本文将会被汇总至 【记录】Python3|2024年 PDF 转 XML 或 HTML 的第三方库的使用方式、测评过程以及对比结果(汇总),更多其他工具请访问该文章查看。
注意!html" title=pdf>pdfminer.six 和 html" title=pdf>pdfminer3k 不是同一个!!!
PDFMiner.six 使用体验与评估
Github 阅读:https://github.com/shandianchengzi/PDF2HTML_Samples/blob/main/results/html" title=pdf>pdfminer.six.md
CSDN 阅读:【记录】Python3| 将 PDF 转换成 HTML/XML(✅⭐html" title=pdf>pdfminer.six)
参考:PDF 到 HTML/XML 转换 Python 库 - html" title=pdf>pdfminer.six 入门
1 安装指南
要使用 PDFMiner.six,您可以通过 Python 的包管理工具 pip 进行安装。在命令行中执行以下命令:
pip install html" title=pdf>pdfminer.six
2 测试代码
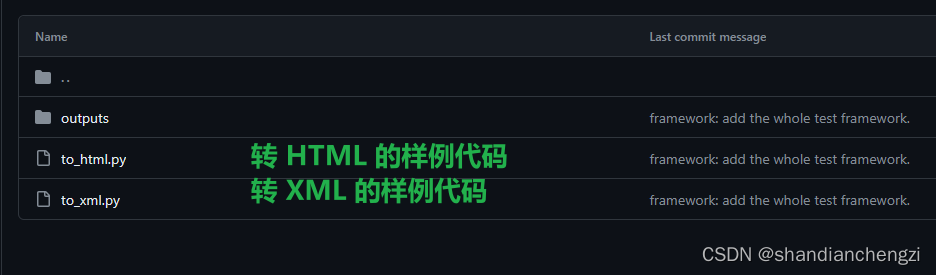
为了帮助您更好地理解 PDFMiner.six 的用法,我提供了一个测试代码示例。您可以在以下 GitHub 仓库中找到相关代码和样本文件:https://github.com/shandianchengzi/PDF2HTML_Samples/tree/main/python_samples/test_html" title=pdf>pdfminer_six。
其目录结构如是:
3 测试结果
html__41">3.1 转 html 的结果
实质就是把每一行转成 span 元素,没有任何节点嵌套等格式。
PDFMiner.six 在将 PDF 转换为 HTML 时,主要将每一行文本转换为 <span> 元素,而不包含任何节点嵌套或格式化信息。这种简单的转换方式使得生成的 HTML 缺乏结构和语义信息。
在测试过程中,我尝试转换了一些包含纯表格和文字+表格的页面,并观察了转换结果。纯表格页面的转换结果并不理想,生成的 HTML 结构混乱,难以阅读。而文字+表格的页面转换结果相对较好,但仍存在一些问题,如表格结构不完整、文字排版混乱等。
纯表格页面的结果(看到结果的我都笑了,这什么玩意):

文字+表格的页面的结果:

xml__59">3.2 转 xml 的结果
实质就是把每一个字转成 text 元素,没有任何节点嵌套等格式。
与 HTML 转换类似,PDFMiner.six 在将 PDF 转换为 XML 时,也是将每个字符转换为 <text> 元素,而不包含任何节点嵌套或格式化信息。这使得生成的 XML 文件非常庞大且难以阅读。
在测试过程中,我尝试查看转换后的 XML 文件,但由于其结构过于复杂且每个节点只是一个字母或符号,因此很难直接阅读和理解。通过在线 XML 元素查看器查看时,可以更加清晰地看到每个节点的结构和内容,但仍然需要一定的耐心和技巧。
众所周知,xml 文件是无法直接查看的,它只是个方便记录数据的、和 html 长得差不多但是小很多的文件。
文字+表格的页面的结果(直接查看结果,实话说看到这里我就知道凉透了):

文字+表格的页面的结果(通过在线 XML 元素查看器查看,简直了。。每个节点只是一个字母或者符号):
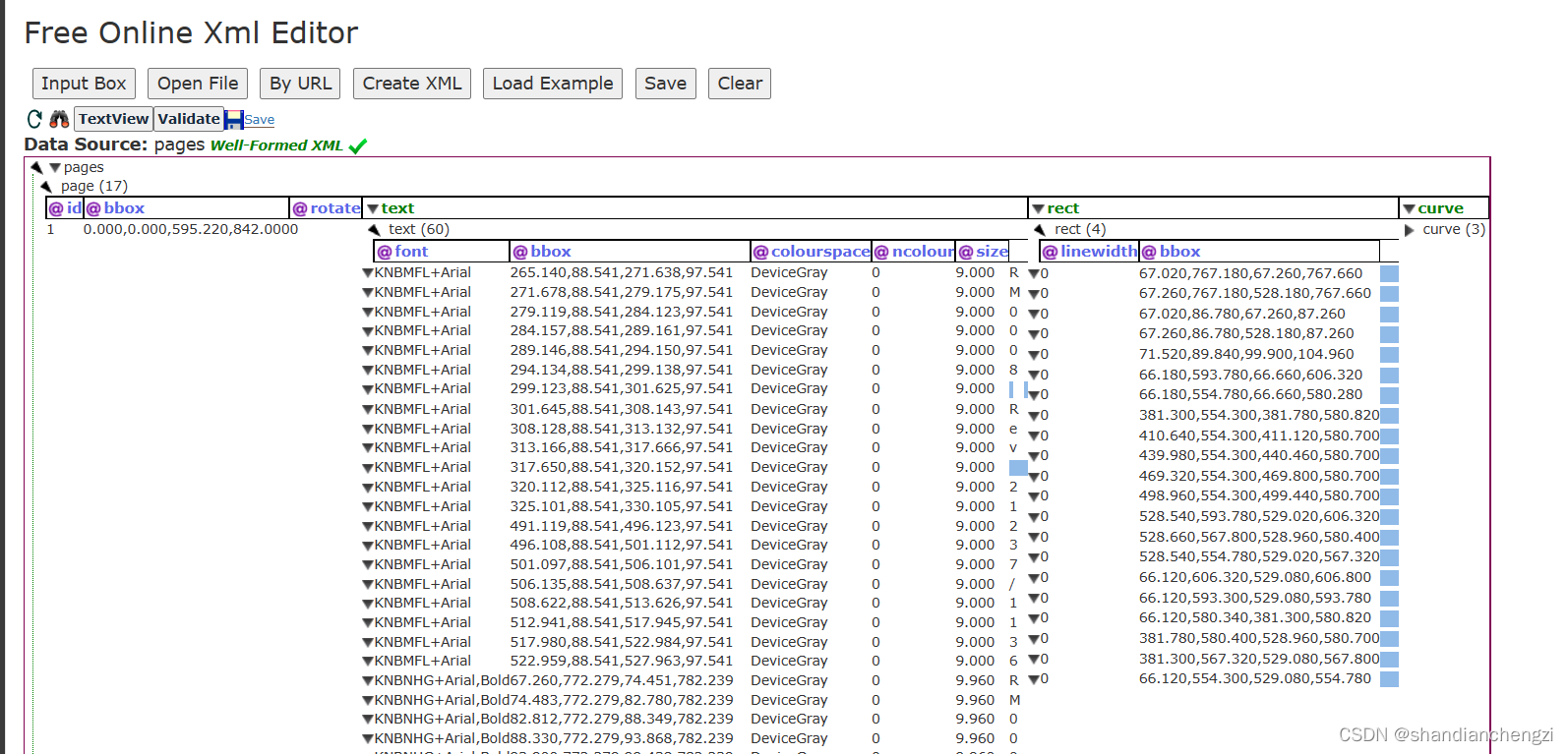
4 总体评价:✅⭐
能跑,没用。
经过测试和使用体验,我认为 PDFMiner.six 的表现并不理想。虽然它能够成功安装并运行,但生成的 HTML 和 XML 结果存在较多问题,如结构混乱、缺乏语义信息等。
经过进一步了解,我发现 PDFMiner.six 是专为 Python 2 设计的工具,而在 Python 3 中的支持并不完善。这可能是导致其表现不佳的主要原因之一。详见 https://pypi.org/project/html" title=pdf>pdfminer/
Warning: Starting from version 20191010, PDFMiner supports Python 3 only. For Python 2 support, check out html" title=pdf>pdfminer.six. https://pypi.org/project/html" title=pdf>pdfminer/
因此,我建议在使用 PDFMiner.six 时,需要注意以下几点:
- 确认您的 Python 版本是否为 2.x,否则不如用别的工具;
- 如果需要转换包含复杂结构和格式的 PDF 文件,可能需要考虑使用其他更成熟的工具或库;
- 在进行转换之前,最好先对 PDF 文件进行一些预处理操作,如拆分页面、识别文字等,以提高转换质量。
本文将会被汇总至 【记录】Python3|2024年 PDF 转 XML 或 HTML 的第三方库的使用方式、测评过程以及对比结果(汇总),更多其他工具请访问该文章查看。
本账号所有文章均为原创,欢迎转载,请注明文章出处:https://blog.csdn.net/qq_46106285/article/details/138095328。百度和各类采集站皆不可信,搜索请谨慎鉴别。技术类文章一般都有时效性,本人习惯不定期对自己的博文进行修正和更新,因此请访问出处以查看本文的最新版本。