题目链接:P3405 [USACO16DEC] Cities and States S - 洛谷
1.分析题目

- 对于一个城市,我只考虑前两个字符是什么,剩下的字符我不关心,对这道题没有影响
2.算法原理
对于形如 <ab,xy>这样的对应关系,找出有多少个形如 <xy,ab>这样的对应关系的城市;
也就是从前往后遍历,在每一个城市里都可以找到<ab,xy>这样的对应关系,在看看在所有的城市里面有多少个城市和州是<xy,ab>这样的对应关系
如何把<ab,xy>/<xy,ab>这样的对应关系存下来
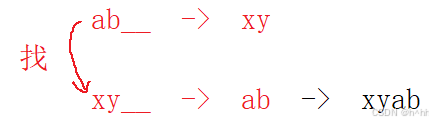
因为它是一个字符串对应另一个字符串的关系,我还要统计这样的对应关系多少个,直接存不太好存,我们可以把对应关系简化一下,针对xy__城市可以把前两个字符给摘出来,和后面州名字拼接起来,xyab,意思就是xy对应ab,此时统计这个字符串出现次数的时候,就特别的好统计,因此待会儿存的时候,不存ab->xy这样的东西,是把ab和xy拼接成一个字符串存起来,往后就很好统计了,直接用哈希表统计xyab字符串出现多少个就可以了,用哈希表统计<拼接后的对应关系,次数>
题目说特殊城市要来自不同的州,如何确定是不同的州
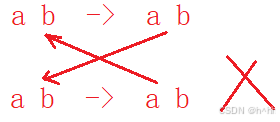
假设我们要找的城市属于同一个州,会有什么问题,两个城市开头两个字母都是ab,对应的州也是ab,根据交叉原则,第二个城市对应的州ab可以转移到第一个城市ab,第一个州的ab是可以转移到第二个城市的ab,也就是说,如果这两个城市属于同一个州,它们前两个字母是和州名字是一样的,此时是不能统计这种情况的,它就不属于特殊的州了,所以一会儿统计到像这样的对应关系的时候,要跳过
另一种思路可以用哈希表嵌套哈希表的形式把对应表关系给存下来,但这样的写法有点不太舒服,所以我们用第一种思路就好了,感兴趣可以往下翻翻看
代码:
#include <iostream>
#include <unordered_map>
using namespace std;int n;int main()
{cin >> n;unordered_map<string, int> mp; // <拼接后的对应关系,次数>int ret = 0;while (n--){string a, b; cin >> a >> b;a = a.substr(0, 2);if (a == b) continue; // 往后查找的时候属于都一个州ret += mp[b + a]; // 统计 b->a 一共有多少个mp[a + b]++; //多了一组a拼接b的形式,在之前的基础上++}cout << ret << endl;return 0;
}代码(嵌套unordered_map):
#include <iostream>
#include <unordered_map>
using namespace std;int n;int main()
{cin >> n;unordered_map<string, unordered_map<string, int>> mp; // <拼接后的对应关系,次数>int ret = 0;while (n--){string a, b; cin >> a >> b;a = a.substr(0, 2);if (a == b) continue; // 往后查找的时候属于都一个州ret += mp[a][b]; // 统计 b->a 一共有多少个mp[b][a]++; //多了一组a拼接b的形式,在之前的基础上++}cout << ret << endl;return 0;
}
代码(pair):
1.为什么需要自定义哈希函数?
在 C++ 中,unordered_map 的键必须满足两个条件:
- 可哈希:必须能通过哈希函数转换为
size_t类型的值。 - 可比较相等:必须支持
operator==比较。
标准库已经为 pair 类型定义了 operator==,但没有提供默认的哈希函数。因此,当你想用 pair<string, string> 作为 unordered_map 的键时,必须手动定义哈希函数
2.用异或算哈希值的缺陷
struct PairHash {size_t operator()(const pair<string, string>& p) const {return hash<string>()(p.first) ^ hash<string>()(p.second);}
};异或的对称性(a ^ b = b ^ a)会导致以下问题
pair<string, string> p1("A", "B");
pair<string, string> p2("B", "A");它们的哈希值将完全相同:
hash(p1.first) ^ hash(p1.second) = hash(p2.first) ^ hash(p2.second)
即使 p1 和 p2 是不同的键,也会被映射到相同的哈希值,导致哈希冲突
方法:位移 + 异或;通过位移破坏对称性,确保顺序不同的键生成不同的哈希值
struct PairHash {size_t operator()(const pair<string, string>& p) const {return (hash<string>()(p.first) << 16) ^ hash<string>()(p.second);}
};- 位移位数需根据哈希值长度调整(例如 64 位系统用
<< 32)
#include <iostream>
#include <unordered_map>
#include <string>
using namespace std;// 定义 pair<string, string> 的哈希函数
//在哈希函数中必须返回 size_t,以满足 unordered_map 或 unordered_set 的接口要求
struct PairHash {size_t operator()(const pair<string, string>& p) const {//先通过`hash<string>()`创建一个临时函数对象,然后通过`(p.first)`来调用这个对象的 //`operator()`方法,从而计算哈希值;果写成`hash<string>(p.first)`,这会被解析为试图用 //`p.first`作为构造函数的参数,但`std::hash`的构造函数并不接受这样的参数 return (hash<string>()(p.first) << 16) ^ hash<string>()(p.second);}
};int main() {int n;cin >> n;unordered_map<pair<string, string>, int, PairHash> mp; // 键为州代码 + 城市代码的组合int ans = 0;for (int i = 0; i < n; ++i) {string city, state;cin >> city >> state;string city_code = city.substr(0, 2);if (state == city_code) continue;// 查找是否存在对应关系 (city_code, state) 的键ans += mp[{city_code, state}];// 将 (state, city_code) 的组合记录到哈希表中mp[{state, city_code}]++;}cout << ans << endl;return 0;
}拓展:
为什么nts1 和 nts2 的哈希比较结果为 false
C++ 标准库为指针类型(如 char*)的哈希函数设计为直接对指针的内存地址进行哈希,而不是对其指向的内容。即使两个指针指向的内容相同(如 "Test"),只要它们的地址不同,哈希值就不同。nts1 和 nts2 是独立的字符数组,虽然内容相同,但内存地址不同。最终结果为 false
C++ 标准库为 std::string 的哈希函数设计为对其字符串内容进行哈希。只要两个字符串内容相同,哈希值一定相同,str1 和 str2 的内容完全相同,最终结果为 true
#include <iostream>
#include <functional>
#include <string>
#include <cstring>
using namespace std;int main() {char nts1[] = "Test";char nts2[] = "Test";std::string str1(nts1);std::string str2(nts2);cout << strcmp(nts1, nts2) << endl;cout << (str1 == str2) << endl;std::hash<char*> ptr_hash;std::hash<std::string> str_hash;// 打印地址std::cout << "nts1 地址: " << (void*)nts1 << std::endl;std::cout << "nts2 地址: " << (void*)nts2 << std::endl;// 打印哈希值std::cout << "nts1 哈希: " << ptr_hash(nts1) << std::endl;std::cout << "nts2 哈希: " << ptr_hash(nts2) << std::endl;std::cout << "str1 哈希: " << str_hash(str1) << std::endl;std::cout << "str2 哈希: " << str_hash(str2) << std::endl;return 0;
}//0
//1
//nts1 地址 : 006AF950
//nts2 地址 : 006AF940
//nts1 哈希 : 1115828456
//nts2 哈希 : 3594615800
//str1 哈希 : 805092869
//str2 哈希 : 805092869




