谈谈基于以太网的GPU Scale-UP网络
Intel Gaudi-3 采用 RoCE 互联技术,促进了 Scale-UP 解决方案。业界专家 Jim Keller 倡导以太网替代 NVLink。Tenstorrent 成功应用以太网实现片上网络互联。RoCE 和以太网已成为互联解决方案的新兴趋势,为高性能计算提供了强大且高效的连接选项。
要实现以太网替代 NVLink,需要对 GPU 架构进行全面修改,本质上等同于将 HBM 连接到以太网上并实现一系列通信优化。全球仅有少数公司掌握这项技术,包括针对计算需求的 In-Network-Computing 优化,如 SHARP。
博通打造NVLink竞品,需解决关键挑战:
- 数据传输速度和延迟优化
- 产品互联性和兼容性提升
- 生态系统发展和合作伙伴支持
链接延迟是不可避免的,源于高吞吐量高速 Serdes FEC 和超大型互连。单纯修改包协议或采用 HPC 以太网并不能解决此问题。
2.传输的语义是什么?做网络的这群人大概只懂个SEND/RECV。举个例子,UEC定义的Reliable Unordered Delivery for Idempotent operations(RUDI)其实就是一个典型的技术上的错误,一方面它满足了交换律和幂等律,但是针对一些算子,例如Reduction的加法如何实现幂等?显然这群人也没做过,还有针对NVLink上那种细颗粒度的访存,基于结合律的优化也是不支持的。更一般来说,它必须演进到Semi-Lattice的语义才行。
优化 NVLINK 上的内存池化,解决计算密集型算子(如 KV Cache)的时间/空间权衡问题,从而增强计算能力。
4.动态路由和拥塞控制能力1:1无收敛的Lossless组网对于万卡集群通过一些hardcode的调优没什么太大的问题,而对于十万卡和百万卡规模集群来看,甚至需要RDMA进行长传,这些问题目前来看没有一个商业厂商能解决的。
考虑到超大规模模型训练的一系列需求,把HBM直接挂载在以太网上并实现了一系列集合通信卸载的,放眼全球现在也就只有少数几个团队干过,前三个问题我是在四年前做NetDAM项目时就已经完全解决干净了,第四个去年也在某个云的团队一起解决干净了。下面我们将介绍一些Gaudi3/Maia100/TPU等多个厂商的互联,然后再分析一下NVLink的演进,最后再来谈谈如何能够真正地解决这些问题 at Scale
1. 当前ScaleUP互联方案概述
1.1 Intel Gaudi3
Gaudi的Die架构采用24个RoCE 200Gbps链路,21个用于内部全互联,3个用于外部连接,形成超大规模组网拓扑。每个边缘交换机的交换容量为25.6T。Intel WhitePaper值得深入研究,解决其提出的问题。
1.1.1 拥塞控制
Intel 采用 Selective ACK 机制取代 PFC,并使用 SWIFT 作为拥塞控制算法,避免 ECN。这种方法类似于 Google Falcon 在 Intel IPU 上的 Reliable Transport Engine,为数据中心网络提供了可靠、高效的传输。
1.1.2 多路径和In-Network Reduction
Intel 宣称支持 Packet Spraying,但使用博通交换机而非自有 Tofino。In-Network Reduction 兼容 FP8/BF16 等,而 Operator 仅支持求和、最小值和最大值。UEC 的 In-Network-Computing (INC) 工作组已明确此配置。
1.2 Microsoft Maia100
没有太多的信息,只有4800Gbps单芯片的带宽,然后单个服务器机框4张Maia100,整个机柜8个服务器构成一个32卡的集群。 放大交换机和互联的线缆来看,有三个交换机,每个服务器有24个400Gbps网络接口,网口间有回环的连接线(图中黑色),以及对外互联线(紫色)。
放大交换机和互联的线缆来看,有三个交换机,每个服务器有24个400Gbps网络接口,网口间有回环的连接线(图中黑色),以及对外互联线(紫色)。 也就是说很有可能构成如下的拓扑:
也就是说很有可能构成如下的拓扑: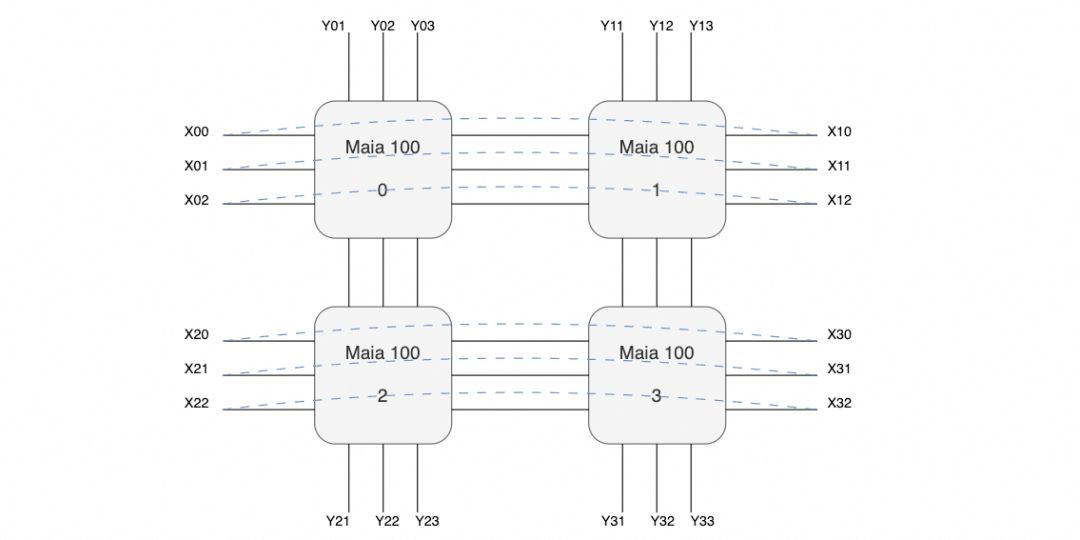 即在主板内部构成一个口字形的互联,然后在X方向构成一个环,而在Y方向则是分别构成三个平面连接到三个交换机。交换机上行进行机柜间的Scale-Out连接,每个机柜每个平面总共有32个400G接口, 再加上1:1收敛,上行交换机链路算在一起正好一个25.6T的交换机,这样搭几层扩展理论应该可行,算是一个Scale-Up和Scale-Out两张网络合并的代表。
即在主板内部构成一个口字形的互联,然后在X方向构成一个环,而在Y方向则是分别构成三个平面连接到三个交换机。交换机上行进行机柜间的Scale-Out连接,每个机柜每个平面总共有32个400G接口, 再加上1:1收敛,上行交换机链路算在一起正好一个25.6T的交换机,这样搭几层扩展理论应该可行,算是一个Scale-Up和Scale-Out两张网络合并的代表。
至于协议对于Torus Ring来看,简单的点到点RoCE应该问题不大,互联到Scale-Out交换机时就需要多路径的能力了。缺点是延迟可能有点大,不过这类自定义的芯片如果不是和CUDA那样走SIMT,而是走脉动阵列的方式,延迟也不是太大的问题。另外Torus整个组就4块,集合通信延迟影响也不大。但是个人觉得这东西可能还是用于做推理为主的,一般CSP都会先做一块推理用的芯片,再做训练的。另外两家CSP也有明确的训练推理区分AWS Trainium/Inferentia, Google也是V5p/V5e。
1.3 Google TPU
TPU互联大家已经很清楚了,Torus Ring的拓扑结构和光交换机来做链路切换。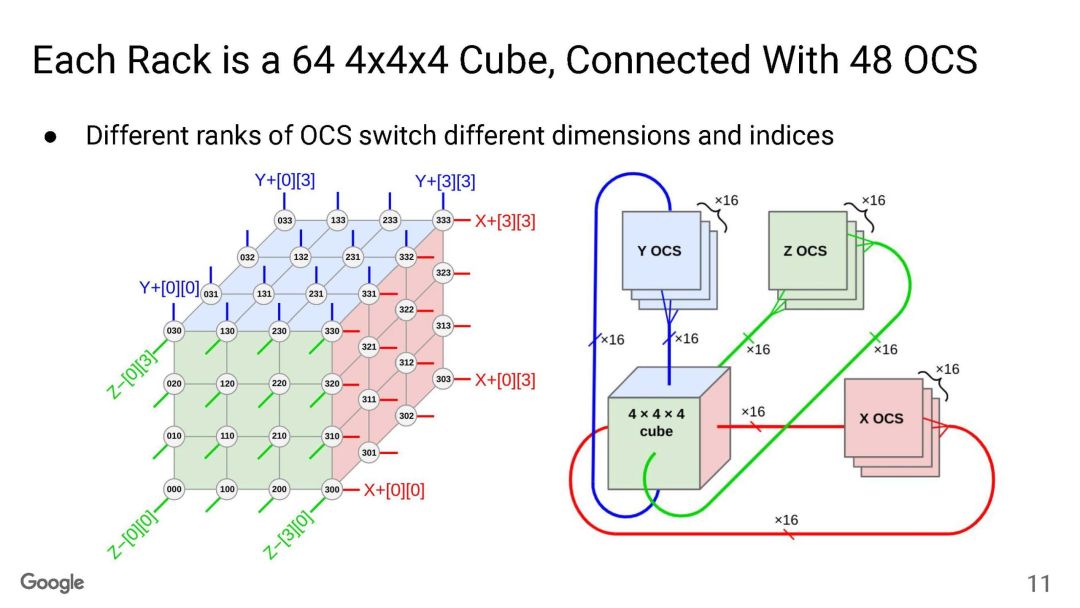
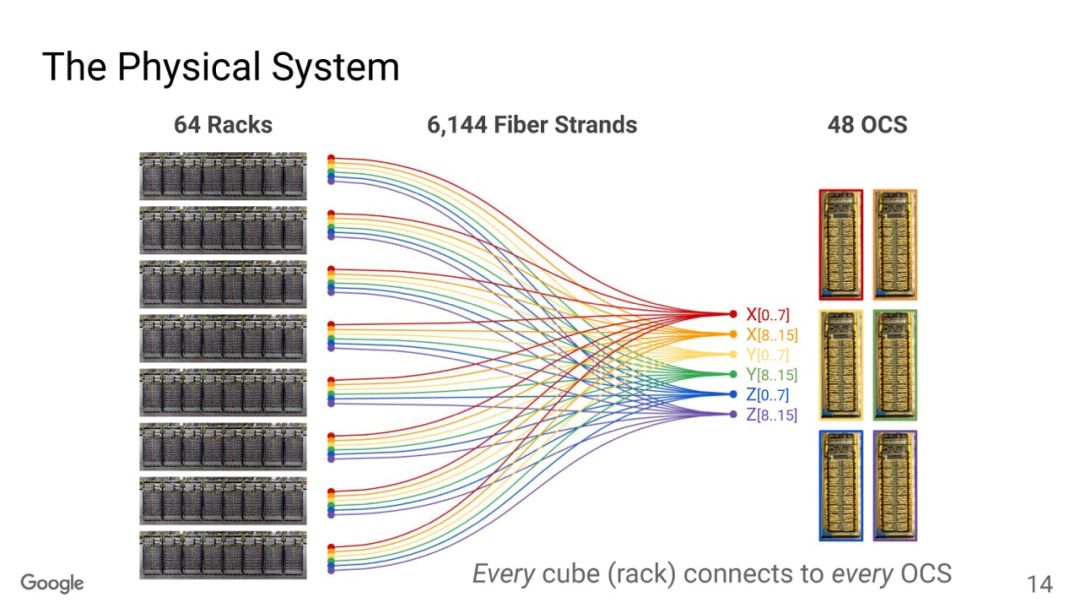 OCS有两个目的,一个是按照售卖的规模进行动态切分,例如TPUv5p 单芯片支持4800Gbps的ICI(Inter-Chip Interconnect)连接,拓扑为3D-Torus,整个集群8960块TPUv5p 最大售卖规模为6144块构成一个3D-Torus。
OCS有两个目的,一个是按照售卖的规模进行动态切分,例如TPUv5p 单芯片支持4800Gbps的ICI(Inter-Chip Interconnect)连接,拓扑为3D-Torus,整个集群8960块TPUv5p 最大售卖规模为6144块构成一个3D-Torus。 通过OCS可以切分这些接口进行不同尺度的售卖, 另一个是针对MoE这些AlltoAll的通信做扩展bisection 带宽的优化。
通过OCS可以切分这些接口进行不同尺度的售卖, 另一个是针对MoE这些AlltoAll的通信做扩展bisection 带宽的优化。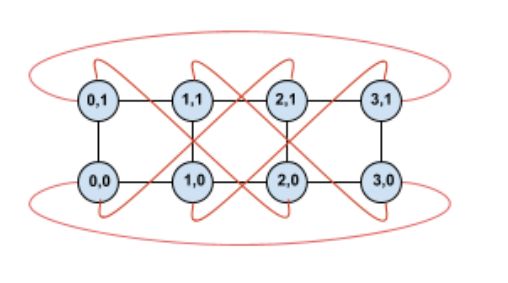 还有一个是容错,这是3D Torus拓扑必须要考虑的一个问题,有一些更新是这周NSDI‘24 讲到一个《Resiliency at Scale: Managing Google’s TPUv4 Machine Learning Supercomputer》[2] 后面我们将专门介绍。另一方面Google还支持通过数据中心网络扩展两个Pod构建Multislice的训练,Pod间做DP并行。
还有一个是容错,这是3D Torus拓扑必须要考虑的一个问题,有一些更新是这周NSDI‘24 讲到一个《Resiliency at Scale: Managing Google’s TPUv4 Machine Learning Supercomputer》[2] 后面我们将专门介绍。另一方面Google还支持通过数据中心网络扩展两个Pod构建Multislice的训练,Pod间做DP并行。
1.4 AWS Trainium
Trainium 架构由 16 片组成一个小型簇集,采用 2D Torus Ring 结构进行片间互连。这种结构确保了高速、低延迟的数据传输,为 AI 和机器学习模型的训练提供了卓越的性能。
1.5 Tesla Dojo
Tesla Transport Protocol(TTP)由 Tesla 开发,简化了芯片内部和外部通信。它整合了 Wafer/NOC 和以太网扩展,实现了统一通信,提升了效率和性能。
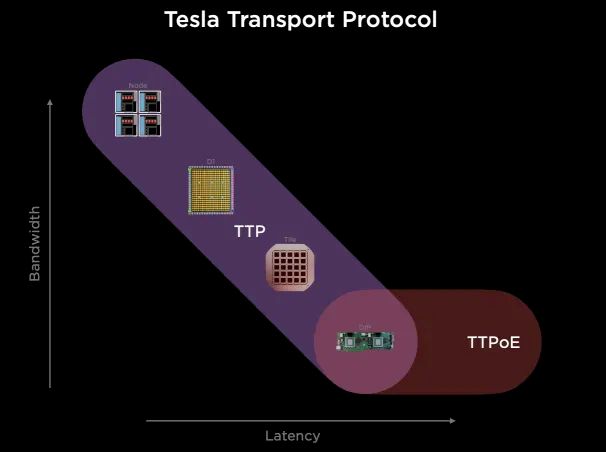
它通过台积电的System-on-Wafer将25个D1计算单元封装在一个晶圆上, 并采用5x5的方式构建2D Mesh网络互联所有的计算单元, 单个晶圆构成一个Tile.每个Tile有40个I/O Die。 Tile之间采用9TB/s互联。
Tile之间采用9TB/s互联。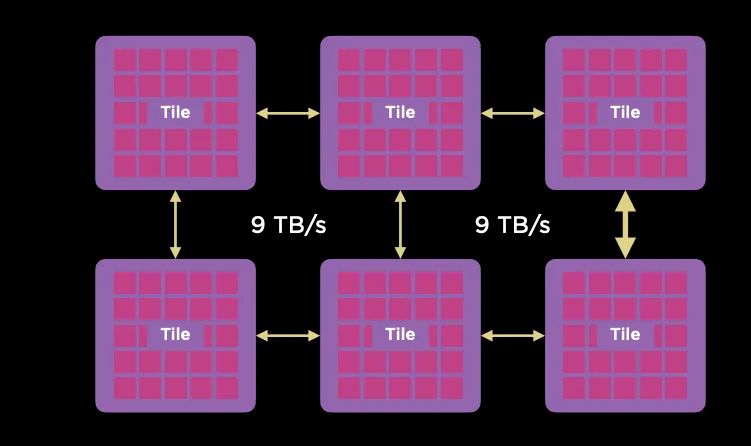 可以通过片上网络路由绕开失效的D1核或者Tile。
可以通过片上网络路由绕开失效的D1核或者Tile。
对外Scale-Out的以太网有一块DIP,每个D1计算引擎有自己的SRAM, 而其它内存放置在带HBM的Dojo接口卡(DIP)上。 每个网卡通过顶部的900GB/s特殊总线TTP(Tesla Transport Protocol)连接到Dojo的I/O Die上, 正好对应800GB HBM的带宽, 每个I/O Die可以连接5个Dojo接口卡(DIP)。
每个网卡通过顶部的900GB/s特殊总线TTP(Tesla Transport Protocol)连接到Dojo的I/O Die上, 正好对应800GB HBM的带宽, 每个I/O Die可以连接5个Dojo接口卡(DIP)。

由于内部通信为一个2D Mesh网络, 长距离通信代价很大, 针对片上路由做了一些特殊的设计。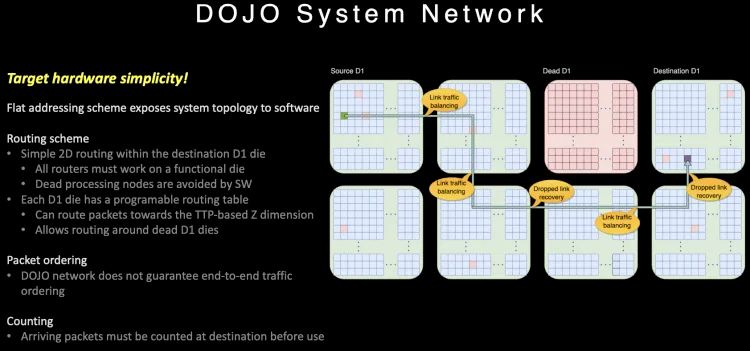 路由在片上提供多路径,并且不保序, 同时针对大范围长路径的通信, 它很巧妙的利用Dojo接口卡构建了一个400Gbps的以太网TTPoE总线来做shortcut。
路由在片上提供多路径,并且不保序, 同时针对大范围长路径的通信, 它很巧妙的利用Dojo接口卡构建了一个400Gbps的以太网TTPoE总线来做shortcut。 Dojo通过System-on-wafer的方式构建了基于晶圆尺度的高密度的片上网络, 同时通过私有的片间高速短距离总线构建了9TB/s的wafer间的通信网络. 然后将I/O和内存整合在DIP卡上,提供每卡900GB/s连接到晶圆片上网络的能力,构建了一个超大规模的2D Mesh网络, 但是考虑到片上网络通信距离过长带来的拥塞控制, 又设计了基于DIP卡的400Gbps逃生通道,通过片外的以太网交换机送到目的晶圆上。
Dojo通过System-on-wafer的方式构建了基于晶圆尺度的高密度的片上网络, 同时通过私有的片间高速短距离总线构建了9TB/s的wafer间的通信网络. 然后将I/O和内存整合在DIP卡上,提供每卡900GB/s连接到晶圆片上网络的能力,构建了一个超大规模的2D Mesh网络, 但是考虑到片上网络通信距离过长带来的拥塞控制, 又设计了基于DIP卡的400Gbps逃生通道,通过片外的以太网交换机送到目的晶圆上。
1.6 Tenstorrent
Tenstorrent 的片上网络采用简单有效的以太网设计,由 Tensor+ 控制头组成以太网报文,支持多种通信语义。网络结构划分为阶段,每个阶段的指令数和带宽可估计,从而简化映射到核上的约束。
该2D Mesh 结构可扩展至 40960 个核心的大规模互联,提供高效且可扩展的片间通信。
2. Scale-UP的技术需求
2.1 拓扑选择
我们可以注意到在ScaleUp网络选择中,Nvidia当前是1:1收敛的FatTree构建,而其它几家基本上都是Torus Ring或者2D Mesh,而Nvidia后续会演进到DragonFly。 背后的逻辑我们可以在hammingMesh的论文中看到的选择如下:
背后的逻辑我们可以在hammingMesh的论文中看到的选择如下: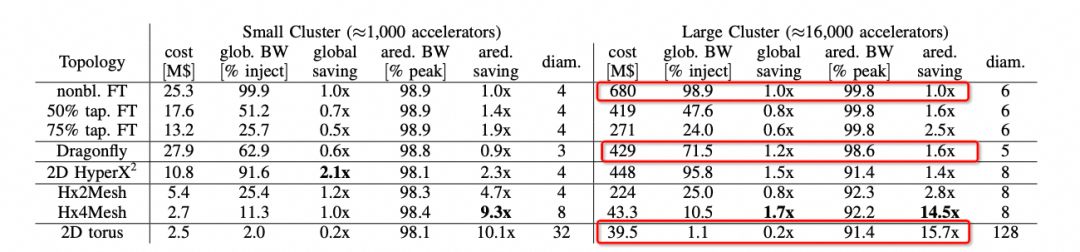 可以看到对于Allreduce带宽来看,Torus是最便宜的,性能也能够基本跑到峰值。但是针对MoE这类模型的AlltoAll就要考察bisection带宽了,而DragonFly无论是在布线复杂度还是GlobBW以及网络直径上都还不错,所以明白了Bill Dally的选择了吧?
可以看到对于Allreduce带宽来看,Torus是最便宜的,性能也能够基本跑到峰值。但是针对MoE这类模型的AlltoAll就要考察bisection带宽了,而DragonFly无论是在布线复杂度还是GlobBW以及网络直径上都还不错,所以明白了Bill Dally的选择了吧?
2.2 动态路由和可靠传输
当网络规模扩展至十万卡时,现有的流量工程解决方案存在局限性。单板级优化,如RoCE缺陷修复、Adaptive Routing和Packet Spraying,只能部分解决万卡规模问题。
对于超大规模网络,需要同时解决流量工程和亲和性控制的难题。
基于元数据的静态路由,管控平面调度和多轨道技术都可以作为解决方案的组成部分。通过综合应用这些技术,可以有效管理超大规模网络中的海量流量,确保网络性能和可靠性。
算法应对突发流量十分困难。令人担忧的是,人们往往忽视突发流量的根源,执着于通过测试交换机缓冲区来抑制它。一些人甚至诉诸确定性网络和傅立叶分析,这显然是徒劳的。
在工业界,优化调度仍面临挑战,取决于其他厂商的洞察力。
谷歌的研究表明,系统失效和弹性售卖会导致数据碎片,从而增加调度难度。
ICI内部路由解决方案与OCS交换机协作,提供完善的解决方案。
这篇论文深入披露了ICI的架构,包括物理层、可靠传输层、路由层和事务层,为理解该解决方案提供详细的技术见解。
以太网的路由层对于支持 ScaleUP 至关重要,因为它提供 DragonFly 和失效链路切换能力,确保以太网在复杂网络环境下保持高可用性。
3. Scale UP延迟重要么?
GPU延迟隐藏优化
GPU延迟隐藏通过以下方式实现:
* NVLink:内存语义,提供高带宽、低延迟。
* RDMA:消息语义,主要用于异构计算,延迟会更高。
GPU作为吞吐量优化的处理器,追求低延迟会导致实现问题。NVLink的内存语义使其具有较低延迟,而RDMA的消息语义和异构计算实现导致延迟较高。
3.1 RDMA实现的缺陷
RDMA相较NVLink延迟高的问题因CPU限制而起。NVIDIA引入GDA-KI技术,有效降低访存延迟,使得访问延迟变得更加容易隐藏。
3.2 细粒度的内存访问
NVLink 的细粒度访问对传输效率和延迟至关重要。利用以太网 RDMA 替换 NVLink 时,需要采用 HPC 以太网来支持较长的数据包。
此外,为实现 RDMA 消息的内部半格语义,需要遵循 NetDAM 中提出的解决方案。通过满足这些要求,可以有效弥补以太网 RDMA 在替换 NVLink 方面的不足。
- 交换律可以保证数据可以用UnOrder方式提交。
- 幂等性确保丢包重传不会导致重复处理。但在涉及副作用的加法操作(如 Reduce)时,需要采用事务或数据幂等性来处理。
- 结合律针对细粒度的内存访问,通过结合律编排,提升传输效率。
对于访存的需求,在主机内的协议如下: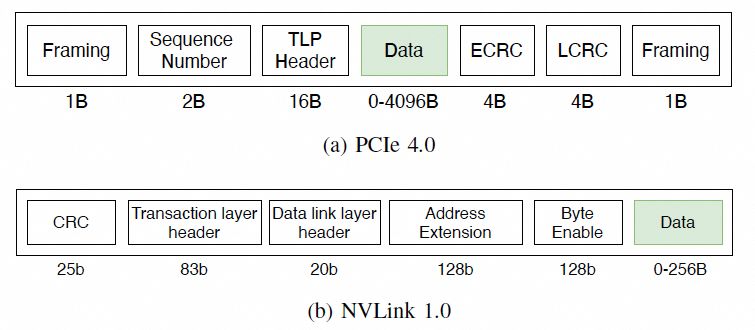 通常是一个FLIT的大小,而在这个基础上要支持超大规模的ScaleUP互联和支撑可靠性又要加一些路由头,还有以太网头,还有如果超大规模集群要多租户隔离还有VPC头,这些其实支持起来都没有太大问题的,因为当你考虑到了 结合律即可。但是UEC似乎完全没理解到,提供了RUDI的支持交换律和幂等律支持了,结合律忘了,真是一个失误。而英伟达针对这个问题怎么解的呢?结合律编码:
通常是一个FLIT的大小,而在这个基础上要支持超大规模的ScaleUP互联和支撑可靠性又要加一些路由头,还有以太网头,还有如果超大规模集群要多租户隔离还有VPC头,这些其实支持起来都没有太大问题的,因为当你考虑到了 结合律即可。但是UEC似乎完全没理解到,提供了RUDI的支持交换律和幂等律支持了,结合律忘了,真是一个失误。而英伟达针对这个问题怎么解的呢?结合律编码: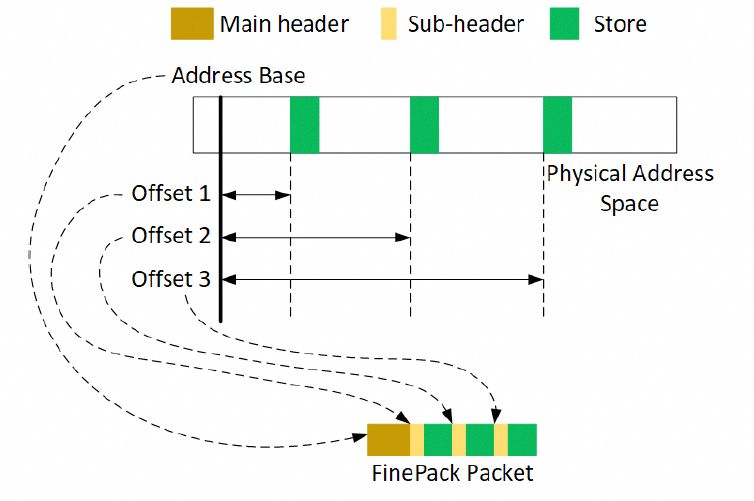
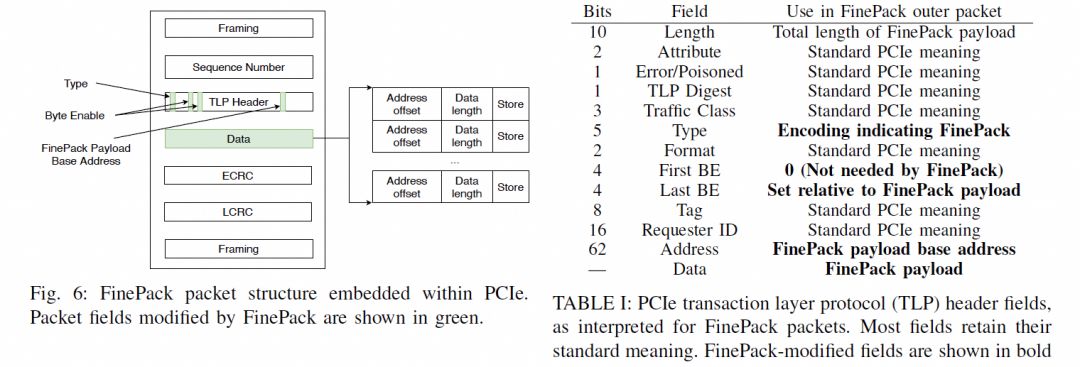 最终细颗粒度访存的问题解决了。
最终细颗粒度访存的问题解决了。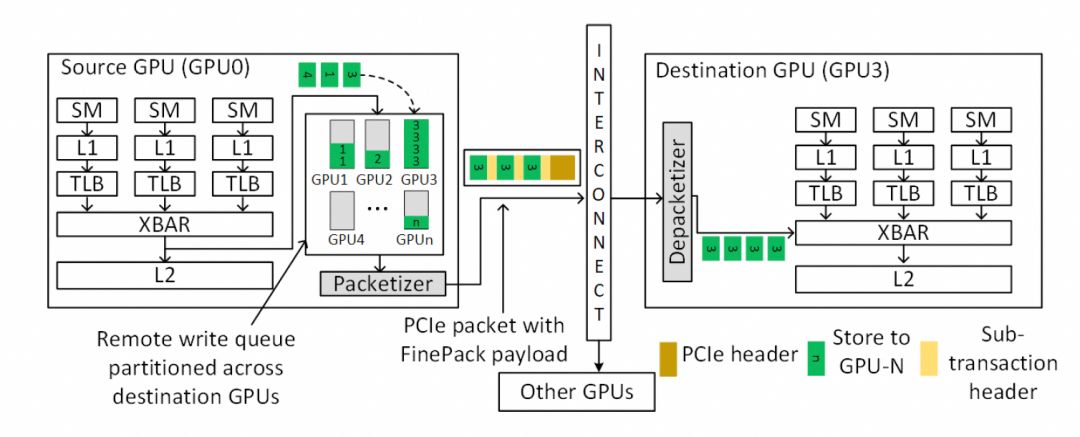 下一代的NVLink一定会走到这条路里面来Infiniband和NVLink这两张ScaleOut和ScaleUP网络一定会融合。
下一代的NVLink一定会走到这条路里面来Infiniband和NVLink这两张ScaleOut和ScaleUP网络一定会融合。
3.2 ScaleUP的内存池化
大模型面临 HBM 容量不足的挑战。英伟达通过 Grace 和 NVLink C2C 扩展解决了该问题,采用池化内存以支持 ScaleUP 网络。值得关注的是,英伟达正在探索其他方式来应对这一挑战,如论文中所展示的。
3. 结论
任何一家公司如果想做Ethernet的Scale UP,需要考虑以下大量的问题:
- 通过优化访问内存协议并利用 GPU 的缓存,FinePack 可显著缩短延迟。其创新的 Message 语义和缓存处理机制能有效隐藏延迟,提升整体性能。
- ScaleUP 网络的动态路由和租户隔离功能至关重要,优化路由以避免碎片问题,特别是当资源受链路故障影响时。
- RDMA语义不完善,且直接复制SHARP存在隐患。为实现幂等,需要完善Semi-Lattice语义,支持有副作用操作的幂等实现。
- Fabric的多路径转发和拥塞控制,提升整个Fabric利用率;
- 大规模内存池化。
NetDAM研究突破性地实现了以太网ScaleUP直连HBM,其消息编码策略与Jim Keller的成就一致,但基于不同出发点。此外,大规模池化和原生In-Network-Computing/Programming加速进一步增强了其功能。通过与多个团队合作,引入了先进的拥塞控制和多路径转发,完善了该方案。NetDAM的论文为以太网在HPC领域应用提供了宝贵的见解,值得深入研读。
探索英特尔® 高迪 3 AI 加速器,实现令人难以置信的 AI 性能。
这款业界领先的加速器提供:
- 高达 40 倍的训练性能提升
- 高达 10 倍的推理延迟降低
- 支持广泛的 AI 框架和模型
通过高迪 3,解锁前所未有的 AI 创新,推动您的业务实现新高度。
Google TPUv4:弹性超算
Google TPUv4 超级计算机是业界首屈一指的机器学习平台,拥有惊人的规模:
* 5,760 个 TPU 单元
* 600 万个 AI 模型训练
* 每天处理 200 PB 数据
该平台采用了创新技术,实现了前所未有的弹性:
* 弹性部署:按需部署 TPU,无需预先配置
* 故障隔离:将工作负载隔离到独立的 TPU,确保可靠性
* 动态弹性:自动扩展和缩小 TPU 容量,优化利用率
TPUv4 的弹性优势使 Google 能够高效管理其庞大的 ML 工作负载,加速模型训练并推动 AI 创新。
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-