1、数组
特别需要注意的是:在 Go 语言中,数组长度也是数组类型的一部分!所以尽管元素类型相同但是长度不同的两个数组,它们的类型并不相同。
1.1、数组的初始化
1.1.1、通过初始化列表{}来设置值
var arr [3]int // int类型的数组默认会初始化全为 0var addr = [3]string{"beijing","wuhan","shanghai"} // 指定初始化值1.1.2、自动推断数组长度
var addr = [...]string{"beijing","wuhan","shanghai"}1.1.3、通过索引初始化部分元素
// 数组类型 [6]stringvar addr = [...]string{0:"beijing",3:"wuhan",5:"shanghai"}// 数组类型 [3]intnums := [...]int{0:1,2:3}1.2、数组的遍历
1.2.1、一维数组的遍历
var arr = [3]int{1,2,3}arr[1] = 3 // 通过索引修改数组的值for i:=0;i<len(arr);i++{fmt.Printf("%d ",arr[i]) // 1 3 3 }1.2.2、二维数组的遍历
二维数组的定义
注意:在二维数组中,列数必须指定,无法自动推导! 行数可以用 [...] 来自动推导。
// 二维数组的初始化var table = [2][3]int{{1,2,3},{4,5,6}}fmt.Println(table) // [[1 2 3] [4 5 6]]
普通遍历
这种遍历方式就是利用索引来遍历:
for i := 0; i < len(table); i++ {for j := 0; j < len(table[i]); j++ {fmt.Print(table[i][j]," ")}fmt.Println()}// 1 2 3 // 4 5 6使用 range 遍历
range 关键字是专门用来遍历数组或切片的,它会返回两个值:索引和元素值。
for _,i := range table{for _,j := range i{fmt.Print(j," ")}fmt.Println()}对于索引我们不需要,所以直接赋值给 _ ,而外层的元素值 i 代表的是二维数组 table 的每一行,相当于是一个一维数组。
所以,对于上面的一维数组遍历,我们同样可以采用这种方式:
for _,i := range arr{fmt.Print(i," ")}1.3、数组是值类型的
数组是值类型的!这是非常重要的一点。这意味着如果把数组作为参数传递给函数进行处理,那么实际的数组并不会发生改变。而且数组的容量是固定的,在定义时必须就确定!
但是 Go 语言提供了一种可以引用类型的特殊数组——切片(slice)。对于切片 ,它不仅是引用类型(作为函数参数时,如果形参被修改,那么实参也将被修改),同时也是可动态扩容的,也就是说我们不需要向数组那样在声明时就初始化大小。
func main(){s1 := [2]int{0,0} // [0,0]fmt.Println(s1) // [0,0]addOne(s1)fmt.Println(s1) // [0,0]
}
func addOne(s [2]int){for i:=0;i<len(s);i++{s[i] += 1}
}可以看到,正因为数组是值类型的,所以当把数组传递给函数的时候,函数中操作的形参相当于是拷贝的这么一个数组,所以操作完毕之后实参并不受影响。(这里的形参在 Java 中就像存在 addOne 方法自己的栈区,而实参存在 mian 方法的栈区,所以操作的就不是同一个内存地址)
1.3.1、数组的比较
也正因为数组是值类型的,所以它支持比较
var arr1 = [3]int{1,2,3}var arr2 = [3]int{1,2,3}fmt.Println(arr1 == arr2) // true可以看到,两个相同类型元素相同的数组是相同的。
2、切片
正因为数组的长度固定,并且数组长度属于数组类型的一部分,所以使用数组非常局限。比如我们定义一个遍历数组的方法,那么我们必须指定数组的类型!
比如下面这个方法只能遍历存放三个元素的数组:
func printArr(arr [3]int){for _,i := range arr{fmt.Print(i," ")}
}2.1、切片的定义
切片定义时不需要指定容量,所以也就没有什么初始值:
var arr [] string需要注意的一点是:因为切片是引用类型而不是值类型的,所以它不能直接比较(和其它切片用 == 进行比较,只能和 nil 进行比较)
2.1.1、切片的长度和容量
切片拥有自己的长度和容量,我们可以通过使用内建的 len() 函数求长度,使用内建的 cap() 函数求切片的容量。
- 长度(Length):长度表示切片中当前可以访问的元素个数,即从第一个元素到最后一个元素的数目。
- 容量(Capacity):容量是指切片的底层数组的大小,即从切片的第一个元素到底层数组的最后一个元素之间的元素总数。容量代表了在不重新分配内存的情况下,切片可以增长到的最大大小。
2.1.2、简单切片表达式
通过数组来给切片初始化:
s := a[low : high]注意:切片表达式中的low和high表示一个索引范围()左包含,右不包含)
var a = [5]int{1,2,3,4,5}s := a[1:3]fmt.Println(a) // [1,2,3,4,5]fmt.Println(s) // [2,3]fmt.Printf("cap(s)=%v,len(s)=%v",cap(s),len(s)) // cap(s)=4,len(s)=2此外
- s := a[1:] :代表从索引 [0,len(s))
- s := a[:2]:代表从索引 [0,2)
- s := a[:]:代表整个数组
注意:对于数组或字符串,如果 0 <= low <= high <= len(a),则索引合法,否则就会索引越界(out of range)。
2.1.3、完整切片表达式
完整的切片表达式是这样的:
s := a[low : high : max]除了比普通切片表达式多了一个参数 max (这个 max 的作用是将得到的结果切片的容量设置为 max-low),此外,在完整切片表达式中,只有第一个索引值 low 可以省略,它默认为 0.
var a = [5]int{1,2,3,4,5}s := a[:3:5]fmt.Println(a) // [1,2,3,4,5]fmt.Println(s) // [1,2,3]fmt.Printf("cap(s)=%v,len(s)=%v",cap(s),len(s)) // cap(s)=5,len(s)=3注意:完整切片表达式需要满足的条件是 0 <= low <= high <= max <= cap(a),其他条件和简单切片表达式相同。
2.1.4、使用 make 函数构造切片
我们上面都是基于已有的数组来创建的切片,如果需要动态的创建一个切片,我们就需要使用内建的 make()函数,格式如下:
// T: 切片元素类型
make([]T, size, cap)比如:
arr := make([]int,2,10) fmt.Println(arr) // [0,0]fmt.Println(cap(arr)) // 10fmt.Println(len(arr)) // 2上面代码中切片 arr 的内部存储空间已经分配了10个,但实际上只用了2个。 容量并不会影响当前元素的个数,所以len(a)返回2,cap(a)则返回该切片的容量 10。
注意:对于未开辟的空间是不能初始化赋值的,比如上面我们指定了 2 个长度,如果此时对 arr[3] := 1 进行赋值,那么会报错,因为切片必须使用特定的方法来进行元素的添加(append)。
2.1.5、切片的本质
切片的本质就是对底层数组的封装,它包含了三个信息:
- 底层数组的指针
- 切片的长度(len)
- 切片的容量(cap)
a := [8]int{0, 1, 2, 3, 4, 5, 6, 7}
s1 := a[:5]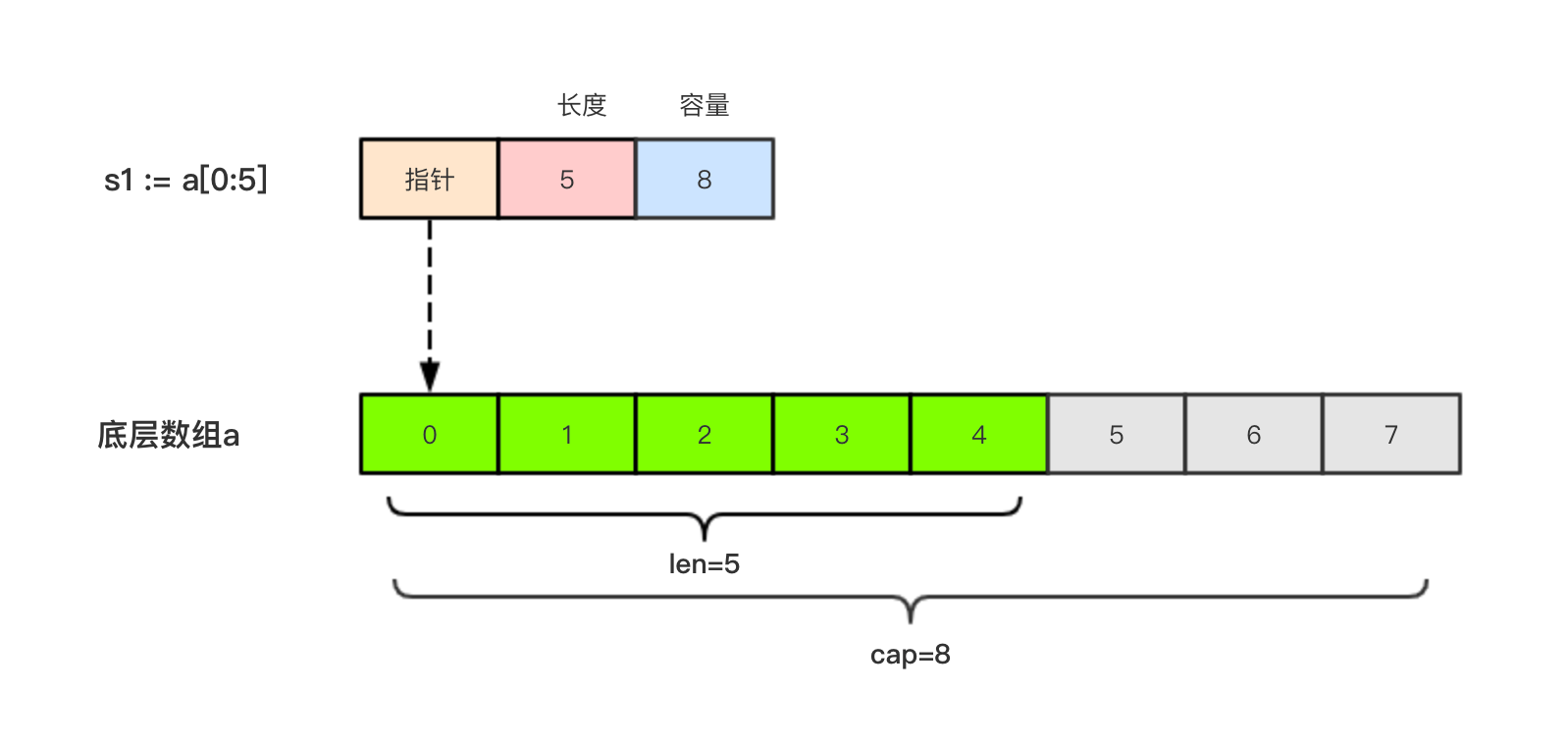
s2 := a[3:6]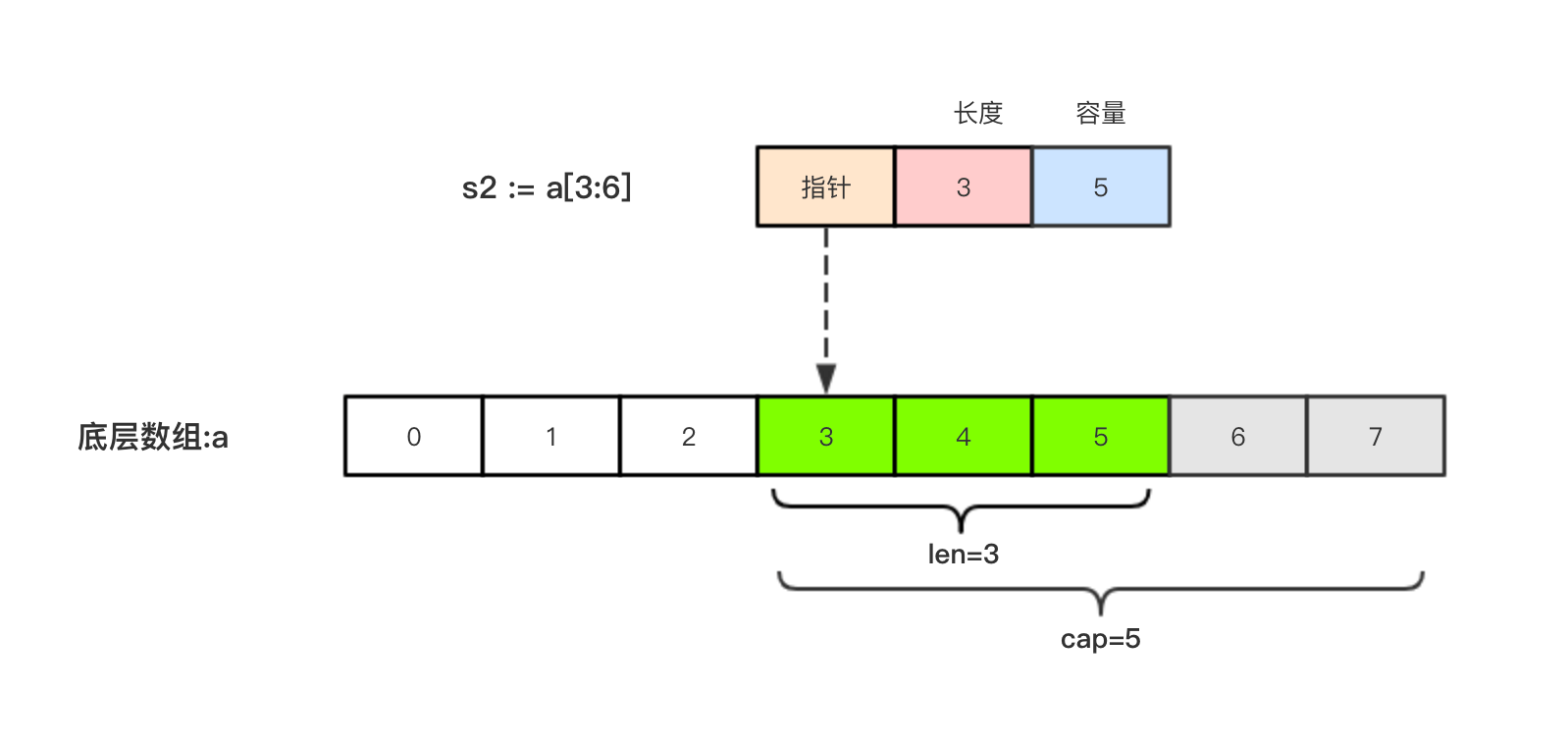
2.1.6、切片的判空
正因为切片是引用类型的,所以切片之间不能用 == 来进行比较,而且切片的判空不能使用 s == nil 来判断,而是通过 len(s) == 0 来判断。
2.1.7、切片引用
func main(){s1 := make([]int,2,10) // [0,0]s2 := s1s2[0] = 1fmt.Println(s1) // [1,0]fmt.Println(s2) // [1,0]
}可以看到,s1 把自己的内存地址赋值给了 s2,所以当 s2 对切片进行操作的时候,操作的是和 s1 共享的内存地址,所以都受影响。
func main(){s1 := make([]int,2,10) // [0,0]fmt.Println(s1) // [1,0]addOne(s1)fmt.Println(s1) // [2,1]
}
func addOne(s []int){for i:=0;i<len(s);i++{s[i] += 1}
}再比如这里,当切片作为参数传递进来时,函数中虽然操作的是形参,但是实参也发生了变化,这就是因为切片是一个引用类型,形参和实参指向同一内存地址。
2.1.8、append 函数为切片添加元素
Go 语言的内部函数 append() 可以为切片动态添加元素。 可以一次添加一个元素,可以添加多个元素,也可以添加另一个切片中的元素(后面加…)。
func main(){var s1 []ints1 = append(s1,1)s1 = append(s1,2,3,4)fmt.Println(s1) // [1 2 3 4]s2 := []int{5,6,7}s1 = append(s1,s2...)fmt.Println(s1) // [1 2 3 4 5 6 7]
}2.1.9、切片扩容
切片的底层是数组,而数组的大小是固定的。这也就是为什么上面给切片添加元素时,搞那么复杂( append 函数的结果返回给原来的切片,而不是 切片.append(元素) )。
func main(){var s1 []intfmt.Printf("size(s1)=%v,cap(s1)=%v,addr=%p \n",len(s1),cap(s1),s1)s1 = append(s1,1,2,3,4)fmt.Printf("size(s1)=%v,cap(s1)=%v,addr=%p \n",len(s1),cap(s1),s1)
}运行结果:
size(s1)=0,cap(s1)=0,addr=0x0
size(s1)=4,cap(s1)=4,addr=0xc000072020可以看到,每扩容一次,切片的地址就会发生变化。
注意:如果是普通值类型的话,我们要取它的地址的话得配合 & 使用,但是如果是引用类型就不需要!因为引用类型本身存储的就是内存地址,不需要再用取地址符取。
Go语言中引用类型和值类型的处理方式与内存分配有关:
- 引用类型(如切片、映射、通道、指针以及函数等)的变量存储的是实际数据的引用(或称为指针),即它们存储的是数据所在的内存地址。当你传递一个引用类型的变量给一个函数时,实际上是传递了该变量所引用的数据的地址,因此函数内部对该地址指向的数据进行修改会影响到原始数据。这就是为什么你不需要使用 & 来获取引用类型变量的地址。
- 值类型(如整型、浮点型、布尔型、字符串以及数组等)的变量直接存储了实际的数据值。当你传递一个值类型的变量给一个函数时,会创建该变量的一个副本并将其传递给函数。这意味着函数内部对副本进行的修改不会影响到原始数据。如果你想让函数能够修改原始数据,你需要传递该变量的地址,这就需要使用 & 来获取值类型变量的地址。
2.1.10、使用 copy 函数覆盖切片
我们创建一个切片,希望两个切片的元素一致。如果直接赋值给另一个切片时,这个两个切片将指向同一个内存地址,一个修改另一个也会被修改。
所以,我们可以通过 copy 函数来进行切片的复制:
func main(){s1 := []int{1,2,3}s2 := []int{4,5,6}copy(s2,s1)fmt.Println(s1) //[1,2,3]fmt.Println(s2) //[1,2,3]s2[0] = -1fmt.Println(s1) //[1,2,3]fmt.Println(s2) //[-1,2,3]
}2.1.11、删除切片中某个元素
Go语言中并没有删除切片元素的专用方法,我们可以使用切片本身的特性来删除元素:
// 删除索引为 2 的元素
func main(){s1 := []int{0,1,2,3,4,5}s1 = append(s1[:2],s1[3:]...)fmt.Println(s1) // [0,1,3,4,5]
}这样,我们对 append 函数有了更深刻的认识,append(p1,p2) 的意思是:在切片 p1 的基础上添加p2(p2可以是切片也可以是单个或多个元素) 中的元素。
3、指针
指针:指针是一种数据类型,用于存储一个内存地址,该地址指向存储在该内存中的对象。
区别于C/C++中的指针,Go语言中的指针不能进行偏移和运算,是安全指针。要搞明白Go语言中的指针需要先知道3个概念:指针地址、指针类型和指针取值。
3.1、指针地址和指针类型
声明指针变量(指针变量的值是地址):
a := 10// 声明一个指针变量b,它的值为a的地址b := &a上面我们声明了一个指针变量 b,它的指针类型为 *int 。
a := 10b := &afmt.Printf("a=%d addr=%p \n",a,&a) // a=10 addr=0xc000014028 fmt.Printf("addr=%p type=%T \n",b,b) // addr=0xc000014028 type=*int fmt.Println(&b) // 0xc00000e030通过上面的结果可以看到,因为 b 存储了 a 的地址,所以 b 的值和 a 的地址是一样的,而 b 也有自己的地址。
3.2、指针取值
a := 10b := &afmt.Printf("type of b: %T \n",b) // type of b: *int c := *bfmt.Printf("type of c: %T \n",c) // type of c: int fmt.Printf("value of c = %v ",c) // value of c = 10 可以看到,变量 c 是数值类型,它把指针变量 b 的值( a 的内存地址)对应的值了取出来。
总结: 取地址操作符 & 和取值操作符 * 是一对互补操作符,& 取出地址,* 根据地址取出地址指向的值。
变量、指针地址、指针变量、取地址、取值的相互关系和特性如下:
- 对变量进行取地址(&)操作,可以获得这个变量的指针变量。
- 指针变量的值是指针地址。
- 对指针变量进行取值(*)操作,可以获得指针变量指向的原变量的值。
3.3、指针传值
之前我们知道值类型的变量传递给函数后无法被操作,因为函数中的形参和实参的地址是不同的。所以,学了指针之后,我们可以通过给函数传递指针地址来保证形参和实参操作的是同一个地址对应的值。
func main(){a := 10fmt.Println(a) // 10addOne(&a)fmt.Println(a) // 11
}
func addOne(num *int){*num += 1
}3.4、new 和 make
var b map[string]intb["李大喜"] = 22fmt.Println(b)对于上面的代码,运行会直接异常:panic: assignment to entry in nil map。这是因为 b 是引用类型(map),我们还没有给它分配内存空间就直接使用了。而值类型是不需要分配内存,因为我们在声明的时候会有默认值。
而要分配内存,就引出来 Go 语言中的new和make,它俩都是 Go 内建的两个函数,主要用来分配内存。
3.4.1、new
new 函数在源码中是这样的:
func new(Type) *Type- Type 代表类型,new 函数的参数是一个类型,而一般的函数参数是值。
- *Type 代表类型指针,new 函数返回一个指向该类型的内存地址的指针。
new函数不太常用,使用new函数得到的是一个类型的指针,并且该指针对应的值为该类型的初始值:
func main(){// 声明一个int类型指针 该指针并没有初始值,因为指针的值是其它变量的内存地址var a *int// 为指针a开辟内存空间,默认指向0的地址值a = new(int)// 取出指针的值fmt.Println(*a) // 0*a = 10fmt.Println(*a) // 10
}3.4.2、make
make 也是用于内存分配的,区别于new,它只用于slice、map以及channel的内存创建,而且它返回的类型就是这三个类型本身,而不是他们的指针类型,因为这三种类型就是引用类型,所以就没有必要返回他们的指针了。make函数的源码:
func make(t Type, size ...IntegerType) Type- t Type:表示传入一个 Type 类型的变量 t
- size... IntegerType:表示传入一个或多个整型的值
我们之前在动态创建切片(相对的是通过数组创建切片)的时候就是使用的 make。make函数是无可替代的,我们在使用slice、map以及channel的时候,都需要使用make进行初始化,然后才可以对它们进行操作。
var score map[string]intscore = make(map[string]int,10)score["小明"] = 98fmt.Println(len(score)) // 1fmt.Println(score) // map[小明:98]这里,我们通过 make 函数为 map 开辟了 10 个内存空间,并使用了一个内存空间。
3.4.3、new 和 make 的区别
- 二者都是用来做内存分配的;
- make只用于slice、map以及channel的初始化,返回的还是这三个引用类型本身;
- 而new用于类型的内存分配,并且内存对应的值为类型初始值,返回的是指向类型的指针;
4、map
4.1、 map 定义
map 的定义:
map[KeyType]ValueType
map类型的变量默认初始值为 nil,需要使用make()函数来分配内存:
make(map[KeyType]ValueType, [cap])其中cap表示map的容量,该参数虽然不是必须的,但是我们应该在初始化map的时候就为其指定一个合适的容量。
比如:
users := make(map[string]int)4.2、map 的基本使用
4.2.1、添加元素
开辟内存空间之后,直接用就完了:
map[key] = value4.2.2、初始化时添加元素
map 也支持初始化的时候指定元素(key 和 value 之间用引号而不是等号):
score := map[string]int{"李大喜": 88,"燕双鹰": 99,}fmt.Println(len(score)) // 1fmt.Println(score) // map[小明:98]但是需要注意的是:初始化后的 map 不能再重新开辟内存了,否则会把初始化的内容全部清空!
但是初始化后的 map 默认是没有固定容量的,所以可以继续进行扩展。
4.2.3、判断 key 是否存在
判断方法:
value, ok := map[key]返回两个值:第一个值是返回的该key对应的值,如果没有则为该值类型的初始值。第二个值为一个 bool 类型的值,表示状态(存在:true,不存在:false)。
users := map[string]int{"李大喜": 88,"燕双鹰": 99,}value,status := users["谢永强"]if status{fmt.Println("存在该用户并且value =",value)}else{fmt.Println("不存在该用户")}如果不希望得到状态值,可以使用 _ 进行忽略,或者:
value = users["谢永强"]因为在Go语言中,range关键字用于遍历map时,会返回两个值,一个是键(key),另一个是值(value)。如果我们只使用了变量接收键,而没有使用任何变量来接收值,则编译器会自动忽略值的部分,只输出键。
4.2.4、map 的遍历
Go 语言使用 for range 来遍历 map:
users := map[string]int{"李大喜": 88,"燕双鹰": 99,}users["谢永强"] = 95for k,v := range users{fmt.Println(k,v)}可以看到,这一点 Go 语言做的要比 Java 简单很多很多!毕竟 Java 不支持返回多个返回值,除非封装成一个数组或者别的对象!
如果希望返回所有 value,可以这样:
delete(map, key) for _,v := range users{fmt.Println(v)}4.2.5、使用 delete 函数删除键值对
使用delete()内建函数从map中删除一组键值对的格式如下:
delete(map, key)注意:之所以叫内建函数,是因为 delete 函数是定义在 buildin.go 文件中的。
5、结构体
Go语言中没有“类”的概念,也不支持“类”的继承等面向对象的概念。Go语言中通过结构体的内嵌再配合接口比面向对象具有更高的扩展性和灵活性。Go 语言正是通过结构体来实现面向对象。
5.1、结构体的定义
type 类名 struct{字段名 字段类型字段名 字段类型//...
}比如:
type person struct {name stringcity stringage int8
}
对于相同类型的字段可以写在一行:
type person struct {name city stringage int8
}
5.2、结构体的实例化
和声明内置类型一样,我们可以使用 var 声明结构体类型:
var 结构体实例 结构体类型比如:
type person struct {name stringcity stringage int8
}func main(){var p personp.name = "谢永强"p.city = "象牙山"p.age = 22fmt.Println(p) // {谢永强 象牙山 22}fmt.Printf("%#v",p) // main.person{name:"谢永强", city:"象牙山", age:22}
}5.3、匿名结构体
在定义一些临时数据结构等场景下还可以使用匿名结构体:
func main(){var p struct{name string;age int;city string}p.name = "谢永强"p.city = "象牙山"p.age = 22fmt.Println(p) // {谢永强 象牙山 22}fmt.Printf("%#v",p) // struct { name string; age int; city string }{name:"谢永强", age:22, city:"象牙山"}
}5.4、结构体的初始化
5.4.1、使用键值对初始化
我们可以使用键值对的形式来实例化结构体:
type person struct{name stringage int8city string
}func main(){p := person{name :"谢永强",age : 22,city : "象牙山",}fmt.Printf("%#v",p) // main.person{name:"谢永强", age:22, city:"象牙山"}
}注意:没有初始化的结构体,其成员变量都是对应其类型的初始值。
5.4.2、使用列表进行初始化
使用列表进行初始化有以下这些要求:
- 必须初始化结构体的所有字段。
- 初始值的填充顺序必须与字段在结构体中的声明顺序一致。
type person struct{name stringage int8city string
}func main(){p := person{"谢永强",22,"象牙山",}fmt.Printf("%#v",p) // main.person{name:"谢永强", age:22, city:"象牙山"}
}5.5、结构体内存布局
结构体占用一块连续的内存。
type test struct {a int8b int8c int8d int8
}func main(){n := test{1, 2, 3, 4,}fmt.Printf("n.a %p\n", &n.a)fmt.Printf("n.b %p\n", &n.b)fmt.Printf("n.c %p\n", &n.c)fmt.Printf("n.d %p\n", &n.d)
}运行结果:
n.a 0xc000014028
n.b 0xc000014029
n.c 0xc00001402a
n.d 0xc00001402b注意:空结构体是不占用空间的。
5.6、构造函数
Go语言的结构体没有构造函数,但是我们可以自己实现:
type person struct{name stringage int8city string
}func newPerson(name,city string,age int8) *person{return &person{name : name,city : city,age : age,}
}func main(){p := newPerson("张三","北京",22)fmt.Printf("%#v\n", p) // &main.person{name:"张三", age:22, city:"北京"}
}5.7、方法与接受者
Go语言中的方法是一种作用于特定类型变量的函数。这种特定类型变量叫做接收者。接收者的概念就类似于 Java 中的 this 。
方法与函数的区别是,函数不属于任何类型,方法属于特定的类型。
5.7.1、创建方法
func (接收者变量 接收者类型) 方法名(参数列表) (返回参数) {函数体
}- 接收者变量:在命名时,官方建议使用接受者类型名称首字母小写
- 接收者类型:可以是指针类型和非指针类型
type person struct{name stringage int8city string
}// 构造器
func newPerson(name,city string,age int8) *person{return &person{name : name,city : city,age : age,}
}// person 的方法
func (p person) eat(){fmt.Println("人会吃饭")
}func main(){p := newPerson("张三","北京",22)p.eat() // 人会吃饭fmt.Printf("%#v\n", p) // &main.person{name:"张三", age:22, city:"北京"}
}5.7.2、指针类型接收者
指针类型的接收者由一个结构体的指针组成,由于指针的特性,调用方法时修改接收者指针的任意成员变量,在方法结束后,修改都是有效的。
type person struct{name stringage int8city string
}// 构造器
func newPerson(name,city string,age int8) *person{return &person{name : name,city : city,age : age,}
}// person 的方法
func (p person) eat(){fmt.Println("人会吃饭")
}// 指针类型的接收者
func (p *person) setName(name string){p.name = name
}func main(){p := newPerson("张三","北京",22)p.eat() // 人会吃饭p.setName("李四")fmt.Printf("%#v\n", p) // &main.person{name:"李四", age:22, city:"北京"}
}注意:结构体是值类型的,并不是引用类型!所以当方法的接收者为指针类型时,才能真正操作结构体实例,否则就相当于拷贝了一份,在方法里自娱自乐。
5.7.3、指针类型接收者
这就是自娱自乐的场景,如果希望使用方法修改结构体实例的属性,那么一定不能使用这种方法。
type person struct{name stringage int8city string
}// 构造器
func newPerson(name,city string,age int8) *person{return &person{name : name,city : city,age : age,}
}// person 的方法
func (p person) eat(){fmt.Println("人会吃饭")
}// 非指针类型的接收者
func (p person) setName(name string){p.name = name
}func main(){p := newPerson("张三","北京",22)p.eat() // 人会吃饭p.setName("李四")fmt.Printf("%#v\n", p) // &main.person{name:"张三", age:22, city:"北京"}
}5.8、嵌套结构体
一个结构体中可以嵌套包含另一个结构体或结构体指针:
type Person struct{name stringage int8addr Address
}type Address struct{province stringcity string
}func main(){p := Person{name :"张三",age : 22,addr : Address{province: "山西省",city : "晋中",},}fmt.Printf("%#v\n", p) // main.Person{name:"张三", age:22, addr:main.Address{province:"山西省", city:"晋中"}}
}5.9、结构体的继承
type Animal struct{category string
}func (a *Animal) move(){fmt.Printf("%s会移动",a.category)
}type Dog struct{feet int8*Animal
}func main(){dog := Dog{feet : 4,Animal: &Animal{category : "狗",},}dog.move() // 狗会移动
}5.10、结构体字段的可见性
结构体中字段大写开头表示可公开访问,小写表示私有。
5.11、结构体 JSON 序列化
我们可以使用 "encoding/json" 包下的 json.Marshal() 函数将结构体转换为 JSON 字符串。该函数接受一个参数,即要转换的结构体对象。如果转换成功,它将返回一个包含JSON数据的字节切片和一个错误值。
注意:结构体的属性必须都为公开的(属性首字母大写),否则无法序列化为 json!
package mainimport ("encoding/json""fmt"
)//Student 学生
type Student struct {ID intGender stringName string
}func main() {student1 := Student{ID : 1,Gender: "男",Name : "刘海柱",}//JSON序列化:结构体-->JSON格式的字符串data, err := json.Marshal(student1)if err != nil {fmt.Println("json marshal failed")return}fmt.Println(string(data)) // {"ID":1,"Gender":"男","Name":"刘海柱"}//JSON反序列化:JSON格式的字符串-->结构体str := `{"ID":1,"Gender":"男","Name":"刘海柱"}`student2 := &Student{}err = json.Unmarshal([]byte(str), student2)if err != nil {fmt.Println("json unmarshal failed!")return}fmt.Printf("%#v\n",student2) // &main.Student{ID:1, Gender:"男", Name:"刘海柱"}
}
5.12、结构体标签 Tag
Tag是结构体的元信息,可以在运行的时候通过反射的机制读取出来。 Tag在结构体字段的后方定义,由一对反引号包裹起来,具体的格式如下:
`key1:"value1" key2:"value2"`结构体tag由一个或多个键值对组成。键与值使用冒号分隔,值用双引号括起来。同一个结构体字段可以设置多个键值对tag,不同的键值对之间使用空格分隔
注意事项: 为结构体编写Tag时,必须严格遵守键值对的规则。结构体标签的解析代码的容错能力很差,一旦格式写错,编译和运行时都不会提示任何错误,通过反射也无法正确取值。例如不要在key和value之间添加空格。
package mainimport ("encoding/json""fmt"
)//Student 学生
type Student struct {ID int `json:"id"`Gender stringName string // 私有属性不能被 json 访问
}func main() {student1 := Student{ID : 1,Gender: "男",Name : "刘海柱",}//JSON序列化:结构体-->JSON格式的字符串data, err := json.Marshal(student1)if err != nil {fmt.Println("json marshal failed")return}fmt.Println(string(data)) // {"id":1,"Gender":"男","Name":"刘海柱"}
}
上面,我们给 ID 属性添加了一个标签 'json:"id"',这样当使用 json 序列化的时候就可以使用我们指定的字段名 "id" 了。