1. 概述
- Cgroups 的全称是control groups,cgroups为每种可以控制的资源定义了一个子系统。
- Cgroups分为三个部分:
- cgroup 本身:对进程进行分组
- hierarchy:将 cgroup 形成树形结构
- subsystem:真正起到限制作用的部组件
- cpu 子系统:主要限制进程的 cpu 使用率。
- cpuacct 子系统:可以统计 cgroups 中的进程的 cpu 使用报告。
- cpuset 子系统:可以为 cgroups 中的进程分配单独的 cpu 节点或者内存节点。
- memory 子系统:可以限制进程的 memory 使用量。
- blkio 子系统:可以限制进程的块设备 io。
- devices 子系统:可以控制进程能够访问某些设备。
- net_cls 子系统:可以标记 cgroups 中进程的网络数据包,然后可以使用 tc 模块(traffic control)对数据包进行控制。
- freezer 子系统:可以挂起或者恢复 cgroups 中的进程。
- ns 子系统:可以使不同 cgroups 下面的进程使用不同的 namespace。
- 这里面每一个子系统都需要与内核的其他模块配合来完成资源的控制,比如对 cpu 资源的限制是通过进程调度模块根据 cpu 子系统的配置来完成的;对内存资源的限制则是内存模块根据 memory 子系统的配置来完成的,而对网络数据包的控制则需要 Traffic Control 子系统来配合完成。
2. Cgroups 层级结构(Hierarchy)
- 内核使用 cgroup 结构体来表示一个 control group 对某一个或者某几个 cgroups 子系统的资源限制。
- cgroup 结构体可以组织成一颗树的形式,每一棵cgroup 结构体组成的树称之为一个 cgroups 层级结构。
- cgroups层级结构可以 attach 一个或者几个 cgroups 子系统,当前层级结构可以对其 attach 的 cgroups 子系统进行资源的限制。
- 每一个 cgroups 子系统只能被 attach 到一个 cpu 层级结构中。
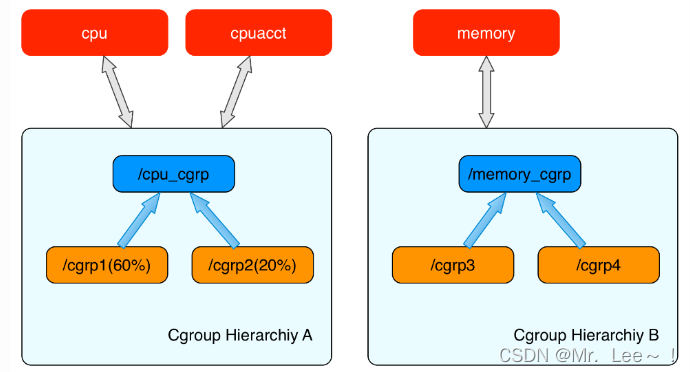
- 上图表示两个cgroups层级结构,每一个层级结构中是一颗树形结构,树的每一个节点是一个 cgroup 结构体(比如cpu_cgrp, memory_cgrp)。
- 第一个 cgroups 层级结构 attach 了 cpu 子系统和 cpuacct 子系统, 当前 cgroups 层级结构中的 cgroup 结构体就可以对 cpu 的资源进行限制,并且对进程的 cpu 使用情况进行统计。
- 第二个 cgroups 层级结构 attach 了 memory 子系统,当前 cgroups 层级结构中的 cgroup 结构体就可以对 memory 的资源进行限制。
- 在每一个 cgroups 层级结构中,每一个节点(cgroup 结构体)可以设置对资源不同的限制权重。比如上图中 cgrp1 组中的进程可以使用60%的 cpu 时间片,而 cgrp2 组中的进程可以使用20%的 cpu 时间片。
3. 进程与 Cgroups 层级结构的联系
- 在创建了 cgroups 层级结构中的节点(cgroup 结构体)之后,可以把进程加入到某一个节点的控制任务列表中,一个节点的控制列表中的所有进程都会受到当前节点的资源限制。
- 同时某一个进程也可以被加入到不同的 cgroups 层级结构的节点中,因为不同的 cgroups 层级结构可以负责不同的系统资源。所以说进程和 cgroup 结构体是一个多对多的关系。

P代表一个进程。每一个进程的描述符中有一个指针指向了一个辅助数据结构css_set(cgroups subsystem set)。 指向某一个css_set的进程会被加入到当前css_set的进程链表中。一个进程只能隶属于一个css_set,一个css_set可以包含多个进程,隶属于同一css_set的进程受到同一个css_set所关联的资源限制。- ”M×N Linkage”说明的是
css_set通过辅助数据结构可以与 cgroups 节点进行多对多的关联。但是 cgroups 的实现不允许css_set同时关联同一个cgroups层级结构下多个节点。 这是因为 cgroups 对同一种资源不允许有多个限制配置。 - 一个
css_set关联多个 cgroups 层级结构的节点时,表明需要对当前css_set下的进程进行多种资源的控制。而一个 cgroups 节点关联多个css_set时,表明多个css_set下的进程列表受到同一份资源的相同限制。
4. Cgroups文件系统
- Linux内核通过 VFS (Virtual File System)把具体文件系统的细节隐藏起来,给用户态进程提供一个统一的文件系统 API 接口。 Cgroups 也是通过 VFS 把功能暴露给用户态的,cgroups 与 VFS 之间的衔接部分称之为 Cgroups 文件系统。
- VFS 通用文件模型中包含以下四种元数据结构:
- 超级块对象(superblock object),用于存放已经注册的文件系统的信息。
- 比如ext2,ext3等这些基础的磁盘文件系统,还有用于读写socket的socket文件系统,以及当前的用于读写cgroups配置信息的 cgroups 文件系统等。
- 索引节点对象(inode object),用于存放具体文件的信息。
- 对于一般的磁盘文件系统而言,inode 节点中一般会存放文件在硬盘中的存储块等信息;
- 对于socket文件系统,inode会存放socket的相关属性;
- 对于cgroups这样的特殊文件系统,inode会存放与 cgroup 节点相关的属性信息。这里面比较重要的一个部分是一个叫做 inode_operations 的结构体,这个结构体定义了在具体文件系统中创建文件,删除文件等的具体实现。
- 文件对象(file object),一个文件对象表示进程内打开的一个文件,文件对象是存放在进程的文件描述符表里面的。同样这个文件中比较重要的部分是一个叫 file_operations 的结构体,这个结构体描述了具体的文件系统的读写实现。当进程在某一个文件描述符上调用读写操作时,实际调用的是 file_operations 中定义的方法。
- 对于普通的磁盘文件系统,file_operations 中定义的就是普通的块设备读写操作;
- 对于socket文件系统,file_operations 中定义的就是 socket 对应的 send/recv 等操作;
- 对于cgroups这样的特殊文件系统,file_operations 中定义的就是操作 cgroup 结构体等具体的实现。
- 目录项对象(dentry object),在每个文件系统中,内核在查找某一个路径中的文件时,会为内核路径上的每一个分量都生成一个目录项对象,通过目录项对象能够找到对应的 inode 对象,目录项对象一般会被缓存,从而提高内核查找速度。
- 超级块对象(superblock object),用于存放已经注册的文件系统的信息。
dockerCgroups_54">5. docker是怎么使用Cgroups的
- Docker 在实现不同的 Container 之间资源隔离和控制的时候,是可以创建比较复杂的 cgroups 节点和配置文件来完成的。然后对于同一个 Container 中的进程,可以把这些进程 PID 添加到同一组 cgroups 子节点中已达到对这些进程进行同样的资源限制。
- 如何实现:
- 具体实例:
- 第一步,启动一个容器,用
-m来设置内存参数为128M- 该命令执行后 docker 会在 memory cgroup 上(也就是
/sys/fs/cgroup/memory路径下)创建一个叫 docker 的子 cgroup,即/sys/fs/cgroup/memory/docker/ 
- 内部除了 cgroup 相关的文件外,还有很多目录,使用容器 ID 作为目录名,其中每个目录即对应一个容器。其中,
da82f9e...这个目录名称和容器 ID 一致,说明 docker 是为每个容器创建了一个子 cgroup 来单独限制。 - 查看里面的配置可以发现,memory.limit_in_bytes 中配置的值为 134217728,转换一下
134217728/1024/1024=128M, 刚好就是我们指定的 128M
- 该命令执行后 docker 会在 memory cgroup 上(也就是
- 第二步,停止该容器(不是删除容器),再次查看cgroup情况,发现目录已经被删除,说明容器对应的子 cgroup 也同步被回收
- 第三步,把停止的容器start,再次查看Cgroup情况,可以发现同名目录又被创建出来了
- 第一步,启动一个容器,用