GaussianCube: Structuring Gaussian Splatting using Optimal Transport for 3D Generative Modeling
GaussianCube:使用最优传输构造高斯溅射用于3D生成建模
张博文 1* 程一季 2* 杨娇龙 3 王春雨 3
Feng Zhao1 Yansong Tang2 Dong Chen3 Baining Guo3
赵峰 1 唐岩松 2 陈冬 3 郭柏宁 3
1University of Science and Technology of China 2Tsinghua University 3Microsoft Research Asia
中国科学技术大学 2 清华大学 3 微软亚洲研究院
Abstract 摘要 GaussianCube: Structuring Gaussian Splatting using Optimal Transport for 3D Generative Modeling
3D Gaussian Splatting (GS) have achieved considerable improvement over Neural Radiance Fields in terms of 3D fitting fidelity and rendering speed. However, this unstructured representation with scattered Gaussians poses a significant challenge for generative modeling. To address the problem, we introduce GaussianCube, a structured GS representation that is both powerful and efficient for generative modeling. We achieve this by first proposing a modified densification-constrained GS fitting algorithm which can yield high-quality fitting results using a fixed number of free Gaussians, and then re-arranging the Gaussians into a predefined voxel grid via Optimal Transport. The structured grid representation allows us to use standard 3D U-Net as our backbone in diffusion generative modeling without elaborate designs. Extensive experiments conducted on ShapeNet and OmniObject3D show that our model achieves state-of-the-art generation results both qualitatively and quantitatively, underscoring the potential of GaussianCube as a powerful and versatile 3D representation. Project page: GaussianCube: Structuring Gaussian Splatting using Optimal Transport for 3D Generative Modeling.
3D高斯溅射(GS)在3D拟合保真度和渲染速度方面比神经辐射场有了相当大的改进。然而,这种具有分散高斯的非结构化表示对生成建模提出了重大挑战。为了解决这个问题,我们引入了GaussianCube,这是一种结构化的GS表示,对于生成式建模来说,它既强大又高效。我们首先提出了一种改进的密度约束GS拟合算法,该算法可以使用固定数量的自由高斯来产生高质量的拟合结果,然后通过最优传输将高斯重新排列到预定义的体素网格中。结构化的网格表示使我们能够使用标准的3D U-Net作为扩散生成建模的骨干,而无需精心设计。 在ShapeNet和OmniObject3D上进行的大量实验表明,我们的模型在定性和定量方面都达到了最先进的生成结果,强调了GaussianCube作为功能强大且通用的3D表示的潜力。项目页面:www.example.com。
1Interns at Microsoft Research Asia.
微软亚洲研究院(Microsoft Research Asia)
1Introduction 一、导言
Recent advancements in generative modeling Ho et al. (2020); Goodfellow et al. (2020); Nichol and Dhariwal (2021); Dhariwal and Nichol (2021); Zhang et al. (2022); Karras et al. (2019) have led to significant progress in 3D content creation Wang et al. (2023); Müller et al. (2023); Cao et al. (2023); Tang et al. (2023c); Shue et al. (2023); Chan et al. (2022); Gao et al. (2022). Most of the prior works in this domain leverage variants of Neural Radiance Field (NeRF) Mildenhall et al. (2021) as their underlying 3D representations Chan et al. (2022); Tang et al. (2023c), which typically consist of an explicit and structured proxy representation and an implicit feature decoder. However, such hybrid NeRF variants have degraded representation power, particularly when used for generative modeling where a single implicit feature decoder is shared across all objects. Furthermore, the high computational complexity of volumetric rendering leads to both slow rendering speed and extensive memory costs. Recently, the emergence of 3D Gaussian Splatting (GS) Kerbl et al. (2023) has enabled high-quality reconstruction Xu et al. (2023); Luiten et al. (2023); Wu et al. (2023a) along with real-time rendering speed. The fully explicit characteristic of 3DGS also eliminates the need for a shared implicit decoder. Although 3DGS has been widely studied in scene reconstruction tasks, its spatially unstructured nature presents significant challenge when applying it to generative modeling.
生成建模的最新进展Ho et al.(2020); Goodfellow et al.(2020); Nichol和达里瓦尔(2021);达里瓦尔和Nichol(2021); Zhang et al.(2022); Karras et al.(2019)导致了3D内容创建的重大进展Wang et al.(2023); Müller et al.(2023); Cao等人(2023); Tang等人(2023 c); Shue等人(2023); Chan等人(2022); Gao等人(2022)。该领域的大多数先前工作都利用神经辐射场(NeRF)的变体Mildenhall et al.(2021)作为其基础3D表示Chan et al.(2022); Tang et al.(2023 c),其通常由显式和结构化代理表示和隐式特征解码器组成。然而,这种混合NeRF变体具有降级的表示能力,特别是当用于生成建模时,其中单个隐式特征解码器在所有对象之间共享。 此外,体绘制的高计算复杂度导致绘制速度慢和大量的存储器成本。最近,3D高斯溅射(GS)Kerbl et al.(2023)的出现使得高质量重建成为可能Xu et al.(2023); Luiten et al.(2023); Wu et al.(2023 a)沿着的实时渲染速度。3DGS的完全显式特性还消除了对共享隐式解码器的需要。虽然3DGS在场景重建任务中得到了广泛的研究,但其空间非结构化的性质在将其应用于生成式建模时提出了重大挑战。
In this work, we introduce GaussianCube, a novel representation crafted to address the unstructured nature of 3DGS and unleash its potential for 3D generative modeling (see Table 1 for comparisons with prior works). Converting 3D Gaussians into a structured format without sacrificing their expressiveness is not a trivial task. We propose to first perform high-quality fitting using a fixed number of Gaussians and then organize them in a spatially structured manner. To keep the number of Gaussians fixed during fitting, a naive solution might omit the densification and pruning steps in GS, which, however, would significantly degrade the fitting quality. In contrast, we propose a densification-constrained fitting strategy, which retains the original pruning process yet constrains the number of Gaussians that perform densification, ensuring the total does not exceed a predefined maximum �3 (32,768 in this paper). For the subsequent structuralization, we allocate the Gaussians across an ��� voxel grid using Optimal Transport (OT). Consequently, our fitted Gaussians are systematically arranged within the voxel grid, with each grid containing a Gaussian feature. The proposed OT-based structuralization process achieves maximal spatial coherence, characterized by minimal total transport distances, while preserving the high expressiveness of the 3DGS.
在这项工作中,我们介绍了GaussianCube,这是一种新颖的表示方法,旨在解决3DGS的非结构化性质,并释放其在3D生成建模方面的潜力(与先前工作的比较见表1)。将3D高斯转换为结构化格式而不牺牲其表现力并不是一项微不足道的任务。我们建议首先使用固定数量的高斯函数进行高质量的拟合,然后以空间结构化的方式组织它们。为了在拟合期间保持高斯数固定,朴素的解决方案可能会省略GS中的致密化和修剪步骤,然而,这会显著降低拟合质量。相比之下,我们提出了一种密度约束拟合策略,它保留了原始的修剪过程,但限制了执行密度化的高斯函数的数量,确保总数不超过预定义的最大值 �3 (本文中为32,768)。 对于随后的结构化,我们使用最优传输(OT)将高斯分布在 �×�×� 体素网格上。因此,我们拟合的高斯分布被系统地排列在体素网格内,每个网格都包含高斯特征。提出的基于OT的结构化过程实现了最大的空间一致性,其特征在于最小的总传输距离,同时保持了3DGS的高表现力。
| Representation | Spatially-structured 空间结构 | Fully-explicit 全显式 | High-quality Reconstruction 高质量重建 | Efficient Rendering 高效渲染 |
|---|---|---|---|---|
| Vanilla NeRF Mildenhall et al. (2021) Vanilla NeRF Mildenhall等人2021 | ✗ | ✗ | ✗ | ✗ |
| Neural Voxels Tang et al. (2023c) 神经体素Tang等人2023c | ✓ | ✗ | ✗ | ✗ |
| Triplane Chan et al. (2022) Triplane Chan等人2022 | ✓ | ✗ | ✗ | ✗ |
| Gaussian Splatting Kerbl et al. (2023) 高斯飞溅Kerbl等人2023 | ✗ | ✓ | ✓ | ✓ |
| Our GaussianCube 我们的高斯魔方 | ✓ | ✓ | ✓ | ✓ |
Table 1:Comparison with prior 3D representations.
表1:与先前3D表示的比较。
We perform 3D generative modeling with the proposed GaussianCube using diffusion models Ho et al. (2020). The spatially coherent structure of the Gaussians in our representation facilitates efficient feature extraction and permits the use of standard 3D convolutions to capture the correlations among neighboring Gaussians effectively. Therefore, we construct our diffusion model with standard 3D U-Net architecture without elaborate designs. It is worth noting that our diffusion model and the GaussianCube representation are generic, which facilitates both unconditional and conditional generation tasks.
我们使用扩散模型Ho et al.(2020)使用提出的GaussianCube执行3D生成建模。在我们的表示中,高斯的空间相干结构有助于有效的特征提取,并允许使用标准的3D卷积来有效地捕获相邻高斯之间的相关性。因此,我们使用标准的3D U—Net架构构建我们的扩散模型,而无需进行精心设计。值得注意的是,我们的扩散模型和GaussianCube表示是通用的,这有利于无条件和有条件的生成任务。
We conduct comprehensive experiments to verify the efficacy of our proposed approach. The model’s capability for unconditional generation is evaluated on the ShapeNet dataset Chang et al. (2015). Both the quantitative and qualitative comparisons indicate that our model surpasses all previous methods. Additionally, we perform class-conditioned generation on the OmniObject3D dataset Wu et al. (2023b), which is a extensive collection of real-world scanned objects with a broad vocabulary. Our model excels in producing semantically accurate 3D objects with complex geometries and realistic textures, outperforming the state-of-the-art methods. These experiments collectively demonstrate the strong capabilities of our GaussianCube and suggest its potential as a powerful and versatile 3D representation for a variety of applications. Some generated samples of our method is presented in Figure 1.
我们进行了全面的实验,以验证我们所提出的方法的有效性。该模型的无条件生成能力在ShapeNet数据集Chang et al.(2015)上进行了评估。定量和定性的比较表明,我们的模型优于所有以前的方法。此外,我们对OmniObject3D数据集Wu等人(2023 b)执行类条件生成,该数据集是具有广泛词汇的真实世界扫描对象的广泛集合。我们的模型在生成具有复杂几何形状和逼真纹理的语义准确的3D对象方面表现出色,优于最先进的方法。这些实验共同证明了我们的GaussianCube的强大功能,并表明其作为各种应用程序的强大和通用的3D表示的潜力。我们的方法生成的一些示例如图1所示。
|
|
|
|
|
|
 3d93c.jpeg" width="1200" />
3d93c.jpeg" width="1200" />
 3dabbe2e7b14.jpeg" width="1200" />
3dabbe2e7b14.jpeg" width="1200" />Figure 1:Samples of our generated 3D objects. Our model is able to create diverse objects with complex geometry and rich texture details.
图1:我们生成的3D对象的示例。我们的模型能够创建具有复杂几何形状和丰富纹理细节的各种对象。
2Related Work 2相关工作
Radiance field representation. Radiance fields model ray interactions with scene surfaces and can be in either implicit or explicit forms. Early works of neural radiance fields (NeRFs) Mildenhall et al. (2021); Zhang et al. (2020); Park et al. (2021); Barron et al. (2022); Pumarola et al. (2021) are often in an implicit form, which represents scenes without defining geometry. These works optimize a continuous scene representation using volumetric ray-marching that leads to extremely high computational costs. Recent works introduce the use of explicit proxy representation followed by an implicit feature decoder to enable faster rendering. The explicit proxy representations directly represent continuous neural features in a discrete data structure, such as triplane Chan et al. (2022); Hu et al. (2023), voxel grid Fridovich-Keil et al. (2022); Sun et al. (2022), hash table Müller et al. (2022), or point sets Xu et al. (2022b). Recently, the 3D Gaussian Splatting methods Kerbl et al. (2023); Xu et al. (2023); Wu et al. (2023a); Cotton and Peyton (2024); Li et al. (2024) utilize 3D Gaussians as their underlying representation and adaptively densify and prune them during fitting, which offers impressive reconstruction quality. The fully explicit representation also provides real-time rendering speed. However, the 3D Gaussians are unstructured representation, and require per-scene optimization to achieve photo-realistic quality. In contrast, our work proposes a structured representation termed GaussianCube for 3D generative tasks.
辐射场表示法。辐射场对光线与场景曲面的交互进行建模,可以采用隐式或显式形式。神经辐射场(NeRFs)的早期工作Mildenhall et al.(2021);Zhang et al.(2020);Park et al.(2021);巴伦et al.(2022);Pumarola et al.(2021)通常采用隐式形式,表示没有定义几何的场景。这些作品优化了连续的场景表示,使用体积射线行进,导致极高的计算成本。最近的作品介绍了使用显式的代理表示,其次是一个隐式的功能解码器,使更快的渲染。显式代理表示直接表示离散数据结构中的连续神经特征,例如三平面Chan等人(2022);Hu等人(2023),体素网格Fridovich—Keil等人(2022);Sun等人(2022),哈希表Müller等人(2022)或点集Xu等人(2022 b)。 最近,3D高斯溅射方法Kerbl等人(2023); Xu等人(2023); Wu等人(2023 a); Cotton和佩顿(2024); Li等人(2024)利用3D高斯作为其底层表示,并在拟合期间自适应地加密和修剪它们,这提供了令人印象深刻的重建质量。完全显式表示还提供实时渲染速度。然而,3D高斯是非结构化的表示,并且需要每个场景优化以实现照片般逼真的质量。相比之下,我们的工作提出了一个结构化的表示称为GaussianCube的3D生成任务。
Image-based 3D reconstruction. Compared to per-scene optimization, image-based 3D reconstruction methods Tatarchenko et al. (2019); Li et al. (2009); Tulsiani et al. (2017); Yu et al. (2021) can directly reconstruct 3D assets given images without optimization. PixelNeRF Yu et al. (2021) leverages an image feature encoder to empower the generalizability of NeRF. Similarly, pixel-aligned Gaussian approaches Charatan et al. (2023); Szymanowicz et al. (2023); Tang et al. (2024) follow this idea to design feed-forward Gaussian reconstruction networks. LRM Hong et al. (2023); He and Wang (2023) shows that transformers can also be scaled up for 3D reconstruction with large-scale training data, which is followed by hybrid Gaussian-triplane methods Zou et al. (2023); Xu et al. (2024) within the LRM frameworks. However, the limited number of Gaussians and spatially unstructured property hinders these methods from achieving high-quality reconstruction, which also makes it hard to extend them to 3D generative modeling.
基于图像的3D重建。与按场景优化相比,基于图像的3D重建方法Tatarchenko et al.(2019); Li et al.(2009); Tulsiani et al.(2017); Yu et al.(2021)可以直接重建给定图像的3D资产,而无需优化。PixelNeRF Yu等人(2021)利用图像特征编码器来增强NeRF的可推广性。类似地,像素对齐高斯方法Charatan et al.(2023); Szymanowicz et al.(2023); Tang et al.(2024)遵循这一思想来设计前馈高斯重建网络。LRM Hong等人(2023); He和Wang(2023)表明,变压器也可以通过大规模训练数据进行3D重建,随后是LRM框架内的混合高斯-三平面方法Zou等人(2023); Xu等人(2024)。 然而,有限数量的高斯和空间非结构化的属性阻碍了这些方法实现高质量的重建,这也使得它很难扩展到三维生成建模。
3D generation. Previous works of SDS-based optimization Poole et al. (2022); Tang et al. (2023b); Xu et al. (2022a); Wang et al. (2024); Sun et al. (2023); Cheng et al. (2023); Chen et al. (2024) distill 2D diffusion priors Rombach et al. (2022) to a 3D representation with the score functions. Despite the acceleration Tang et al. (2023a); Yi et al. (2023) achieved by replacing NeRF with 3D Gaussians, generating high-fidelity 3D Gaussians using these optimization-based methods still requires costly test-time optimization. 3D-aware GANs Chan et al. (2022); Gao et al. (2022); Chan et al. (2021); Gu et al. (2021); Niemeyer and Geiger (2021); Deng et al. (2022); Xiang et al. (2022) can generate view-dependent images by training on single image collections. Nevertheless, they fall short in modeling diverse objects with complex geometry variations. Many recent works Wang et al. (2023); Müller et al. (2023); Gupta et al. (2023); Tang et al. (2023c); Shue et al. (2023) apply diffusion models for 3D generation using structured proxy 3D representations such as hybrid triplane Wang et al. (2023); Shue et al. (2023) or voxels Müller et al. (2023); Tang et al. (2023c). However, they typically need a shared implicit feature decoder across different assets, which greatly limits the representation expressiveness. Also, the inherent computational cost from NeRF leads to slow rendering speed, making it unsuitable for efficient training and rendering. Building upon the strong capability and rendering efficiency of Gaussian Splatting Kerbl et al. (2023), we propose a spatially structured Gaussian representation, making it suitable for 3D generative modeling. A concurrent work of He et al. (2024) also investigated transforming 3DGS into a volumetric representation. Their method confines the Gaussians to voxel grids during fitting and incorporates a specialized desification strategy. In contrast, our method only restricts the total number of Gaussians, adhering to the original splitting strategy and allowing unrestricted spatial distribution. This preserves the representation power during fitting. The subsequent OT-based voxelization yields spatially coherent arrangement with minimal global offset cost and hence effectively eases the difficulty of generative modeling.
3D生成。Poole等(2022);Tang等(2023 b);Xu等(2022 a);Wang等(2024);Sun等(2023);Cheng等(2023);Chen等人(2024)将2D扩散先验Rombach等人(2022)提取为具有评分函数的3D表示。尽管Tang等人(2023 a);Yi等人(2023)通过用3D高斯代替NeRF实现了加速,但使用这些基于优化的方法生成高保真3D高斯仍然需要昂贵的测试时间优化。3D感知GANs Chan et al.(2022);Gao et al.(2022);Chan et al.(2021);Gu et al.(2021);Niemeyer and盖革(2021);Deng et al.(2022);Xiang et al.(2022)可以通过对单个图像集合进行训练来生成视图相关图像。然而,它们在对具有复杂几何变化的不同对象建模方面存在不足。最近的许多作品Wang et al.(2023);Müller et al.(2023);Gupta et al.(2023);Tang et al.(2023c);Shue et al. (2023)使用结构化代理3D表示应用扩散模型进行3D生成,例如混合三平面Wang等人(2023); Shue等人(2023)或体素Müller等人(2023); Tang等人(2023 c)。然而,它们通常需要跨不同资产的共享隐式特征解码器,这极大地限制了表示的表达能力。此外,NeRF固有的计算成本导致渲染速度缓慢,使其不适合有效的训练和渲染。基于高斯溅射Kerbl等人(2023)的强大能力和渲染效率,我们提出了一种空间结构化的高斯表示,使其适用于3D生成建模。He等人(2024)的一项并行工作也研究了将3DGS转换为体积表示。他们的方法在拟合过程中将高斯限制在体素网格上,并采用了专门的desification策略。 相比之下,我们的方法只限制高斯的总数,坚持原来的分裂策略,并允许不受限制的空间分布。这在拟合期间保留了表示能力。随后的基于OT的体素化以最小的全局偏移代价产生空间相干排列,从而有效地减轻了生成式建模的难度。
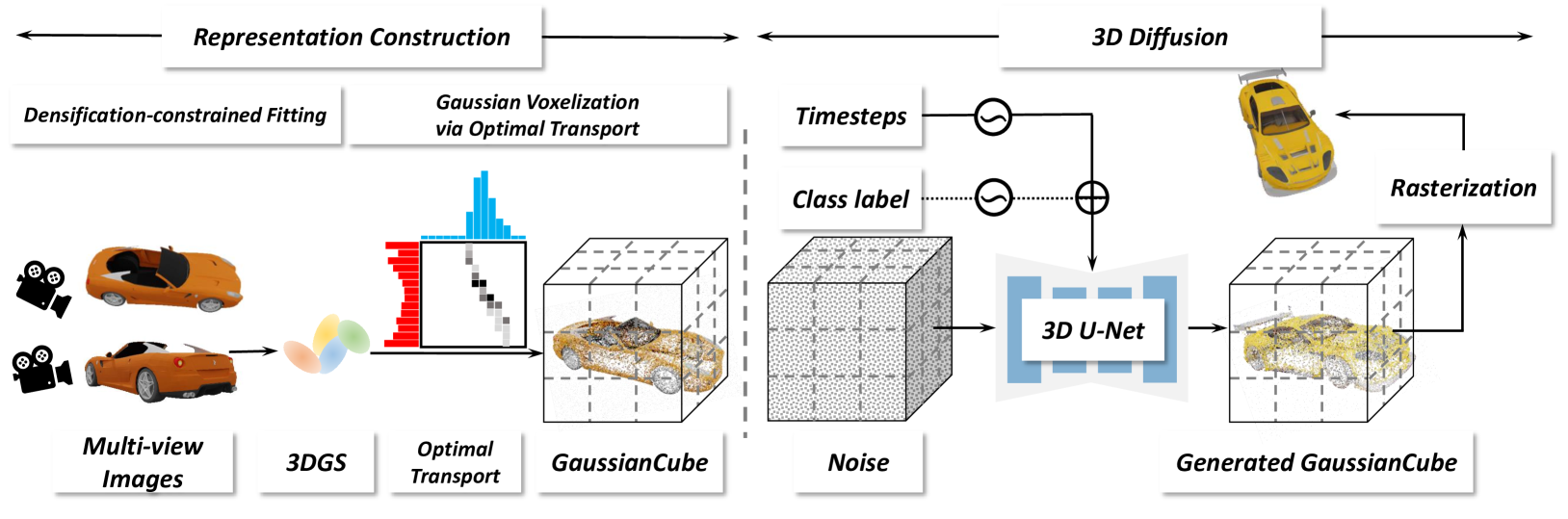
Figure 2:Overall framework. Our framework comprises two main stages of representation construction and 3D diffusion. In the representation construction stage, given multi-view renderings of a 3D asset, we perform densification-constrained fitting to obtain 3D Gaussians with constant numbers. Subsequently, the Gaussians are voxelized into GaussianCube via Optimal Transport. In the 3D diffusion stage, our 3D diffusion model is trained to generate GaussianCube from Gaussian noise.
图2:总体框架。我们的框架包括两个主要阶段的代表性建设和3D扩散。在表示构造阶段,给定3D资产的多视图渲染,我们执行密度约束拟合以获得具有常数的3D高斯。随后,通过最优传输将高斯体素化为GaussianCube。在3D扩散阶段,我们的3D扩散模型经过训练,从高斯噪声中生成GaussianCube。
3Method 3方法
Following prior works, our framework comprises two primary stages: representation construction and diffusion modeling. In representation construction phase, we first apply a densification-constrained 3DGS fitting algorithm for each object to obtain a constant number of Gaussians. These Gaussians are then organized into a spatially structured representation via Optimal Transport between the positions of Gaussians and centers of a predefined voxel grid. For diffusion modeling, we train a 3D diffusion model to learn the distribution of GaussianCubes. The overall framework is illustrated in Figure 2. We will detail our designs for each stage subsequently.
根据以前的工作,我们的框架包括两个主要阶段:代表性建设和扩散建模。在表示构造阶段,我们首先对每个对象应用密度约束的3DGS拟合算法,以获得恒定数量的高斯。然后,通过高斯的位置和预定义的体素网格的中心之间的最优传输,将这些高斯组织成空间结构化表示。对于扩散建模,我们训练一个3D扩散模型来学习GaussianCubes的分布。总体框架如图2所示。我们将详细介绍我们的设计为每个阶段随后。
3.1Representation Construction
3.1表示构造
We expect the 3D representation to be both structured, expressive and efficient. Despite Gaussian Splatting (GS) offers superior expressiveness and efficiency against NeRFs, it fails to yield fixed-length representations across different 3D assets; nor does it organize the data in a spatially structured format. To address these limitations, we introduce GaussianCube, which effectively overcomes the unstructured nature of Gaussian Splatting, while retaining both expressiveness and efficiency.
我们希望3D表示既结构化,表达性和效率。尽管高斯溅射(GS)提供了相对于NeRF的上级表现力和效率,但它无法在不同的3D资产中产生固定长度的表示;也不能以空间结构化格式组织数据。为了解决这些限制,我们引入了GaussianCube,它有效地克服了高斯飞溅的非结构化性质,同时保留了表现力和效率。
Formally, a 3D asset is represented by a collection of 3D Gaussians as introduced in Gaussian Splatting Kerbl et al. (2023). The geometry of the �-th 3D Gaussian 𝒈� is given by
从形式上讲,3D资产由高斯飞溅Kerbl等人(2023)中介绍的3D高斯集合表示。第0#个3D高斯模型 𝒈� 的几何形状由下式给出:
| 𝒈�(𝒙)=exp(−12(𝒙−𝝁�)⊤𝚺�−1(𝒙−𝝁�)), | (1) |
where 𝝁�∈ℝ3 is the center of the Gaussian and 𝚺�∈ℝ3×3 is the covariance matrix defining the shape and size, which can be decomposed into a quaternion 𝒒�∈ℝ4 and a vector 𝒔�∈ℝ3 for rotation and scaling, respectively. Moreover, each Gaussian 𝒈� have an opacity value ��∈ℝ and a color feature 𝒄�∈ℝ3 for rendering. Combining them together, the �-channel feature vector Ǘ3d;�={𝝁�,𝒔�,𝒒�,��,𝒄�}∈ℝ� fully characterizes the Gaussian 𝒈�.
其中 𝝁�∈ℝ3 是高斯的中心, 𝚺�∈ℝ3×3 是定义形状和大小的协方差矩阵,其可以被分解为分别用于旋转和缩放的四元数 𝒒�∈ℝ4 和矢量 𝒔�∈ℝ3 。此外,每个高斯 𝒈� 具有用于渲染的不透明度值 ��∈ℝ 和颜色特征 𝒄�∈ℝ3 。将它们组合在一起, � 通道特征向量 Ǘ3d;�={𝝁�,𝒔�,𝒒�,��,𝒄�}∈ℝ� 完全表征高斯 𝒈� 。
Notably, the adaptive control is one of the most essential steps during the fitting process in GS Kerbl et al. (2023). It dynamically clones Gaussians in under-reconstructed regions, splits Gaussians in over-reconstructed regions, and eliminates those with irregular dimensions. Although the adaptive control substantially improves the fitting quality, it can lead to a varying number of Gaussians for different objects. Furthermore, the Gaussians are stored without a predetermined spatial order, resulting in an absence of an organized spatial structure. These aspects pose significant challenges to 3D generative modeling. To overcome these obstacles, we first introduce our densification-constrained fitting strategy to obtain a fixed number of free Gaussians. Then, we systematically arrange the resulting Gaussians within a predefined voxel grid via Optimal Transport, thereby achieving a spatially structured GS representation.
值得注意的是,自适应控制是GS Kerbl等人(2023)中拟合过程中最重要的步骤之一。它动态地克隆高斯在重建不足的地区,分裂高斯在过度重建的地区,并消除那些不规则的尺寸。虽然自适应控制大大提高了拟合质量,但它可能导致不同对象的高斯数不同。此外,在没有预定空间顺序的情况下存储高斯,导致缺乏有组织的空间结构。这些方面对3D生成式建模提出了重大挑战。为了克服这些障碍,我们首先引入我们的密度约束拟合策略,以获得固定数量的自由高斯。然后,我们通过最优传输系统地将所得到的高斯分布安排在预定义的体素网格内,从而实现空间结构化的GS表示。
\begin{overpic}[width=424.94574pt]{imgs/framework/densification_OT-cropped.pdf% } \put(23.0,-1.5){(a)} \put(70.0,-1.5){(b)} \end{overpic}
\开始{overpic}[width=424.94574pt]{imgs/framework/densification_OT-cropped.pdf% } \put(23.0,-1.5){(a)} \put(70.0,-1.5){(b)} \end{overpic}
Figure 3:Illustration of representation construction. First, we perform densification-constrained fitting to yield a fixed number of Gaussians, as shown in (a). We then employ Optimal Transport to organize the resultant Gaussians into a voxel grid. A 2D illustration of this process is presented in (b).
图3:表示构造的图示。首先,我们执行密度约束拟合以产生固定数量的高斯,如(a)所示。然后,我们采用最优运输组织所得到的高斯体素网格。在(B)中给出了该过程的2D图示。
Densification-constrained fitting. Our approach begins with the aim of maintaining a constant number of Gaussians 𝒈∈ℝ�max×� across different objects during the fitting. A naive approach might involve omitting the densification and pruning steps in the original GS. However, we argue that such simplifications significantly harm the fitting quality, with empirical evidence shown in Table 4. Instead, we propose to retain the pruning process while imposing a new constraint on the densification phase. Specifically, if the current iteration comprises �c Gaussians and �� Gaussians need to be densified, we introduce a measure to prevent exceeding the predefined maximum of �max Gaussians (with �max set to 32,768 in this work). This is achieved by selecting �max−�c Gaussians with the largest view-space positional gradients from the �� candidates for densification in cases where ��>�max−�c. Otherwise, all �� Gaussians are subjected to densification as in the original GS. Additionally, instead of performing the cloning and splitting in the same densification steps, we opt to perform each alternately without influencing each other. Upon completion of the entire fitting process, we pad Gaussians with �=0 to reach the target count of �max without affecting the rendering results. The detailed fitting procedure is shown in Figure 3 (a).
密度约束拟合。我们的方法首先是在拟合过程中保持不同对象的高斯数 𝒈∈ℝ�max×� 不变。一种简单的方法可能涉及省略原始GS中的致密化和修剪步骤。然而,我们认为这种简化会严重损害拟合质量,经验证据如表4所示。相反,我们建议保留修剪过程,同时对致密化阶段施加新的约束。具体来说,如果当前迭代包括 �c 高斯,并且需要对 �� 高斯进行加密,则我们引入一种措施来防止超过 �max 高斯的预定义最大值(在本工作中将 �max 设置为 32,768 )。这是通过在 ��>�max−�c 的情况下从用于致密化的 �� 候选中选择具有最大视图空间位置梯度的 �max−�c 高斯来实现的。否则,所有 �� 高斯函数都要像原始GS一样进行致密化。 此外,我们没有在相同的致密化步骤中执行克隆和拆分,而是选择交替执行每个步骤,而不会相互影响。在完成整个拟合过程后,我们用 �=0 填充高斯,以达到目标计数 �max ,而不影响渲染结果。详细的拟合过程如图3(a)所示。
Gaussian voxelization via Optimal Transport. To further organize the obtained Gaussians into a spatially structured representation for 3D generative modeling, we propose to map the Gaussians to a predefined structured voxel grid 𝒗∈ℝ��×��×��×� where ��=�max3. Intuitively, we aim to “move” each Gaussian into a voxel grid while preserving their geometric relations as much as possible. To this end, we formulate this as an Optimal Transport (OT) problem Villani et al. (2009); Burkard and Cela (1999) between the Gaussians’ spatial positions {𝝁�,�=1,…,�max} and the voxel grid centers {𝒙�,�=1,…,�max}. Let 𝐃 be a distance matrix with 𝐃�� being the moving distance between 𝝁� and 𝒙�, i.e., 𝐃��=‖𝝁�−𝒙�‖2. The transport plan is represented by a binary matrix 𝐓∈ℝ�max×�max, and the optimal transport plan is given by:
通过最优传输的高斯体素化。为了进一步将所获得的高斯曲线组织成用于3D生成建模的空间结构化表示,我们建议将高斯曲线映射到预定义的结构化体素网格 𝒗∈ℝ��×��×��×� ,其中 ��=�max3 。直观地说,我们的目标是将每个高斯“移动”到体素网格中,同时尽可能保留它们的几何关系。为此,我们将其公式化为高斯空间位置 {𝝁�,�=1,…,�max} 和体素网格中心 {𝒙�,�=1,…,�max} 之间的最优传输(OT)问题Villani et al.(2009); Burkard and Cela(1999)。令 𝐃 为距离矩阵,其中 𝐃�� 为 𝝁� 和 𝒙� 之间的移动距离,即,八号。运输计划由二进制矩阵 𝐓∈ℝ�max×�max 表示,并且最优运输计划由下式给出:
| minimize𝐓∑�=1�max∑�=1�max𝐓��𝐃�� subject to ∑�=1�max𝐓��=1∀�∈{1,…,�max}∑�=1�max𝐓��=1∀�∈{1,…,�max}𝐓��∈{0,1}∀(�,�)∈{1,…,�max}×{1,…,�max}. | (2) |
The solution is a bijective transport plan 𝐓* that minimizes the total transport distances. We employ the Jonker-Volgenant algorithm Jonker and Volgenant (1988) to solve the OT problem. We organize the Gaussians according to the solutions, with the �-th voxel grid encapsulating the feature vector of the corresponding Gaussian Ǘ3d;�={𝝁�−𝒙�,𝒔�,𝒒�,��,𝒄�}∈ℝ�, where � is determined by the optimal transport plan (i.e., 𝐓��*=1). Note that we substitute the original Gaussian positions with offsets of the current voxel center to reduce the solution space for diffusion modeling. As a result, our fitted Gaussians are systematically arranged within a voxel grid 𝒗 and maintain the spatial coherence.
解决方案是一个双射运输计划 𝐓* ,它使总运输距离最小化。我们使用Jonker和Volgenant(1988)算法来解决OT问题。我们根据解来组织高斯,其中第 � 个体素网格封装对应高斯 Ǘ3d;�={𝝁�−𝒙�,𝒔�,𝒒�,��,𝒄�}∈ℝ� 的特征向量,其中 � 由最优传输计划确定(即, 𝐓��*=1 )。请注意,我们用当前体素中心的偏移量替换原始高斯位置,以减少扩散建模的解空间。因此,我们的拟合高斯被系统地布置在体素网格 𝒗 内,并保持空间相干性。
3.23D Diffusion on GaussianCube
GaussianCube上的3.23维扩散
We now introduce our 3D diffusion model incorporated with the proposed expressive, efficient and spatially structured representation. After organizing the fitted Gaussians 𝒈 into GaussianCube 𝒚 for each object, we aim to model the distribution of GaussianCube, i.e., �(𝒚).
现在,我们介绍我们的3D扩散模型与建议的表达,高效和空间结构化的表示。在为每个对象将拟合的Gaussian 𝒈 组织成GaussianCube 𝒚 之后,我们的目标是对GaussianCube的分布进行建模,二号。
Formally, the generation procedure can be formulated into the inversion of a discrete-time Markov forward process. During the forward phase, we gradually add noise to 𝒚0∼�(𝒚) and obtain a sequence of increasingly noisy samples {𝒚�|�∈[0,�]} according to
形式上,生成过程可以被公式化为离散时间马尔可夫正向过程的逆。在前向阶段期间,我们逐渐将噪声添加到 𝒚0∼�(𝒚) ,并且根据下式获得噪声越来越大的样本序列 {𝒚�|�∈[0,�]} :
| 𝒚�:=��𝒚0+���, | (3) |
where �∈𝒩(𝟎,𝑰) represents the added Gaussian noise, and ��,�� constitute the noise schedule which determines the level of noise added to destruct the original data sample. As a result, 𝒚� will finally reach isotropic Guassian noise after sufficient destruction steps. By reversing the above process, we are able to perform the generation process by gradually denoise the sample starting from pure Gaussian noise 𝒚�∼𝒩(𝟎,𝑰) until reaching 𝒚0. Our diffusion model is trained to denoise 𝒚� into 𝒚0 for each timestep �, facilitating both unconditional and class-conditioned generation.
其中 �∈𝒩(𝟎,𝑰) 表示所添加的高斯噪声,而 ��,�� 构成噪声调度,该噪声调度确定所添加的噪声的电平以破坏原始数据样本。结果, 𝒚� 在足够的破坏步骤之后将最终达到各向同性高斯噪声。通过颠倒上述过程,我们能够通过从纯高斯噪声 𝒚�∼𝒩(𝟎,𝑰) 开始逐渐对样本进行降噪直到达到 𝒚0 来执行生成过程。我们的扩散模型经过训练,在每个时间步 � 中将 𝒚� 降噪为 𝒚0 ,从而促进无条件和类条件生成。
Model architecture. Thanks to the spatially structured organization of the proposed GaussianCube, standard 3D convolution is sufficient to effectively extract and aggregate the features of neighboring Gaussians without elaborate designs. We leverage the popular U-Net network for diffusion Nichol and Dhariwal (2021); Dhariwal and Nichol (2021) and simply replace the original 2D convolution layer to their 3D counterparts. The upsampling, downsampling and attention operations are also replaced with corresponding 3D implementations.
模型架构。由于所提出的GaussianCube的空间结构化组织,标准3D卷积足以有效地提取和聚合相邻高斯的特征,而无需精心设计。我们利用流行的U-Net网络进行扩散Nichol和达里瓦尔(2021);达里瓦尔和Nichol(2021),并简单地将原始的2D卷积层替换为3D对应层。上采样、下采样和注意操作也被相应的3D实现所取代。
Conditioning mechanism. When performing class-conditional diffusion training, we use adaptive group normalization (AdaGN) Dhariwal and Nichol (2021) to inject conditions of class labels 𝒄cls into our model, which can be defined as:
调节机制。当执行类条件扩散训练时,我们使用自适应组归一化(AdaGN)达里瓦尔和尼科尔(2021)将类标签 𝒄cls 的条件注入我们的模型中,可以定义为:
| AdaGN(𝒇�) | =GroupNorm(𝒇�)⋅(1+𝜸)+𝜷, | (4) |
where the group-wise scale and shift parameters 𝜸 and 𝜷 are estimated to modulate the activations {𝒇�} in each residual block from the embeddings of both timesteps � and condition 𝒄cls.
其中,估计成组缩放和移位参数 𝜸 和 𝜷 ,以根据时间步长 � 和条件 𝒄cls 两者的嵌入来调制每个残差块中的激活 {𝒇�} 。
Training objective. In our 3D diffusion training, we parameterize our model 𝒚^� to predict the noise-free input 𝒚0 using:
培训目标。在我们的3D扩散训练中,我们参数化我们的模型 𝒚^� 以预测无噪声输入 𝒚0 ,使用:
| ℒsimple =𝔼�,𝒚0,�[‖𝒚^�(��𝒚0+���,�,𝒄cls)−𝒚0‖22], | (5) |
where the condition signal 𝒄cls is only needed when training class-conditioned diffusion models. We additionally add supervision on the image level to ensure better rendering quality of generated GaussianCube, which has been shown to effectively enhance the visual quality in previous works Wang et al. (2023); Müller et al. (2023). Specifically, we penalize the discrepancy between the rasterized images �pred of the predicted GaussianCubes and the ground-truth images �gt:
其中条件信号 𝒄cls 仅在训练类条件扩散模型时需要。我们还在图像级别上添加了监督,以确保生成的GaussianCube具有更好的渲染质量,这在以前的作品Wang et al.(2023); Müller et al.(2023)中已被证明可以有效地提高视觉质量。具体地,我们惩罚预测的GaussianCubes的光栅化图像 �pred 和地面实况图像 �gt 之间的差异:
| ℒimage | =ℒpixel+ℒperc | (6) | ||
| =𝔼�,�pred (∑�‖Ψ�(�pred)−Ψ�(�gt)‖22) | ||||
| +𝔼�,�pred(‖�pred−�gt ‖22), |
where Ψ� is the multi-resolution feature extracted using the pre-trained VGG Simonyan and Zisserman (2014). Benefiting from the efficiency of both rendering speed and memory costs from Gaussian Splatting Kerbl et al. (2023), we are able to render the full image rather than only a small patch as in previous NeRF-based methods Wang et al. (2023); Chen et al. (2023), which facilitates fast training with high-resolution renderings. Our overall training loss can be formulated as:
其中 Ψ� 是使用预训练的VGG Simonyan和Zisserman(2014)提取的多分辨率特征。受益于高斯溅射Kerbl等人(2023)的渲染速度和内存成本的效率,我们能够渲染完整的图像,而不是像以前的基于NeRF的方法Wang等人(2023)那样只渲染一小块图像; Chen等人(2023),这有助于使用高分辨率渲染进行快速训练。我们的整体训练损失可以公式化为:
| ℒ=ℒsimple+�ℒimage, | (7) |
where � is a balancing weight.
其中 � 是平衡配重。
4Experiments 4实验
4.1Dataset and Metrics 4.1数据集和数据库
To measure the expressiveness and efficiency of various 3D representations, we fit 100 objects in ShapeNet Car Chang et al. (2015) using each representation and report the PSNR, LPIPS Zhang et al. (2018) and Structural Similarity Index Measure (SSIM) metrics when synthesizing novel views. Furthermore, we conduct experiments of single-category unconditional generation on ShapeNet Chang et al. (2015) Car and Chair. We randomly render 150 views and fit 32×32×32×14 GaussianCube for each object. To further validate the strong capability of the proposed framework, we also conduct experiments on Omniobject3D Wu et al. (2023b), which is a challenging dataset containing large-vocabulary real-world scanned 3D objects. We fit GaussianCube of the same dimensions as ShapeNet using 100 multi-view renderings for each object. To numerically measure the generation quality, we report the FID Heusel et al. (2017) and KID Bińkowski et al. (2018) scores between 50K renderings of generated samples and 50K ground-truth renderings at the 512×512 resolution.
为了衡量各种3D表示的表现力和效率,我们使用每种表示在ShapeNet Car Chang et al.(2015)中拟合了100个对象,并在合成新视图时报告了PSNR,LPIPS Zhang et al.(2018)和结构相似性指数度量(SSIM)指标。此外,我们在ShapeNet Chang et al.(2015)Car and Chair上进行了单类别无条件生成实验。我们随机渲染150个视图,并为每个对象安装 32×32×32×14 GaussianCube。为了进一步验证所提出的框架的强大功能,我们还对Omniobject3D Wu等人(2023 b)进行了实验,这是一个具有挑战性的数据集,包含大量词汇的真实世界扫描的3D对象。我们为每个对象使用100个多视图渲染来拟合与ShapeNet相同尺寸的GaussianCube。为了在数值上测量生成质量,我们报告了FID Heusel等人(2017)和KID Bioglovkowski等人。 (2018)在 512×512 分辨率下,生成的样本的50K渲染和50K地面实况渲染之间的得分。
4.2Implementation Details
4.2实现细节
To construct GaussianCube for each object, we perform the proposed densification-constrained fitting for 30K iterations. Since the time complexity of Jonker-Volgenant algorithm Jonker and Volgenant (1988) is �(�max3), we opt for an approximate solution to the Optimal Transport problem. This is achieved by dividing the positions of the Gaussians and the voxel grid into four sorted segments and then applying the Jonker-Volgenant solver to each segment individually. We empirically found this approximation successfully strikes a balance between computational efficiency and spatial structure preservation. For the 3D diffusion model, we adopt the ADM U-Net network Nichol and Dhariwal (2021); Dhariwal and Nichol (2021). We perform full attention at the resolution of 83 and 43 within the network. The timesteps of diffusion models are set to 1,000 and we train the models using the cosine noise schedule Nichol and Dhariwal (2021) with loss weight � set to 10. All models are trained on 16 Tesla V100 GPUs with a total batch size of 128.
为了为每个对象构建GaussianCube,我们执行了30 K次迭代的建议的密度约束拟合。由于Jonker和Volgenant(1988)算法的时间复杂度是 �(�max3) ,我们选择近似解决最优运输问题。这是通过将高斯和体素网格的位置划分为四个排序的片段,然后将Jonker-Volgenant求解器单独应用于每个片段来实现的。我们的经验发现,这种近似成功地达到了计算效率和空间结构保存之间的平衡。对于三维扩散模型,我们采用ADM U-Net网络Nichol和达里瓦尔(2021);达里瓦尔和Nichol(2021)。我们在网络中以 83 和 43 的分辨率进行充分关注。扩散模型的时间步长设置为 1,000 ,我们使用余弦噪声时间表Nichol和达里瓦尔(2021)训练模型,损失权重 � 设置为 10 。 All models are trained on 16 Tesla V100 GPUs with a total batch size of 128 .
| Representation | Spatially-structured 空间结构 | PSNR↑ PSNR ↑ 的问题 | LPIPS↓ LPIPPS ↓ 的问题 | SSIM↑ 阿信 ↑ | Rel. Speed↑ | Params (M)↓ |
| Instant-NGP | ✗ | 33.98 | 0.0386 | 0.9809 | 1× | 12.25 |
| Gaussian Splatting | ✗ | 35.32 | 0.0303 | 0.9874 | 2.58× | 1.84 |
| Voxels | ✓ | 28.95 | 0.0959 | 0.9470 | 1.73× | 0.47 |
| Voxels* | ✓ | 25.80 | 0.1407 | 0.9111 | 1.73× | 0.47 |
| Triplane | ✓ | 32.61 | 0.0611 | 0.9709 | 1.05× | 6.30 |
| Triplane* | ✓ | 31.39 | 0.0759 | 0.9635 | 1.05× | 6.30 |
| Our GaussianCube 我们的高斯魔方 | ✓ | 34.94 | 0.0347 | 0.9863 | 3.33× | 0.46 |
Table 2:Quantitative results of representation fitting on ShapeNet Car. * denotes that the implicit feature decoder is shared across different objects.
\begin{overpic}[width=433.62pt]{imgs/results/fitting.jpg} \put(5.0,-2.0){Ground-truth} \put(21.0,-2.0){Instant-NGP} \put(36.0,-2.0){Gaussian Splatting} \put(57.0,-2.0){Voxel${}^{*}$} \put(72.0,-2.0){Triplane${}^{*}$} \put(85.0,-2.0){{Our GaussianCube}} \end{overpic}
Figure 4:Qualitative results of object fitting.
| Method | ShapeNet Car | ShapeNet Chair | OmniObject3D | |||
|---|---|---|---|---|---|---|
| FID-50K↓ | KID-50K(‰)↓ | FID-50K↓ | KID-50K(‰)↓ | FID-50K↓ | KID-50K(‰)↓ | |
| EG3D | 30.48 | 20.42 | 27.98 | 16.01 | - | - |
| GET3D | 17.15 | 9.58 | 19.24 | 10.95 | - | - |
| DiffTF | 51.88 | 41.10 | 47.08 | 31.29 | 46.06 | 22.86 |
| Ours | 13.01 | 8.46 | 15.99 | 9.95 | 11.62 | 2.78 |
Table 3:Quantitative results of unconditional generation on ShapeNet Car and Chair Chang et al. (2015) and class-conditioned generation on OmniObject3D Wu et al. (2023b).
\begin{overpic}[width=424.94574pt]{imgs/results/shapenet_all.jpg} \put(12.0,-3.0){EG3D~{}\cite[cite]{\@@bibref{Authors Phrase1YearPhrase2}{chan2% 022efficient}{\@@citephrase{(}}{\@@citephrase{)}}}} \put(37.0,-3.0){GET3D~{}\cite[cite]{\@@bibref{Authors Phrase1YearPhrase2}{gao2% 022get3d}{\@@citephrase{(}}{\@@citephrase{)}}}} \put(60.0,-3.0){DiffTF~{}\cite[cite]{\@@bibref{Authors Phrase1YearPhrase2}{cao% 2023large}{\@@citephrase{(}}{\@@citephrase{)}}}} \put(85.0,-3.0){{Ours}} \end{overpic}
Figure 5:Qualitative comparison of unconditional 3D generation on ShapeNet Car and Chair datasets. Our model is capable of generating results of complex geometry with rich details.
\begin{overpic}[width=424.94574pt]{imgs/results/omni_all.jpg} \put(18.0,-3.0){DiffTF~{}\cite[cite]{\@@bibref{Authors Phrase1YearPhrase2}{cao% 2023large}{\@@citephrase{(}}{\@@citephrase{)}}}} \put(75.0,-3.0){{Ours}} \end{overpic}
Figure 6:Qualitative comparison of class-conditioned 3D generation on large-vocabulary OmniObject3D Wu et al. (2023b). Our model is able to handle diverse distribution with high-fidelity generated samples.
4.3Main Results
3D fitting. We first evaluate the representation power of our GaussianCube using 3D object fitting and compare it against previous NeRF-based representations including Triplane and Voxels, which are widely adopted in 3D generative modeling Chan et al. (2022); Wang et al. (2023); Cao et al. (2023); Müller et al. (2023); Tang et al. (2023c). We also include Instant-NGP Müller et al. (2022) and original Gaussian Splatting Kerbl et al. (2023) for reference, although they cannot be directly applied in generative modeling due to their spatially unstructured nature. As shown in Table 2, our GaussianCube outperforms all NeRF-based representations among all metrics. The visualizations in Figure 3 illustrate that GaussianCube can faithfully reconstruct geometry details and intricate textures, which demonstrates its strong capability. Moreover, compared with over 131,000 Gaussians utilized in the original GS for each object, our GaussianCube only employs 4× less Gaussians due to our densification-constrained fitting. This leads to the faster fitting speed of our method and significantly fewer parameters (over 10× less than Triplane), which demonstrate its efficiency and compactness. Notably, for 3D generation tasks, NeRF-based methods typically necessitate a shared implicit feature decoder for different objects, which leads to significant decreases sin fitting quality compared to single-object fitting, as shown in Table 2. In contrast, the explicit characteristic of GS allows our GaussianCube to bypass such a shared feature decoder, resulting in no quality gap between single and multiple object fitting.
3D拟合。我们首先使用3D对象拟合来评估我们的GaussianCube的表示能力,并将其与以前的基于NeRF的表示进行比较,包括三平面和体素,这些表示在3D生成建模中被广泛采用Chan et al.(2022); Wang et al.(2023); Cao et al.(2023); Müller et al.(2023); Tang et al.(2023 c)。我们还包括Instant-NGP Müller et al.(2022)和原始的Gaussian Splatting Kerbl et al.(2023)作为参考,尽管由于其空间非结构化性质,它们不能直接应用于生成建模。如表2所示,我们的GaussianCube在所有指标中优于所有基于NeRF的表示。图3中的可视化显示了GaussianCube可以忠实地重建几何细节和复杂的纹理,这证明了它的强大能力。 此外,与每个对象的原始GS中使用的超过 131,000 高斯相比,由于我们的密度约束拟合,我们的GaussianCube仅使用 4× 较少的高斯。这导致我们的方法的更快的拟合速度和更少的参数(超过 10× 小于Triplane),这证明了它的效率和紧凑性。值得注意的是,对于3D生成任务,基于NeRF的方法通常需要用于不同对象的共享隐式特征解码器,这导致与单对象拟合相比,sin拟合质量显著降低,如表2所示。相比之下,GS的显式特性允许我们的GaussianCube绕过这样的共享特征解码器,从而在单个和多个对象拟合之间没有质量差距。
Single-category unconditional generation. For unconditional generation, we compare our method with the state-of-the-art 3D generation works including 3D-aware GANs Chan et al. (2022); Gao et al. (2022) and Triplane diffusion models Cao et al. (2023). As shown in Table 3, our method surpasses all prior works in terms of both FID and KID scores and sets new records. We also provide visual comparisons in Figure 5, where EG3D and DiffTF tend to generate blurry results with poor geometry, and GET3D fails to provide satisfactory textures. In contrast, our method yields high-fidelity results with authentic geometry and sharp texture details.
单类无条件生成。对于无条件生成,我们将我们的方法与最先进的3D生成工作进行了比较,包括3D感知GANs Chan et al.(2022); Gao et al.(2022)和Triplane diffusion models Cao et al.(2023)。如表3所示,我们的方法在FID和KID分数方面超过了所有先前的工作,并创下了新的记录。我们还在图5中提供了视觉比较,其中EG 3D和DiffTF倾向于生成具有较差几何形状的模糊结果,而GET 3D无法提供令人满意的纹理。相比之下,我们的方法产生高保真度的结果与真实的几何形状和尖锐的纹理细节。
Large-vocabulary class-conditioned generation. We also compare class-conditioned generation with DiffTF Cao et al. (2023) on more diverse and challenging OmniObject3D Wu et al. (2023b) dataset. We achieve significantly better FID and KID scores than DiffTF as shown in Table 3, demonstrating the stronger capacity of our method. Visual comparisons in Figure 6 reveal that DiffTF often struggles to create intricate geometry and detailed textures, whereas our method is able to generate objects with complex geometry and realistic textures.
大词汇量的阶级制约生成。我们还在更多样化和更具挑战性的OmniObject 3D Wu et al.(2023 b)数据集上将类条件生成与DiffTF Cao et al.(2023)进行了比较。如表3所示,我们实现了比DiffTF显著更好的FID和KID分数,证明了我们方法的更强能力。图6中的视觉比较显示,DiffTF通常难以创建复杂的几何形状和详细的纹理,而我们的方法能够生成具有复杂几何形状和逼真纹理的对象。
| Method | Densify & Prune 加密和修剪 | Representation Fitting 表示拟合 | Generation | |||
|---|---|---|---|---|---|---|
| PSNR↑ PSNR ↑ 的问题 | LPIPS↓ LPIPPS ↓ 的问题 | SSIM↑ 阿信 ↑ | FID-50K↓ | KID-50K(‰)↓ KID-50K(‰) ↓ | ||
| A. Voxel grid w/o offset A.无偏移的体素网格 | ✗ | 25.87 | 0.1228 | 0.9217 | - | - |
| B. Voxel grid w/ offset B。带偏移的体素网格 | ✗ | 30.18 | 0.0780 | 0.9628 | 40.52 | 24.35 |
| C. Ours w/o OT C.我们没有加班 | ✓ | 34.94 | 0.0346 | 0.9863 | 21.41 | 14.37 |
| D. Ours | ✓ | 34.94 | 0.0346 | 0.9863 | 13.01 | 8.46 |
Table 4:Quantitative ablation of both representation fitting and generation quality on ShapeNet Car.
表4:ShapeNet Car上的代表拟合和生成质量的定量消融。
\begin{overpic}[width=346.89731pt]{imgs/results/ablation/ablation_fitting_all.% jpg} \put(5.0,-3.0){Ground-truth} \put(32.0,-3.0){~{}\lx@cref{creftypecap~refnum}{tab:ablation_fitting_generatio% n} A.} \put(57.0,-3.0){~{}\lx@cref{creftypecap~refnum}{tab:ablation_fitting_generatio% n} B.} \put(78.0,-3.0){{~{}\lx@cref{creftypecap~refnum}{tab:ablation_fitting_generati% on} D. (Ours)}} \end{overpic}
Figure 7:Qualitative ablation of representation fitting. Our GaussianCube achieves superior fitting results while maintaining a spatial structure.
\begin{overpic}[width=424.94574pt]{imgs/results/ablation/ablation_mapping_% results.jpg} \put(3.0,-1.5){{Optimal Transport (Ours)}} \put(27.0,-1.5){Nearest Neighbor Transport} \put(56.0,-1.5){~{}\lx@cref{creftypecap~refnum}{tab:ablation_fitting_generatio% n} B.} \put(72.0,-1.5){~{}\lx@cref{creftypecap~refnum}{tab:ablation_fitting_generatio% n} C.} \put(85.0,-1.5){{~{}\lx@cref{creftypecap~refnum}{tab:ablation_fitting_generati% on} D. (Ours)}} \put(23.0,-4.0){\small{(a)}} \put(75.0,-4.0){\small{(b)}} \end{overpic}
Figure 8:Ablation study of the Gaussian structuralization methods and 3D generation. For visualization of Gaussian structuralization in (a), we map the coordinates of the corresponding voxel grid of each Gaussians to RGB values to visualize the organization. Our Optimal Transport solution yields smooth transit among Gaussians, indicating a coherent global structure, whereas Nearest Neighbor Transport leads to obvious discontinuities. Our OT-based solution also results in the best generation quality shown in (b).
图8:高斯结构化方法和3D生成的消融研究。对于(a)中的高斯结构化的可视化,我们将每个高斯的对应体素网格的坐标映射到RGB值以可视化组织。我们的最优运输解决方案产生高斯之间的平稳过渡,表明一个连贯的全球结构,而最近邻运输导致明显的不连续性。我们基于OT的解决方案还可实现(b)中所示的最佳发电质量。
4.4Ablation Study 4.4消融研究
We first examine the key factors in representation construction. To spatially structure the Gaussians, a simplest approach would be anchoring the positions of Gaussians to a predefined voxel grid while omitting densification and pruning, which leads to severe failure when fitting the objects as shown in Figure 7. Even by introducing learnable offsets to the voxel grid, the complex geometry and detailed textures still can not be well captured, as shown in Figure 7. We observe that the offsets are typically too small to effectively lead the Gaussians close to the object surfaces, which demonstrates the necessity of performing densification and pruning during object fitting. Based on these insights, we do not organize the Gaussians during the fitting stage. Instead, we only maintain a constant number of Gaussians using densification-constrained fitting and post-process the Gaussians into a spatially structured representation. Our GaussianCube can capture both complex geometry and intricate details as illustrated in Figure 7. The numerical comparison in Table 4 also demonstrates the superior fitting quality of our GaussianCube.
我们首先研究表征构建中的关键因素。为了在空间上构造高斯,最简单的方法是将高斯的位置锚定到预定义的体素网格,同时省略致密化和修剪,这在拟合对象时会导致严重的失败,如图7所示。即使通过向体素网格引入可学习的偏移量,复杂的几何形状和详细的纹理仍然不能很好地捕获,如图7所示。我们观察到,偏移量通常太小,无法有效地引导高斯函数接近对象表面,这表明在对象拟合期间执行致密化和修剪的必要性。基于这些见解,我们在拟合阶段不组织高斯。相反,我们只使用密度约束拟合保持恒定数量的高斯,并将高斯后处理为空间结构化表示。 我们的GaussianCube可以捕获复杂的几何形状和复杂的细节,如图7所示。表4中的数值比较也证明了我们的GaussianCube的上级拟合质量。
We also evaluate how the representation affects 3D generative modeling in Table 4 and Figure 8. Limited by the poor fitting quality, performing diffusion modeling on voxel grid with learnable offsets leads to blurry generation results as shown in Figure 8. To validate the importance of organizing Gaussians via OT, we compare with the organization based on nearest neighbor transport between positions of Gaussians and centers of voxel grid. We linearly map each Gaussian’s corresponding coordinates of voxel grid to RGB color to visualize the different organizations. As shown in Figure 8 (a), our proposed OT approach results in smooth color transitions, indicating that our method successfully preserves the spatial correspondence. However, nearest neighbor transport does not consider global structure, which leads to abrupt color transitions. Notably, since our OT-based organization considers the global spatial coherence, both the quantitative results in Table 4 and visual comparisons Figure 8 indicate that our structured arrangement facilitates generative modeling by alleviating its complexity, successfully leading to superior generation quality.
我们还评估了表示如何影响表4和图8中的3D生成建模。受限于较差的拟合质量,在具有可学习偏移的体素网格上执行扩散建模会导致模糊的生成结果,如图8所示。为了验证通过OT组织高斯的重要性,我们比较了基于高斯位置和体素网格中心之间的最近邻传输的组织。我们将每个高斯体素网格的对应坐标线性映射到RGB颜色,以可视化不同的组织。如图8(a)所示,我们提出的OT方法导致平滑的颜色过渡,表明我们的方法成功地保留了空间对应性。然而,最近邻传输不考虑全局结构,这导致突然的颜色过渡。 值得注意的是,由于我们基于OT的组织考虑了全局空间相干性,表4中的定量结果和图8中的视觉比较都表明,我们的结构化布置通过减轻其复杂性来促进生成建模,成功地导致上级生成质量。
5Conclusion 5结论
We have presented GaussianCube, a novel representation crafted for 3D generative models. We address the unstructured nature of Gaussian Splatting and unleash its potential for 3D generative modeling. Firstly, we fit each 3D object with a constant number of Gaussians by our proposed densification-constrained fitting algorithm. Furthermore, we organize the obtained Gaussians into a spatially structured representation by solving the Optimal Transport problem between the positions of Gaussians and the predefined voxel grid. The proposed GaussianCube is expressive, efficient and with spatially coherent structure, providing a strong 3D representation alternative for 3D generation. We train 3D diffusion models to perform generative modeling using GaussianCube, and achieve state-of-the-art generation quality on the evaluated datasets without elaborate network or training algorithm design. This demonstrates the promise of GaussianCube to be a versatile and powerful 3D representation for 3D generation.
我们介绍了GaussianCube,这是一种为3D生成模型制作的新颖表示。我们解决了高斯飞溅的非结构化性质,并释放其潜力的3D生成建模。首先,我们适合每个3D对象与一个常数数量的高斯我们提出的密度约束拟合算法。此外,我们组织得到的高斯到一个空间结构化的表示,通过解决高斯的位置和预定义的体素网格之间的最优运输问题。所提出的GaussianCube具有表达性、高效性和空间相干性,为3D生成提供了一种强大的3D表示替代方案。我们使用GaussianCube训练3D扩散模型以执行生成建模,并在评估的数据集上实现最先进的生成质量,而无需精心的网络或训练算法设计。 这证明了GaussianCube是一个多功能和强大的3D表示3D生成的承诺。