一:前言
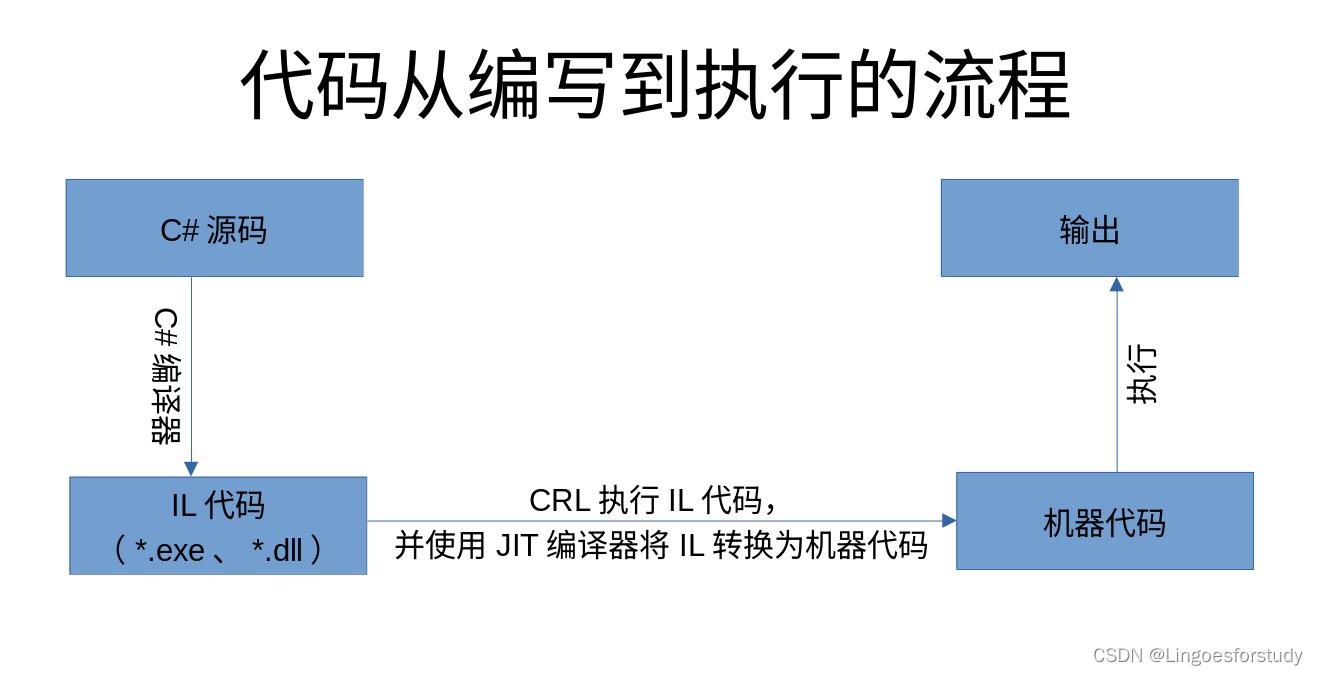
Dictionary是一种键值对的形式存放数据,即 key和value一一映射。key的类型没有限制,可以是整数、字符串甚至是实例对象
C#字典源码
时间复杂度
——Add:O(1)
——Remove:一般情况下为O(1),最差情况为O(n)
——Find:一般情况下为O(1),最差情况为O(n)
二:相关介绍
——Hash算法:Hash算法是一种数字摘要算法,将不定长度的数据根据不同的算法变成一个固定长度的Hash值,Hash值具有不可逆性的特点。常见的MD5算法就是一种Hash算法
——Hash函数:也称为散列函数。有很多种Hash函数,最常见的就是除留余数法,用Hash值除以一个值求余计算出一个索引值
——哈希冲突:不同的值通过算法>哈希算法后计算出的哈希值可能相同,那么就产生了哈希冲突,解决哈希冲突的方法有开放定址法、再哈希法、拉链法。C#字典解决哈希冲突的方法是拉链法
——字典内部是通过两个数组存储,如下图所示,一个是哈希桶用于解决哈希冲突,存储的是每个链表的头结点Entry下标。一个是Entry数组,内部形成一个链表,存储每一个数据实体
因为如果只用一个数组存储,一是每个Hash值对应一个索引那么需要声明一个超级大容量的数组,二是两个不同的key生成的哈希值也有可能相同会产生Hash碰撞。于是就有了哈希桶,将Hash值分类装到一个个桶里,减小了索引的范围,也使查找的效率更高
举个列子,如果我们知道一个人的身份证号,想要查询他的信息,拿身份证号去全国的数据库里查找肯定会很慢,但我们知道,从身份证号可以看出这个人是属于哪个省份或地区的,去所在地区的数据库查找,那肯定就比较快了
private struct Entry {public int hashCode; // Lower 31 bits of hash code, -1 if unusedpublic int next; // Index of next entry, -1 if lastpublic TKey key; // Key of entrypublic TValue value; // Value of entry
}private int[] buckets; // 哈希桶数组
private Entry[] entries; // 数据实体数组
...三:底层实现
——构造字典
声明字典容量相当于声明哈希桶和Entry数组的容量,两个桶的容量会取大于给定容量的一个质数
容量设置为质数的原因是因为计算桶下标是根据Hash值除以桶长度求余获得,那么Hash值和桶长度的公因子就应该尽量少,如果公因子多,那么数据的分布会不均匀,很多桶会是空的,所以容量设置为质数(素数)就是最佳选择了,
——Add
首先通过内置的GetHashCode函数计算出一个哈希值(如果是数值类型则哈希值就是这个数值,如果是其他类型则会通过某种算法计算出一个哈希值,GetHashCode(key) & 0x7FFFFFFF,逻辑与是为了确保Hash值是一个正整数),然后通过除留余数法计算出桶索引,将当前Entry的next指向上一个头结点Entry的下标,将buckets对应的桶索引设置为当前Entry的下标,相当于每次添加的Entry都是头结点
entries[index].hashCode = hashCode;
entries[index].next = buckets[targetBucket];
entries[index].key = key;
entries[index].value = value;
buckets[targetBucket] = index;
——Remove
字典内部声明了三个字段,FreeCount、FreeList和Count
FreeCount用于记录当前有几个被删除的元素位置是空闲的,FreeList用于存储上一个被删除的Entry下标,也是一个单链表结构,当删除某个元素时,首先找到对应的Entry数组位置将其删除,并赋值给FreeList,当下次添加元素时,优先判断FreeCount是否大于0,添加到FreeList空闲位置,如果没有空闲位置,则按照Count字段记录的位置去添加元素,Count表示为字典当前存储的有效元素的数量,每次Add后会+1
——Resize
字典出现的扩容的时机有两种,一个是数组已经满了无法存放新的元素,二是发生哈希碰撞的次数太多了,会影响性能(某一个哈希值的哈希碰撞次数过多导致这个哈希值下的链表太长了,遍历起来费时费力,浪费性能,所以会有一个碰撞的阈值来保证其性能)
扩容的过程首先是申请两倍于现在大小的buckets、entries并取大于给定容量的一个质数,然后将现有的元素拷贝到新的entries中(如果是Hash碰撞太多导致扩容,则使用新HashCode函数重新计算Hash值,再重建Hash链表)
——Find
字典内部查找时候FindEntry方法,首先通过同样的操作找到链表头节点的位置,通过遍历链表,比对hashCode和key值找到目标数据
查找某个key对应的valye时时使用TryGetValue只调用了1次FindEnty,而使用ContainKey判断是否存在后还需要通过this得到vlaue,一共需要调用2次FindEnty
四:几种数据结构的比较
这里比较一下Dictionary、HashSet、Hashtable、List
——如果是通过key去查找,Dictionary和Hashtable的效率是高于List的,如果是通foreash遍历,则List的效率更高(List底层是数组,内存是连续的。Dictionary和Hashtable底层是哈希表,根据Hash算法进行存储内存是不连续的,会产生更多的换页操作)
——HashSet的查找效率要高于List,因为HashSet内部原理是哈希表,只不过与Dictionary和Hashtable不同的是只存了key
——HashSet添加元素时会判断是否已经存在,不会添加重复的元素,可以使用HashSet去重