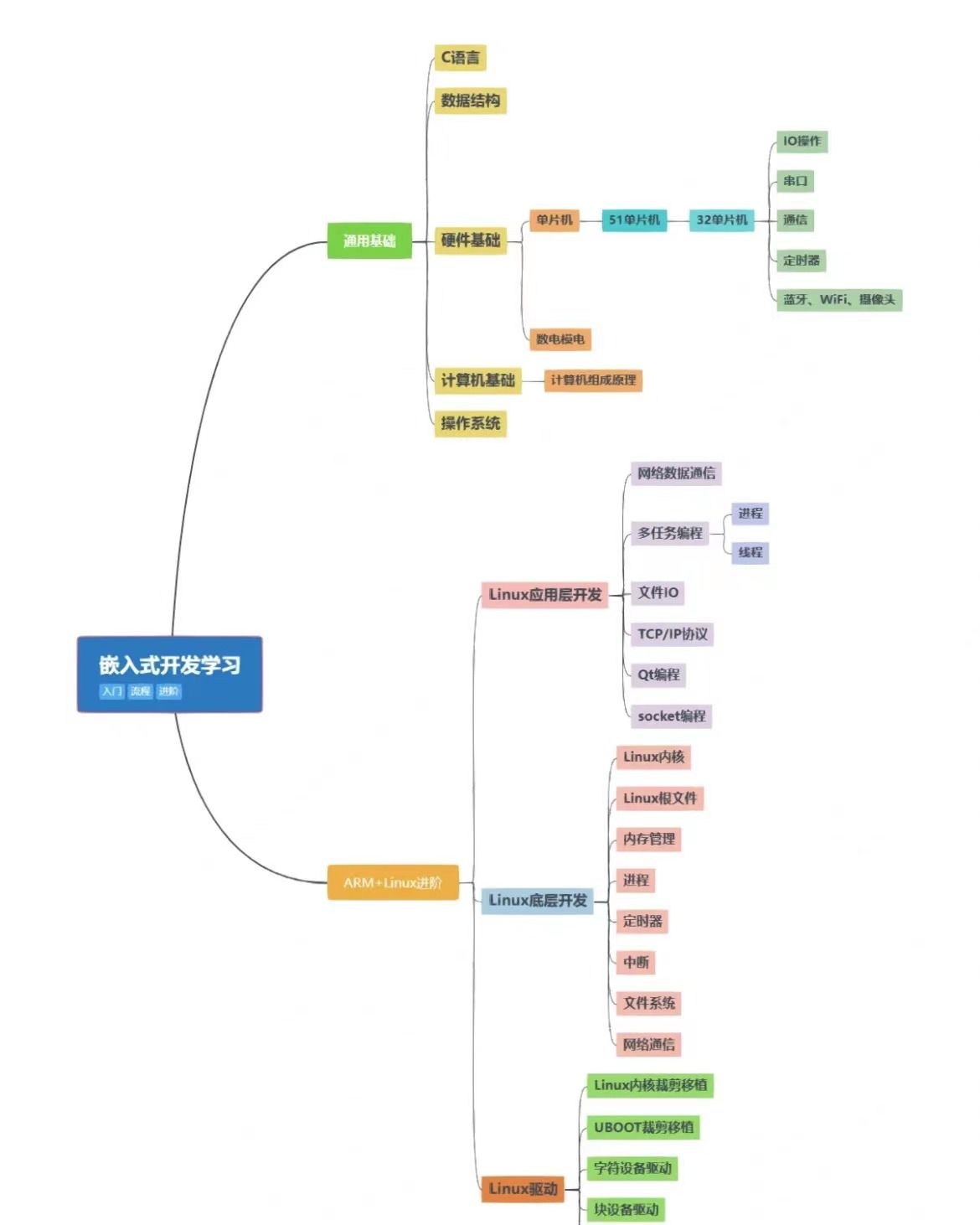
VGG
提出论文:1409.1556.pdf (arxiv.org)
引入
距离VGG网络的提出已经约十年,很难想象在深度学习高速发展的今天,一个模型能够历经十年而不衰。虽然如今已经有VGG的大量替代品,但是笔者研究的一些领域仍然有大量工作选择使用VGG。有人说VGG开创了基于一些基础结构(如Conv,Linear,RNN)进行模型堆叠的开端,但笔者更以为是其对深层次网络的研究和特征提取器这一概念的广泛使用作出了巨大贡献(但并不是首次提出)。深度学习高速发展之外,是硬件算力的高速发展。10年前使用VGG某种意义上也可以看成现如今使用LLM。VGG是由Visual Geometry Group中的两位大佬提出(VGG名字的由来就显而易见了)
模型介绍
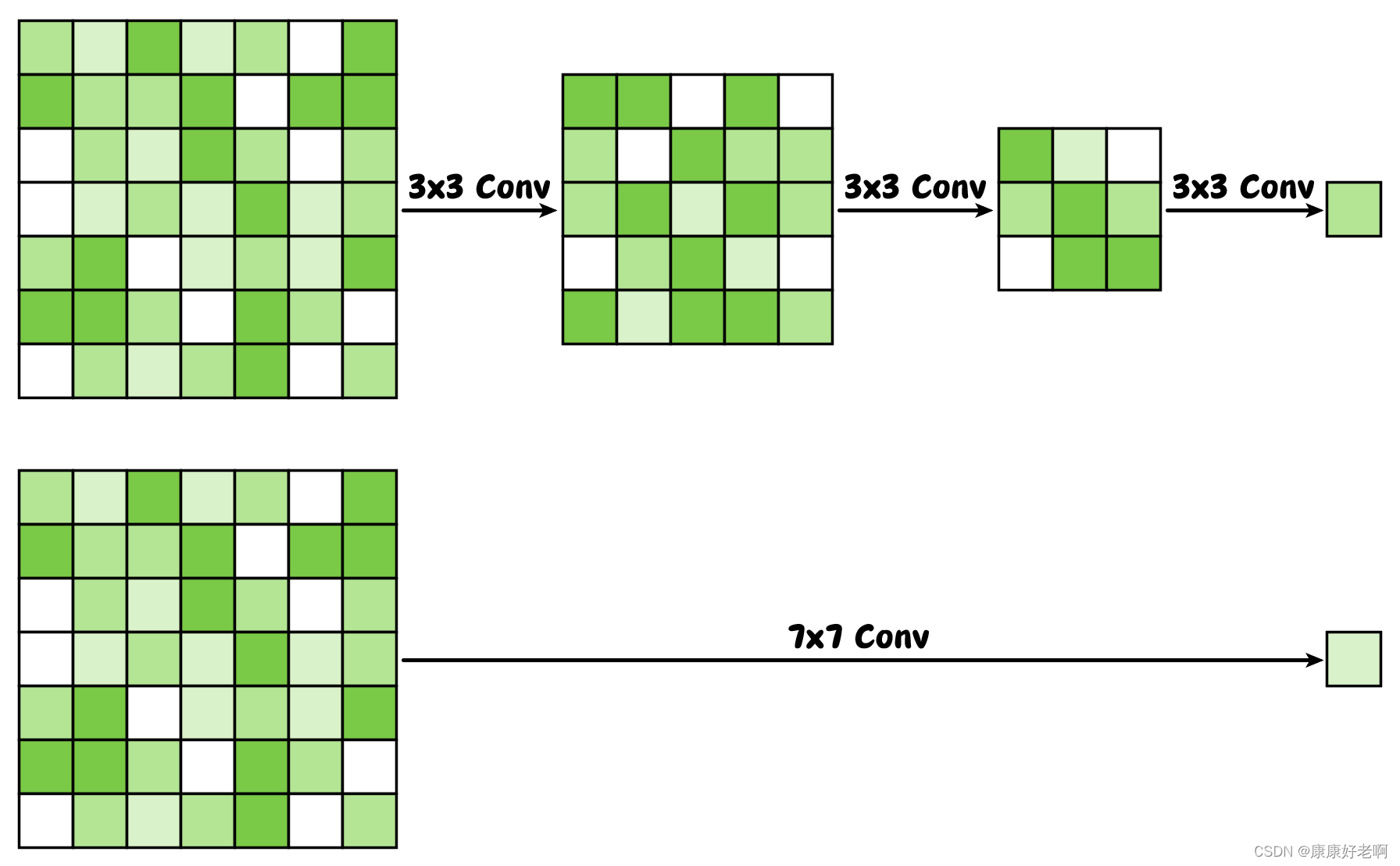
3×3卷积核
在VGG中,很大的贡献之一是使用了3×3卷积核以替代5×5卷积核、7×7卷积核等。这样的优点有两个:
(1)对相同大小的图像使用更小感受野的卷积,就会导致卷积的层数更多,层数更多意味着对非线性的拟合更好。这一点可以类比于高次函数可以拟合的曲线更多、更逼近。比如 y = a x + b y=ax+b y=ax+b就难以拟合曲线,而 y = ( a x + b ) ( c x + d ) y=(ax+b)(cx+d) y=(ax+b)(cx+d)就可以拟合部分曲线。
(2)对相同大小的图像使用3×3的卷积所需要的参数量更少。如图,如果用作者论文中举的例子就是,对一个7×7的感受野使用3×3的卷积总共需要 3 × ( 3 2 C 2 ) = 27 C 2 3\times(3^2C^2)=27C^2 3×(32C2)=27C2的参数,而使用7×7的卷积核则需要 ( 7 2 C 2 ) = 49 C 2 (7^2C^2)=49C^2 (72C2)=49C2的参数,其中 C C C代表通道数。
补充解释:一个3×3的卷积核参数量是 3 2 3^2 32,如果原始特征有 C C C个通道,输出特征也相应有 C C C个通道,那么每个通道对应相乘就得到 C 2 C^2 C2,而对于一个7×7的感受野,需要分成三个阶段使用3×3的卷积,所以再乘以3。
不同深度的VGG
VGG最常见的有四种模型结构,分别是VGG11,VGG13,VGG16,VGG19,其模型结构分别如下:
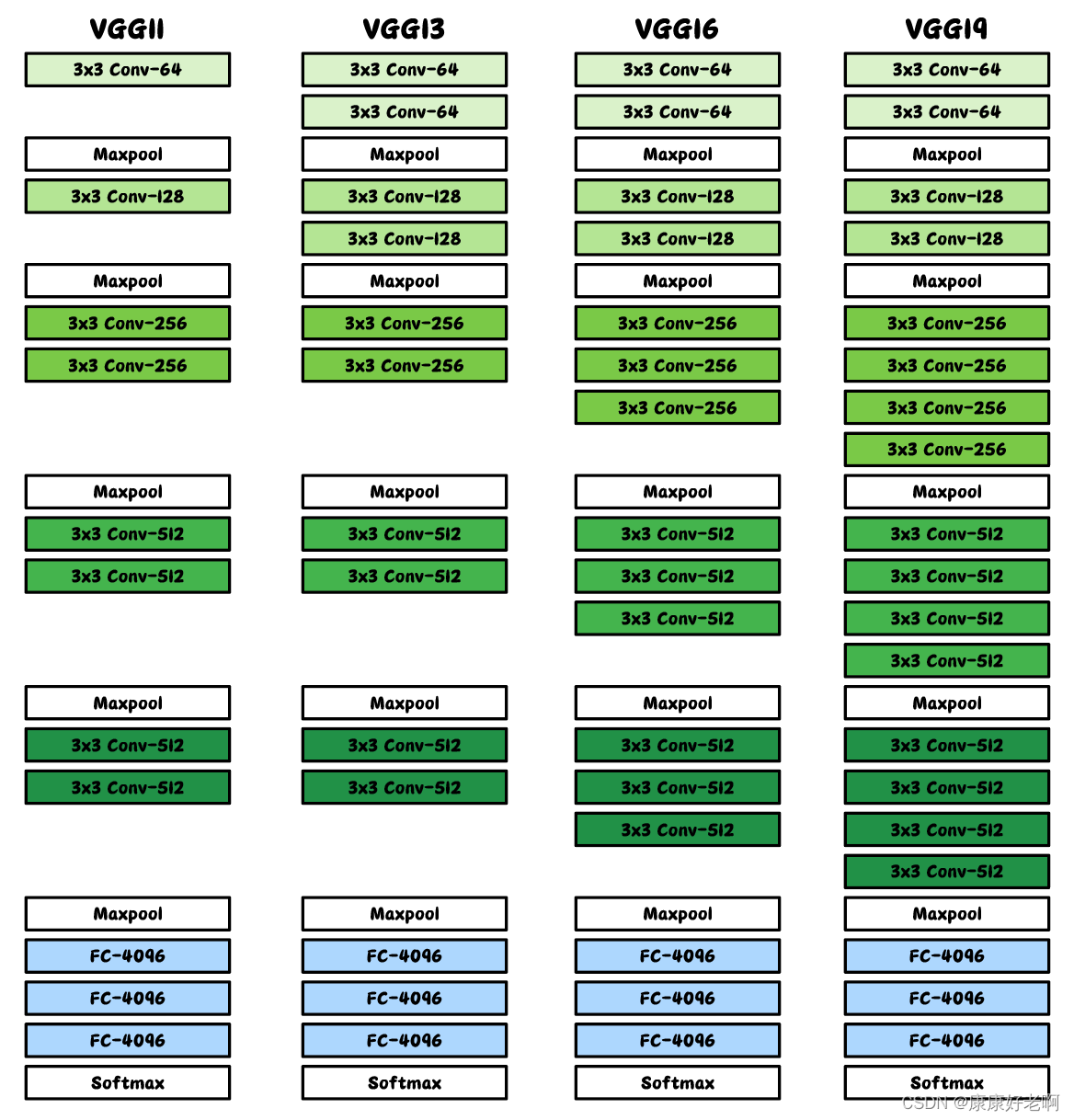
作者也是通过这四种不同深度的模型验证了更深的网络可以有效提高模型的效果。
代码实现
目前最便捷的方法是使用Pytorch中的torchvision库。
以VGG16举例:
下面是官方给的代码:
from torchvision.io import read_image
from torchvision.models import vgg16, VGG16_Weightsimg = read_image("image.jpg")# Step 1: Initialize model with the best available weights
weights = VGG16_Weights.DEFAULT
model = vgg16(weights=weights)
model.eval()# Step 2: Initialize the inference transforms
preprocess = weights.transforms()# Step 3: Apply inference preprocessing transforms
batch = preprocess(img).unsqueeze(0)# Step 4: Use the model and print the predicted category
prediction = model(batch).squeeze(0).softmax(0)
class_id = prediction.argmax().item()
score = prediction[class_id].item()
category_name = weights.meta["categories"][class_id]
print(f"{category_name}: {100 * score:.1f}%")
如果要封装成一个类,并控制输出的维度,可以使用如下代码:
import torch.nn as nn
import torchvision.models as models
from torchvision.models.vgg import VGG16_Weightsclass VGG16(nn.Module):def __init__(self):super(VGG16, self).__init__()self.vgg = models.vgg16(weights=VGG16_Weights.IMAGENET1K_V1)self.dim_feat = 4096self.vgg.classifier[6] = nn.Linear(4096, self.dim_feat)def forward(self, x):output = self.vgg(x)return output
当然,VGG并不止VGG16可以调用,下面是Pytorch官方给出的表格:
| Weight | Acc@1 | Acc@5 | Params | GFLOPS | Recipe |
|---|---|---|---|---|---|
VGG11_BN_Weights.IMAGENET1K_V1 | 70.37 | 89.81 | 132.9M | 7.61 | link |
VGG11_Weights.IMAGENET1K_V1 | 69.02 | 88.628 | 132.9M | 7.61 | link |
VGG13_BN_Weights.IMAGENET1K_V1 | 71.586 | 90.374 | 133.1M | 11.31 | link |
VGG13_Weights.IMAGENET1K_V1 | 69.928 | 89.246 | 133.0M | 11.31 | link |
VGG16_BN_Weights.IMAGENET1K_V1 | 73.36 | 91.516 | 138.4M | 15.47 | link |
VGG16_Weights.IMAGENET1K_V1 | 71.592 | 90.382 | 138.4M | 15.47 | link |
VGG16_Weights.IMAGENET1K_FEATURES | nan | nan | 138.4M | 15.47 | link |
VGG19_BN_Weights.IMAGENET1K_V1 | 74.218 | 91.842 | 143.7M | 19.63 | link |
VGG19_Weights.IMAGENET1K_V1 | 72.376 | 90.876 | 143.7M | 19.63 | link |