一、概述
随着新一代信息技术在产业数字化中的应用,产生了大量多源多模态信息以及响应的信息处理模式,数据孤岛、模型林立的问题也随之产生,使得业务系统臃肿、信息处理和决策效率低下,面对复杂任务及应用场景问题求解效率低。针对信息处理模型林立、模型协同难的问题,研究大小模型协同机制,基于开源大模型建立包括提示词、任务规划、任务执行、记忆、人工反馈等的大模型系统是解决该问题的一个尝试。
建立数据库链接、信息系统 API 调用、文档解析、多模态信息处理、模型链接及调用、智能体协同调用的工具生成技术;通过构建大模型系统驱动小模型、领域模型协同、多智能体协同的决策框架,将散落的信息、数据、系统、模型、智能体有效协同,实现基于多智能体的空间管理运管决策,一方面降低业务侧信息系统的臃肿,信息的流转和处理有效协同,另一方面提升信息系统解决产业数字化及业务决策中复杂、多流程的任务及场景,降低信息系统管理和使用门槛,从而达到降本增效的目的。
为此,我们搭建了以下的一个多智能体协作的框架,通过构建一个集合了专业/领域模型的工具库,利用大语言模型的语言理解、任务拆解、代码输出等能力调度各类模型,并支持基于结果的迭代更新。
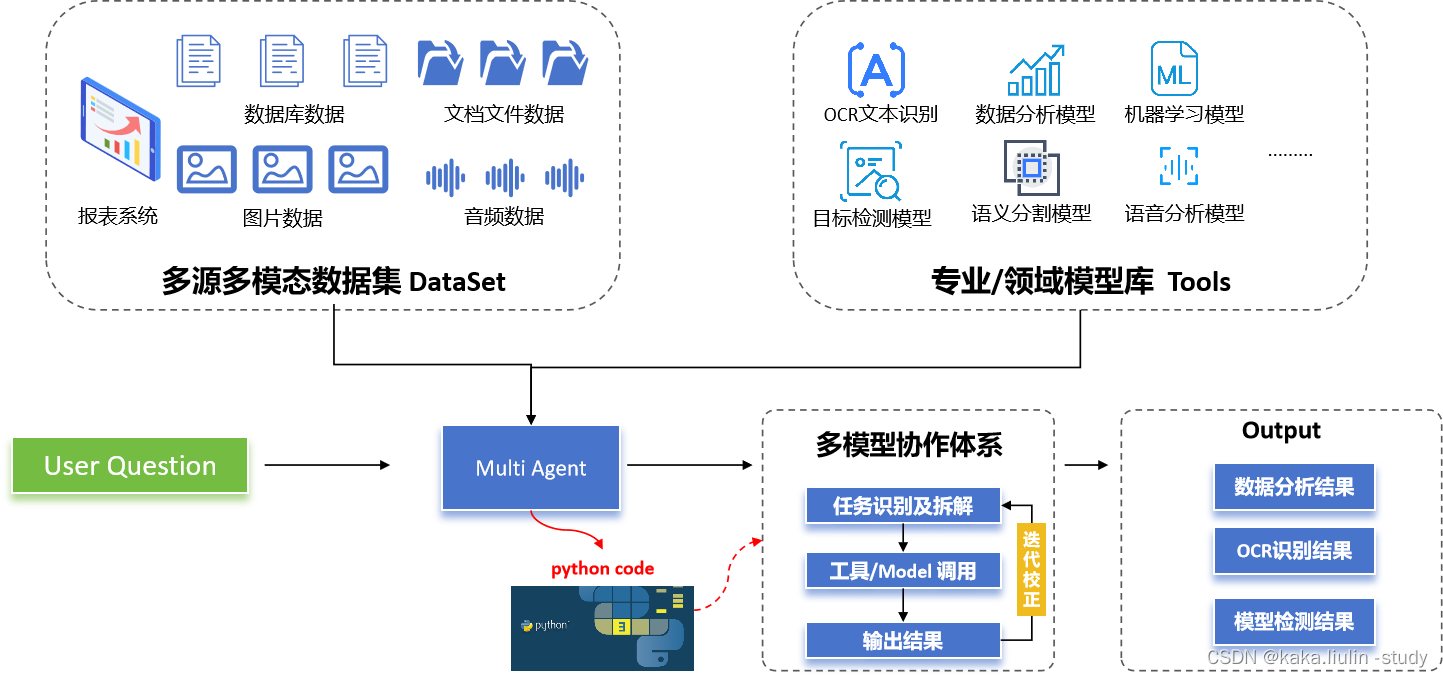
二、小模型的构建
本次实践构建了基于paddlepaddle 的OCR模型、图片描述模型、SKlearn的时间序列模型等小模型。
① OCR模型
OCR模型一般用于解析图片信息并提取结构化数据,本文的实践借助paddle OCR中的表格信息提取模型实现。
#安装相关依赖
!pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
!pip3 install -U https://paddleocr.bj.bcebos.com/whl/layoutparser-0.0.0-py3-none-any.whl
!pip install "paddleocr>=2.2"
构建表格识别模型并测试验证
import os
import cv2
from paddleocr import PPStructure,draw_structure_result,save_structure_restable_engine = PPStructure(show_log=True)save_folder = './output/table'
img_path = '1713940615272.jpg'
img = cv2.imread(img_path)
result = table_engine(img)
save_structure_res(result, save_folder,os.path.basename(img_path).split('.')[0])for line in result:line.pop('img')print(line)from PIL import Imagefont_path = '../doc/fonts/simfang.ttf' # PaddleOCR下提供字体包
image = Image.open(img_path).convert('RGB')
im_show = draw_structure_result(image, result,font_path=font_path)
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')
检测结果:
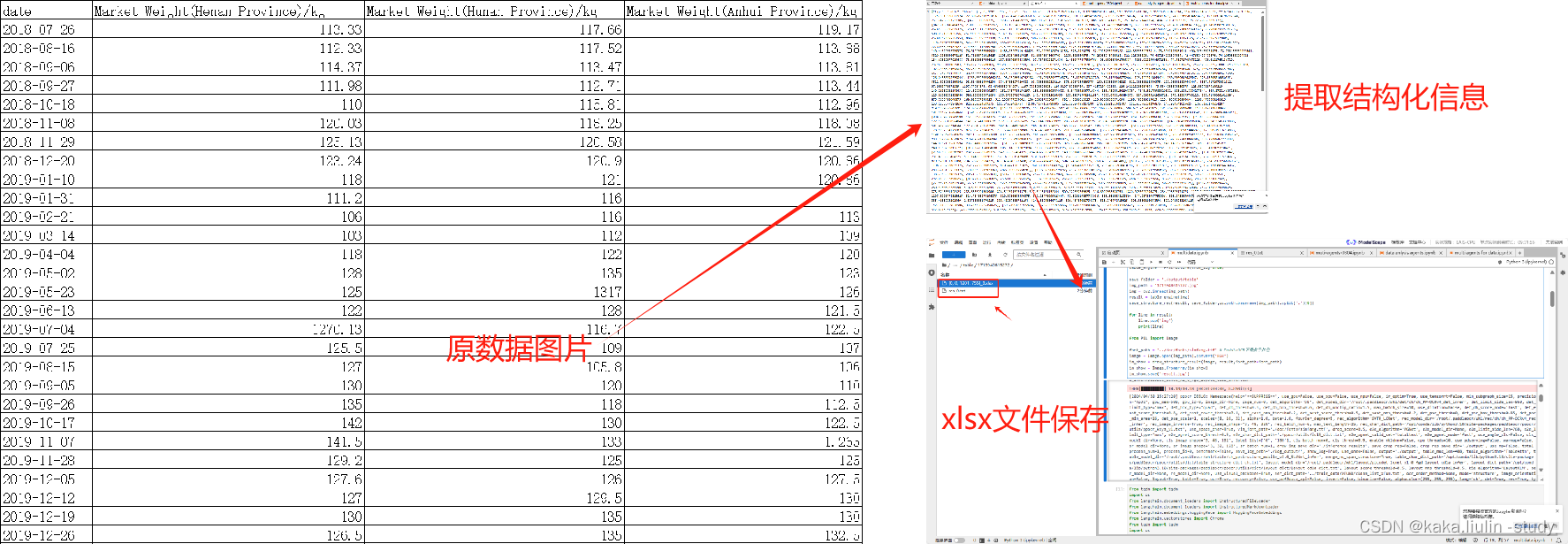
将上述paddle OCR模型转换成Multi Agents的工具之一:“Image to Txt Tool”
class ImageToTxtTool(BaseTool):name = "Image to Txt Tool"description = 'This is a tool designed to extract structured data from images and save it as a spreadsheet.'def _run(self, img_path: str):table_engine = PPStructure(show_log=True)save_folder = './output/table'img = cv2.imread(img_path)result = table_engine(img)save_structure_res(result, save_folder,os.path.basename(img_path).split('.')[0])for line in result:line.pop('img')print(line)return resultdef _arun(self, query: str):raise NotImplementedError("Async operation not supported yet")tools = [ImageToTxtTool]
② 多模态:图片转文字模型
随着多模态信息处理的需求,越来越多的信息类型需要相互转换,如图片转文字、文字生成图片、语音转文字等。本次实践使用一个图片描述模型,该模型来自ModelScope社区,测试多智能体系统借助小模型如何处理多模态信息。
import os
import shutil
from modelscope.utils.hub import snapshot_download
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
from modelscope.outputs import OutputKeys
from modelscope.utils.constant import ModelFilepretrained_model = 'damo/ofa_pretrain_large_en'
pretrain_path = snapshot_download(pretrained_model, revision='v1.0.2')
task_model = 'damo/ofa_image-caption_coco_large_en'
task_path = snapshot_download(task_model)shutil.copy(os.path.join(task_path, ModelFile.CONFIGURATION), # 将任务的配置覆盖预训练模型的配置os.path.join(pretrain_path, ModelFile.CONFIGURATION))#ofa_pipe = pipeline(Tasks.image_captioning, model=pretrain_path)
#result = ofa_pipe('20980534 (1).jpg')
#print(result[OutputKeys.CAPTION]) def describeImage(image_url):ofa_pipe = pipeline(Tasks.image_captioning, model=pretrain_path)result = ofa_pipe(image_url)return result[OutputKeys.CAPTION]
测试图文生成模型
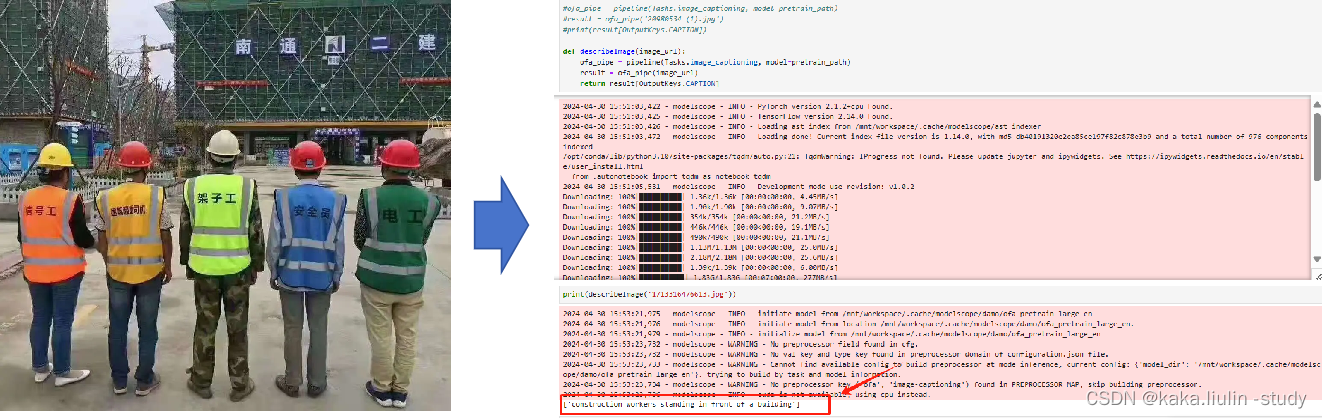
将其改造成多智能体系统的工具之一:“Describe Image Tool”
class DescribeImageTool(BaseTool):name = "Describe Image Tool"description = 'use this tool to describe an image.'def _run(self, url: str):pretrained_model = 'damo/ofa_pretrain_large_en'pretrain_path = snapshot_download(pretrained_model, revision='v1.0.2')task_model = 'damo/ofa_image-caption_coco_large_en'task_path = snapshot_download(task_model)shutil.copy(os.path.join(task_path, ModelFile.CONFIGURATION), # 将任务的配置覆盖预训练模型的配置os.path.join(pretrain_path, ModelFile.CONFIGURATION))ofa_pipe = pipeline(Tasks.image_captioning, model=pretrain_path)result = ofa_pipe(url)return result[OutputKeys.CAPTION]def _arun(self, query: str):raise NotImplementedError("Async operation not supported yet")tools = [DescribeImageTool()]
③ 机器学习:时间序列数据预测
通过机器学习模型分析结构化数据,尤其是时间序列数据,越来越重要。通过分类、聚类、回归、相关性、因素分析等机器学习方法分析业务数据,透视生产、经营、运营、营销等业务业态态势,是产业数字化的核心。本次构建了一个时间序列模型预测生猪市场价格的趋势,并尝试利用大语言模型系统调度该模型去完成任务。
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
import warnings
warnings.filterwarnings("ignore")
from langchain.tools import BaseTool
from sklearn.svm import SVR
data = pd.read_csv('/content/drive/MyDrive/LLM_Agents/data/Weekly price of commercial pigs.csv')
X = data.iloc[2:300,2:5]
y = data.iloc[2:300,6]X = np.array(X)
y = np.array(y)# 划分数据集为训练集(70%)和测试集(30%)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)# 创建并训练线性回归模型
model = SVR(kernel='linear', C=3)
model.fit(X_train, y_train)
input = pd.read_csv('/content/drive/MyDrive/LLM_Agents/data/Weekly price of commercial pigs.csv')
input = np.array(input.iloc[200:230,2:5])# 预测测试集结果
y_pred = model.predict(X_test)# 计算均方误差(MSE)作为评估指标
mse = mean_squared_error(y_test, y_pred)#根据用户输入预测结果
y_predict = model.predict(input)
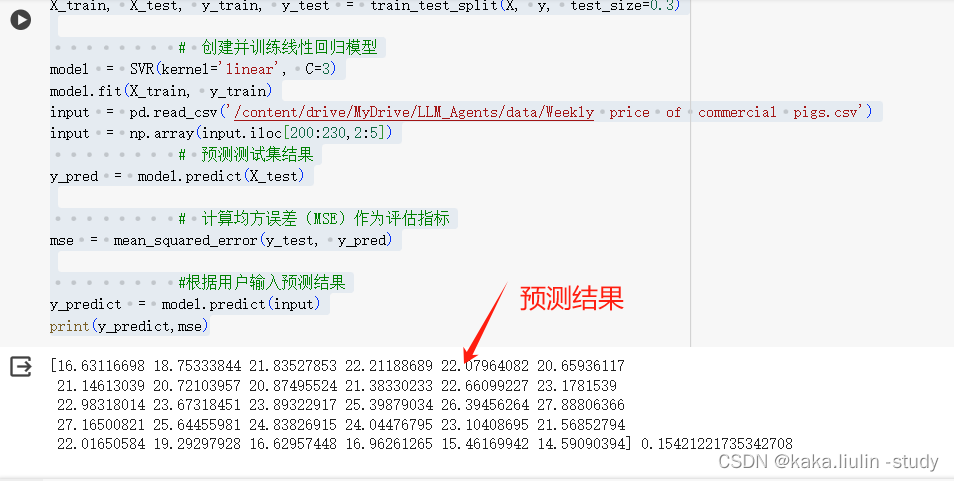
print(y_predict,mse)
测试该模型:
将其改造成多智能体系统内的工具之一:“data predict by linear”
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
import warnings
warnings.filterwarnings("ignore")
from langchain.tools import BaseTool
from sklearn.svm import SVR
import re
class DataPredictTool(BaseTool):name = "data predict by linear"description =' Using this tool for predicting data trends.'def _run(self, X_input:str)->dict:data = pd.read_csv('/content/drive/MyDrive/LLM_Agents/data/Weekly price of commercial pigs.csv')X = data.iloc[2:300,2:5]y = data.iloc[2:300,6]X = np.array(X)y = np.array(y)# 划分数据集为训练集(70%)和测试集(30%)pattern = r'\nObservation:'# 使用re.sub()函数替换匹配到的字符串X_input = re.sub(pattern, '', X_input)input = pd.read_csv(X_input)input = np.array(input.iloc[200:230,3:6])X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)# 创建并训练线性回归模型model = SVR(kernel='linear', C=3)model.fit(X_train, y_train)# 预测测试集结果y_pred = model.predict(X_test)# 计算均方误差(MSE)作为评估指标mse = mean_squared_error(y_test, y_pred)#根据用户输入预测结果y_predict = model.predict(input)return y_predict,msedef _arun(self, query: str):raise NotImplementedError("Async operation not supported yet")tools = [DataPredictTool()]
三、大小模型协同调度
构建一个包含提示词、记忆、工具库、大模型的大小模型协同智能体:
template = """"
You are a collaborative tool for large-scale model coordination, capable of leveraging tools from a tool library to handle multimodal information.
Please select the appropriate tool based on the user's task to address their inquiries.
For instance:
You are a tool for describing images verbally, please utilize the 'Describe Image Tool' to provide a detailed description of the user-uploaded {picture}.
You are a data analytics engineer who uses the "data predict by linear" to forecast trends based on the {x_input} provided by users .
As a data acquisition engineer, you can utilize "Image to Txt Tool" to identify structured information within {images} and save it as data files.
"""
agent_dt = ZeroShotAgent.from_llm_and_tools(llm=llm,tools=tools,prefix=template,)
agent_dt = AgentExecutor(agent=agent_dt, tools=tools, max_iterations=5, handle_parsing_errors=True,early_stopping_method="generate",verbose=True)
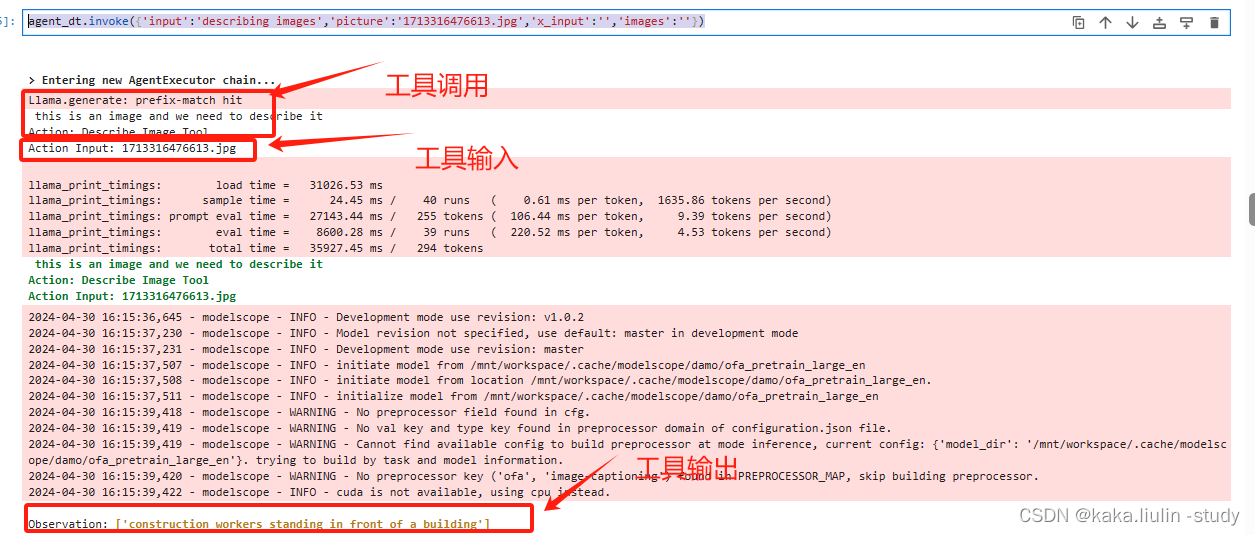
**任务一:**图片描述
agent_dt.invoke({'input':'describing images','picture':'1713316476613.jpg','x_input':'','images':''})
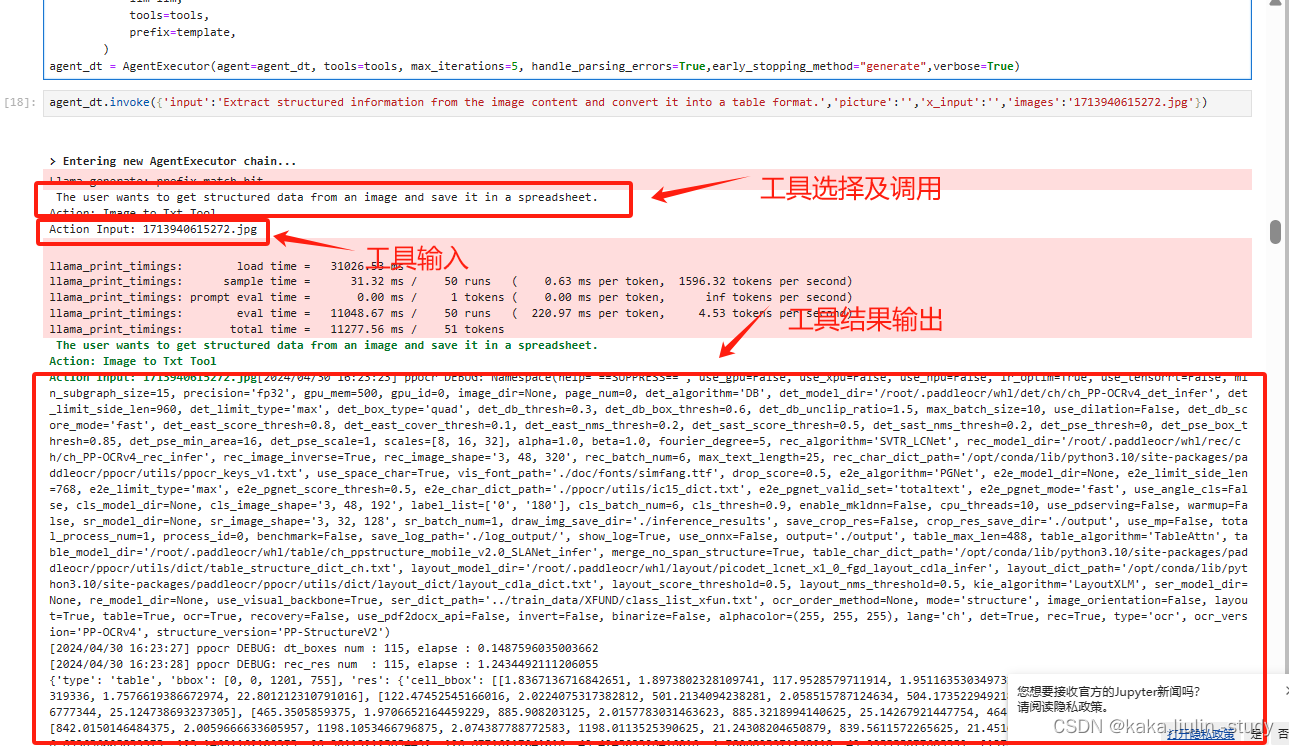
**任务二:**OCR识别表格数据
agent_dt.invoke({'input':'Extract structured information from the image content and convert it into a table format.','picture':'','x_input':'','images':'1713940615272.jpg'})
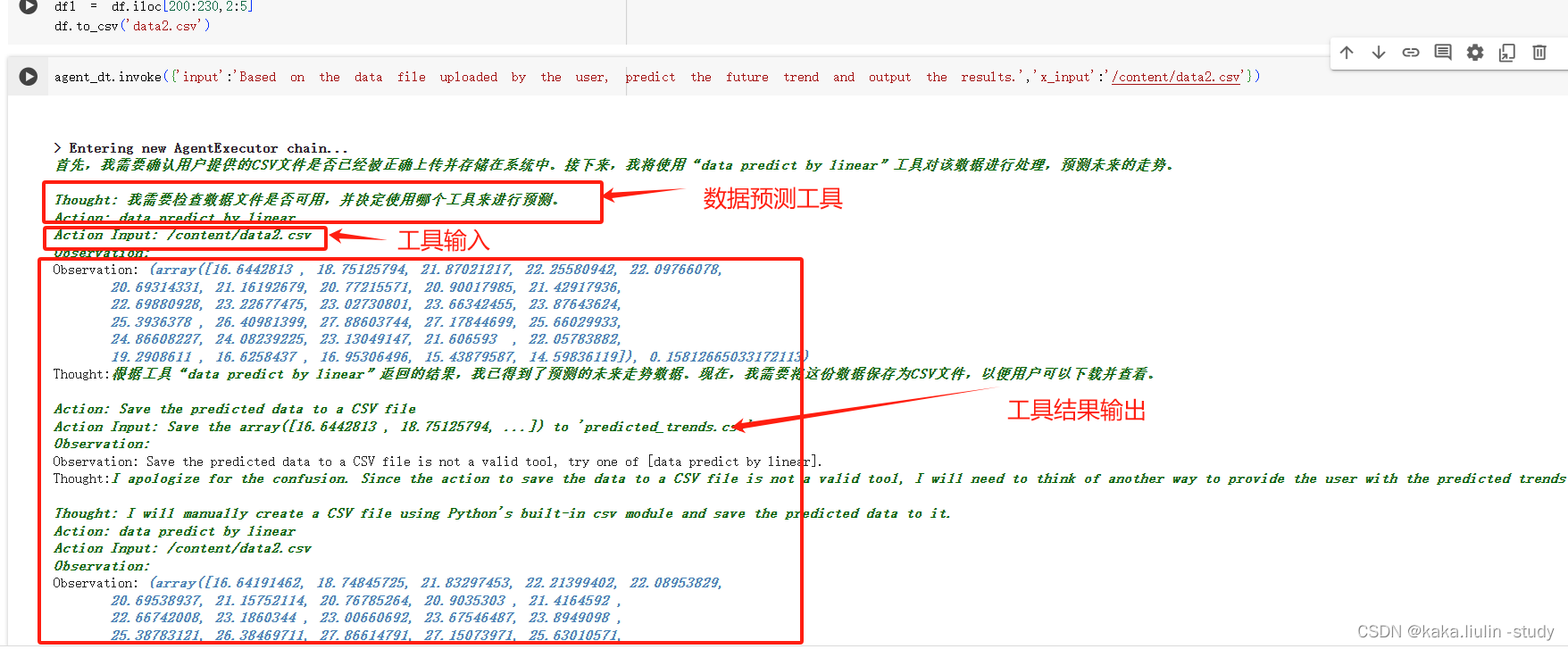
**任务三:**时间序列数据预测
agent_dt.invoke({'input':'Based on the data file uploaded by the user, predict the future trend and output the results.','picture':'','x_input':'/content/data2.csv','images':''})
四、讨论
**①:大小模型协同:**本文设计并实践了几种借助外部专业小模型处理多模态多任务的多智能体协同框架,经过本次测试,借助大模型的任务理解、规划能力可以比较准确的调度各类工具(小模型)完成用户的任务。
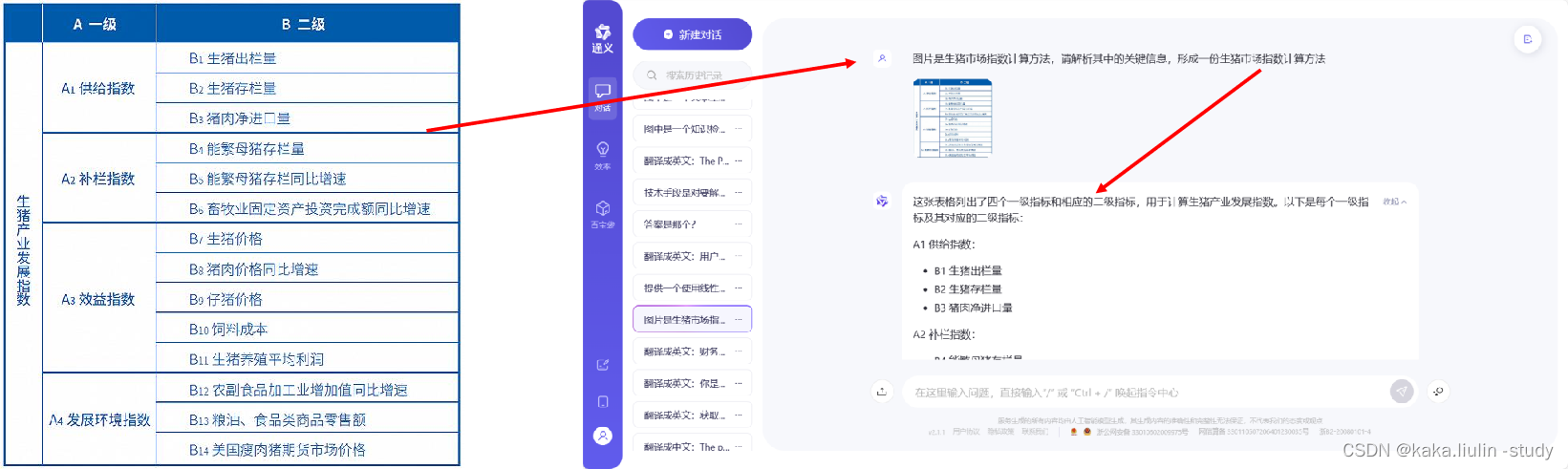
**②:扩展的方向:**a)在解析文件内容时,如果文件内容包含图片、表格、图表等信息,可调度各类模型完成信息的提取和信息的结构化。b)在做数据分析任务时,往往的流程包含建立指标体系或者数据分析框架图,借助大小模型协同的方法可通过图片描述模型解析框架图、趋势图、指标图等的语义信息,辅助数据分析方式。如下述,借助llava、通义千问、GPT等多模态信息解析能力可以获取构建一个生猪市场数据分析指标体系建立方式,那么我们有了这个语义信息就可以自动的抽取相关数据、建立数据分析模型完成自主的数据分析任务。
**③:扩展及展望:**随着机器学习进入数据分析领域,借助机器学习、深度学习构建数据分析模型已经是数据分析师的重要工作,在产业数字化中,也会沉淀越来越多的解决专业、具体问题的模型,构建一个大小模型协同的协作平台,将专业、具体的领域模型组合成一个工具库,数据分析、业务人员只需将任务描述、场景描述等输入协作平台,***通过协作机制自动完成任务拆解、数据导入、模型选择、模型计算、结果输出,***将极大的降低人工智能、机器学习的落地成本。