写在前面:
首先感谢兄弟们的订阅,让我有创作的动力,在创作过程我会尽最大能力,保证作品的质量,如果有问题,可以私信我,让我们携手共进,共创辉煌。
路虽远,行则将至;事虽难,做则必成。只要有愚公移山的志气、滴水穿石的毅力,脚踏实地,埋头苦干,积跬步以至千里,就一定能够把宏伟目标变为美好现实。
1、介绍
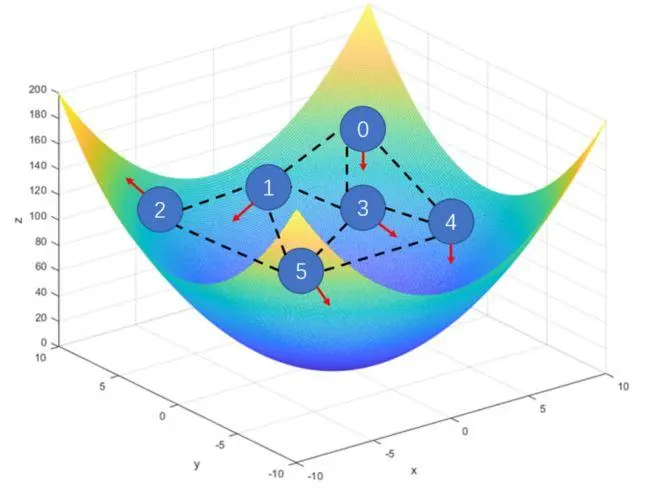
粒子群优化(PSO)算法是一种受到鸟群觅食行为启发的优化算法。在PSO中,每个粒子代表一个解,而整个粒子群则代表了解空间。算法的基本思想是通过粒子之间的合作与竞争,不断更新粒子的位置和速度,以找到最优解。
而pyswarm是一个专门用于实现粒子群优化(PSO)的Python库。它提供了一组工具和类,使得用户能够轻松地使用PSO算法来解决连续和组合优化问题。通过pyswarm,用户能够利用PSO的并行性和全局搜索能力,快速找到问题的最优解。
pyswarm库具有以下几个特点:
- 易用性:pyswarm提供了简洁明了的API接口,用户只需要定义适应度函数和设置相应的参数,即可开始使用PSO算法进行优化。
- 灵活性:pyswarm允许用户自定义适应度函数和粒子群的行为,以适应不同的问题需求。用户可以根据问题的特性,调整粒子的速度更新公式和位置更新公式,以获得更好的优化效果。
- 高效性:pyswarm利用Python的高效数值计算库,如NumPy,来加速计算过程。这使得pyswarm在处理大规模优化问题时能够保持较高的效率。
在使用pyswarm时,用户通常需要指定搜索空间的上下界、粒子群的大小和最大迭代次数等参数。然后,通过调用pyswarm的函数来执行优化过程。优化完成后,pyswarm会返回找到的最优解和相应的适应度值。
总的来说,pyswarm是一个功能强大且易于使用的粒子群优化库,适用于解决各种优化问题。通过它,用户可以方便地利用PSO算法的全局搜索能力,快速找到问题的最优解。
2、实战代码
本次博文的内容聚焦于实战,如何使用pyswarm中的pso进行参数优化,下面给出一个优化函数的实例:
import pyswarm
import numpy as np # 定义目标函数
def objective_function(x): # 计算成本或损失 return np.sum(x**2) # 定义搜索空间的边界
lb = [-10, -10] # 下界
ub = [10, 10] # 上界 # 设置粒子群大小和最大迭代次数
swarmsize = 100
maxiter = 100 # 执行 PSO 优化
xopt, fopt = pyswarm.pso(objective_function, lb, ub, swarmsize=swarmsize, maxiter=maxiter) # 输出最优解和最优值
print("Optimal position:", xopt)
print("Optimal cost:", fopt)
提供的代码示例展示了如何使用 pyswarm 库中的 pso 函数来执行粒子群优化(PSO)算法,以找到给定目标函数的最小值。代码定义了一个目标函数 objective_function,它计算了输入向量 x 中每个元素的平方和。然后,设置了搜索空间的边界 lb 和 ub,定义了粒子群的大小 swarmsize 和最大迭代次数 maxiter。最后,调用 pyswarm.pso 函数来执行优化,并打印出找到的最优解和最优值。
代码本身看起来是正确的,并且应该能够正常运行。当运行这段代码时,pyswarm 会使用粒子群优化算法来寻找目标函数 objective_function 在指定搜索空间内的最小值。在每次迭代中,粒子会根据它们的位置、速度和个体/全局最优解来更新它们的位置,直到达到最大迭代次数或满足其他停止条件。
请注意,由于 pyswarm 是一个随机算法,每次运行代码时得到的最优解可能会有所不同,尽管在多次运行后通常会收敛到相近的值。此外,对于某些复杂的问题,可能需要调整 swarmsize 和 maxiter 等参数以获得更好的结果。
如果遇到任何问题或错误,请确保已经正确安装了 pyswarm 库(可以通过运行 pip install pyswarm 来安装),并且的 Python 环境是兼容的。此外,如果使用的是较新的 pyswarm 版本,请检查其文档以确保参数和用法没有发生变化。
下面给出一个优化KNN分类的实例:
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score
from sklearn.neighbors import KNeighborsClassifier
from pyswarm import pso # 加载数据集
iris = load_iris()
X = iris.data
y = iris.target # 定义目标函数,使用交叉验证评估 KNN 分类器的性能
def objective_function(k): k = int(k)print("current k", k)# 初始化 KNN 分类器 knn = KNeighborsClassifier(n_neighbors=k) # 使用交叉验证评估分类器性能,这里使用5折交叉验证 scores = cross_val_score(knn, X, y, cv=5, scoring='accuracy') # 返回平均准确率作为优化目标 return -np.mean(scores) # 注意这里取负值,因为 pso 默认寻找最小值 # 设置 PSO 的参数范围
# 在这个例子中,我们优化 k 值,假设合理的范围是从 1 到 10
lb = [1]
ub = [10] # 运行 PSO 优化
xopt, fopt = pso(objective_function, lb, ub, swarmsize=100, maxiter=100, debug=False) # 输出最优 k 值和对应的负平均准确率
print(f"最优 k 值: {xopt[0]}")
print(f"最优负平均准确率: {fopt}") # 使用最优 k 值重新训练 KNN 分类器
best_knn = KNeighborsClassifier(n_neighbors=int(xopt[0]))
best_knn.fit(X, y) # 你可以进一步评估最佳模型的性能,例如计算测试集上的准确率等。
pyswarm 是一个 Python 库,用于实现粒子群优化(PSO)算法来解决优化问题。在使用 pyswarm 时,用户需要设置一些参数来控制优化过程。以下是一些常用的 pyswarm 参数及其解释:
- func: 这是一个函数对象,定义了要优化的目标函数。它接受一个表示潜在解的向量(例如一个NumPy数组)作为输入,并返回一个实数,即该解的评估值(例如成本或损失)。
- lb 和 ub: 这两个参数分别定义了搜索空间的下界和上界。它们通常是NumPy数组,其长度与目标函数的输入维度相同。这些边界限定了粒子在搜索空间中可以移动的范围。
- swarmsize: 这个参数定义了粒子群的大小,即参与优化的粒子数量。较大的粒子群可能有助于找到全局最优解,但也会增加计算成本。
- maxiter: 这个参数指定了优化过程的最大迭代次数。在达到最大迭代次数后,算法将停止,并返回当前找到的最优解。
- tol: 这是一个容忍度参数,用于判断何时停止优化过程。如果连续多次迭代中,最优解的变化小于此容忍度,算法将提前终止。
- debug: 这是一个布尔值,用于控制是否输出调试信息。如果设置为 True,则算法会在运行过程中输出一些中间结果和状态信息。