今天给大家介绍两种mysql的主从同步方式:第一种是基于binlogzhu主从同步;第二种就是基于gtid的主从同步方式。
首先给大家介绍一下什么是sql的主从复制。
主从复制:
通过将MySQL的某一台主机(master)的数据复制到其他主机(slaves)上,并重新执行一遍来执行 复制过程中一台服务器充当主服务器,而其他一个或多个其他服务器充当从服务器
MySQL支持的复制类型:
基于语句(statement)的复制
在主服务器上执行SQL语句,在从服务器上执行同样的语句。MySQL默认采用基于语句的复制,效率比较高。
基于行(row)的复制
把改变的内容复制过去,而不是把命令在从服务器上执行一遍。从MySQL 5.0开始支持。
混合型(mixed)的复制
默认采用基于语句的复制,一旦发现基于语句的无法精确复制时,就会采用基于行的复制。
为什么要做主从复制(用途):
灾备
数据分布
负载平衡
读写分离
提高并发能力
主从复制原理:

主要基于MySQL二进制日志
主要包括三个线程(2个I/O线程,1个SQL线程)
1、MySQL将数据变化记录到二进制日志中;
2、Slave将MySQL的二进制日志拷贝到Slave的中继日志中;
3、Slave将中继日志中的事件在做一次,将数据变化,反应到自身(Slave)的数据库详细步骤:1、从库通过手工执行change master to 语句连接主库,提供了连接的用户一切条件(user 、password、port、ip),并且让从库知道,二进制日志的起点位置(file名 position 号); start slave
2、从库的IO线程和主库的dump线程建立连接。
3、从库根据change master to 语句提供的file名和position号,IO线程向主库发起binlog的请求。
4、主库dump线程根据从库的请求,将本地binlog以events的方式发给从库IO线程。
5、从库IO线程接收binlog events,并存放到本地relay-log中,传送过来的信息,会记录到master.info中
6、从库SQL线程应用relay-log,并且把应用过的记录到relay-log.info中,默认情况下,已经应用过的relay 会自动被清理purge
MySQL复制常用的拓扑结构:
主从类型(Master-Slave)
主主类型(Master-Master)
级联类型(Master-Slave-Slave)
如何实现主从复制
在主服务器(master)上
启用二进制日志
选择一个唯一的server-id
创建具有复制权限的用户
在从服务器(slave)上
启用中继日志
(二进制日志可开启,也可不开启)
选择一个唯一的server-id
连接至主服务器,并开始复制
给大家介绍一下第一种基于binlog的主从同步方式:
首先是准备工作,创建三台机器。
![]()
在这里我将192.168.1.11作为主服务器,另外两台作为从服务器。然后都安装并且开启mysql服务.
[root@openEuler-1 ~]# yum install -y mysql-server
[root@openEuler-1 ~]# systemctl enable --now mysqld
由于三台虚拟机都是一样的操作,这里就不重复展示。
接下来就是对主服务器进行配置:
首先是设置唯一的server_id(建议用ip地址的最后三位):
[root@openEuler-1 ~]# vim /etc/my.cnf.d/mysql-server.cnf

以此为另外两台机子插入的数据是server_id=12(13)
然后查看主机的binlog:
mysql> show master status;
+---------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+---------------+----------+--------------+------------------+-------------------+
| binlog.000001 | 678 | | | |
+---------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)
这样主机就完成后了配置:
接下来我们对从库进行配置:


至此,我们对两台从库的配置已经完成。接下来看看是否配置成功。

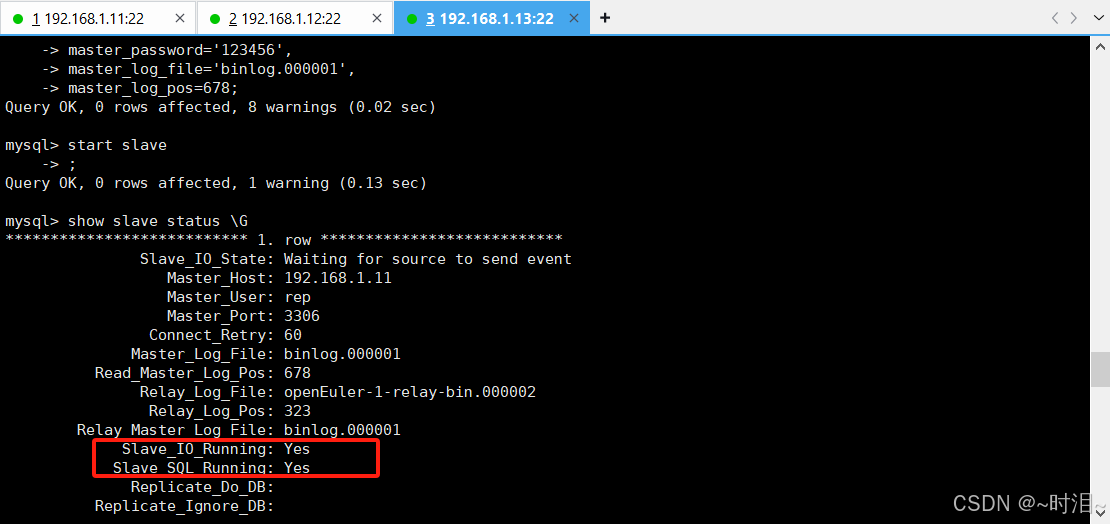
此时我们已经配置完成主从配置,接下来就是验证主从配置
在主机上创建一个数据库
mysql> create database db1;
Query OK, 1 row affected (0.01 sec)
在另外两台机子上查看


在主机的数据库中创建一个表并且插入内容
mysql> use db1
Database changed
mysql> create table t1(id int);
Query OK, 0 rows affected (0.01 sec)mysql> insert into t1 values(1),(2),(3),(4);
Query OK, 4 rows affected (0.03 sec)
Records: 4 Duplicates: 0 Warnings: 0
在另外两个机子上查看是否有数据


此时删除主机上的数据库
mysql> drop database db1;
Query OK, 1 row affected (0.01 sec)
在另外两台机子上查看是否还存在


可选配置
#[可选] 0(默认)表示读写(主机),1表示只读(从机)
read-only=0
#设置日志文件保留的时长,单位是秒
binlog_expire_logs_seconds=6000
#控制单个二进制日志大小。此参数的最大和默认值是1GB
max_binlog_size=200M
#[可选]设置不要复制的数据库
binlog-ignore-db=test
#[可选]设置需要复制的数据库,默认全部记录。
binlog-do-db=需要复制的主数据库名字
#[可选]设置binlog格式
binlog_format=STATEMENT至此,基于binlog建立主从同步的实验结束!
接下来介绍第二种,基于gtid的主从同步:
我们首先要两台从设备上一种模式的主从:如果不想停可以选择快照还原
mysql> stop slave;
Query OK, 0 rows affected, 1 warning (0.01 sec)
然后开启gtid(三台机器都是同样的操作):
[root@openEuler-1 ~]# vim /etc/my.cnf.d/mysql-server.cnf

开启之后需要重启服务
[root@openEuler-1 ~]# systemctl restart mysqld
然后开启从库配置:
开始前先停止slave在进行配置后再启动
第一种方法配置从库

第二种方法配置从库

之后在主库中新建一个库,对这个主从同步进行测试:
mysql> create database it;
Query OK, 1 row affected (0.00 sec)mysql> show master status;
+---------------+----------+--------------+------------------+----------------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+---------------+----------+--------------+------------------+----------------------------------------+
| binlog.000002 | 336 | | | 8d5f4996-e18e-11ef-9d13-000c29f250db:1 |
+---------------+----------+--------------+------------------+----------------------------------------+
1 row in set (0.00 sec)mysql> use it
Database changed
mysql> create table user(-> di int,-> name char(20)-> );
Query OK, 0 rows affected (0.02 sec)mysql> insert into user values(1,'alice'),(2,'bob'),(3,'tom');
Query OK, 3 rows affected (0.02 sec)
Records: 3 Duplicates: 0 Warnings: 0

 此时,两个从库都实现了同步试验成功。
此时,两个从库都实现了同步试验成功。
总结:相比于binlog方式,gtid方式更加简单,因为它不用查看binlog_file以及binlog_position.





