相关文章

DeepSeek大模型指定github项目版本安装环境
最近DeepSeek非常的火爆,有一些公司复现了DeepSeek,如open-r1, 但其依赖的环境往往是最新的,甚至是新增的功能,整个生态安装没有完善。需要需要指定特定的依赖安装:
查看open-r1的setup.py发现,lighteval&…
![python算法和数据结构刷题[1]:数组、矩阵、字符串](https://i-blog.csdnimg.cn/direct/21f81f3f38af47ada982711451fcbe9f.png)
python算法和数据结构刷题[1]:数组、矩阵、字符串
一画图二伪代码三写代码
LeetCode必刷100题:一份来自面试官的算法地图(题解持续更新中)-CSDN博客
算法通关手册(LeetCode) | 算法通关手册(LeetCode) (itcharge.cn)
面试经典 150 题 - 学习计…

企业微信开发012_使用WxJava企业微信开发框架_封装第三方应用企业微信开发005_多企业授权实现---企业微信开发014
这里主要说一下如何授权的思路,如何来做,其实非常简单,
如果你有很多企业微信需要授权以后才能使用自己开发的,第三方企业微信功能,那么
首先,在企业列表中,你可以给某个企业去配置,这个企业,他对应的企业微信的,比如,
这个企业的企业id,cropID,当然还可以有,比如企业名称,用…
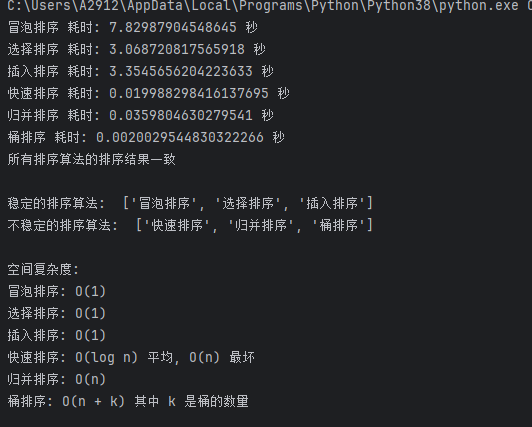
蓝桥杯python基础算法(2-1)——排序
目录 一、排序
二、例题 P3225——宝藏排序Ⅰ
三、各种排序比较
四、例题 P3226——宝藏排序Ⅱ 一、排序 (一)冒泡排序 基本思想:比较相邻的元素,如果顺序错误就把它们交换过来。 (二)选择排序 基本思想…

【Excel笔记_4】平均绝对偏差(MAD,Mean Absolute Deviation)的EXCEL公式表达
平均绝对偏差(MAD,Mean Absolute Deviation),其数学表达式如下: M A D S 1 N ∑ t 1 N ∣ S t − S ‾ ∣ MAD_S \frac{1}{N} \sum_{t1}^{N} |S_t - \overline{S}| MADSN1t1∑N∣St−S∣
在 Excel 中&…
Android学习19 -- 手搓App
1 前言
之前工作中,很多时候要搞一个简单的app去验证底层功能,Android studio又过于重型,之前用gradle,被版本匹配和下载外网包折腾的堪称噩梦。所以搞app都只有找应用的同事帮忙。一直想知道一些简单的app怎么能手搓一下&#x…

MYSQL--一条SQL执行的流程,分析MYSQL的架构
文章目录 第一步建立连接第二部解析 SQL第三步执行 sql预处理优化阶段执行阶段索引下推 执行一条select 语句中间会发生什么? 这个是对 mysql 架构的深入理解。
select * from product where id 1;对于mysql的架构分层: mysql 架构分成了 Server 层和存储引擎层&a…

深度学习-第五章机器学习基础
前言 5.1 学习算法 5.1.1 任务 5.1.2 性能度量 5.1.3 经验 5.1.4 示例: 线性回归 5.2 容量、过拟合和欠拟合 5.2.1 没有免费午餐定理5.2.2 正则化 5.3 超参数和验证集 5.3.1 验证集的作用5.3.2 交叉验证 5.4 估计、偏差和方差 5.4.1 点估计5.4.2 偏差5.4.4 权衡偏差和方差以…