写在前面
关于数据科学环境的建立,可以参考我的博客:
【深耕 Python】Data Science with Python 数据科学(1)环境搭建
往期数据科学博文一览:
【深耕 Python】Data Science with Python 数据科学(2)jupyter-lab和numpy数组
【深耕 Python】Data Science with Python 数据科学(3)Numpy 常量、函数和线性空间
【深耕 Python】Data Science with Python 数据科学(4)(书337页)练习题及解答
【深耕 Python】Data Science with Python 数据科学(5)Matplotlib可视化(1)
【深耕 Python】Data Science with Python 数据科学(6)Matplotlib可视化(2)
【深耕 Python】Data Science with Python 数据科学(7)书352页练习题
【深耕 Python】Data Science with Python 数据科学(8)pandas数据结构:Series和DataFrame
【深耕 Python】Data Science with Python 数据科学(9)书361页练习题
【深耕 Python】Data Science with Python 数据科学(10)pandas 数据处理(一)
【深耕 Python】Data Science with Python 数据科学(11)pandas 数据处理(二)
【深耕 Python】Data Science with Python 数据科学(12)pandas 数据处理(三)
【深耕 Python】Data Science with Python 数据科学(13)pandas 数据处理(四):书377页练习题
【深耕 Python】Data Science with Python 数据科学(14)pandas 数据处理(五):泰坦尼克号亡魂 Perished Souls on “RMS Titanic”
【深耕 Python】Data Science with Python 数据科学(15)pandas 数据处理(六):书385页练习题
【深耕 Python】Data Science with Python 数据科学(16)Scikit-learn机器学习(一)
【深耕 Python】Data Science with Python 数据科学(17)Scikit-learn机器学习(二)
代码说明: 由于实机运行的原因,可能省略了某些导入(import)语句。
本期,简单地使用scikit-learn库完成K-Means聚类算法。
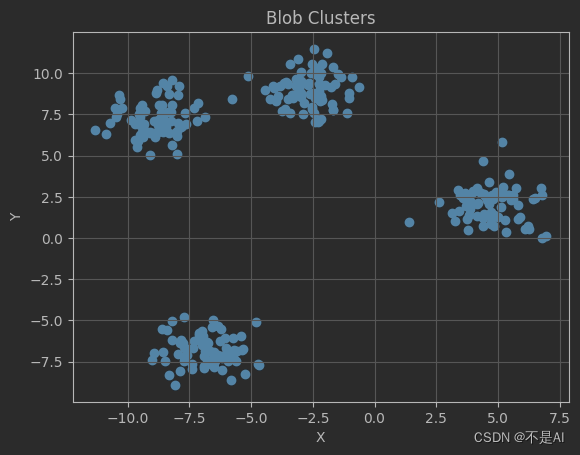
一、生成随机数据簇
python">from sklearn.datasets import make_blobs
import matplotlib.pyplot as pltX, _ = make_blobs(n_samples=300, centers=4, random_state=42)
fig, ax = plt.subplots()
ax.scatter(X[:, 0], X[:, 1])
plt.title("Blob Clusters")
plt.xlabel("X")
plt.ylabel("Y")
plt.grid()
plt.show()
程序输出:
二、在数据集上调用KMeans聚类算法
python">from sklearn.cluster import KMeanskmeans = KMeans(n_clusters=4)
kmeans.fit(X)
centers = kmeans.cluster_centers_
print(centers)
程序输出:
python">[[-2.70981136 8.97143336] # center 1[-6.83235205 -6.83045748] # center 2[ 4.7182049 2.04179676] # center 3[-8.87357218 7.17458342]] # center 4
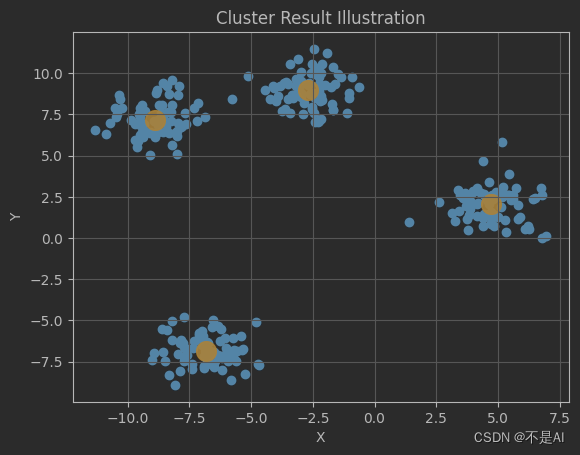
四、聚类结果可视化
使用matplotlib库将上述的聚类结果可视化:
python">fig, ax = plt.subplots()
ax.scatter(X[:, 0], X[:, 1])
ax.scatter(centers[:, 0], centers[:, 1], s=200, alpha=0.9, color="orange")
plt.title("Cluster Result Illustration")
plt.xlabel("X")
plt.ylabel("Y")
plt.grid()
plt.show()
程序输出:
参考文献 Reference
《Learn Enough Python to be Dangerous——Software Development, Flask Web Apps, and Beginning Data Science with Python》, Michael Hartl, Boston, Pearson, 2023.