Python 正则表达式
目录
正则
flags:标志位
match函数
search函数
findall函数
finditer函数
元字符
匹配单个字符和数字
锚字符(边界字符)
^ 行首匹配
$ 行尾匹配
\A匹配字符串开始
\Z 匹配字符串结束
\b 匹配一个单词的边界
\B 匹配非单词的边界
匹配多个字符
应用
字符串切割
提取中间内容
字符串替换和修改
sub函数
subn函数
区别
分组
给组起名
编译
总结
正则
Python自1.5以后增加了re的模块,提供了正则表达式模式
re模块使Python语言拥有了全部的正则表达式功能。
flags:标志位
用于控制正则表达式的匹配方式,值如下
re.I 忽略大小写
re.L 做本地户识别
re.M 多行匹配,影响^和S
re.S 是.匹配包括换行符在内的所有字符
re.U 根据Unicode字符集解析字符,影响\w \W \b \B
re.X 使我们以更灵活的格式理解正则表达式
match函数
原型:match(pattern,stringflags=0)
patter:匹配的正则表达式
string:要匹配的字符串参数:
功能:尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,返回None
示例:
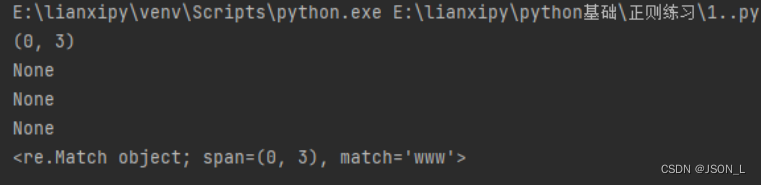
python">import re# www.baidu.com
print(re.match("www", "www.baiwwwdu.com").span())
print(re.match("www", "ww.baidu.com"))
print(re.match("www", "baidu.wwwcom"))
print(re.match("www", "wwW.baidu.com"))
print(re.match("www", "www.baidu.com", flags=re.I))
# 扫描整个字符申,返回从起始位置成功的匹配执行效果:
search函数
原型:search(pattern, string,flags=0)参数:
patter:匹机的正则表达式
string:要匹配的字符串
flags:标志位,用于控制正则表达式的匹配方式
功能:扫描整个字符串,并返回第一个成功的匹配
示例:
python">print(re.search("English", "Do you teach me English?"))执行效果:

findall函数
原型:findall(pattern,flags=0)string,参数:
patter:匹配的正则表达式
string:要匹配的字符串
flags:标志位,用于控制正则表达式的匹配方式
功能:扫描整个字符串,并返回结果列表
示例:
python">print(re.findall("English", "Do you teach me English?Yes, I teach you English.", flags=re.I))执行效果:

finditer函数
原型:finditer(pattern, string,flags=0)
参数:
patter:匹配的正则表达式
string:要匹配的字符串
flags:标志位,用于控制正则表达式的匹配方式
功能:与findall类似,扫描整个字符串,返回的是一个迭代器
示例:
python">str2 = 'Do you teach me English?Do I teach you English?Does he teach her English?'
gets = re.finditer('Do.*?English', str2)
print(gets, type(gets)) # <callable_iterator object at 0x00000172A48CB1C8> <class 'callable_iterator'> 结果为一个对象迭代器while True:try:print(next(gets))except StopIteration as e:break# 执行结果
# <callable_iterator object at 0x0000024CC9D8B288> <class 'callable_iterator'>
# <re.Match object; span=(0, 23), match='Do you teach me English'>
# <re.Match object; span=(24, 46), match='Do I teach you English'>
# <re.Match object; span=(47, 72), match='Does he teach her English'>
使用迭代器防止数据过多增大内存,使用next读取下一个。
元字符
匹配单个字符和数字
. 匹配除换行符以外的任意字符
[0123456789] []是字符集合,表示匹配方括号中所包含的任意一个字符
[a-z] 匹配任意小写字母
[A-Z] 匹配任意大写字母
[0-9] 匹配任意数字,类似[0123456789]
[0-9a-zA-Z] 匹配任意的数字和字母
[0-9a-zA-Z_] 匹配任意的数字、字母和下划线
[^cat] 匹配除了cat这几个字母以外的所有字符,中括号里的^称为脱字符,表示不匹配集合中的字符
[^0-9] 匹配所有的非数字字符
\d 匹配所有数字,效果同[0-9]
\D 匹配非数字,效果同[^0-9]
\w 匹配数字、字母和下划线,效果等同[0-9a-zA-Z_]
\s 匹配任意的空白符(空格,换行,回车,换页,制表)效果同[\f\n\r\t]
\S 匹配任意非空白符,效果同[^\f\n\r\t]
示例:
python">print(re.search('.', 'I have a cat.')) # 匹配的字母I
print(re.search('[0123456789]', 'I have 2 cats.')) # 匹配的数字2锚字符(边界字符)
^ 行首匹配
和在[]里的^不是一个意思
示例:
python">print(re.search('^Do', 'Do you teach me English?'))$ 行尾匹配
示例:
python">print(re.search('English.$', 'Yes, I teach you English.'))\A匹配字符串开始
它和^的区别是,\A只匹配整个字符串的开头,
即使在re.M模式下也不会匹配它行的行首。
示例:
python">print(re.findall('^Do', "Do you teach me English?\nDo he teaches him English?", re.M))
print(re.findall('\ADo', "Do you teach me English?\nDo he teaches him English?", re.M))执行效果:
E:\lianxipy\venv\Scripts\python.exe E:\lianxipy\python基础\正则练习\1..py
['Do', 'Do']
['Do']\Z 匹配字符串结束
它和$的区别是,\Z只匹配整个字符串的结束,即使在re.M模式下也不会匹配它行的行尾。
示例:
python">print(re.findall('English$', "I teach you English\nHe teaches me English", re.M))
print(re.findall('English\Z', "I teach you English\nHe teaches me English", re.M))执行效果:
E:\lianxipy\venv\Scripts\python.exe E:\lianxipy\python基础\正则练习\1..py
['English', 'English']
['English']\b 匹配一个单词的边界
也就是指单词和空格间的位置,’er\b’可以匹配never,但是不能匹配nerve
示例如下:
python">print(re.search(r'er\b', 'never'))
print(re.search(r'er\b', 'nerve'))效果:
E:\lianxipy\venv\Scripts\python.exe E:\lianxipy\python基础\正则练习\1..py
<re.Match object; span=(3, 5), match='er'>
None\B 匹配非单词的边界
示例:
python">print(re.search(r'er\B', 'never'))
print(re.search(r'er\B', 'nerve'))执行效果:
E:\lianxipy\venv\Scripts\python.exe E:\lianxipy\python基础\正则练习\1..py
None
<re.Match object; span=(1, 3), match='er'>匹配多个字符
下方的x、y、z均为假设的普通字符,不是正则表达式的元字符
(xyz) 匹配小括号内的xyz(作为一个整体去匹配)。
x? 匹配0个或者1个x
示例:
python">print(re.findall("a?", 'aaaa')) # 非贪婪模式(尽可能少的匹配)# 执行结果
# ['a', 'a', 'a', 'a', '']x* 匹配0个或者任意多个x(.*表示匹配0个或者任意多个字符(换行符除外))
示例:
python">print(re.findall("a*", 'aaaabbaaa')) # 贪婪模式(尽可能多的匹配)# 执行结果
# ['aaaa', '', '', 'aaa', '']x+ 匹配至少一个x
示例:
python">print(re.findall("a+", 'aaabbaaaa')) # 贪婪模式(尽可能多的匹配)# 执行结果
# ['aaa', 'aaaa']x{n} 匹配确定的n个x(n是一个非负整数)
x{n,} 匹配至少n个x
x{n,m} 匹配至少n个最多m个x。注意:n<=m
x|y |表示或,匹配x或者y
示例:
python">print(re.findall('a{4}', 'bbbaaaaaabaa'))
print(re.findall('a{4,}', 'bbbaaaaaabaa'))
print(re.findall('a{4,5}', 'bbbaaaaaabaa'))
print(re.findall('((a|A)aaa)', 'baaaaAaaab'))# 执行结果
# ['aaaa']
# ['aaaaaa']
# ['aaaaa']
# [('aaaa', 'a'), ('Aaaa', 'A')]应用
判断手机号
示例:
python">def check_phone(phone):reg = '^1[3578]\d{9}'if re.match(reg, phone) != None:print('正确')else:print('不正确')check_phone('13813103489')
check_phone('138131034890')
check_phone('10813103489')
check_phone('00813103489')
check_phone('19813103489')字符串切割
示例:
python">str1 = 'Do you teach me English?'
print(str1.split(' '))
print(re.split(' +', str1))# 执行结果
# ['Do', 'you', 'teach', 'me', 'English?']
# ['Do', 'you', 'teach', 'me', 'English?']提取中间内容
示例:
python">str2 = 'Do you teach me English?Do I teach you English?Does he teach her English?'
print(re.findall('Do.*?English', str2))# 执行结果
# ['Do you teach me English', 'Do I teach you English', 'Does he teach her English']字符串替换和修改
sub函数
subn函数
sub(pattern, repl,string,count=0)
subn(pattern, repl, string, count=0)
pattern:正则表达式(规则)
repl :指定的用来替换的字符串
string:目标字符串
count :最多替换次数
功能:在目标字符串中以正则表达式的规则匹配字符串,再它们替换成指定字符串。
可以指定替换的次数,如果不指定,替换所有的匹配字符串
示例:
python">str4 = 'aaabababab'
print(re.sub('b', 'a', str4))
print(re.subn('b', 'a', str4))# 执行结果
# aaaaaaaaaa
# ('aaaaaaaaaa', 4)区别
前者返回一个被替换的字符串,后者返回一个元组(第一个元素被替换的字符串,第二个元素表示被替换的次数)。
分组
概念:除了简单的判断是否匹配之外,正则表达式还有提取子串的功能。
用()表示的就是提取分组。
示例:
python">str5 = '0310-8899166'
alls = re.match('(\d{3,4})-(\d{7,8})', str5)
print(alls.group(0)) # 一直代表的是原始字符串
print(alls.group(1))
print(alls.group(2))
print(alls.groups()) # 获取所有匹配情况# 执行结果
# 0310-8899166
# 0310
# 8899166
# ('0310', '8899166')使用序号获取对应组的情况,group(0) 一直代表的是原始字符串
groups()查看匹配的各组情况
给组起名
可以通过以下方式给分组起名,起名后可以通过名称获取分组适用于匹配较多的情况。
示例:
python">str5 = '0310-8899166'
alls = re.match('(?P<first>\d{3,4})-(?P<two>\d{7,8})', str5)
print(alls.groups())
print(alls.group('first'))
print(alls.group('two'))
# 当然还可以使用原来的获取
print(alls.group(1))
print(alls.group(2))编译
当我们使用正则表达式时,re模块会干两件事
2.用编译后的正则表达式去匹配对象
compile(pattern, flags=0)
pattern:要编译的正则表达式
示例:
python">reg = '^1[3578]\d{9}'
# 原版
print(re.match(reg, '13666666666'))
# 编译版
obj = re.compile(reg)
print(obj.match('13666666666'))执行效果:
<re.Match object; span=(0, 11), match='13666666666'>
<re.Match object; span=(0, 11), match='13666666666'>总结
本篇主要是在学习python 正则时总结和练习笔记。