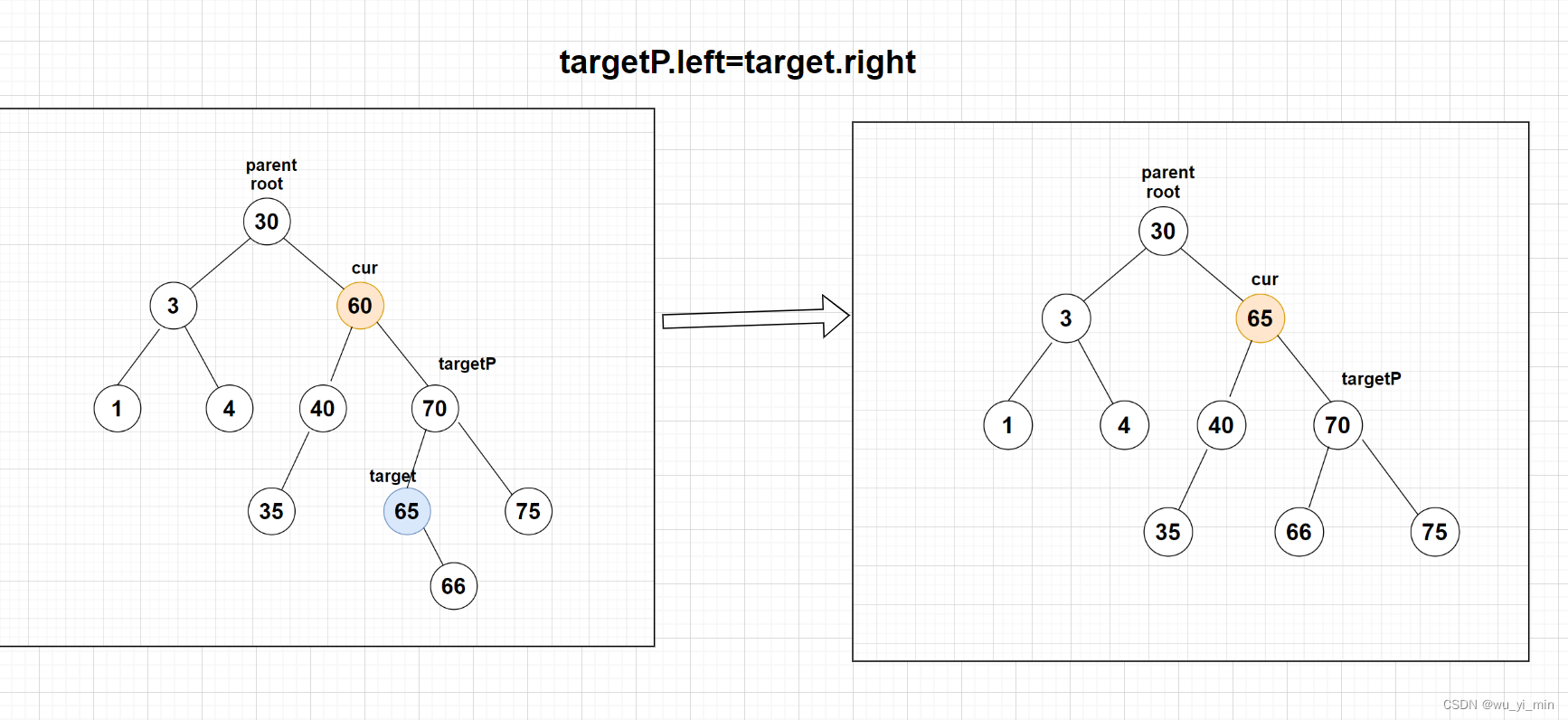
【情况2】:target为targetP(父亲节点)的右子叶节点,此时删除最小值节点只需要将targetP的右子树替换为target的右子树即可
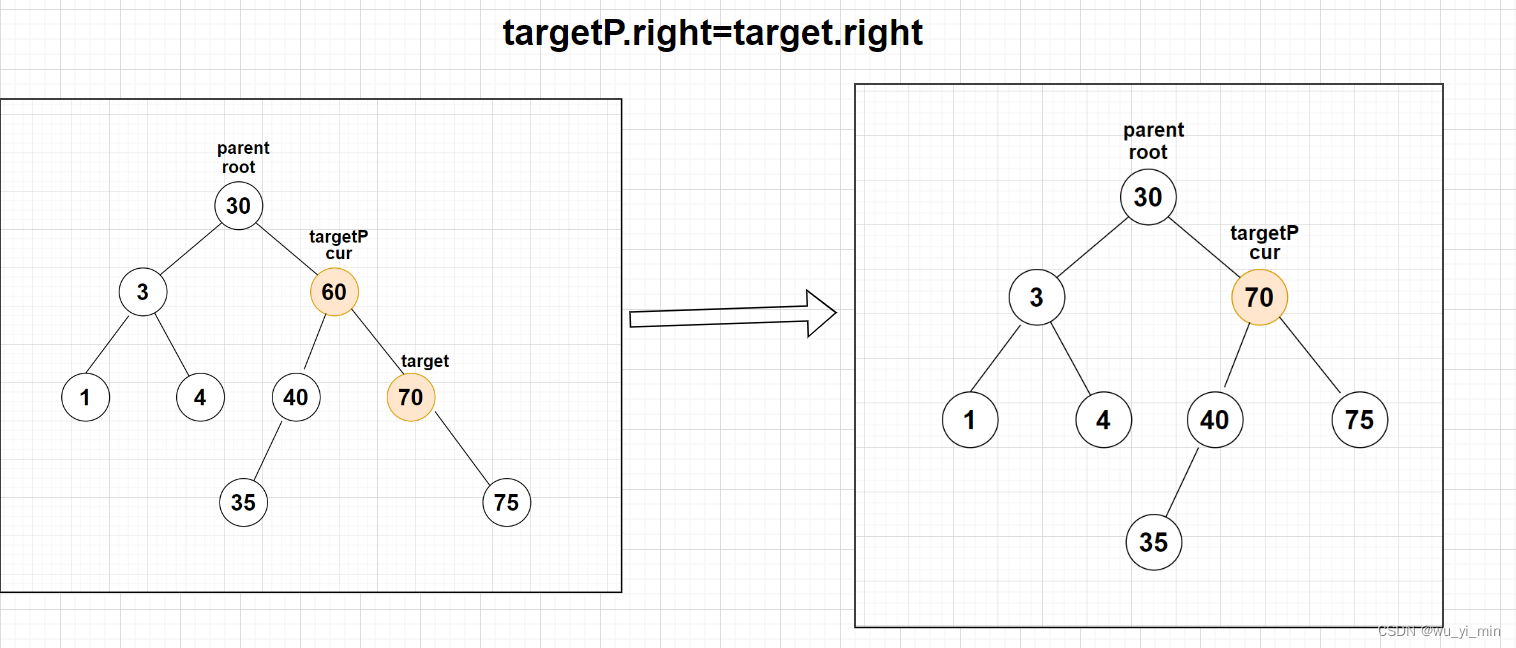
//删除数据方法:public void remove(int key){TreeNode cur=root;TreeNode parent=null;//寻找要删除的节点,使用cur定位要删除的节点,parent定位cur的父亲节点while(cur!=null){if(cur.val>key){parent=cur;cur=cur.left;} else if (cur.val<key) {parent=cur;cur=cur.right;}else{//找到删除的节点removeNode( cur,parent);return;}}}//删除指定元素方法:public void removeNode(TreeNode cur,TreeNode parent){if(cur.left==null){//1、cur.left==nullif(cur==root){ //cur为根节点root=cur.right;} else if(cur==parent.left){ //cur是左子叶节点parent.left=cur.right;}else{//cur是右子叶节点parent.right=cur.right;}} else if (cur.right==null) {//2、cur.right==nullif(cur==root){//cur为根节点root=cur.left;} else if(cur==parent.left){//cur为左子叶节点parent.left=cur.left;} else {//cur为右子叶节点parent.right=cur.left;}}else{//3、cur的左右子叶都为空TreeNode target=cur.right;TreeNode targetP=cur;//使用target定位比cur右子树中最小的元素while(target.left!=null){targetP=target;target=target.left;}cur.val=target.val;if(target==targetP.left){//target为左子叶节点targetP.left=target.right;}else{//target为右子叶节点targetP.right=target.right;}}}二、Map和Set
Map和Set是一种专门用来进行搜索的【数据结构】!拥有查找数据的功能,同时也可以进行插入数据和删除数据操作!
1、两种模型
一般,我们把搜索的数据称之为【关键字】(Key),和【关键字】对于的称为【值】(Value),二者合一称为Key-Value键值对,由此衍生出来两种模型:
1、Key-Value模型:
这里举一个例子,Key-Value就好像是《水浒传》里面【人物名字】与【江湖外号】的关系,宋江的外号是及时雨,宋江对应Key,及时雨对应Value。Value可以存储关键字Key的信息。
又比如,在一篇英文文章中,可以将文章中出现过的每一个单词称之为Key,而Value值可以用来记录每一个Key单词出现了几次。
2、纯Key模型:
而纯Key模型的意思也仅仅是Key-Value模型没有了Value而已!其他都是相同的!
【此时看不懂也没有关系,我觉得还是实际了解Map和Set里面的方法会更加好理解!】
三、Map的使用
Map其实是一个【接口】,【TreeMap类】实现了这个【接口】,并且,TreeMap类底层就是我们前面所学的【二叉搜索树】!这也就是前面我们为什么要学习二叉搜索树的原因!
另外,该接口存储的是Key-Value结构的【键值对】,并且Key一定是【唯一】的,不能重复!
【Map常用方法】
1、V put(K key,V value)&&V get(Object key)
【功能】
put(K key,V value):设置key对应的value
V get(Object key):返回key对应的value
【实例1】
给key设置过value的情况:
public class Test {public static void main(String[] args) {Map<String,String> map=new TreeMap<>();//给key设置valuemap.put("宋江","及时雨");map.put("孙悟空","齐天大圣");//使用val来接收get方法的返回值String val=map.get("宋江");System.out.println(val);String val2=map.get("孙悟空");System.out.println(val2);}
}
程序运行:
打印出来key对应的value值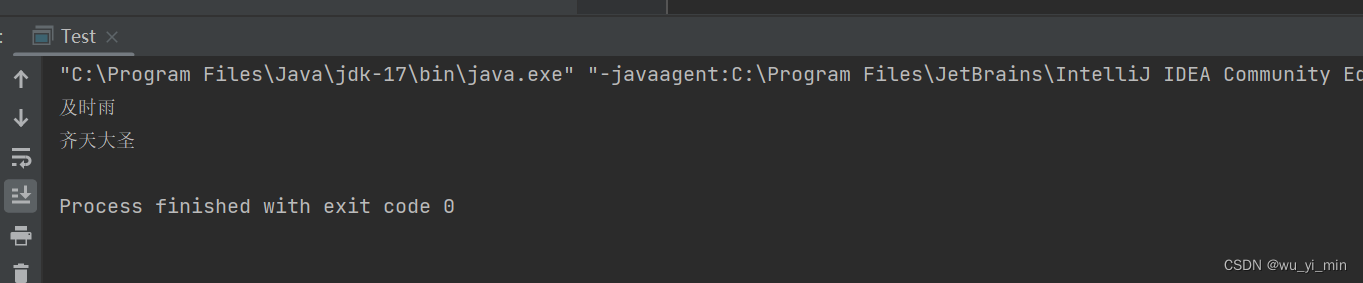
【实例2】
没有给key设置value的情况:
public class Test {public static void main(String[] args) {Map<String,String> map=new TreeMap<>();map.put("宋江","及时雨");map.put("孙悟空","齐天大圣");//使用val来接收get方法的返回值String val=map.get("宋江2");//没有给"宋江2"设置过valueSystem.out.println(val);}
}
程序运行:
get的返回值是null
2、V getOrDefault(Object key,V defaultValue)
【功能】
返回key对应的value,如果key不存在,返回默认值defaultValue
【实例】
public class Test {public static void main(String[] args) {Map<String,String> map=new TreeMap<>();map.put("宋江","及时雨");//关键字存在,返回关键字的valueString val=map.getOrDefault("宋江","hhhhh");System.out.println(val);//关键字不存在,返回传入的默认值String val2=map.getOrDefault("宋江1","hhhhhhh");System.out.println(val2);}
}
程序运行:
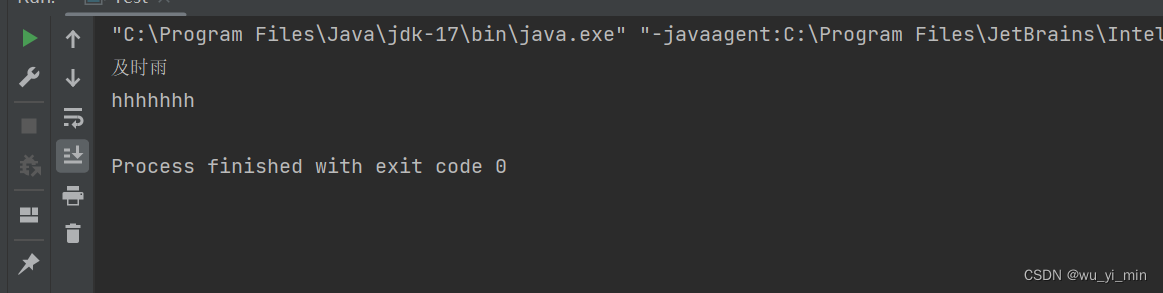
3、V remove(Object key)
【功能】
删除key对应的映射关系
【实例】
public class Test {public static void main(String[] args) {Map<String,String> map=new TreeMap<>();map.put("宋江","及时雨");map.put("孙悟空","齐天大圣");String val=map.remove("孙悟空");//返回值是要删除的关键字的valueSystem.out.println(val);}
}

4、Set<K> keySet()
【功能】
返回所有的key,存储在集合Set中。
【实例】
public class Test {public static void main(String[] args) {Map<String,String> map=new TreeMap<>();map.put("宋江","及时雨");map.put("孙悟空","齐天大圣");//返回所有的key,存储在set中Set<String> set=map.keySet();System.out.println(set);}
}

5、Set< Map.Entry<K,V> > entrySet( )
【功能】
返回所有的Key-Value映射关系 ,存储在Set中
【实例】
public class Test {public static void main(String[] args) {Map<String,String> map=new TreeMap<>();map.put("宋江","及时雨");map.put("孙悟空","齐天大圣");//返回所有的key-Value,存储在set中Set<Map.Entry<String,String>> entries =map.entrySet();System.out.println(entries);}
}
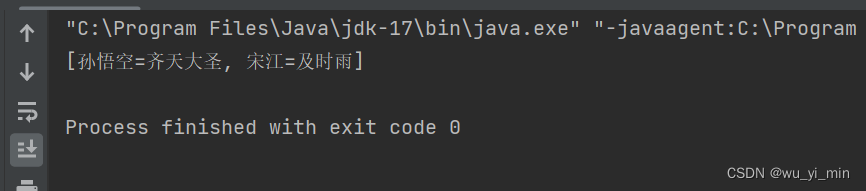
【注意事项】
1、Map是一个接口,不能直接实例化对象,如果要实例化对象只能实例化其实现该接口的类TreeMap和HashMap
2、Map中存放键值的Key是唯一的,而Value是可以重复的
3、Map存入的Key必须是可以比较的,如果Key是自定义类型的类,一定要提供比较方式!
4、Map中的Key不能修改,但是Key对应的Value可以修改,如果要修改Key,只能先删除,再重新插入!
四、Set的使用
【注意事项】
1、Set与Map不同的点在于:Set只存储了Key,并没有Value;
2、与Map相同的是,Set也不能存储重复的Key;
3、实现Set接口常见的类:TreeSet和HashSet
【Set常用方法】
方法: 功能:
boolean add(E e) 添加元素,但是重复元素不会被添加
void clear() 清空集合
boolean contains(Object o) 判断o是否在集合中
boolean remove(Object o) 删除集合中的o
int size() 返回set中的元素个数
boolean isEmpty() 检测set是否为空,为空返回true,不为空返回false
五、哈希表
【概念】
在【顺序表】和【平衡树】中,元素与关键字与其存储的位置没有对应的关系,因此在查找一个元素的时候,必须要经过关键字的多次比较,搜索的效率取决于搜索过程中元素的比较次数。
这里我们想要一种理想的搜索方法,可以不经过任何比较,一次直接就从表中得到要搜索的元素。就好比摆在我们面前有50个不一样的锁,再给我们一个钥匙,我们要想找到这个钥匙对应的锁,如果钥匙和锁之间没有标记,我们只能拿着钥匙一个一个尝试,直至找到匹配的锁才行,但是,如果每一把锁都有标记数字,这个钥匙也有标记数字,1号钥匙可以打开1号锁,2号钥匙可以打开2号锁……那么,我们只需要根据锁和钥匙之间的【映射关系】,直接找到对应的锁就行了!
如果要实现以上理想的搜索方法,就要构造一种【存储结构】,通过某个【函数】(HashFunc/哈希函数)使元素的【存储位置】与它的【关键字】之间能够建立【一 一映射】的关系,那么在查找时,我们就可以很快找到元素!
最后,这种结构就是我们要学习的【哈希表】
当向该结构中:
【插入元素】:
根据插入元素的关键字,以此函数【计算】出该元素的存储位置并按此位置进行存放!
【搜索元素】:
对元素的关键字进行同样的计算,把求得的函数值当做元素的存储位置,在结构中按此位置取元素进行比较,若关键字对等,则搜索成功!
【哈希函数】
介绍【哈希函数】我还是举一个例子,这样比较好懂:
现在,我们有一个数据集合{1,7,6,4,5,9}
哈希函数设置为:hash(key)=key%capacity (capacity为存储元素底层空间的总的大小)
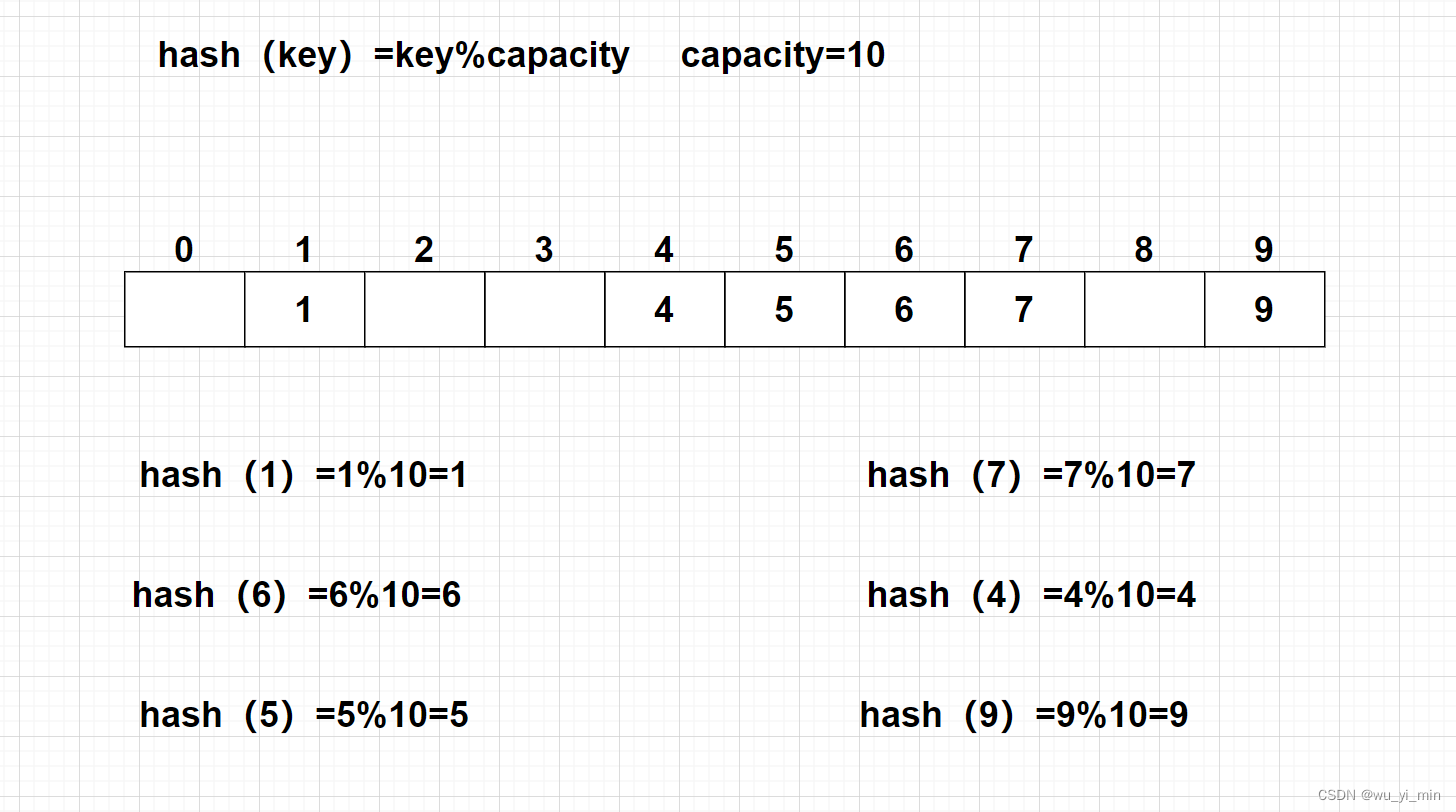
1、【哈希冲突】
按照这种计算方法,那么毫无疑问,会出现下面这种情况:
假如现在该结构要添加关键字为【14】的元素,根据哈希函数计算,应该存入下标为4的数组中,可是原结构的该位置,已经存储了关键字为【4】的元素!这种情况就是【哈希冲突】!
【哈希冲突】可以理解为关键字不同的元素根据哈希函数,计算出来相同的存储位置!
首先,我们要明确一个点,冲突的发生是必然的,无法避免,但我们应该尽量【降低冲突率】!
讲到冲突率,让我们来认识一个与【冲突率】有关的新概念:载荷因子
哈希表的【载荷因子】定义为:ɑ=填入表中的元素 / 哈希表的长度
一般来说,载荷因子越大,冲突率越高!
降低载荷因子的方法是:扩容!
2、【解决哈希冲突的方法】
解决哈希冲突一般采用两种方法:【闭散列】和【开散列】
【闭散列】
闭散列也叫开放地址法,当发生哈希冲突时,如果哈希表【未被填满】,说明哈希表还有空位置,那么可以把key存放在冲突位置的【下一个】空位置中。
找空位置这里提供两种方法:
1、线性探测:
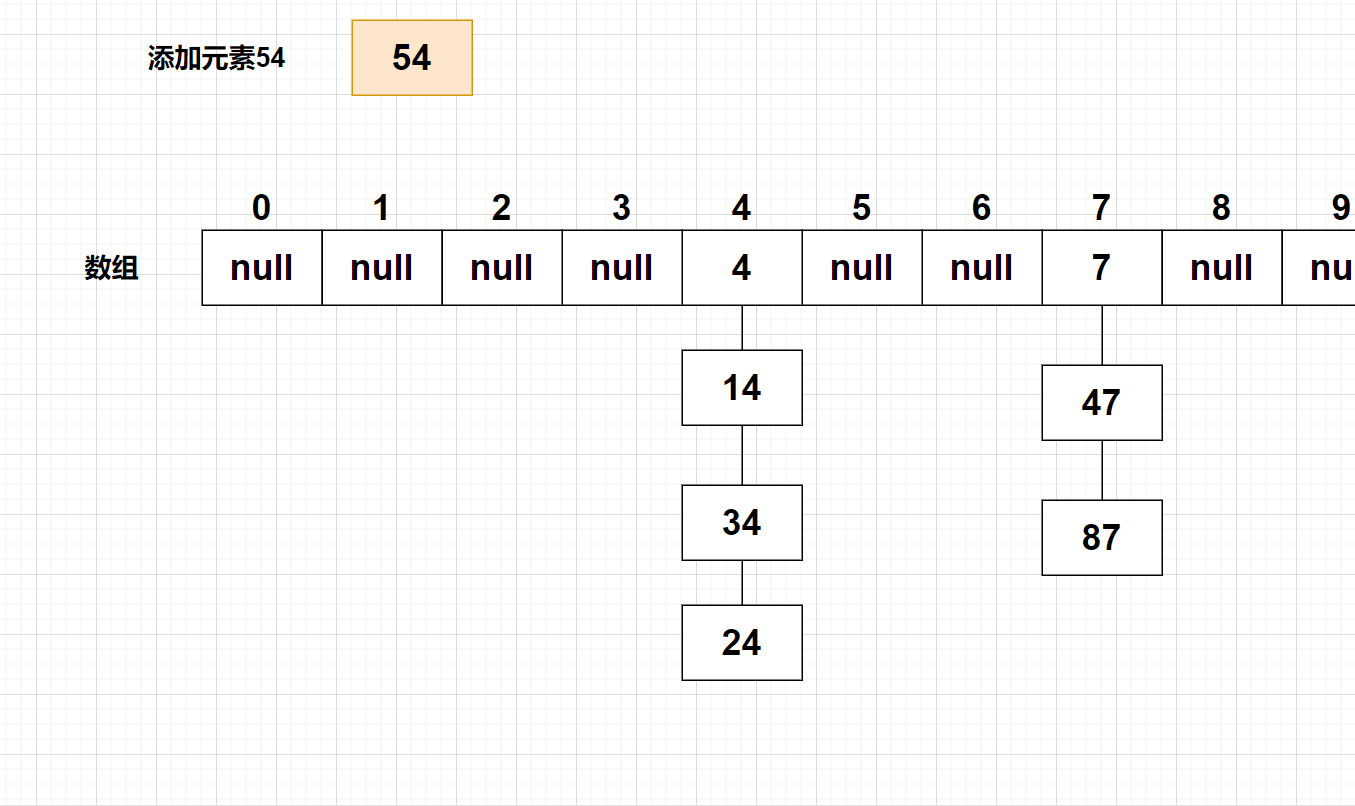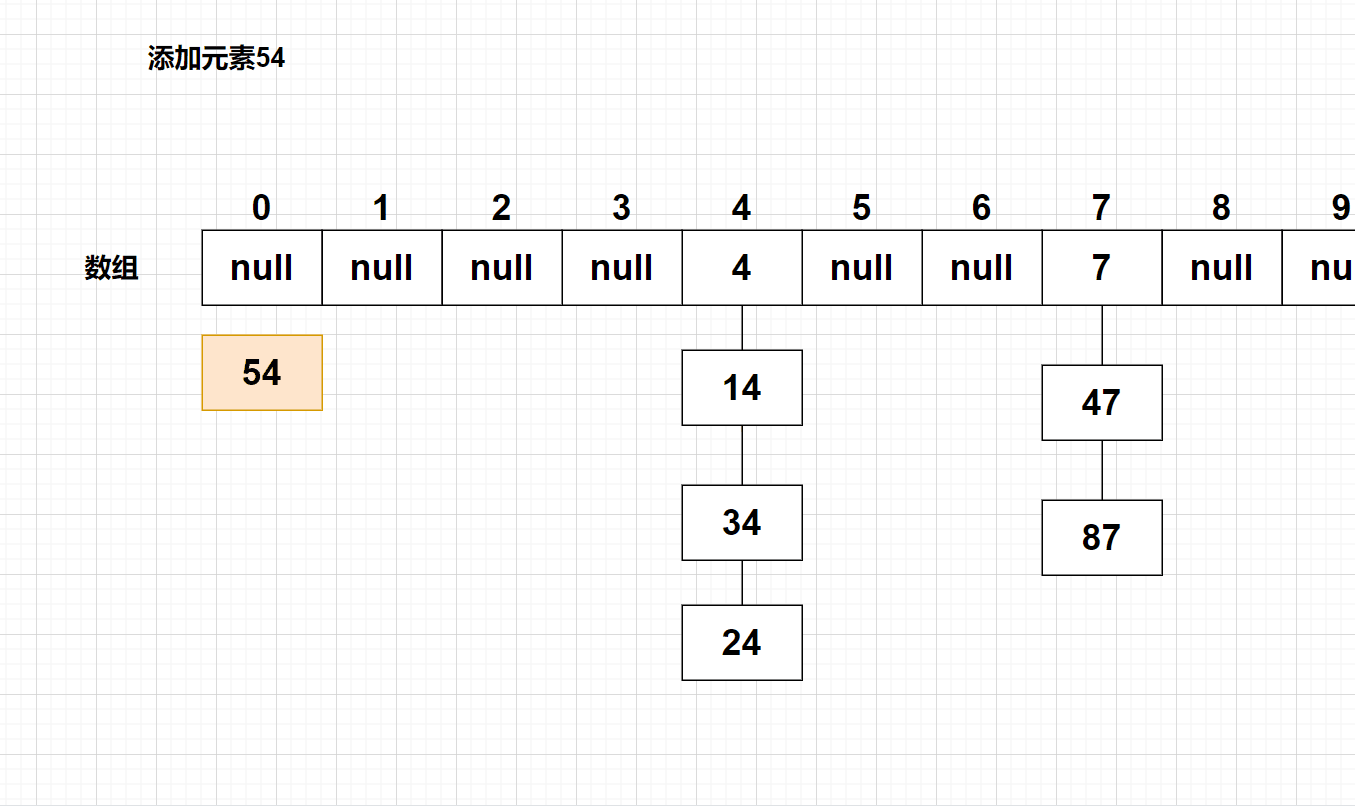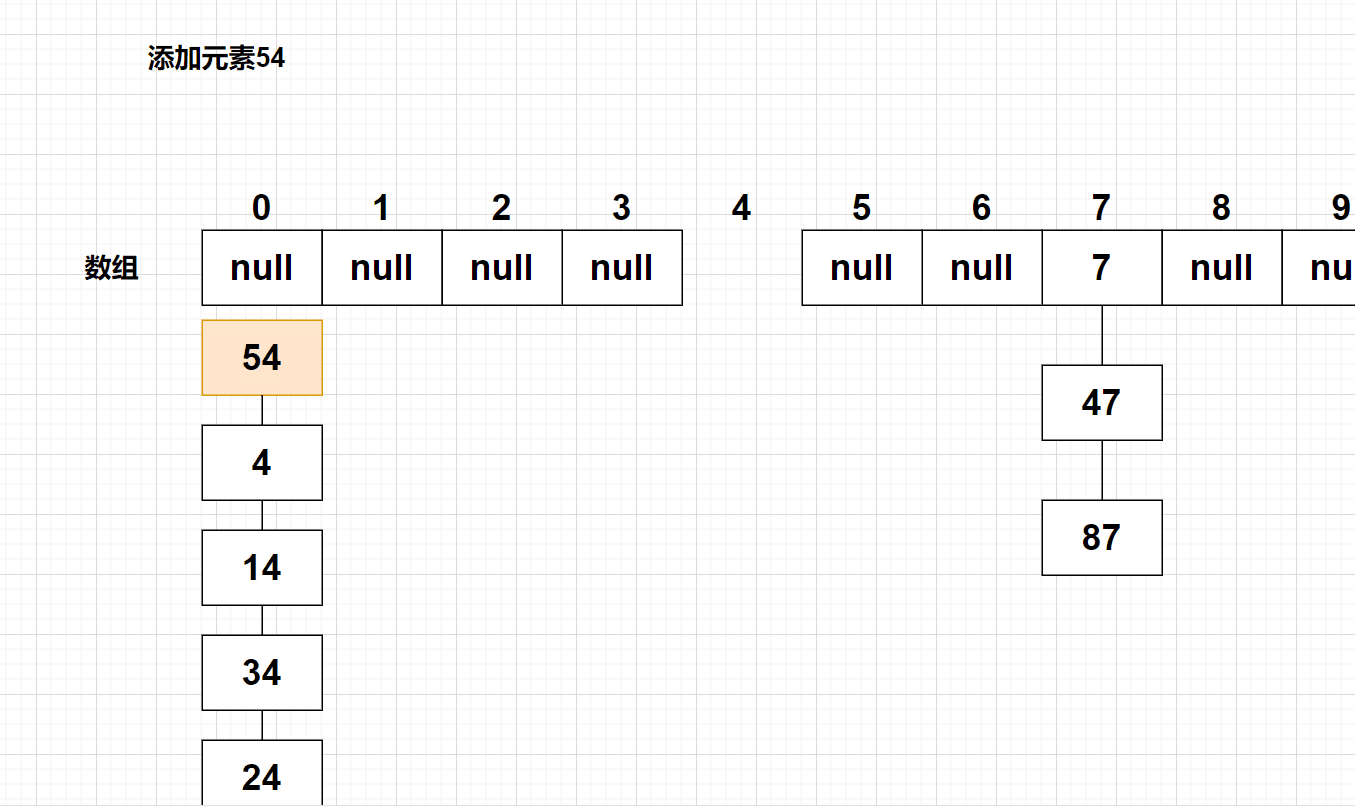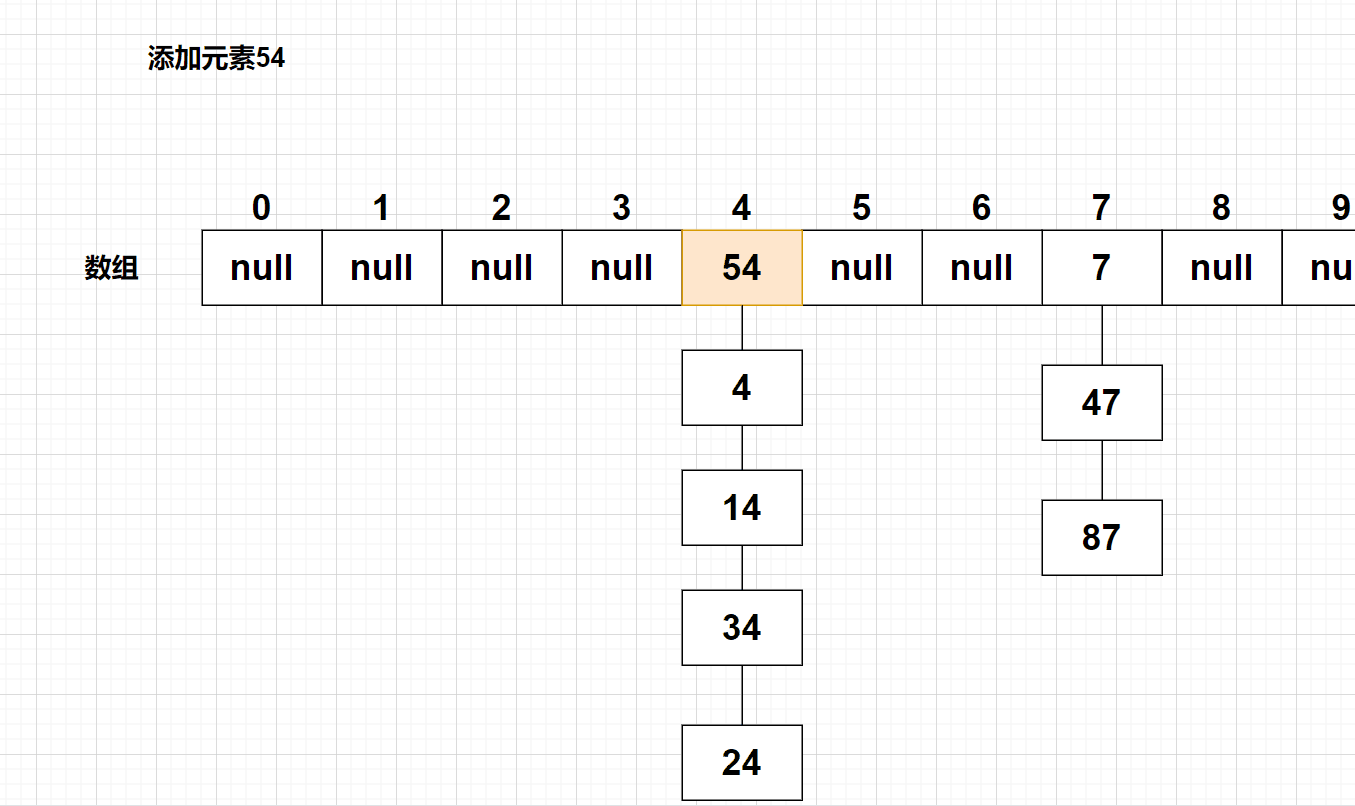
例如,在以下哈希表中,我们还要插入元素{14,24,34}
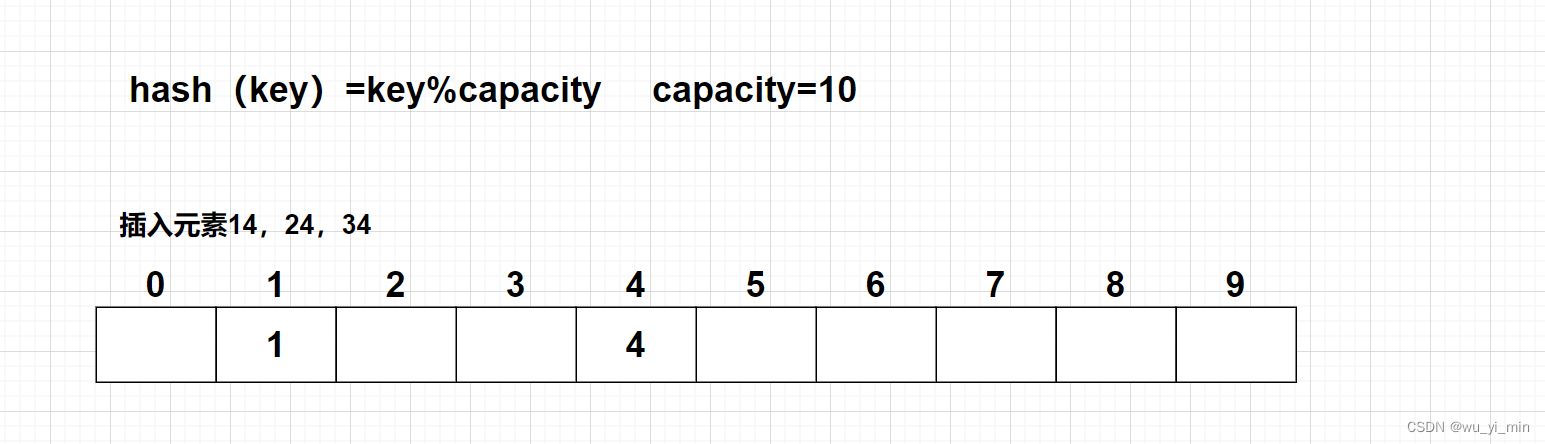
这三个数有共同的特点:根据哈希函数计算,应该存入下标4的位置,可是该位置已经有元素了!
那么,就要采用【线性探测】方法,找到存储位置的【下一个空位置】,存入元素!

2、 二次探测
线性探测有一个缺点:有可能会让冲突的元素集中在一个地方,正如上面的例子!为解决该问题我们可以采用二次探测!
二次探测找空位置的方法为:
新位置下标值=(存储位置下标值 + i 的平方)% 哈希表长度
第一次计算时,i=1,第二次计算时,i=2,以此类推

【开散列】(哈希桶)
开散列又叫【链地址法】,首先对【关键字集合】用【哈希函数】计算其【存储下标】,将具有相同地址的关键字归于【同一子集合】,每一个子集合称为【一个桶】,桶中的每一个元素通过单【单链表】连接起来,各个链表的【头节点】存储在【哈希表】中。
哈希桶可以理解为【数组+链表】的组合,哈希表存储的元素为链表节点!
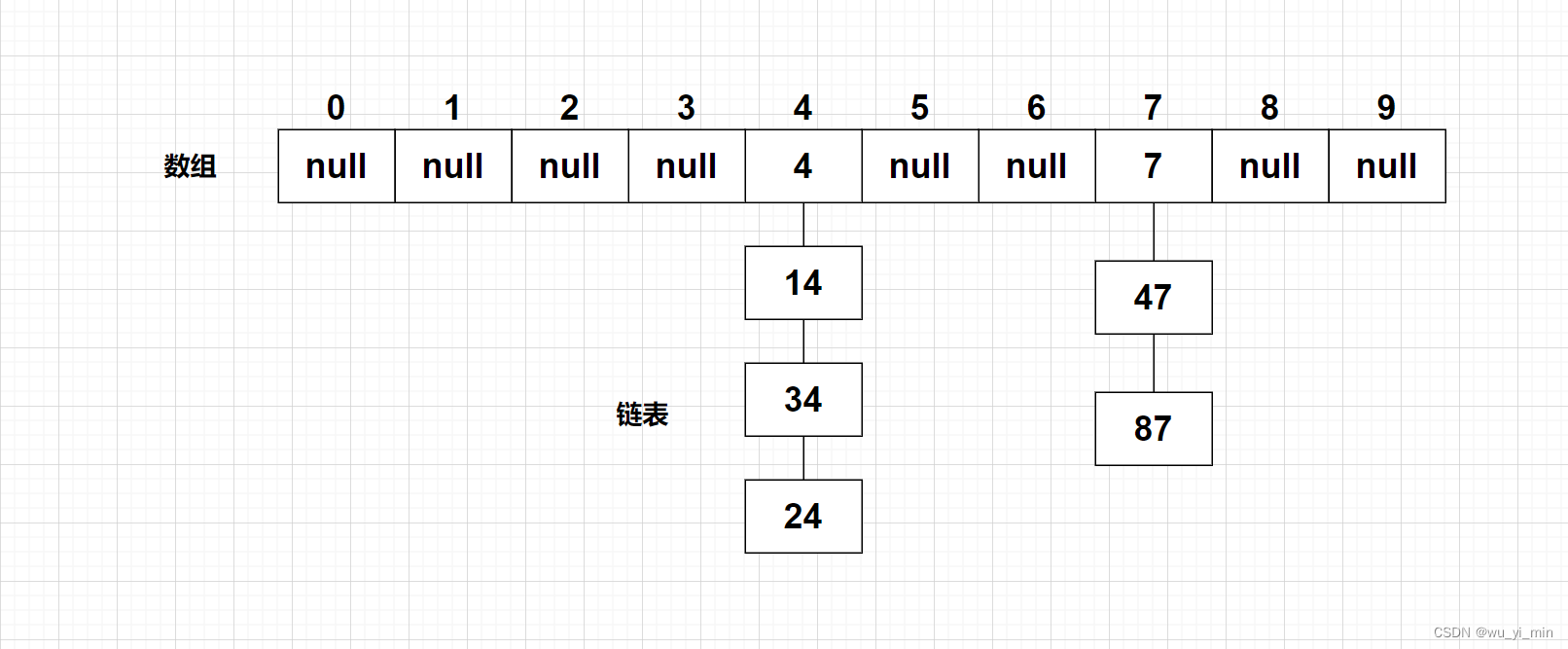
六、模拟实现【哈希桶】
首先,我们创建一个类:HashBuck类!在这个类当中,我们定义一个内部类:Node类!
public class HashBuck {//定义节点类(内部类)static class Node{//成员变量public int key;public int value;public Node next;//构造方法public Node(int key,int value ){this.key=key;this.value=value;}}//哈希表public Node[] array;public int usedSize;//记录哈希表存储元素个数public double loadFactor=0.75;//载荷因子默认为0.75//初始化哈希表public HashBuck(){//默认容量为10array=new Node[10];}
}1、【添加元素方法】
【基本思想】
给哈希表添加元素这个方法主要可以划分4个步骤:
1、根据关键字计算出存储位置的下标
计算下标的哈希函数:HashFunc(key)=key%哈希表容量
2、遍历该存储位置所在的链表,判断其关键字是否已经存在,存在则更新其value即可,不能重复添加包含相同的关键字的元素
3、在该存储位置所在的链表找不到该关键字,则使用【头插法】添加该元素
4、计算【载荷因子】的大小,如果载荷因子大于默认值0.75,则该哈希表需要扩容
扩容的时候,一般采用2倍扩容,扩容之后,由于其哈希函数: HashFunc(key)=key%哈希表容量 与 【哈希表容量】有关,因此需要将表中的每一个元素重新放置!
【代码实现】
//添加元素方法public void put(int key,int value){//1、先根据关键字计算出存储下标int index=key%array.length;Node cur=array[index];//2、看看该关键字是否已经存在,存在则更新其value即可while (cur!=null){if(cur.key==key){cur.value=value;return;}cur=cur.next;}//3、找不到该关键字,使用【头插法】添加该元素Node node=new Node(key,value);node.next=array[index];array[index]=node;usedSize++;//4、判断【载荷因子】是否大于默认值,大于则扩容if(loadFactorCount()>=loadFactor){reSize();}}//计算载荷因子方法private double loadFactorCount(){return usedSize*1.0/array.length;}//扩容方法private void reSize(){//2倍扩容Node[] newArray=new Node[2*array.length];//对哈希表中元素进行重新放置for(int i=0;i<array.length;i++){Node cur=array[i];while(cur!=null){Node curN=cur.next;//移动元素到新的位置int newIndex=cur.key%newArray.length;cur.next=newArray[newIndex];newArray[newIndex]=cur;//cur往下遍历cur=curN;}}//将【旧哈希表】的引用更新为【新哈希表】的引用array=newArray;}2、【获取value值的方法】
//获取value值方法public int get(int key){//计算出该下标的位置int index=key%array.length;Node cur=array[index];//遍历当前链表,看看是否存在该关键字while(cur!=null){if(cur.key==key){return cur.value;}cur=cur.next;}//找不到该关键字return -1;}
七、泛型类【哈希桶】
1、【类对象获取哈希值】
学到这里,我们发现目前存入的【关键字】是一个int类型的数据,可以通过哈希函数计算下标值,那么,如果存入的关键字是一个【类对象】,该如何计算其存储位置的下标呢?
这里我举一个例子:
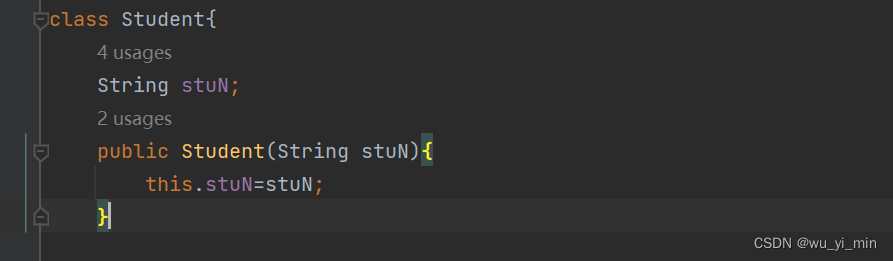
首先,我们实例化一个Student类,该学生类有成员变量stuN表示学号!
接下来,实例化两个学生类对象,将其存入哈希表中!在此之前,我们得想办法将对象转换为整型数据,这里可以使用hashCode方法,每一个对象都可以通过调用该方法,返回一个int类型的数据!这个数称为【哈希值】,我们可以将其视为该对象的【关键字】,计算出来该对象的存储位置下标!
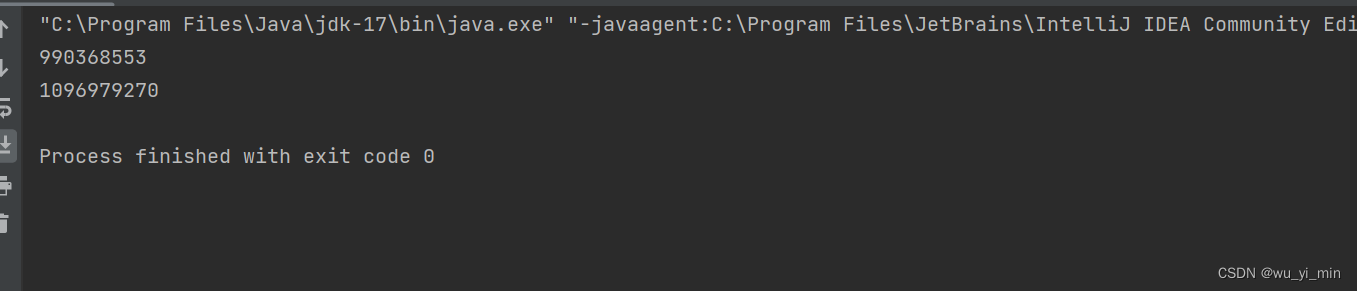
public class Test {public static void main(String[] args) {Student student1=new Student("123");Student student2=new Student("123");//调用hashCode方法int hashcode1=student1.hashCode();int hashcode2=student2.hashCode();System.out.println(hashcode1);System.out.println(hashcode2);}
}我们认为,学号相同的学生可以被认为是同一个学生,但是具有相同学号的对象调用hashCode方法返回的哈希值 并不是相同的,因此,我们需要在该类中重写hashCode方法和equals方法!
 【重写方法】具体步骤:
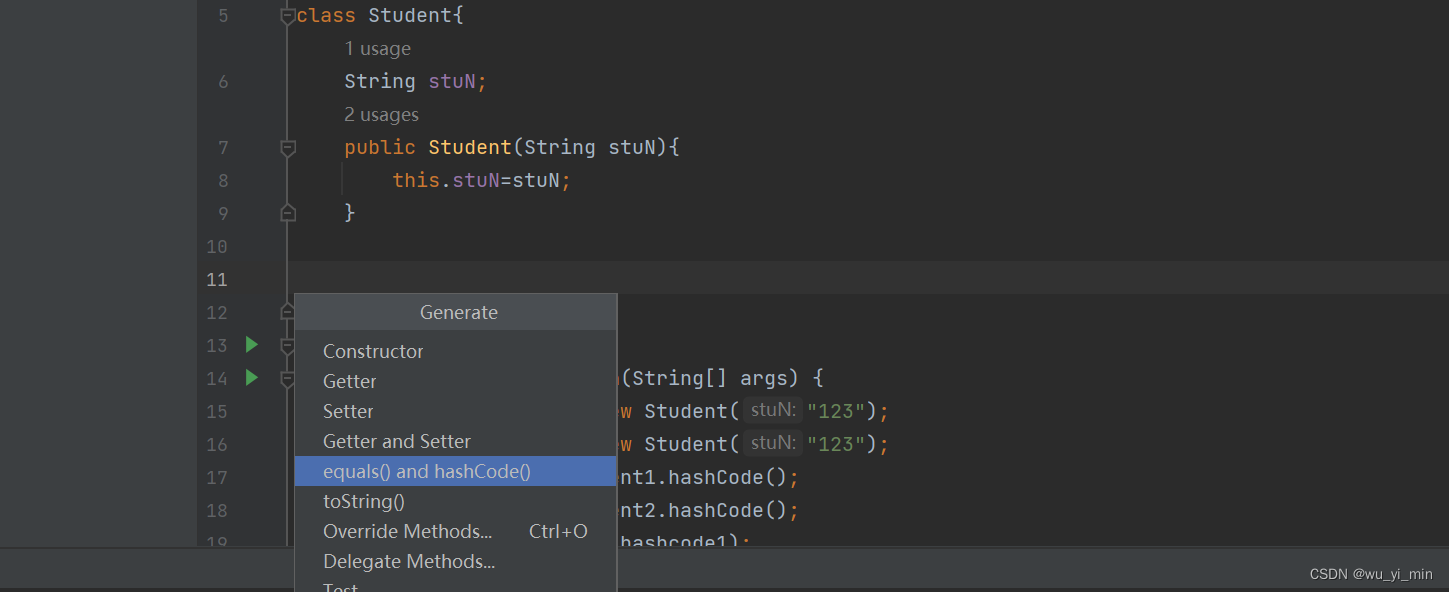
【重写方法】具体步骤:
1、 这里可以使用快捷建【insert+insert】,弹出以下画面,选中【蓝色选项】
2、接下来一直按next,直到出现create,按下即可!

重写方法后,重新运行代码,会发现student1和student2产生了相同的哈希值!

2、【泛型类哈希桶代码】
//泛型类的【哈希桶】
class HashBuck1<K,V>{//定义节点类(内部类)static class Node<K,V>{public K key;public V val;public Node<K,V> next;public Node(K key,V val){this.key=key;this.val=val;}}//哈希表public Node<K,V>[] array;public int usedSize;public double loadFactor=0.75;//初始化哈希表public HashBuck1(){array=new Node[10];//默认数组容量是10}//添加元素方法:public void put(K key,V val){//1、获取对象的哈希值,根据哈希值计算存储地址的下标int hash=key.hashCode();int index=hash%array.length;Node<K,V> cur=array[index];//2、判断该对象是否已经存入哈希表中while(cur!=null){if(cur.key.equals(cur.key)){cur.val=val;return;}cur=cur.next;}//3、该列表不存在该对象,添加该对象Node<K,V> node=new Node(key,val);node.next=array[index];array[index]=node;usedSize++;//4、计算载荷因子,如果过大,扩容if(loadFactorCount()>=loadFactor){reSize();}}//计算载荷因子方法;private double loadFactorCount(){return usedSize*1.0/array.length;}//扩容方法:private void reSize(){Node<K,V>[] newArray=new Node[2*array.length];//对哈希表中元素进行重新放置for(int i=0;i<array.length;i++){Node<K,V> cur=array[i];while(cur!=null){Node<K,V> curN=cur.next;int hash=cur.key.hashCode();int newIndex=hash%newArray.length;cur.next=newArray[newIndex];newArray[newIndex]=cur;cur=curN;}}array=newArray;}//获取value值的方法;public V get(K key){int hash=key.hashCode();int index=hash%array.length;Node<K,V> cur=array[index];while(cur!=null){if(cur.key.equals(key)){return cur.val;}cur=cur.next;}return null;}
}