目录
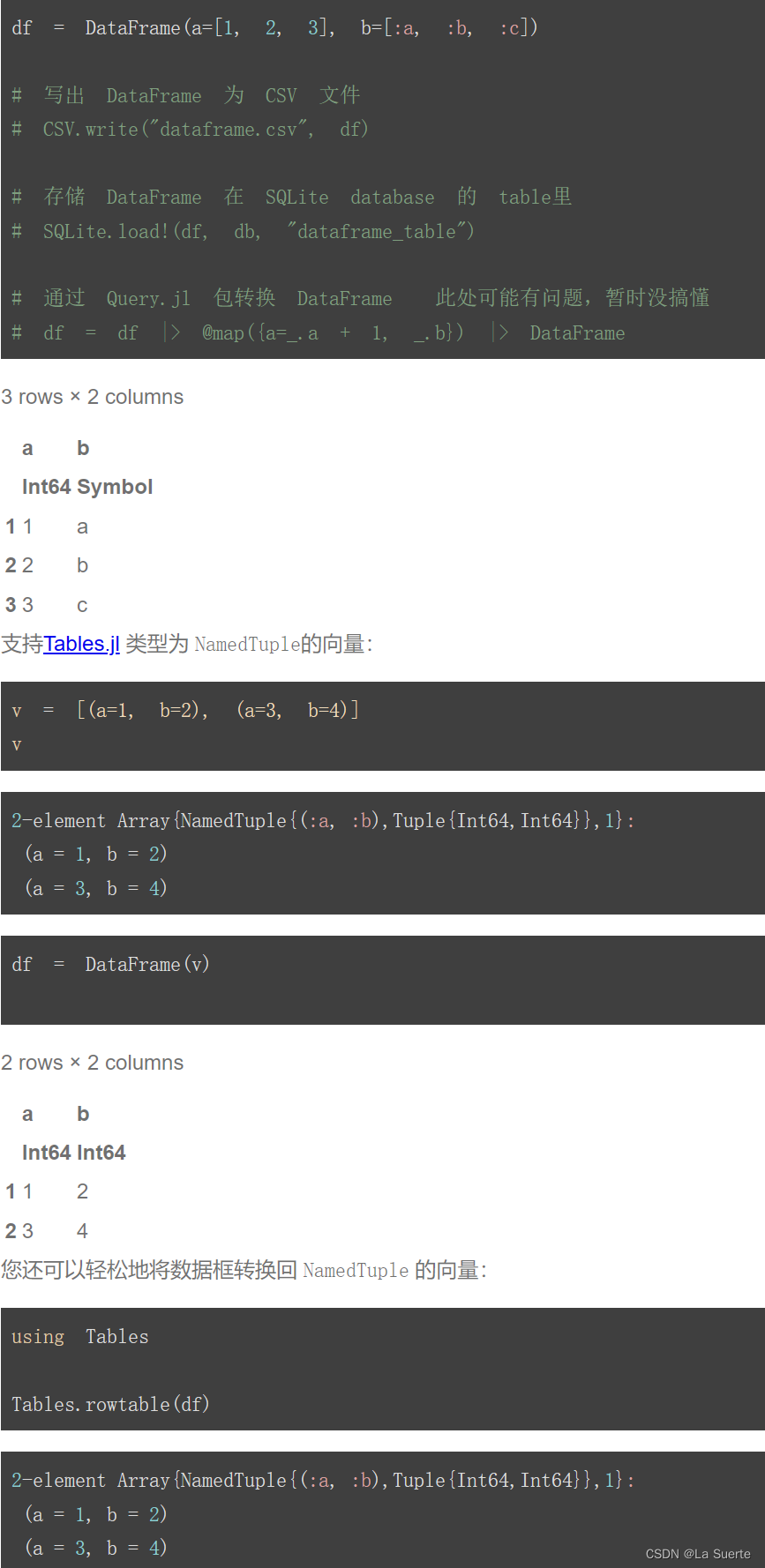
在 Python 编程中,进程、线程和协程是实现并发和并行执行任务的三种主要机制。它们之间的关系如下图所示:
下面是它们的简要概述,以及在 Python 中与它们相关的内容。
进程(Process)
操作系统对正在运行程序的抽象,这个就是进程(process)。
比如运行一个 web 浏览器,一个 text 文本,都是运行的一个一个进程。
有的人说:进程是程序运行资源的集合。进程是系统资源分配的最小单位等等。
从静态的角度来说,进程确实是运行程序的各种资源集合。
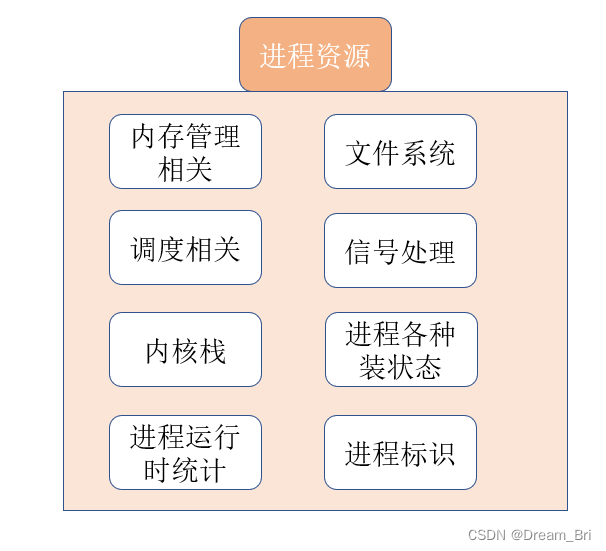
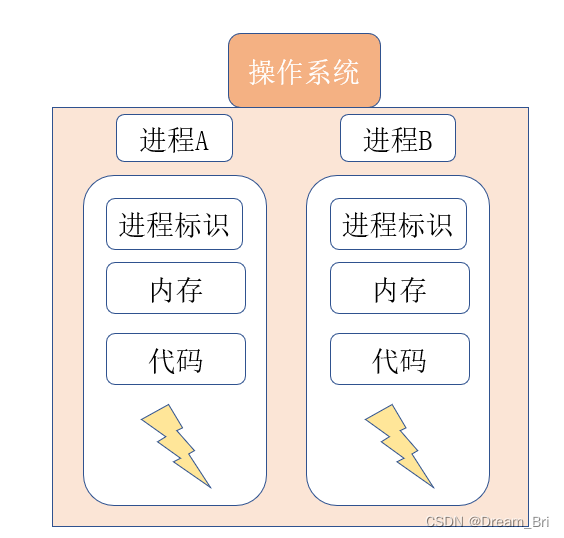
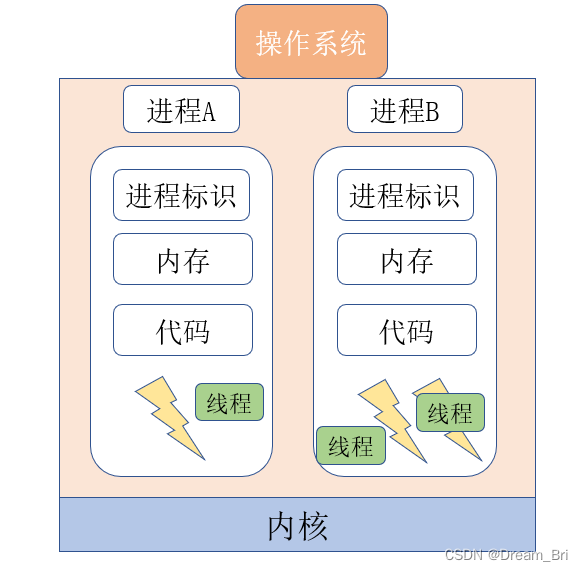
进程是操作系统分配资源并执行程序的基本单位。每个进程拥有自己的内存空间、数据栈以及其他跟踪执行的辅助数据。进程之间的内存空间是隔离的,因此它们之间的通信需要使用进程间通信机制(如管道、信号、共享内存、套接字等)。
操作系统有多个程序运行,那么就有多个进程,如下所示简图
在 Python 中,你可以使用 multiprocessing 模块来创建进程、管理进程间的通信和同步。
multiprocessing.Process:创建一个进程。multiprocessing.Queue、multiprocessing.Pipe:进程间通信。multiprocessing.Pool:用于并行执行任务的进程池。multiprocessing.Value、multiprocessing.Array:进程间共享数据。- 还有很多其他同步原语,如
Lock、Event、Semaphore等。
多进程代码实例
下面我们展示下使用进程的代码和优势,下面代码是通过使用进程和不使用进程进行四个网页的读取下载,并在最后通过各自的运行时间来进行比较:
import requests
from multiprocessing import Pool
import timeurls = ['https://example.com', 'https://httpbin.org', 'https://github.com', 'https://google.com']def download_page(url):print(f"Downloading {url}...")response = requests.get(url)print(f"Downloaded {url} with status code {response.status_code}")# 串行下载网页并测量时间
def serial_download(urls):start_time = time.time()for url in urls:download_page(url)end_time = time.time()return end_time - start_time# 并行下载网页并测量时间
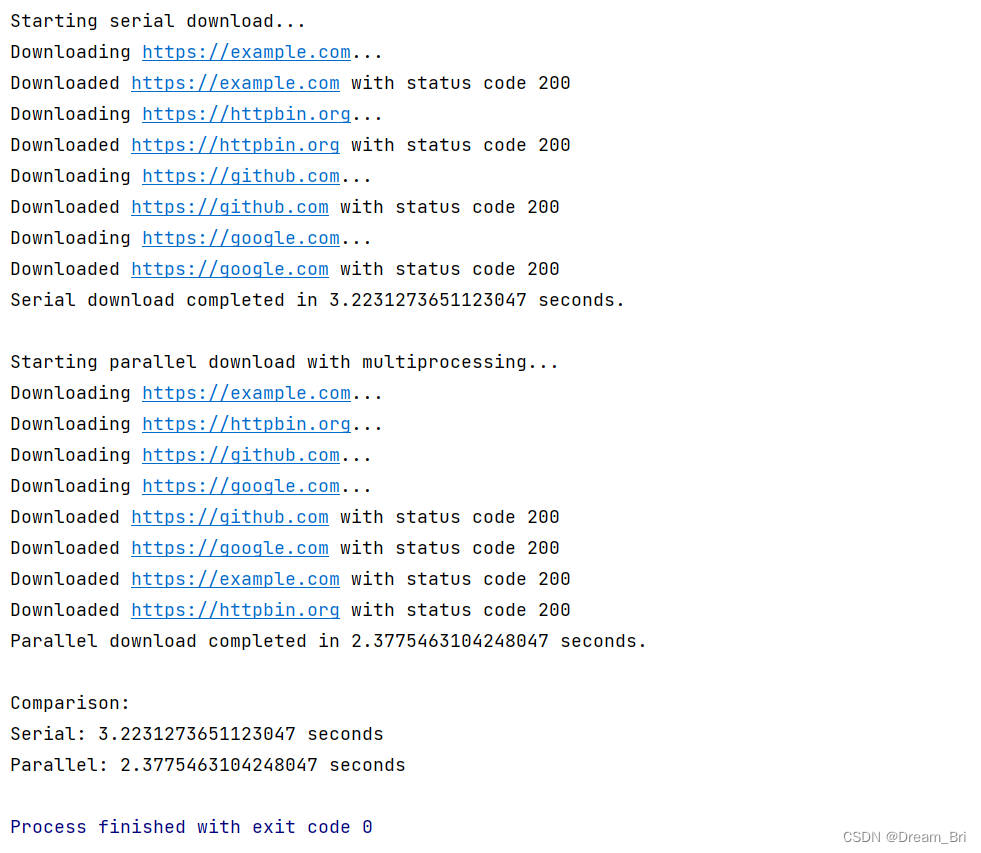
def parallel_download(urls):start_time = time.time()with Pool(4) as pool:pool.map(download_page, urls)end_time = time.time()return end_time - start_timeif __name__ == '__main__':print("Starting serial download...")serial_time = serial_download(urls)print(f"Serial download completed in {serial_time} seconds.")print("\nStarting parallel download with multiprocessing...")parallel_time = parallel_download(urls)print(f"Parallel download completed in {parallel_time} seconds.")print("\nComparison:")print(f"Serial: {serial_time} seconds")print(f"Parallel: {parallel_time} seconds")
运行结果展示如下:
线程(Thread)
线程是进程中的执行序列,一个进程可以包含多个线程,它们共享进程的内存空间和资源。线程之间的通信因此更加容易,可以直接读写同一进程内的数据。然而,因为这种共享,线程安全成为一个需要注意的问题,需要使用锁和其他同步机制来保证数据的一致性。
《操作系统设计与实现》里说:在传统操作系统中,每个进程中只存在一个地址空间和一个控制流(thread)。然后,有些情况下,需要在相同地址空间中有多个控制流并行的运行,就像他们是单独的进程一样(只是他们共享相同的地址空间)。
这些控制流通常被称为线程(thread),有时也称为轻量级进程(lightweight process)。
尽管线程必须在进程中执行,但是线程和进程是可以分别对待处理的两个概念。进程用来集合资源,而线程是 CPU 调度的实体。线程给进程模型增加的是,允许在同一个进程环境中有多个执行流,这些执行流在很大程度上相对独立。也即是说,在进程中,程序执行的最小单位(执行流)是线程,可以把线程看作是进程里的一条执行流。
在 Python 中,可以使用 threading 模块来创建和管理线程。
threading.Thread:创建一个线程。threading.Lock、threading.RLock:线程锁。threading.Event、threading.Condition:线程同步。threading.Semaphore:信号量机制。threading.local:线程本地数据。
多线程存在原因及其缺点
在一个应用程序执行过程中,应用程序里可能会有多种事件执行。
而有些事件执行一段时间后可能会被阻塞。如果把应用程序执行事件分解成多个并行运行的线程,即可以让程序设计变得简单,如果有阻塞的,可以把这部分让出行换其他线程执行。
还有一个原因是:线程比进程更轻量级。所以线程比进程更加容易创建,销毁。
第三个跟第一个有点关系,是关于性能的,若多线程都是 CPU 密集型的,那么不能获取性能上增强。如果有大量计算和大量 I/O 处理,那么多线程就可以获取性能上的优势,因为允许多线程重叠执行。
多线程的缺点:
1、对于多线程来说,进程中的资源是共享的,所以会产生资源竞争。
2、当进程中的一个线程崩溃了,会导致这个进程里的其他线程也崩溃。所以有时多进程程序更好,一个进程崩溃不会导致其他进程也崩溃。
多线程代码实例
下面我们展示下使用线程的代码和优势,下面代码是通过使用线程和使用进程进行四个网页的读取下载,并在最后通过各自的运行时间来进行比较:
import requests
import threading
from multiprocessing import Pool
import time# 网站列表
urls = ['https://example.com','https://httpbin.org','https://github.com','https://google.com'
]# 下载单个页面的函数
def download_page(url):print(f"Downloading {url}...")response = requests.get(url)print(f"Downloaded {url} with status code {response.status_code}")# 使用多线程下载页面并测量时间
def threaded_download(urls):start_time = time.time()threads = [threading.Thread(target=download_page, args=(url,)) for url in urls]for thread in threads:thread.start()for thread in threads:thread.join()end_time = time.time()return end_time - start_time# 使用多进程下载页面并测量时间
def multiprocessing_download(urls):start_time = time.time()with Pool(4) as pool:pool.map(download_page, urls)end_time = time.time()return end_time - start_timeif __name__ == '__main__':print("Starting threaded download...")threaded_time = threaded_download(urls)print(f"Threaded download completed in {threaded_time} seconds.")print("\nStarting multiprocessing download...")multiprocessing_time = multiprocessing_download(urls)print(f"Multiprocessing download completed in {multiprocessing_time} seconds.")print("\nComparison:")print(f"Threaded: {threaded_time} seconds")print(f"Multiprocessing: {multiprocessing_time} seconds")代码运行结果展示:
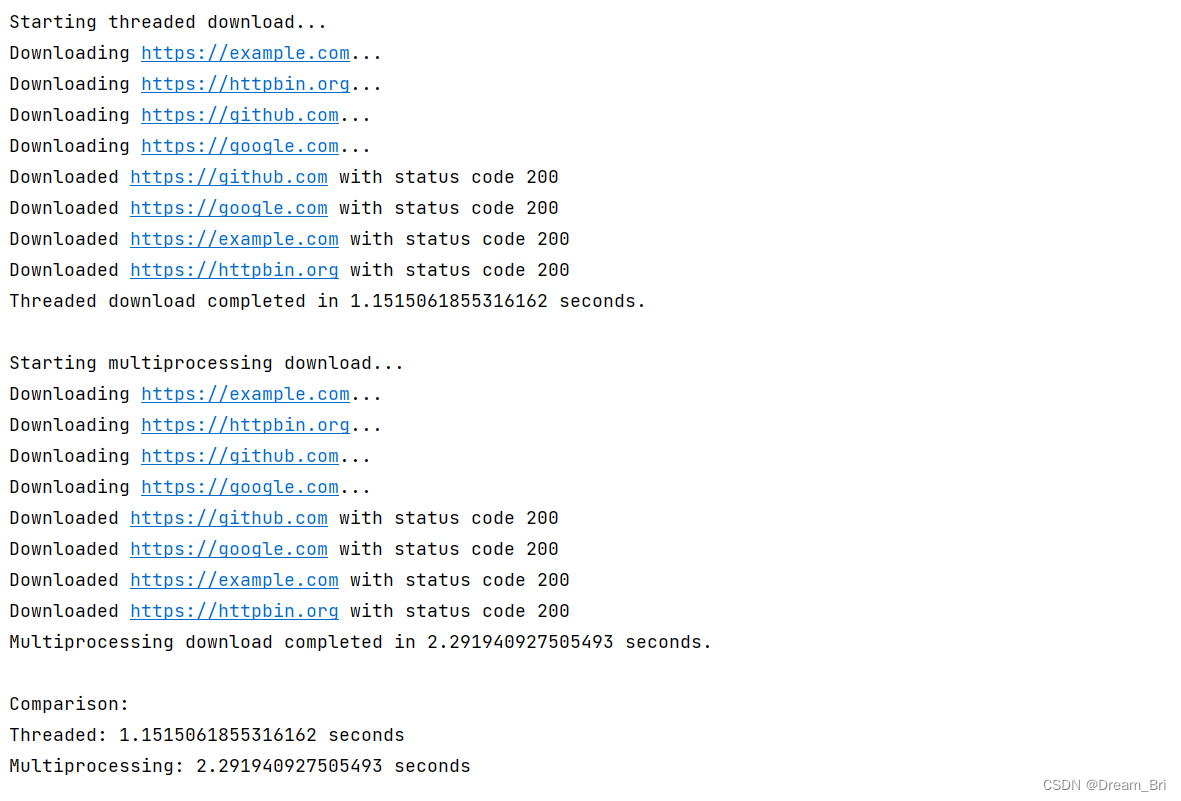
通过这里的结果,我们可以看到线程比进程所用的时间更短,效率更高,
协程(Coroutine)
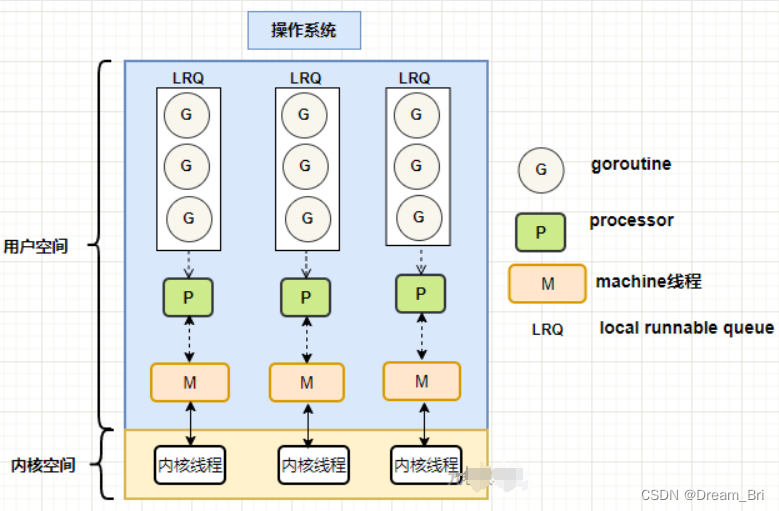
协程是建立在线程之上,一般是语言级别的 ”多线程“ 模型,比线程更加的轻量级。有的叫它微线程。它是完全运行在用户态里。协程是在线程之上在进行抽象,它需要线程来承载运行。一个线程可以有多个协程。
协程是一种轻量级的、协作式的并发机制。它允许在单个线程内执行多个任务,通过协作而不是抢占来进行任务切换。协程为异步编程提供了更直观和易用的形式,可以有效地用于 I/O 密集型和高级别的结构化并发任务。
在 Python中,可以使用 asyncio 标准库来创建和管理协程。
async def:定义一个协程函数。await:在协程中等待另一个协程的结果。asyncio.run():运行最高层级的协程入口点。asyncio.create_task():调度协程的执行。asyncio.Event、asyncio.Lock等:用于协程的同步原语。asyncio.Queue:用于协程间的消息传递。
除了上述内容外,第三方库如 gevent 和 greenlet 也提供了对协程的支持和优化,但它们的工作方式与 asyncio 不同。
Python 中的协程特别适合编写异步I/O操作,如Web服务器、客户端库等,因为它们在等待网络响应或磁盘I/O等操作的过程中可以挂起函数执行,让出控制权,允许其他协程运行。
协程的优点
1、协程栈很小,只有几KB,而线程栈是 1 M,对比起来,创建大量协程需要的内存更少。
2、协程的调度是语言提供的 runtime 来调度,是在用户空间直接调度,不需要在内核空间和用户空间来回切换,浪费效率。
3、能更好的利用 cpu 的多核,提高程序执行性能。
4、避免阻塞,如果协程所在的线程发生了阻塞,那么协程调度器可以把运行在阻塞线程上的协程,调度到其它没有发生阻塞的线程上,继续运行。
协程代码实例
下面我们展示下使用协程的代码和优势,下面代码是通过使用协程同线程、进程进行四个网页的读取下载,并在最后通过各自的运行时间来进行比较:
import time
import threading
import asyncio
import aiohttp
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutorurls = ['https://example.com', 'https://httpbin.org', 'https://github.com', 'https://google.com']# 同步下载页面的函数(用于线程和进程)
def download_page(url):with aiohttp.ClientSession() as session:with session.get(url) as response:return f"Downloaded {url} with status code {response.status}"# 使用多线程下载页面
def threaded_download(urls):with ThreadPoolExecutor(max_workers=4) as executor:executor.map(download_page, urls)# 使用多进程下载页面
def multiprocessing_download(urls):with ProcessPoolExecutor(max_workers=4) as executor:executor.map(download_page, urls)# 异步下载页面
async def async_download_page(session, url):async with session.get(url) as response:return f"Downloaded {url} with status code {response.status}"async def async_download_all_pages():async with aiohttp.ClientSession() as session:tasks = [async_download_page(session, url) for url in urls]return await asyncio.gather(*tasks)# 测量函数执行时间的装饰器
def timeit(method):def timed(*args, **kw):ts = time.time()result = method(*args, **kw)te = time.time()print(f"{method.__name__} executed in {(te - ts):.2f} seconds")return resultreturn timed@timeit
def measure_threaded():threaded_download(urls)@timeit
def measure_multiprocessing():multiprocessing_download(urls)@timeit
async def measure_asyncio():await async_download_all_pages()# 顺序运行三种方法并比较时间
if __name__ == '__main__':measure_threaded()measure_multiprocessing()asyncio.run(measure_asyncio())进程、线程和协程适合的任务性质和环境
多进程更适合的场景
1、CPU密集型任务:
对于计算密集型操作,多进程通常比多线程更好,这是因为每个进程有自己的GIL,能够在多核处理器上并行运行,实现真正的并行计算。
2、内存隔离和安全:
进程之间的内存是隔离的,所以对于需要高安全性或内存隔离的任务,使用多进程会更安全,可以防止数据泄露或污染。
3、大规模并发和稳定性:
对于需要很多并发执行单元,但其中一些可能会因为异常或必须被杀死的任务,进程可能是更好的选择,因为一个进程崩溃不会影响到其他进程,而线程崩溃可能会影响整个应用程序的稳定性。
多线程更适合的场景
1、I/O密集型任务:
如果任务主要是I/O密集型的,例如网络请求或文件读写操作,线程通常能够提供很好的性能,因为当一个线程等待I/O操作时,其他线程可以继续执行。在Python中,虽然全局解释器锁(GIL)限制了同一时刻只有一个线程执行Python字节码,但I/O密集型任务在等待数据时会释放GIL,允许其他线程运行。
2、上下文切换开销小:
线程比进程有更小的内存占用和更快的创建及上下文切换时间。进程需要更多的资源和时间来创建,因为每个进程有自己独立的地址空间,而线程则共享内存地址空间。
3、GIL的影响有限:
由于下载任务主要是在等待网络响应,这意味着大部分时间线程并不持有GIL。因此,即使是在CPython这样的环境中,线程也可能是高效的。
协程更适合的场景
1、更高的I/O效率——非阻塞I/O操作:
协程可以在I/O操作等待数据时挂起,并让出CPU控制权给其他协程。这样可以处理大量的并发网络I/O,非常适合开发高效的网络服务器和客户端。
2、轻量级任务管理:
相对于进程和线程,协程拥有更小的内存占用,因为任务之间共享内存空间并且上下文切换开销很小。这允许程序员创建数以万计的协程而不会大量耗费系统资源。
3、简化的异步编程:
使用协程库(如Python中的asyncio),可以用顺序的方式编写非阻塞代码,降低了异步编程的复杂性。
4、更好的调度控制:
协程的调度是在用户空间完成的,这给了程序员更大的灵活性去控制任务执行的顺序。

![正点原子[第二期]Linux之ARM(MX6U)裸机篇学习笔记-6.5, 汇编 led.s,第一次点亮LED灯](https://img-blog.csdnimg.cn/direct/aa1d91229c4f4b9d83633d79dfaff874.png)