- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍦 参考文章:TensorFlow入门实战|第3周:天气识别
- 🍖 原作者:K同学啊|接辅导、项目定制
一、定义模型
from tempfile import TemporaryDirectory
from typing import Tuple
from torch import nn, Tensor
from torch.nn import TransformerEncoder, TransformerEncoderLayer
from torch.utils.data import Dataset
import math, os, torchclass TransformerModel(nn.Module):def __init__(self, ntoken: int, d_model: int, nhead: int, d_hid: int, nlayers: int, dropout: float = 0.5):super().__init__()self.pos_encoder = PositionalEncoding(d_model, dropout)# 编码器层堆栈encoder_layers = TransformerEncoderLayer(d_model, nhead, d_hid, dropout)# 编码器堆栈. pytorch已经实现了Transformer编码器层的堆栈,这里直接调用即可self.transformer_encoder = TransformerEncoder(encoder_layers, nlayers)self.embedding = nn.Embedding(ntoken, d_model)self.d_model = d_modelself.linear = nn.Linear(d_model, ntoken)self.init_weights()# 初始化权重def init_weights(self) -> None:initrange = 0.1self.embedding.weight.data.uniform_(-initrange, initrange)self.linear.bias.data.zero_()self.linear.weight.data.uniform_(-initrange, initrange)def forward(self, src: Tensor, src_mask: Tensor = None) -> Tensor:"""Arguments:src: Tensor, 形状为 [seq_len, batch_size]src_mask: Tensor, 形状为 [seq_len, seq_len]Returns:最终的 Tensor, 形状为 [seq_len, batch_size, ntoken]"""src = self.embedding(src) * math.sqrt(self.d_model)src = self.pos_encoder(src)output = self.transformer_encoder(src, src_mask)output = self.linear(output)return outputclass PositionalEncoding(nn.Module):def __init__(self, d_model: int, dropout: float = 0.1, max_len: int = 5000):super().__init__()self.dropout = nn.Dropout(p=dropout)# 位置编码器的初始化部分position = torch.arange(max_len).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model))pe = torch.zeros(max_len, 1, d_model)pe[:, 0, 0::2] = torch.sin(position * div_term)pe[:, 0, 1::2] = torch.cos(position * div_term)# 注册为持久状态变量,不参与参数优化self.register_buffer('pe', pe)def forward(self, x: Tensor) -> Tensor:"""Arguments:x: Tensor, 形状为 [seq_len, batch_size, embedding_dim]Returns:最终的 Tensor, 形状为 [seq_len, batch_size, embedding_dim]"""x = x + self.pe[:x.size(0)]return self.dropout(x)

二、加载数据集
wikitext2_dir = "d:/wikitext-2-v1/wikitext-2"# Modify the data processing function to read from the local file
def data_process(file_path: str) -> Tensor:with open(file_path, 'r', encoding='utf-8') as file:data = [torch.tensor(vocab(tokenizer(line)), dtype=torch.long) for line in file]return torch.cat(tuple(filter(lambda t: t.numel() > 0, data)))# Load train, validation, and test data from local files
train_file = os.path.join(wikitext2_dir, "wiki.train.tokens")
val_file = os.path.join(wikitext2_dir, "wiki.valid.tokens")
test_file = os.path.join(wikitext2_dir, "wiki.test.tokens")train_data = data_process(train_file)
val_data = data_process(val_file)
test_data = data_process(test_file)# 使用数据处理函数处理数据集
train_data = data_process(train_iter)
val_data = data_process(val_iter)
test_data = data_process(test_iter)# 设置设备优先使用GPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# 将数据集分批的函数
def batchify(data: Tensor, bsz: int) -> Tensor:# 计算批次大小nbatch = data.size(0) // bsz# 裁剪掉多余的部分使得能够完全分为批次data = data.narrow(0, 0, nbatch * bsz)# 重新整理数据维度为[批次, 批次大小]data = data.view(bsz, -1).t().contiguous()# 将数据移动到指定设备return data.to(device)# 批次大小
batch_size = 20
eval_batch_size = 10# 应用batchify函数分批处理训练集、验证集和测试集
train_data = batchify(train_data, batch_size) # 结果为 [序列长度, batch_size]
val_data = batchify(val_data, eval_batch_size)
test_data = batchify(test_data, eval_batch_size)bptt = 35def get_batch(source: Tensor, i: int) -> Tuple[Tensor, Tensor]:"""生成批次数据参数:source: Tensor, 形状为 `[full_seq_len, batch_size]`i: int, 批次索引值返回:tuple (data, target).- data包含输入 [seq_len, batch_size],- target包含标签 [seq_len * batch_size]"""seq_len = min(bptt, len(source) - 1 - i)data = source[i:i+seq_len]target = source[i+1:i+1+seq_len].reshape(-1)return data, target
三、实例初始化
ntokens = len(vocab) # 词汇表的大小
emsize = 200 # 嵌入维度
nhid = 200 # nn.TransformerEncoder 中间层的维度
nlayers = 2 # nn.TransformerEncoder层的数量
nhead = 2 # nn.MultiheadAttention 头的数量
dropout = 0.2 # 丢弃率# 初始化 Transformer 模型,并将其发送到指定设备
model = TransformerModel(ntokens, emsize, nhead, nhid, nlayers, dropout).to(device)
四、训练模型
import time# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
lr = 5.0 # 学习率
optimizer = torch.optim.SGD(model.parameters(), lr=lr) # 使用SGD优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1, gamma=0.95) # 学习率衰减# 训练函数
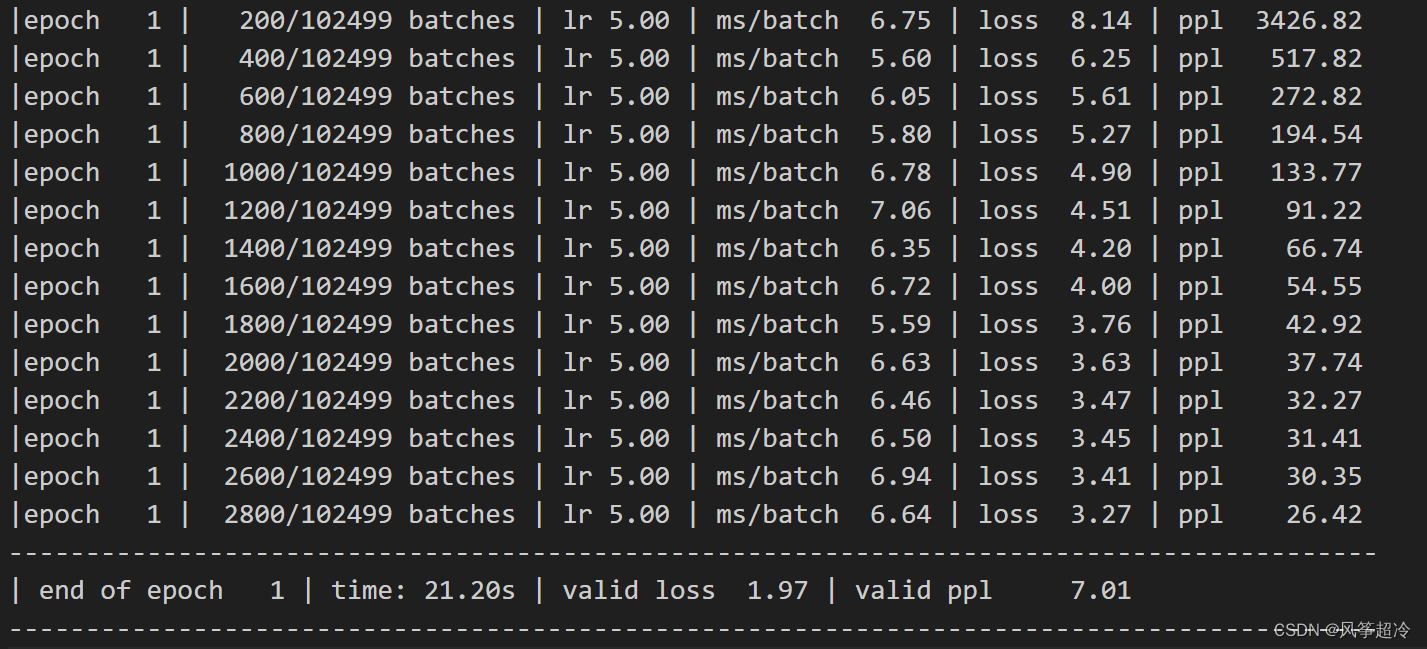
def train(model: nn.Module) -> None:model.train() # 开启训练模式total_loss = 0.log_interval = 200 # 每隔200个batch打印一次日志start_time = time.time()num_batches = len(train_data) // bpttfor batch, i in enumerate(range(0, train_data.size(0) - 1, bptt)):data, targets = get_batch(train_data, i)output = model(data)output_flat = output.view(-1, ntokens)loss = criterion(output_flat, targets)optimizer.zero_grad() # 梯度清零loss.backward() # 反向传播torch.nn.utils.clip_grad_norm_(model.parameters(), 0.5) # 梯度裁剪optimizer.step() # 更新参数total_loss += loss.item()if batch % log_interval == 0 and batch > 0:lr = scheduler.get_last_lr()[0] # 获取当前学习率ms_per_batch = (time.time() - start_time) * 1000 / log_intervalcur_loss = total_loss / log_intervalppl = math.exp(cur_loss)print(f'| epoch {epoch:3d} | {batch:5d}/{num_batches:5d} batches | 'f'lr {lr:02.2f} | ms/batch {ms_per_batch:5.2f} | 'f'loss {cur_loss:5.2f} | ppl {ppl:8.2f}')total_loss = 0start_time = time.time()# 评估函数
def evaluate(model: nn.Module, eval_data: Tensor) -> float:model.eval() # 开启评估模式total_loss = 0.with torch.no_grad():for i in range(0, eval_data.size(0) - 1, bptt):data, targets = get_batch(eval_data, i)output = model(data)output_flat = output.view(-1, ntokens)total_loss += criterion(output_flat, targets).item()return total_loss / (len(eval_data) - 1)
训练函数train通过多次迭代数据,并使用梯度下降来更新模型的权重。它还包括了每个日志间隔打印损失和困惑度(perplexity,常用于语言模型的评估指标)。评估函数evaluate用于计算模型在验证集或测试集上的性能,但不会进行参数更新。代码还展示了如何使用学习率调度器来随着训练进行逐步减小学习率。
best_val_loss = float('inf') # 初始设置最佳验证集损失为无穷大
epochs = 1 # 设置训练的总轮数为1
best_model_params = None # 用于存储最佳模型参数# 使用临时目录存储模型参数
with TemporaryDirectory() as tempdir:best_model_params_path = os.path.join(tempdir, "best_model_params.pt")# 循环遍历每个epochfor epoch in range(1, epochs + 1):epoch_start_time = time.time()train(model)val_loss = evaluate(model, val_data) # 在验证集上评估当前模型print('-' * 89)elapsed = time.time() - epoch_start_timeprint(f'| end of epoch {epoch:3d} | time: {elapsed:5.2f}s | valid loss {val_loss:5.2f} | 'f'valid ppl {math.exp(val_loss):8.2f}')print('-' * 89)# 检查当前epoch的验证集损失是否为最佳if val_loss < best_val_loss:best_val_loss = val_loss # 更新最佳验证集损失best_model_params = model.state_dict() # 保存最佳模型参数# 保存有最佳验证集损失的模型参数torch.save(best_model_params, best_model_params_path)scheduler.step() # 更新学习率# 加载最佳模型参数,以便在测试集上进行评估或进一步训练
model.load_state_dict(torch.load(best_model_params_path))
五、评估模型
test_loss = evaluate(model, test_data)
test_ppl = math.exp(test_loss)print('-' * 89)
print(f'| End of training | test loss {test_loss:5.2f} | 'f'test ppl {test_ppl:8.2f}')
print('-' * 89)