前言
系列专栏:机器学习:高级应用与实践【项目实战100+】【2024】✨︎
在本专栏中不仅包含一些适合初学者的最新机器学习项目,每个项目都处理一组不同的问题,包括监督和无监督学习、分类、回归和聚类,而且涉及创建深度学习模型、处理非结构化数据以及指导复杂的模型,如卷积神经网络、门控递归单元、大型语言模型和强化学习模型
帕金森病是一种进行性疾病,会影响神经系统和由神经控制的身体部位,症状看起来也不太明显。僵硬、震颤和运动减慢可能是帕金森病的征兆。
但是,由于没有诊断这种疾病的诊断方法,因此无法确定一个人是否患有帕金森氏病。但是,如果我们使用机器学习来预测一个人是否患有帕金森氏病,那会怎么样呢?这正是我们将在本文中讨论的内容。
目录
1. 相关库和数据集
Python 库使我们能够非常轻松地处理数据并使用一行代码执行典型和复杂的任务。
Pandas– 该库有助于以 2D 数组格式加载数据框,并具有多种功能,可一次性执行分析任务。Numpy– Numpy 数组速度非常快,可以在很短的时间内执行大型计算。Matplotlib/Seaborn– 此库用于绘制可视化效果。Sklearn– 包含多个库,这些库具有预实现的功能,用于执行从数据预处理到模型开发和评估的任务。XGBoost– 包含eXtreme Gradient Boosting 机器学习算法,能帮助我们实现高精度预测。Imblearn– 此模块包含一个函数,可用于处理与数据不平衡相关的问题。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sbfrom imblearn.over_sampling import RandomOverSampler
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, MinMaxScaler
from sklearn.feature_selection import SelectKBest, chi2
from tqdm.notebook import tqdm
from sklearn import metrics
from sklearn.svm import SVC
from xgboost import XGBClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_auc_score as rasimport warnings
warnings.filterwarnings('ignore')
我们将在此处使用的UCI机器学习存储库中的数据集,包括755列和每位患者的三个观察值。这些列中的值是其他一些诊断的一部分,这些诊断通常用于捕获健康人与受影响的人之间的差异。现在,让我们将数据集加载到Pandas的数据框中。
df = pd.read_csv('pd_speech_features.csv')
1.1 首先让我们检查数据集的大小
df.shape
输出
(756, 755)
由于特征空间包含 755 列,因此数据集的维度非常高。让我们检查数据集的哪一列包含哪种类型的数据。
df.info()
输出
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 756 entries, 0 to 755
Columns: 755 entries, id to class
dtypes: float64(749), int64(6)
memory usage: 4.4 MB
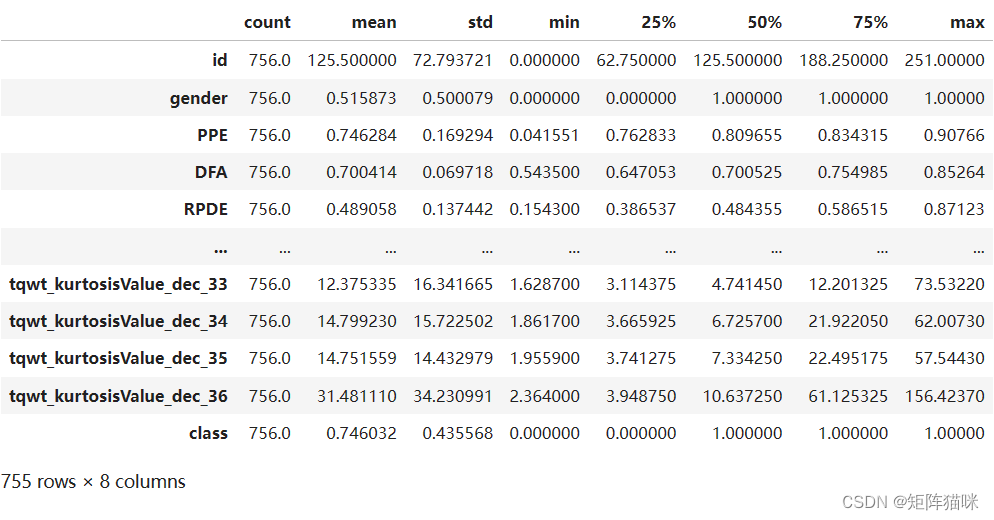
根据上述有关每列数据的信息,我们可以观察到没有空值。
df.describe().T
输出
1.2 数据清理
从主要来源获得的数据被称为原始数据,需要大量的预处理,然后才能从中得出任何结论或对其进行一些建模。这些预处理步骤称为数据清理,它包括异常值删除、空值插补以及删除数据输入中的任何类型的差异。
df = df.groupby('id').mean().reset_index()
df.drop('id', axis=1, inplace=True)
这些特征只表明它们是相互衍生出来的,或者我们可以说它们之间的相关性很高。在下面的代码块中,实现了一个函数,可以删除目标列之外的高度相关特征。
columns = list(df.columns)
for col in columns:if col == 'class':continuefiltered_columns = [col]for col1 in df.columns:if((col == col1) | (col == 'class')):continueval = df[col].corr(df[col1])if val > 0.7:# If the correlation between the two# features is more than 0.7 removecolumns.remove(col1)continueelse:filtered_columns.append(col1)# After each iteration filter out the columns# which are not highly correlated features.df = df[filtered_columns]
df.shape
输出
(252, 287)
1.3 卡方检验
因此,从755列的特征空间,我们将其减少到287列的特征空间。但是,由于特征数量仍然超过示例或数据点的数量,所以这个数字仍然太高。这一说法背后的原因与维度诅咒问题背后的原因相同,因为随着特征空间的增长,在数据集上进行泛化所需的示例数量变得困难,模型的性能也会降低。
因此,让我们通过使用卡方检验将特征空间减少到30。
X = df.drop('class', axis=1)
X_norm = MinMaxScaler().fit_transform(X)
selector = SelectKBest(chi2, k=30)
selector.fit(X_norm, df['class'])
filtered_columns = selector.get_support()
filtered_data = X.loc[:, filtered_columns]
filtered_data['class'] = df['class']
df = filtered_data
df.shape
输出
(252, 31)
1.4 数据检验
由于数据集的维度现在处于控制之下,让我们检查一下数据集是否对两个类都是平衡的。
x = df['class'].value_counts()
plt.pie(x.values,labels = x.index,autopct='%1.1f%%')
plt.show()
输出
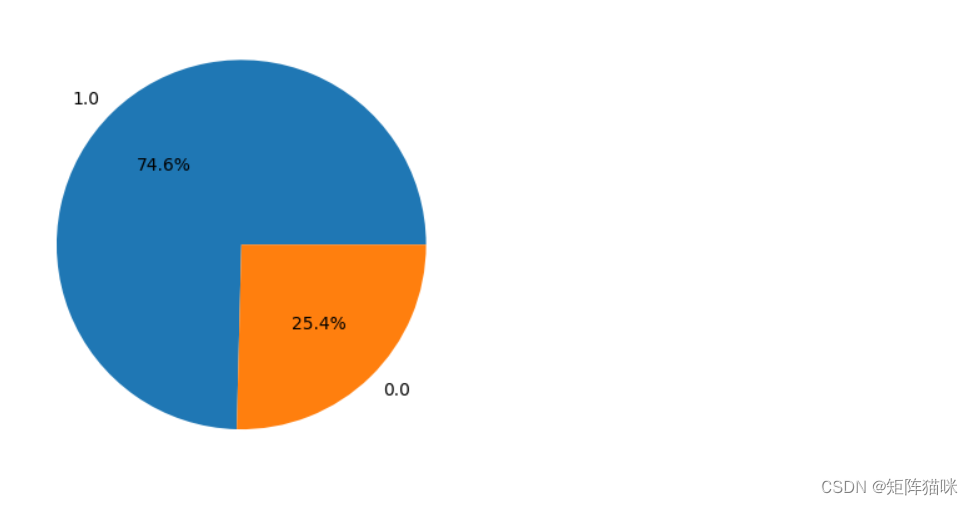
可以看出数据不平衡。我们必须解决这个问题,否则在这个数据集上训练的模型将更难预测阳性类别,这是我们在这里的主要目标。
2. 模型训练
2.1 数据分离(训练和测试)
现在我们将分离特征和目标变量,并将其分为训练数据和测试数据,通过使用这些数据,我们将选择在验证数据上表现最佳的模型。
features = df.drop('class', axis=1)
target = df['class']X_train, X_val,\Y_train, Y_val = train_test_split(features, target,test_size=0.2,random_state=10)
X_train.shape, X_val.shape
输出
((201, 30), (51, 30))
通过在少数类上使用过采样方法处理数据不平衡问题。
# As the data was highly imbalanced we will balance
# it by adding repetitive rows of minority class.
ros = RandomOverSampler(sampling_strategy='minority',random_state=0)
X, Y = ros.fit_resample(X_train, Y_train)
X.shape, Y.shape
输出
((302, 30), (302,))
2.2 数据建模(LogisticRegression、XGBClassifier、SVC)
数据集已经在数据清理步骤中进行了标准化,我们可以直接训练一些最先进的机器学习模型,并比较它们与我们的数据是否更匹配。
models = [LogisticRegression(), XGBClassifier(), SVC(kernel='rbf', probability=True)]for i in range(len(models)):models[i].fit(X, Y)print(f'{models[i]} : ')train_preds = models[i].predict_proba(X)[:, 1]print('Training Accuracy : ', ras(Y, train_preds))val_preds = models[i].predict_proba(X_val)[:, 1]print('Validation Accuracy : ', ras(Y_val, val_preds))print()
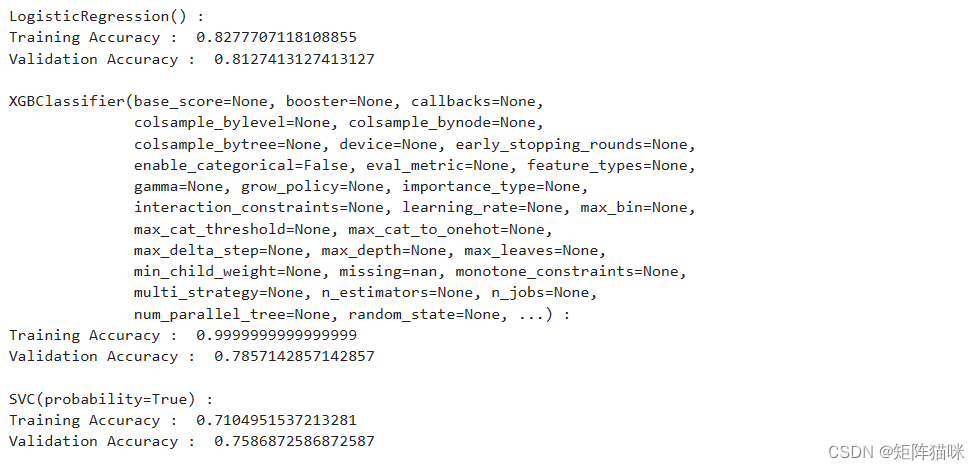
3. 模型评估
从上述准确度来看,我们可以说逻辑回归和SVC在验证数据上的表现更好,验证数据和训练数据之间的差异更小。让我们使用逻辑回归和SVC模型为验证数据绘制混淆矩阵。
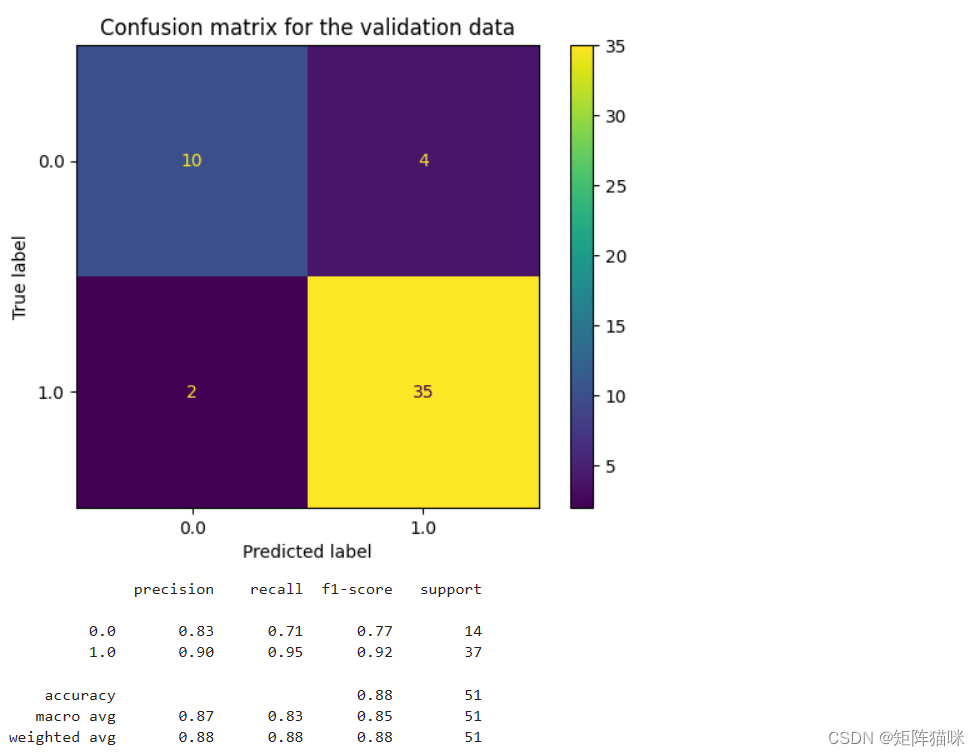
3.1 逻辑回归
metrics.ConfusionMatrixDisplay.from_estimator(models[0],X_val, Y_val)
plt.title('Confusion matrix for the validation data')
plt.show()
print(metrics.classification_report(Y_val, models[0].predict(X_val)))
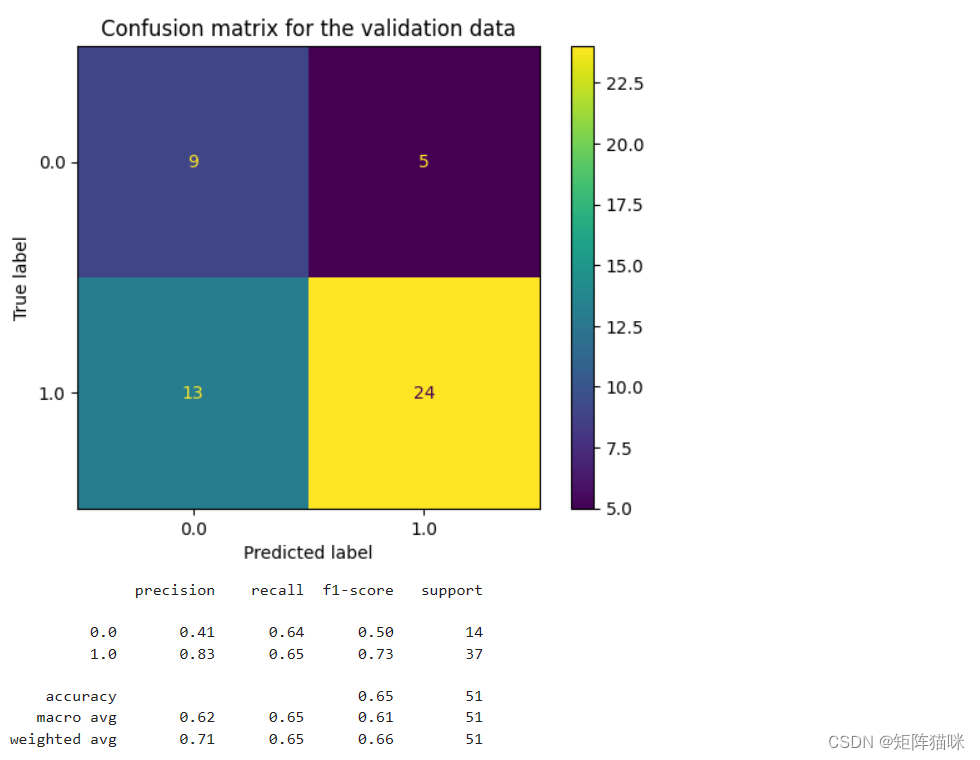
3.2 支持向量机
metrics.ConfusionMatrixDisplay.from_estimator(models[2],X_val, Y_val)
plt.title('Confusion matrix for the validation data')
plt.show()
print(metrics.classification_report(Y_val, models[2].predict(X_val)))
4. 结论
我们创建的机器学习模型的准确率约为75%至80%。对于没有诊断方法的疾病,机器学习模型能够预测一个人是否患有帕金森氏症。这就是机器学习的力量,通过使用它,许多现实世界的问题正在得到解决。
完整源码:基于Sklearn、XGBoost框架,使用逻辑回归、支持向量机和XGBClassifier预测帕金森病【源码】✨︎

![[Linux][网络][网络编程套接字][二][Socket编程接口][地址转换函数][TCP协议通讯流程]详细讲解](https://img-blog.csdnimg.cn/direct/405d0e9880b94b6c8f532bf1a8c47e8b.png)