Inflated 3D Convolution-Transformer for Weakly-Supervised Carotid Stenosis Grading with Ultrasound Videos
摘要
在临床实践中,在颈动脉超声 (US) 中定位血管最窄位置并进行相应的血管和残余血管描绘对于颈动脉狭窄分级 (CSG) 至关重要。然而,由于斑块和时间变化的模糊边界,既费时又艰难。要使此过程自动化,通常需要大量的手动划定,这不仅费力,而且考虑到注释的难度,也不可靠。
本文提出了第一个自动CSG的视频分类框架。提出了一种针对弱监督CSG的新颖有效的视频分类网络。
其次,对网络采用了膨胀策略,其中预训练的 2D 卷积权重可以适应我们网络中的 3D 对应物,以实现有效的热启动。
第三,为了增强视频的特征辨别能力,提出了一种新型的注意力引导多维融合(AMDF)转换器编码器,用于在空间和时间维度内和跨空间维度的全局依赖性进行建模和集成,其中设计了两种轻量级的跨维度注意力机制。
本文方法
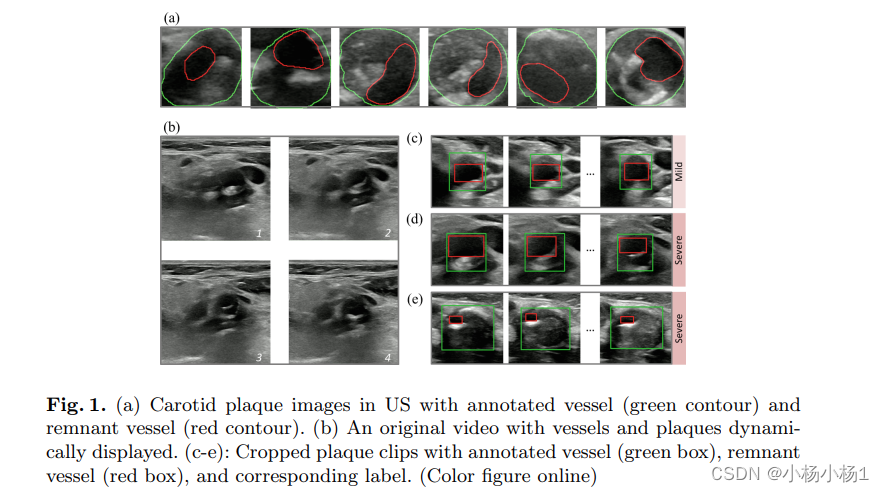
图 1.(a) 颈动脉斑块图像,带有注释的血管(绿色轮廓)和残余血管(红色轮廓)。
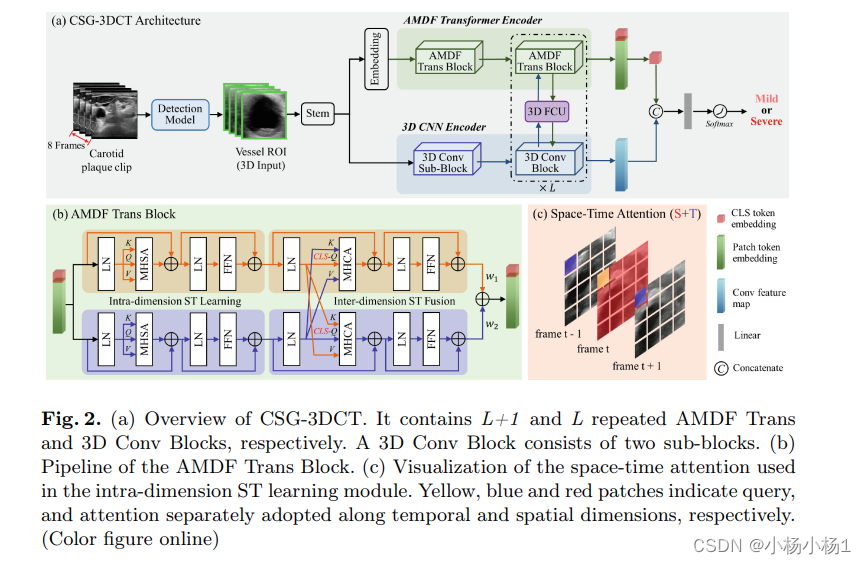
图 2.(a) CSG-3DCT概述。它分别包含 L+1 和 L 重复的 AMDF 反式和 3D 转换块。3D ConvBlock 由两个子模块组成。(b) AMDF Trans Block的管道。(c) 内部维度ST学习模块中使用的时空注意力的可视化。黄色、蓝色和红色斑块分别表示查询和注意力,分别沿时间和空间维度采用。
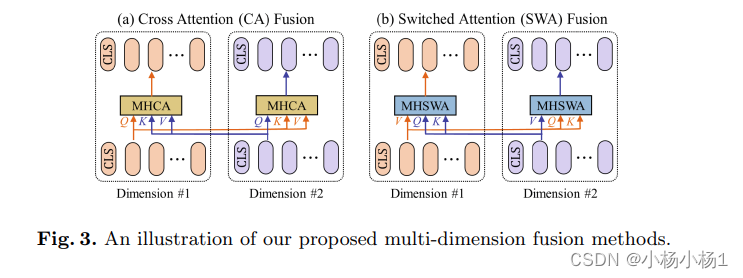
AMDF模块采用交叉注意力,下图是两张交叉注意力模块
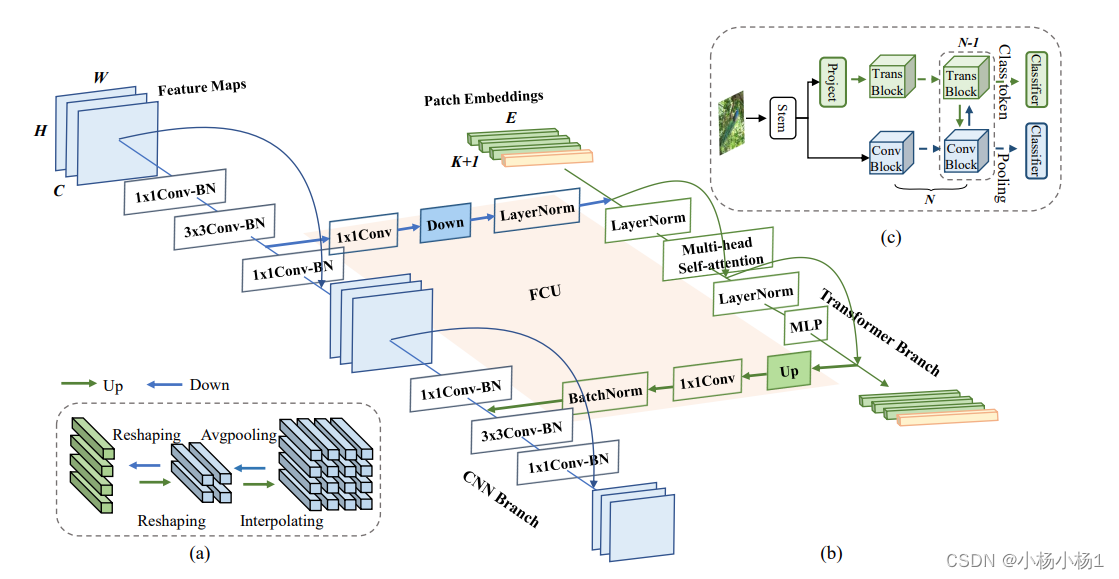
FCU来自于下面这篇文章
文章链接
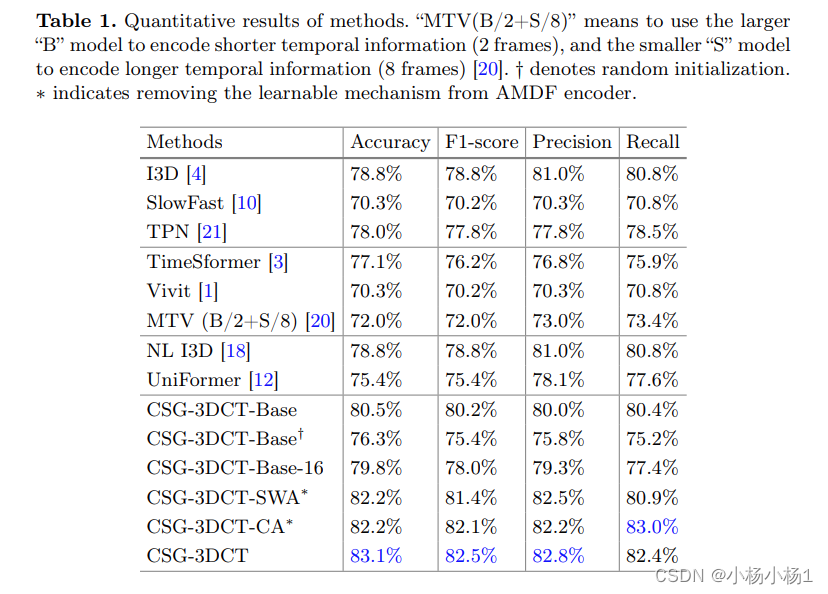
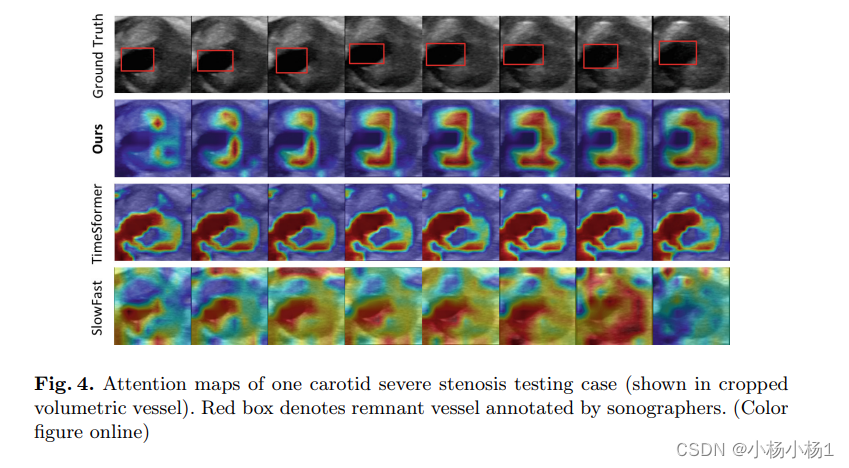
实验结果