概述
Swin Transformer是微软研究院于2021年在ICCV上发表的一篇论文,因其在多个视觉任务中的出色表现而被评为当时的最佳论文。它引入了移动窗口的概念,提出了一种层级式的Vision Transformer,将Shifted Windows(移动窗口)作为其主要贡献。这个概念使得Swin Transformer可以像卷积神经网络一样进行分块,并进行层级式的特征提取,从而在特征表示中引入多尺度的概念。
在OpenAI发布的Sora中也出现了视频patches的概念,这进一步表明了Vision Transformer和Swin Transformer在引入patch概念方面的重要性。目前,许多多模态模型的backbone都采用了这两种模型,因此理解和应用它们的原理对于掌握和应用这些优秀的多模态模型非常必要。
在 Swin Transformer之前,基于Transformer的图像识别模型是视觉变换器(ViT)。它将图像视为由 16x16 个单词组成的句子,是自然语言处理中使用的变换器在图像识别中的首次应用。
本文指出了文本和图像之间的差异,并提出了 Swin Transformer,使 ViT 更适应图像领域。
文字和图像的两个区别如下。
- 与文字符号不同,图像中的视觉元素在比例上差异很大
- 图像中的像素比文件中的文字具有更高的分辨率(更多信息)。
为了消除这些差异
- 计算不同贴片尺寸下的关注度
- 用较小的补丁尺寸计算关注度。
下图说明了 ViT 和 Swin Transformer在这些方面的区别。
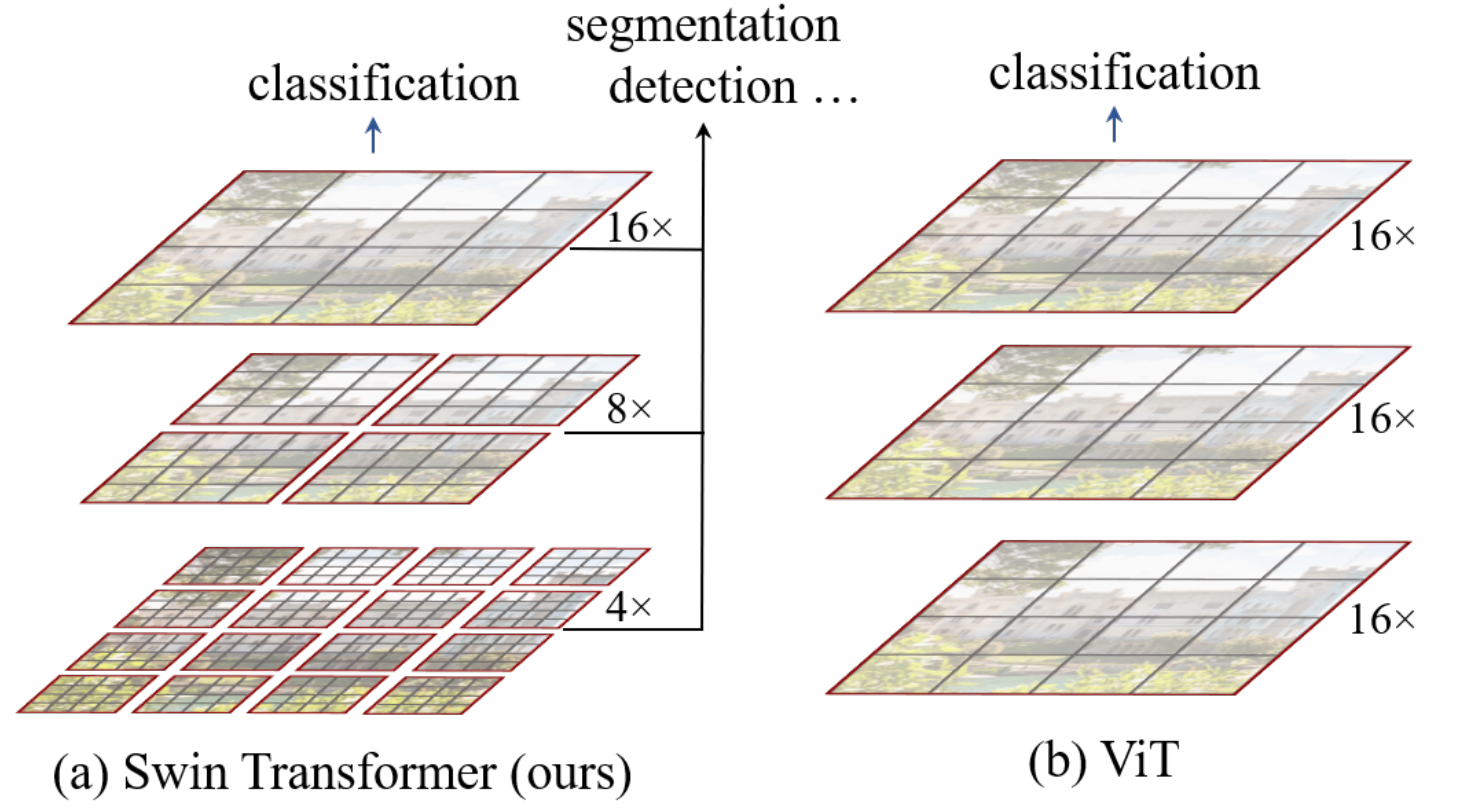
用较小的斑块尺寸计算注意力可以获得精细的特征,但计算成本较高。
这就是在 Swin 变换器中引入基于移位窗口的自注意的原因。多个补丁被合并到一个窗口中,注意力计算只在该窗口中进行,从而减少了计算量。
在下一节中,我们将了解斯温变换器的整体情况,然后了解一些更微小的细节,包括基于移位窗口的自我关注。
Swin Transformer
大画面
下面是 Swin Transformer的全貌。
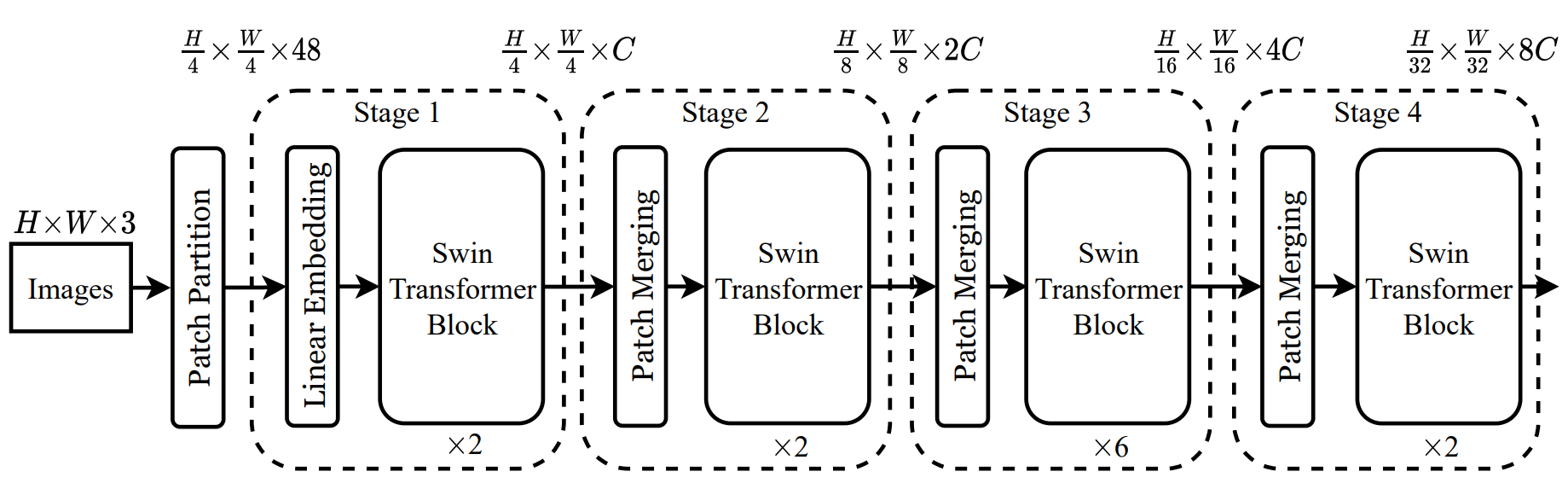
首先,对输入图像进行补丁分割。
补丁分割:将 4x4 像素分割为一个补丁;由于 ViT将 16x16像素作为一个补丁,因此斯温变换器可以提取更精细的特征。
然后进行线性嵌入。
线性嵌入:将补丁(4x4x3ch)转换为 C 维标记,其中 C 取决于模型的大小。
对于从每个补丁中获得的标记,Swin Transformer Block 会计算关注度并进行特征提取。

Swin Transformer区块:用基于移位窗口的自保持(W-MSA 和 SW-MSA)取代常规变压器区块中使用的多头自保持(MSA)。以下章节将提供更多信息。下文将对它们进行更详细的介绍。其他配置与普通变压器几乎完全相同。
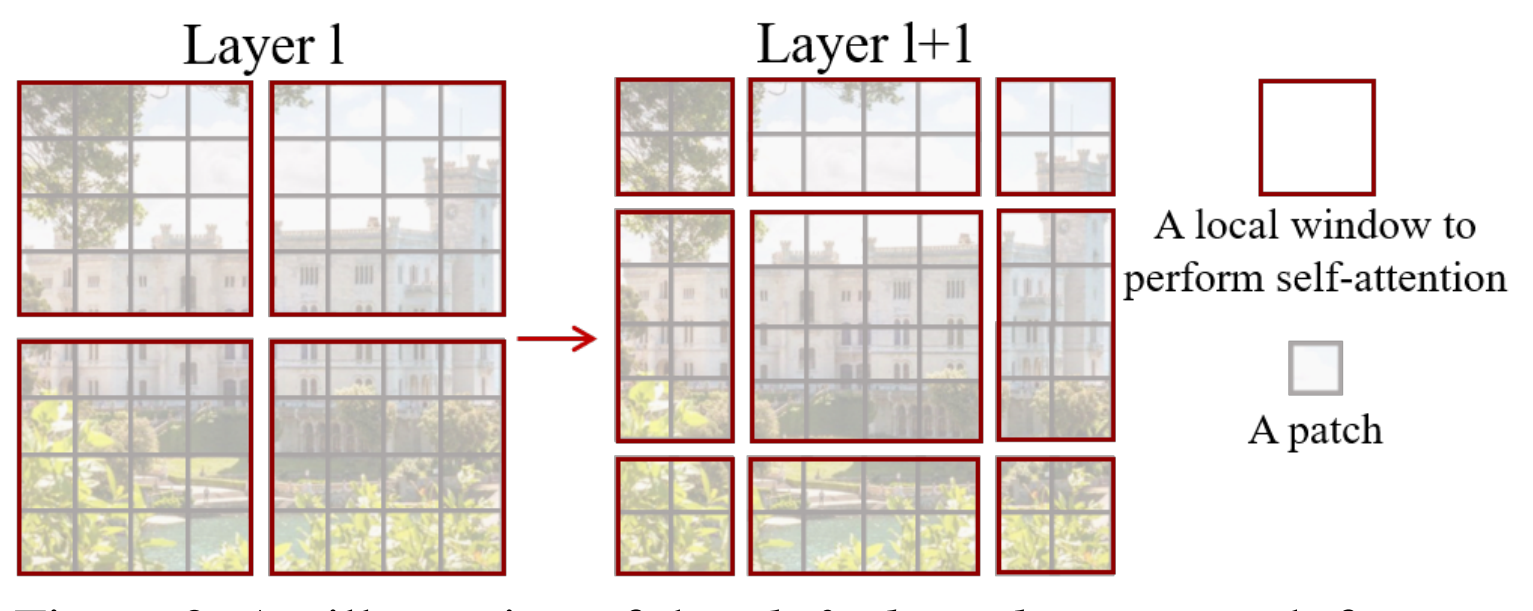
目前看到的线性嵌入和变换块部分被称为第 1 阶段;共有 1 到 4 个阶段,但每个阶段的补丁大小不同,因此可以在不同尺度上进行特征提取。不同大小的补丁是由补丁合并(Patch Merging)产生的,它将邻域中的补丁聚合在一起。
补丁合并:在每个阶段,相邻的(2 × 2)补丁(标记)合并在一起,形成一个标记。具体来说,合并 2 × 2 标记,并通过线性层将所得的 4C 维向量变为 2C 维。例如,在第 2 阶段,(H/4)×(W/4)×C 维度被简化为 (H/8)×(W/8)×2C 维度。
基于移动窗口的自我关注
从计算复杂度的角度解释了普通变压器和斯温变压器模块注意力计算的区别。
法线变换器计算所有标记之间的距离,其中 h 和 w 是图像中垂直和水平斑块的数量,计算量如下
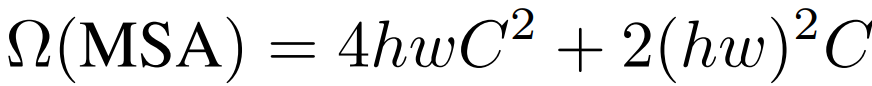
另一方面,Swin 变换器只计算由多个补丁组成的窗口内的关注度:一个窗口包含 M x M 个补丁,基本固定为 M = 7。计算复杂度如下式所示。
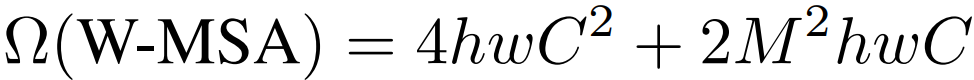
在普通变换器中,计算复杂度的增加与补丁数 (hw) 的平方成正比。然而,由于 M = 7,影响很小,即使是补丁数 (hw) 的增加也保持在幂级数以内。这使得 Swin变换器可以计算小尺寸的贴片。
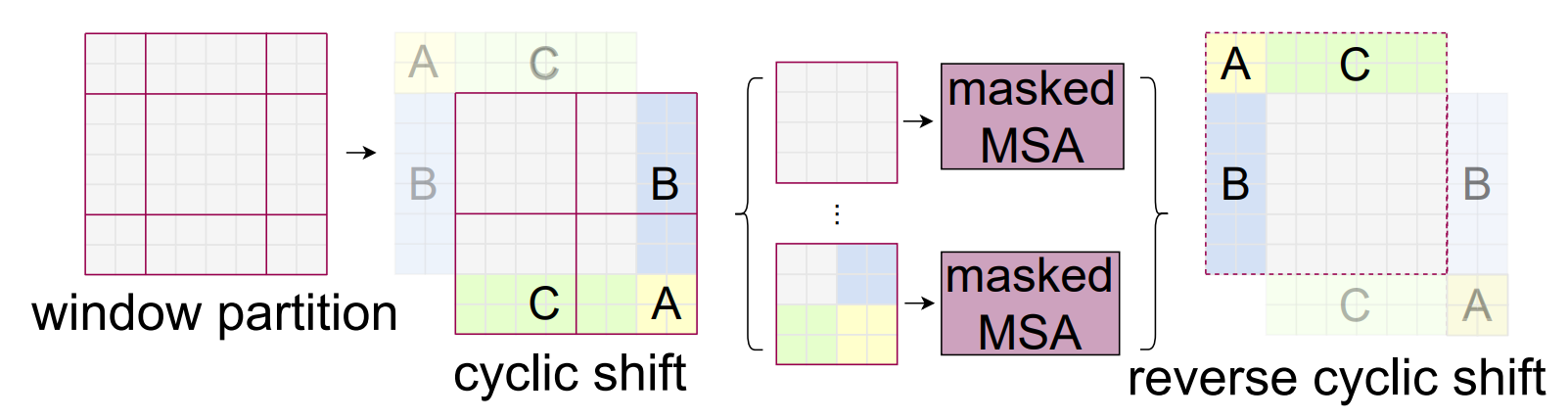
接下来介绍将图像划分为窗口的方法:窗口的排列方式是将图像平均划分为 M x M 个补丁。以这种方式排列的每个窗口都会计算注意力,因此即使是相邻的补丁,如果它们是不同的窗口,也不会计算注意力。为了解决窗口边界问题,在计算第一个注意力(W-MSA:基于窗口的多头自注意力)后,窗口会被移动,注意力会被再次计算(SW-.MSA:基于移动窗口的多头自注意)。
如下图所示,在原窗口分割的基础上移动([M/2], [M/2])个像素。
代码模型:
python">class PatchEmbed(nn.Module):def __init__(self, patch_size=4, in_c=3, embed_dim=96, norm_layer=None):super().__init__()patch_size = (patch_size, patch_size)self.patch_size = patch_sizeself.in_chans = in_cself.embed_dim = embed_dimself.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size)self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()def forward(self, x):_, _, H, W = x.shape# 如果输入图片的 H,W 不是patch_size的整数倍,需要进行paddingpad_input = (H % self.patch_size[0] != 0) or (W % self.patch_size[1] != 0)if pad_input:# to pad the last 3 dimensions, (W_left, W_right, H_top,H_bottom, C_front, C_back)x = F.pad(x, (0, self.patch_size[1] - W % self.patch_size[1],0, self.patch_size[0] - H % self.patch_size[0],0, 0))# 下采样patch_size倍x = self.proj(x)_, _, H, W = x.shape# flatten: [B, C, H, W] -> [B, C, HW]; transpose: [B, C, HW] -> [B, HW, C]x = x.flatten(2).transpose(1, 2)x = self.norm(x)return x, H, W
移位配置的高效批量计算
SW-MSA 的窗口大小不同,窗口数量也会增加。因此,如果直接进行处理,就会出现计算量比 W-MSA 增加的问题。因此,在 SW-MSA 中,使用一种称为循环移动的方法进行伪操作,而不是实际改变窗口的排列。
如下图所示,整个图像向左上方移动,溢出区域插入空白区域 (循环移动 )。通过这种方法,它的计算方法与 W-MSA 窗口中的 Attention 计算方法相同。此外,由于窗口中可能包含不相邻的斑块,因此要对这些部分进行掩膜处理。在最终输出中,将执行循环移位的反向操作(反向循环移位),将补丁恢复到原始位置。
代码实现:
python">class PatchMerging(nn.Module):def __init__(self, dim, norm_layer=nn.LayerNorm):super().__init__()self.dim = dimself.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)self.norm = norm_layer(4 * dim)def forward(self, x, H, W):"""x: B, H*W, C"""B, L, C = x.shapeassert L == H * W, "input feature has wrong size"x = x.view(B, H, W, C)# 如果输入feature map的H,W不是2的整数倍,需要进行paddingpad_input = (H % 2 == 1) or (W % 2 == 1)if pad_input:# to pad the last 3 dimensions, starting from the last dimension and moving forward.# (C_front, C_back, W_left, W_right, H_top, H_bottom)# 注意这里的Tensor通道是[B, H, W, C],所以会和官方文档有些不同x = F.pad(x, (0, 0, 0, W % 2, 0, H % 2))x0 = x[:, 0::2, 0::2, :] # [B, H/2, W/2, C]x1 = x[:, 1::2, 0::2, :] # [B, H/2, W/2, C]x2 = x[:, 0::2, 1::2, :] # [B, H/2, W/2, C]x3 = x[:, 1::2, 1::2, :] # [B, H/2, W/2, C]x = torch.cat([x0, x1, x2, x3], -1) # [B, H/2, W/2, 4*C]x = x.view(B, -1, 4 * C) # [B, H/2*W/2, 4*C]x = self.norm(x)x = self.reduction(x) # [B, H/2*W/2, 2*C]return x
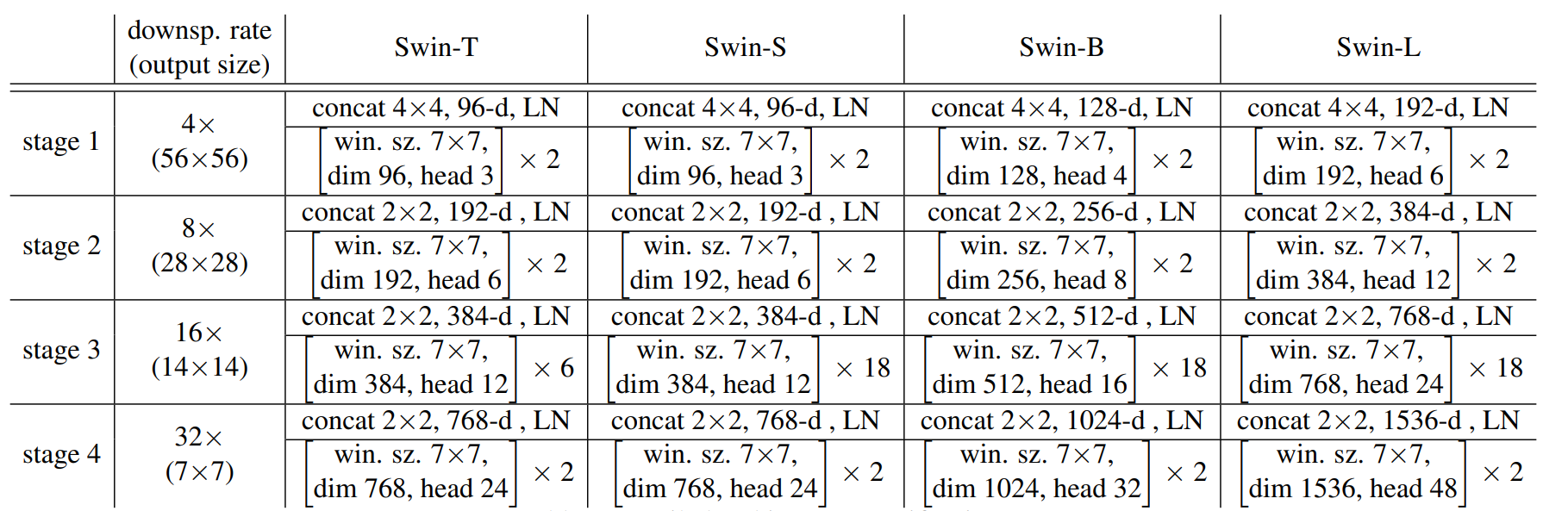
结构变体
Swin 变压器有 T、S、B 和 L 四种尺寸,每级的尺寸(dim)、头(head)和块数各不相同,如下表所示。
试验
在 ImageNet-1K 的图像识别任务、COCO 的物体检测任务和 ADE20K 的语义分割任务中与其他模型进行了比较,结果都达到了最高准确率。(实验结果详见本文第四章表 1~表 3)。
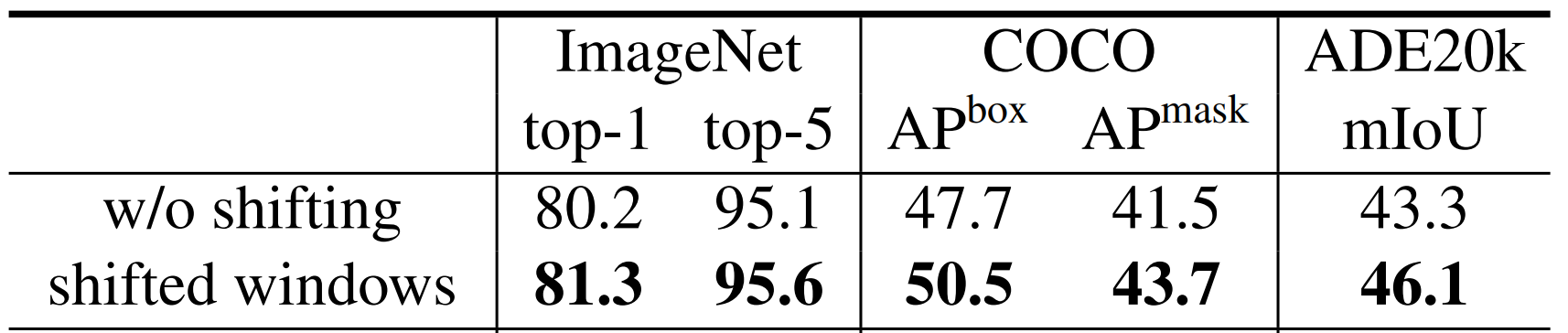
在 SW-MSA 中进行的消融研究证实,在这两项任务中,引入 SW-MSA 的准确率都高于单独引入 W-MSA。
摘要
与在所有斑块之间计算注意力的 ViT 不同,注意力计算和斑块聚合可以在相邻斑块的窗口中重复进行,从而可以在不同尺度上提取特征。另一个优点是不在所有斑块之间计算注意力,从而降低了计算复杂度,并能从较小的斑块尺寸中提取特征。