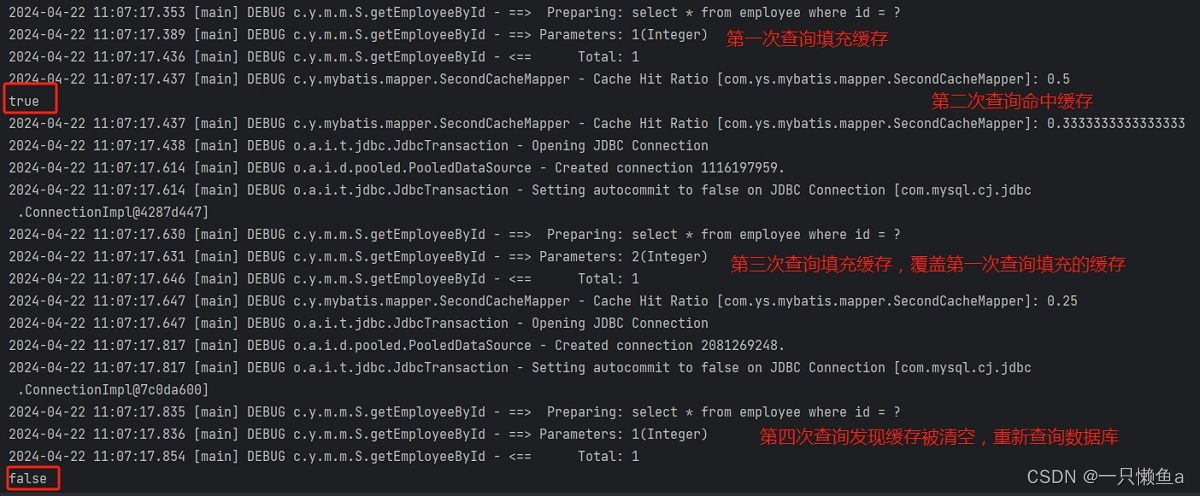
序言
简单回顾一下。上一篇文章介绍了从xml文件context component-scan标签的加载流程到ConfigurationClassPostProcessor的创建流程。
本篇会深入了解context component-scan标签底层做了些什么。
component-scan
早期使用Spring进行开发时,很多时候都是注解 + 标签的形式来进行类的配置。而在之前文章中有介绍过xml在加载解析时,会对 各种标签进行解析。那注解修饰的类是什么时候被Spring识别的呢?
就是在component-scan标签解析时,获取对应base-package所对应的包下所有符合条件的类,从而进行处理。
流程图

parse - 主流程
接下来从parse() 主流程开始,看看每一步都有哪些细节。
java">@Override@Nullablepublic BeanDefinition parse(Element element, ParserContext parserContext) {//获取base-package属性值String basePackage = element.getAttribute(BASE_PACKAGE_ATTRIBUTE);//解析占位符basePackage = parserContext.getReaderContext().getEnvironment().resolvePlaceholders(basePackage);//解析base-package属性值进行拆分,返回数组String[] basePackages = StringUtils.tokenizeToStringArray(basePackage,ConfigurableApplicationContext.CONFIG_LOCATION_DELIMITERS);// Actually scan for bean definitions and register them.// 创建和配置ClassPathBeanDefinitionScanner对象ClassPathBeanDefinitionScanner scanner = configureScanner(parserContext, element);//执行扫描,返回bean定义集合并注册到BeanFactorySet<BeanDefinitionHolder> beanDefinitions = scanner.doScan(basePackages);//注册组件(包括注册一些内部的注解后置处理器(ConfigurationClassPostProcessor.class)等 触发注册事件registerComponents(parserContext.getReaderContext(), beanDefinitions, element);return null;}
configureScanner解析标签属性
方法主要是看context:component-scan标签中是否包含scope-resolver、resource-pattern、use-default-filters等属性值,并创建scanner对象进行封装。
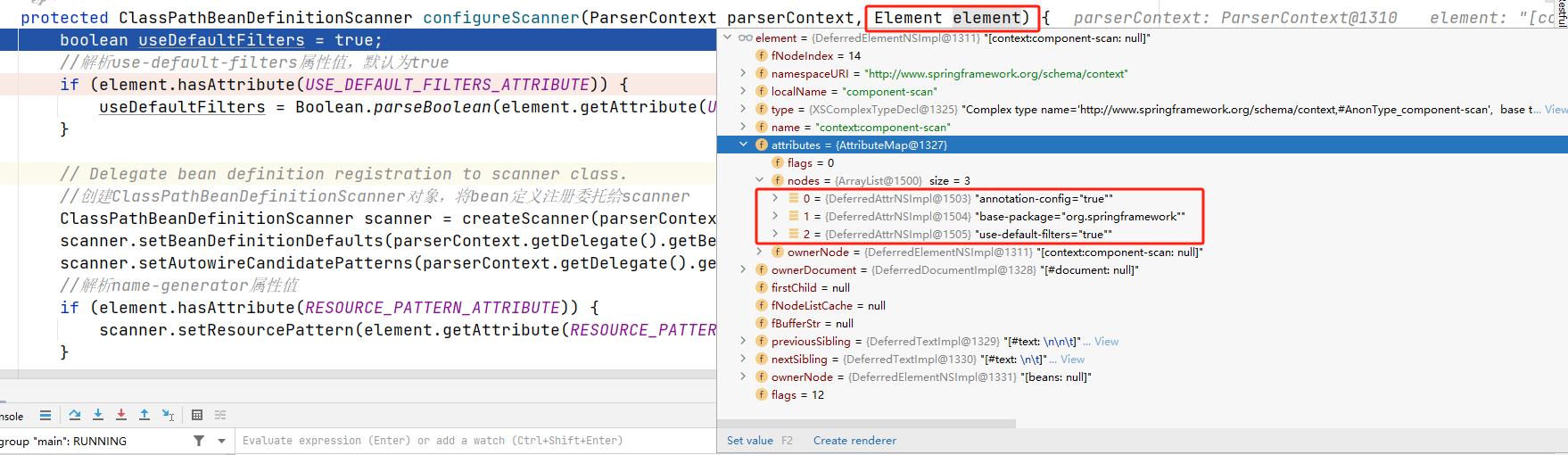
java">protected ClassPathBeanDefinitionScanner configureScanner(ParserContext parserContext, Element element) {//去除部分无用代码....boolean useDefaultFilters = true;//解析use-default-filters属性值,默认为trueif (element.hasAttribute(USE_DEFAULT_FILTERS_ATTRIBUTE)) {useDefaultFilters = Boolean.parseBoolean(element.getAttribute(USE_DEFAULT_FILTERS_ATTRIBUTE));}// Delegate bean definition registration to scanner class.//创建ClassPathBeanDefinitionScanner对象,将bean定义注册委托给scannerClassPathBeanDefinitionScanner scanner = createScanner(parserContext.getReaderContext(), useDefaultFilters);scanner.setBeanDefinitionDefaults(parserContext.getDelegate().getBeanDefinitionDefaults());scanner.setAutowireCandidatePatterns(parserContext.getDelegate().getAutowireCandidatePatterns());//解析name-generator属性值if (element.hasAttribute(RESOURCE_PATTERN_ATTRIBUTE)) {scanner.setResourcePattern(element.getAttribute(RESOURCE_PATTERN_ATTRIBUTE));}//如果包含name-generator属性值,则按照Spring规则生成beanName.parseBeanNameGenerator(element, scanner);//解析scope-resolver属性值parseScope(element, scanner);}//解析include-filter和exclude-filter子标签属性。parseTypeFilters(element, scanner, parserContext);return scanner;}
parseTypeFilters解析子标签
值得注意的和扩展的是parseTypeFilters方法。方法中会对 context:exclude-filter 子标签和 context:exclude-filter 子标签进行处理。
type类型:
assignable-指定扫描某个接口派生出来的类annotation-指定扫描使用某个注解的类aspectj-指定扫描AspectJ表达式相匹配的类custom-指定扫描自定义的实现了org.springframework.core.type.filter.TypeFilter接口的类 regex-指定扫描符合正则表达式的类
context:exclude-filter
标签的作用是:在base-package扫描时,让指定的类不被Spring管理。
例子中代表标记了Controller注解的类不被Spring识别管理
<!--举个栗子 -->
<context:component-scan base-package="com.example"><context:exclude-filter type="annotation" expression="org.springframework.stereotype.Controller"/>
</context:component-scan>
context:include-filter
标签的作用是:在base-package扫描时,额外扫描指定的类被Spring管理
例子中User类虽然没有注解修饰,但也会被加载。
<!--举个栗子 -->
<context:component-scan base-package="com.example"><context:include-filter type="assignable" expression="org.springframework.User"/>
</context:component-scan>
额外加载User类。
java">package org.springframework;public class User {}
方法会遍历context:componet-scan标签下的include和exclude子标签,并加到scanner的属性中。
java">protected void parseTypeFilters(Element element, ClassPathBeanDefinitionScanner scanner, ParserContext parserContext) {// Parse exclude and include filter elements.ClassLoader classLoader = scanner.getResourceLoader().getClassLoader();NodeList nodeList = element.getChildNodes();for (int i = 0; i < nodeList.getLength(); i++) {Node node = nodeList.item(i);if (node.getNodeType() == Node.ELEMENT_NODE) {String localName = parserContext.getDelegate().getLocalName(node);if (INCLUDE_FILTER_ELEMENT.equals(localName)) {TypeFilter typeFilter = createTypeFilter((Element) node, classLoader, parserContext);scanner.addIncludeFilter(typeFilter);}else if (EXCLUDE_FILTER_ELEMENT.equals(localName)) {TypeFilter typeFilter = createTypeFilter((Element) node, classLoader, parserContext);scanner.addExcludeFilter(typeFilter);} }}}
其中,Scanner对象在创建时,构造方法中会对IncludeFilter进行初始化赋值操作。
划重点!!!!!!!!!!!!后面includeFilters有用到。在这也可以看出,为什么只会识别@Component注解和@Configuration
java"> protected ClassPathBeanDefinitionScanner createScanner(XmlReaderContext readerContext, boolean useDefaultFilters) {return new ClassPathBeanDefinitionScanner(readerContext.getRegistry(), useDefaultFilters,readerContext.getEnvironment(), readerContext.getResourceLoader());}public ClassPathBeanDefinitionScanner(BeanDefinitionRegistry registry, boolean useDefaultFilters,Environment environment, @Nullable ResourceLoader resourceLoader) {//删除无用代码if (useDefaultFilters) {registerDefaultFilters();}}protected void registerDefaultFilters() {//删掉无用代码this.includeFilters.add(new AnnotationTypeFilter(Component.class));}
@Configuration
Configaration注解上也被@Component修饰,所以也可以被识别到。
java">@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Component
public @interface Configuration {
}
doScan-扫描package下所有class文件
方法主要是获取到base-package包下所有类,并遍历看是否符合条件让Spring进行管理。其中findCandidateComponents会对类进行筛选。
java">protected Set<BeanDefinitionHolder> doScan(String... basePackages) {Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();//遍历basePackagefor (String basePackage : basePackages) {//获取basePackage下所有符合要求的BeanSet<BeanDefinition> candidates = findCandidateComponents(basePackage);for (BeanDefinition candidate : candidates) {//解析@Scope注解ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);candidate.setScope(scopeMetadata.getScopeName());//用生成器生成beanNameString beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);if (candidate instanceof AbstractBeanDefinition) {postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);}if (candidate instanceof AnnotatedBeanDefinition) {// 处理定义在目标类上的通用注解,包括@Lazy,@Primary,@DependsOn,@Role,@DescriptionAnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);}//再次检查beanName是否注册过,如果注册过,检查是否兼容if (checkCandidate(beanName, candidate)) {//将beanName和beanDefinition封装到BeanDefinitionHolderBeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);definitionHolder =AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);beanDefinitions.add(definitionHolder);//注册BeanDefinitionregisterBeanDefinition(definitionHolder, this.registry);}}}return beanDefinitions;}
findCandidateComponents - 筛选符合条件的类
代码会走scanCandidateComponents方法逻辑。
java">public Set<BeanDefinition> findCandidateComponents(String basePackage) {if (this.componentsIndex != null && indexSupportsIncludeFilters()) {return addCandidateComponentsFromIndex(this.componentsIndex, basePackage);}else {return scanCandidateComponents(basePackage);}}
scanCandidateComponents
获取package下所有class文件,并转换成Resource -> MetadataReader读取数据进行判断。
如果满足isCandidateComponent方法的逻辑,则创建ScannedGenericBeanDefinition对象封装Bean信息。
java">private Set<BeanDefinition> scanCandidateComponents(String basePackage) {//删除无用代码。。。。Set<BeanDefinition> candidates = new LinkedHashSet<>();try {//packageSearchPath: "classpath*:com/example/*/**.class"String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +resolveBasePackage(basePackage) + '/' + this.resourcePattern;Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);for (Resource resource : resources) {if (resource.isReadable()) {try {MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);//判断该类是否允许被Spring识别if (isCandidateComponent(metadataReader)) {//创建BeanDefinition封装Bean信息ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);sbd.setSource(resource);if (isCandidateComponent(sbd)) {candidates.add(sbd);}}}}}}return candidates;}
isCandidateComponent
根据配置 context:include-filter 和 context:exclude-filter 规则进行过滤,如果都没有配置,则此时 includeFilters 属性中有默认值 @Component ,所以此处只会保留包含 @Component注解的类。
java">protected boolean isCandidateComponent(MetadataReader metadataReader) throws IOException {for (TypeFilter tf : this.excludeFilters) {if (tf.match(metadataReader, getMetadataReaderFactory())) {return false;}}for (TypeFilter tf : this.includeFilters) {if (tf.match(metadataReader, getMetadataReaderFactory())) {return isConditionMatch(metadataReader);}}return false;}
isConditionMatch
创建ConditionEvaluator对象,并在shouldSkip()方法中判断类是否含有 @Conditional注解,是否符合@Conditional中的类加载条件。
java">private boolean isConditionMatch(MetadataReader metadataReader) {if (this.conditionEvaluator == null) {this.conditionEvaluator =new ConditionEvaluator(getRegistry(), this.environment, this.resourcePatternResolver);}return !this.conditionEvaluator.shouldSkip(metadataReader.getAnnotationMetadata());}
如果类中没有@Conditional注解,则直接返回,否则获取Conditional注解中value属性值并进行加载。递归调用,看是否符合家在条件。
java">public boolean shouldSkip(@Nullable AnnotatedTypeMetadata metadata, @Nullable ConfigurationPhase phase) {//如果metadata为空或者没有@Conditional注解,直接返回falseif (metadata == null || !metadata.isAnnotated(Conditional.class.getName())) {return false;}//第一次进来时phase为null,所以一定会走下面方法//判断是否是@Configuration注解,如果是,则进入shouldSkip(metadata, ConfigurationPhase.PARSE_CONFIGURATION)if (phase == null) {if (metadata instanceof AnnotationMetadata &&//判断是否是抽象类 return false//判断是否被Component、ComponentScan、Import、ImportResource注解修饰 return true//判断是否被Bean修饰 return trueConfigurationClassUtils.isConfigurationCandidate((AnnotationMetadata) metadata)) {//递归调用shouldSkip(metadata, ConfigurationPhase.PARSE_CONFIGURATION)return shouldSkip(metadata, ConfigurationPhase.PARSE_CONFIGURATION);}return shouldSkip(metadata, ConfigurationPhase.REGISTER_BEAN);}List<Condition> conditions = new ArrayList<>();//获取@Conditional注解的value属性for (String[] conditionClasses : getConditionClasses(metadata)) {for (String conditionClass : conditionClasses) {//创建value属性所对应的Condition类Condition condition = getCondition(conditionClass, this.context.getClassLoader());conditions.add(condition);}}//对conditions进行排序AnnotationAwareOrderComparator.sort(conditions);for (Condition condition : conditions) {ConfigurationPhase requiredPhase = null;if (condition instanceof ConfigurationCondition) {requiredPhase = ((ConfigurationCondition) condition).getConfigurationPhase();}//此逻辑为:1.requiredPhase不是ConfigurationCondition的实例//2.phase==requiredPhase,从上述的递归可知:phase可为ConfigurationPhase.PARSE_CONFIGURATION或者ConfigurationPhase.REGISTER_BEAN//3.condition.matches(this.context, metadata)返回false//如果1、2或者1、3成立,则在此函数的上层将阻断bean注入Spring容器if ((requiredPhase == null || requiredPhase == phase) && !condition.matches(this.context, metadata)) {return true;}}return false;}
registerComponents 注册组件 (ConfigurationClassPostProcessor.class等)
将doScan过滤出来的beanDefinition添加到compositeDef的nestedComponents属性中。
获取annotation-config属性值(默认为true),并调用registerAnnotationConfigProcessors方法进行注册。
java">protected void registerComponents(XmlReaderContext readerContext, Set<BeanDefinitionHolder> beanDefinitions, Element element) {Object source = readerContext.extractSource(element);//根据tagName(此处为context:component-scan)和source创建CompositeComponentDefinition对象CompositeComponentDefinition compositeDef = new CompositeComponentDefinition(element.getTagName(), source);// 将扫描到的所有beanDefinition添加到compositeDef的nestedComponents属性中for (BeanDefinitionHolder beanDefHolder : beanDefinitions) {compositeDef.addNestedComponent(new BeanComponentDefinition(beanDefHolder));}// Register annotation config processors, if necessary.boolean annotationConfig = true;if (element.hasAttribute(ANNOTATION_CONFIG_ATTRIBUTE)) {//获取component-scan标签的annotation-config属性值annotationConfig = Boolean.parseBoolean(element.getAttribute(ANNOTATION_CONFIG_ATTRIBUTE));}//annotationConfig默认为true.if (annotationConfig) {//注册注解配置处理器Set<BeanDefinitionHolder> processorDefinitions =AnnotationConfigUtils.registerAnnotationConfigProcessors(readerContext.getRegistry(), source);for (BeanDefinitionHolder processorDefinition : processorDefinitions) {// 将注册的注解后置处理器的BeanDefinition添加到compositeDef的nestedComponents属性中compositeDef.addNestedComponent(new BeanComponentDefinition(processorDefinition));}}readerContext.fireComponentRegistered(compositeDef);}
registerAnnotationConfigProcessors
此时,又回到了我们上一篇文章所讲的 ConfigurationClassPostProcessor类的由来。就是在此处进行的加载。
java">public static final String CONFIGURATION_ANNOTATION_PROCESSOR_BEAN_NAME ="org.springframework.context.annotation.internalConfigurationAnnotationProcessor";判断当前BeanFacroty中是否包含internalConfigurationAnnotationProcessor,如果不包含,则创建ConfigurationClassPostProcessor.class
java">public static Set<BeanDefinitionHolder> registerAnnotationConfigProcessors(BeanDefinitionRegistry registry, @Nullable Object source) {//获取beanFactoryDefaultListableBeanFactory beanFactory = unwrapDefaultListableBeanFactory(registry);if (beanFactory != null) {if (!(beanFactory.getDependencyComparator() instanceof AnnotationAwareOrderComparator)) {//设置依赖比较器beanFactory.setDependencyComparator(AnnotationAwareOrderComparator.INSTANCE);}if (!(beanFactory.getAutowireCandidateResolver() instanceof ContextAnnotationAutowireCandidateResolver)) {//设置自动装配解析器beanFactory.setAutowireCandidateResolver(new ContextAnnotationAutowireCandidateResolver());}}//创建BeanDefinitionHolder集合Set<BeanDefinitionHolder> beanDefs = new LinkedHashSet<>(8);// 注册内部管理的用于处理@configuration注解的后置处理器的beanif (!registry.containsBeanDefinition(CONFIGURATION_ANNOTATION_PROCESSOR_BEAN_NAME)) {RootBeanDefinition def = new RootBeanDefinition(ConfigurationClassPostProcessor.class);def.setSource(source);beanDefs.add(registerPostProcessor(registry, def, CONFIGURATION_ANNOTATION_PROCESSOR_BEAN_NAME));}// 注册内部管理的用于处理@Autowired,@Value,@Inject以及@Lookup注解的后置处理器beanif (!registry.containsBeanDefinition(AUTOWIRED_ANNOTATION_PROCESSOR_BEAN_NAME)) {RootBeanDefinition def = new RootBeanDefinition(AutowiredAnnotationBeanPostProcessor.class);def.setSource(source);beanDefs.add(registerPostProcessor(registry, def, AUTOWIRED_ANNOTATION_PROCESSOR_BEAN_NAME));}// Check for JSR-250 support, and if present add the CommonAnnotationBeanPostProcessor.// 注册内部管理的用于处理JSR-250注解,例如@Resource,@PostConstruct,@PreDestroy的后置处理器beanif (jsr250Present && !registry.containsBeanDefinition(COMMON_ANNOTATION_PROCESSOR_BEAN_NAME)) {RootBeanDefinition def = new RootBeanDefinition(CommonAnnotationBeanPostProcessor.class);def.setSource(source);beanDefs.add(registerPostProcessor(registry, def, COMMON_ANNOTATION_PROCESSOR_BEAN_NAME));}// Check for JPA support, and if present add the PersistenceAnnotationBeanPostProcessor.if (jpaPresent && !registry.containsBeanDefinition(PERSISTENCE_ANNOTATION_PROCESSOR_BEAN_NAME)) {RootBeanDefinition def = new RootBeanDefinition();try {def.setBeanClass(ClassUtils.forName(PERSISTENCE_ANNOTATION_PROCESSOR_CLASS_NAME,AnnotationConfigUtils.class.getClassLoader()));}catch (ClassNotFoundException ex) {throw new IllegalStateException("Cannot load optional framework class: " + PERSISTENCE_ANNOTATION_PROCESSOR_CLASS_NAME, ex);}def.setSource(source);beanDefs.add(registerPostProcessor(registry, def, PERSISTENCE_ANNOTATION_PROCESSOR_BEAN_NAME));}// 注册内部管理的用于处理@EventListener注解的后置处理器的beanif (!registry.containsBeanDefinition(EVENT_LISTENER_PROCESSOR_BEAN_NAME)) {RootBeanDefinition def = new RootBeanDefinition(EventListenerMethodProcessor.class);def.setSource(source);beanDefs.add(registerPostProcessor(registry, def, EVENT_LISTENER_PROCESSOR_BEAN_NAME));}// 注册内部管理用于生产ApplicationListener对象的EventListenerFactory对象if (!registry.containsBeanDefinition(EVENT_LISTENER_FACTORY_BEAN_NAME)) {RootBeanDefinition def = new RootBeanDefinition(DefaultEventListenerFactory.class);def.setSource(source);beanDefs.add(registerPostProcessor(registry, def, EVENT_LISTENER_FACTORY_BEAN_NAME));}return beanDefs;}
下一篇文章详细看看 ConfigurationClassPostProcessor 类的 postProcessBeanDefinitionRegistry()方法做了什么。