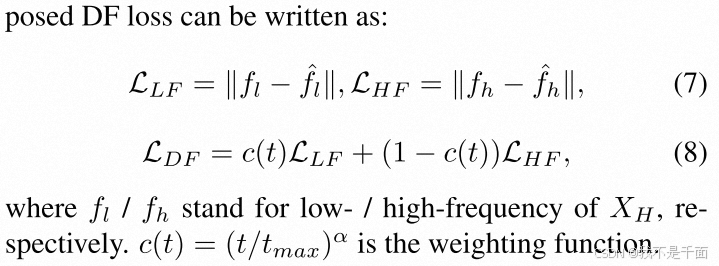目录
1. IP 协议简介
2. 首部属性
2.1 版本号
2.2 首部长度
2.3 服务类型
2.4 总长度
2.5 => 16位标识 & 3位标志 & 13位片偏移
2.5.1 => 16 位标识
2.5.2 => 3 位标志
2.5.3 => 13 位片偏移
2.6 生存时间(TTL)
2.7 => 8 位协议
2.8 首部校验和
2.9 源/目的 IP 地址
3. 地址管理
3.1 动态分配
3.2 NAT 机制 [主力方案]
3.2.1 NAT 网络地址映射
3.3 IPv6
3.4 网段划分
3.4.1 网络号和主机号
3.4.2 子网掩码
3.5 特殊的 IP 地址
4. 路由选择
1. IP 协议简介
IP 协议, 是网络层的协议, 和 TCP 一样, 也是 TCP/IP 协议栈的 "冠名协议" 之一. 同样, 其复杂程度和 TCP 差不多(都非常复杂).
但是作为 Java 程序员, 我们只需关注应用层和传输层即可, 对于网络层的 IP 协议, 我们了解即可. 所以本篇博客, 不会展开介绍 IP 协议的详细内容.
IP 协议 / 网络层, 主要的工作有以下两个:
- 地址管理: 通过 IP 地址, 来标识网络上的某个设备的位置.
- 路由选择: 在两个通信的节点之间, 规划出一条合理的路径.
2. 首部属性
IP 协议的报文格式如下:

2.1 版本号

虽然版本号有 6 位, 但是目前使用的 IP 协议版本只有两种:
- IPv4 [本篇讨论]
- IPv6 (近几年才多起来)
本篇讨论的均为 IPv4 协议.
2.2 首部长度

由于 选项 这一属性, 使得 IP 协议的首部长度也是可变的.
首都长度 一共有 4 位, 可表示的范围是 0 ~ 0xF, 依旧以 4 字节为单位, 故最大首部长度为 0xF(15) * 4 => 60 字节.
其中, 固定部分为 20 字节, 选项部分最多为 40 字节.
2.3 服务类型

服务类型这一属性, 决定了 IP 协议的工作方式.
8 位服务类型中, 其中 3 位优先权字段已经弃用, 还有 4 位 TOS 字段, 和 1 位保留字段(必须置为 0).
所以, 只有其中的 4 位 TOS 字段可供选择, 这 4 个字段分别为:
- 最小延时(从 A 到 B, 花费的时间最短)
- 最大吞吐量(从 A 到 B, 单位时间内传输的数据量最多)
- 最高可靠性(最大程度的降低丢包率)
- 最小成本(最大程度的减少系统开销)
并且, 这 4 个字段相互冲突, 只能选择其中一个.
也就是说, IP 协议可以通过设置服务字段中的值, 来切换工作状态, 来优先保证 4 个 TOS 字段中的其中一个性质.(就像迪迦一样, 可以切换速度状态和攻击状态)
2.4 总长度

这一属性, 是 IP 数据报的总长度: 报头 + 载荷.
总长度属性的长度为 16 位, 看到这里, 相信大家就有疑问了, 难道 IP 数据报最多也只能携带 2^16 - 1(65535) 个比特的数据(64KB)??
虽然一个 IP 数据报能携带的数据量有限, 但是, IP 协议内置了拆包组包的功能(不需要我们手动实现, 它内部就有). 比如: 如果有一个较大的 TCP 数据报, IP 协议就会自动把它拆成多个 IP 数据报, 通过多个 IP 数据报来共同传输一个 TCP 数据报.
2.5 => 16位标识 & 3位标志 & 13位片偏移

这三个属性, 就是为拆包组包而设定的.
2.5.1 => 16 位标识
标识相同, 表示同一组的数据
- 拆包: 把拆出来的多个包, 设为相同的标识
- 组包: 把相同标识的数据报, 组合到一起
2.5.2 => 3 位标志
共 3 个比特位, 各比特位含义如下:
- DF位(表示是否允许拆包): 1 => 允许分片/拆包; 0 => 不允许分片/拆包
- MF位(表示是不是最后一个包): 1 => "后面还有分片"; 0 => "这是最后一个分片"
- 保留位: 必须为 0
2.5.3 => 13 位片偏移
描述拆出的各个包的先后顺序.(偏移小的放前面, 偏移大的放后面)
讲到这, 就可以引申出一个面试题:
如果要基于 UDP 实现传输超过 64KB 的数据, 该如何设计??
- 思路: 参考 IP 协议的设计.
- 既然是基于 UDP, 那么传输层的数据包就是一个 UDP 数据包, 格式已经固定住了(就是 UDP 的格式). 那么我们只能在应用层协议中来设计: 指定标识, 指定标志位, 指定片偏移, 手动写代码来实现拆包组包的功能.
2.6 生存时间(TTL)

表示该 IP 数据包, 能够在网络上传输的最大时间(最大存活时间).
注意: TTL 的单位不是 "时间", 而是 "次数", IP 数据包每经过一次路由器转发, TTL 的值就会 - 1. 当 TTL 的值减到 0 时, 就说明该数据报无法到达目的地址, 就会被丢弃
那 TTL 的作用是什么呢??
- 比如目的 IP 设置错误时, 即使经过很多次的转发, 也一定不会到达目的地.
我们可以在 cmd 中通过 ping 命令来查看 TTL 值:

上图中 TTL 的初始值为 64, 经过了 11 次转发到达了搜狗服务器.
但是, TTL 的值并不是固定的, 当需要转发的次数较多时, TTL 可以初始化为更大的值: 128, ....

但是, 当地址等一系列信息都设置正确时, 数据报通过这些次数的转发, 就一定能到对端服务器上吗??
理论是可能存在到达不了的情况的, 但是可能性比较小.
- 因为, 网络中存在 "六度空间" 的理论, 即两台设备之间, 最多通过 6次 转发, 就一定能够到达对端.
啥是 "六度空间" 呢?? 举个例子:
- 比如我是一个普通程序员, 我想认识一下特朗普, 那么我就可以向我所有的朋友发起请求, 问问他们认不认识特朗普, 如果他们不认识, 再让他们去问问他们的所有的朋友.......
- 理论上, 最多通过六层朋友的询问, 我就能认识到特朗普~~ (前提是, 每一层朋友都必须竭尽全力)
在实际生活中, 是很难完成每一层的朋友都竭尽全力的.
但是在网络上, 每个路由器都可以发动他们所有相邻的设备, 于是 "六度空间" 这样的理论是非常可靠的.
2.7 => 8 位协议

标识传输层使用的哪个协议.
分用的使用, IP 协议解析完 IP 数据报头后, 拿到载荷, 交给上层处理. 这里的 8位 协议编号, 就能够起到区分的作用.(交给上层的哪个协议)
2.8 首部校验和

校验 IP 数据报 报头部分的信息是否正确. (不用校验载荷, 载荷部分自有 TCP/UDP 来校验)
2.9 源/目的 IP 地址

这是 IP 协议最重要的部分, 用来标识 源设备和目的设备.
由于 IP 地址由 32 位二进制数构成, 而 32 位不方便阅读, 所以采用 点分十进制 的方式来表示 IP 地址.
![]()
3. 地址管理
我们希望 IP 地址用来表示唯一的主机, 而 32 位 IP 地址最多只能表示 42亿9千万 个不同的 IP, 在 15 年前还好, 但是在 2025 年的今天, 这个数字显然早就不够用了...
那么, 是怎样处理 IP 不够用的情况的呢??
- 动态分配: 仅对上网的设备分配, 不上网就不分配.(有所缓解, 但治标不治本, 没有从根本上解决问题)
- NAT 机制: 网络地址转换 [主力方案]
- IPv6 [终极方案]
当前的网络世界, 就是通过 NAT 机制来解决 IP 不够用的问题的.
3.1 动态分配
动态分配: 仅对上网的设备分配 IP 地址, 不上网就不分配.
只是权宜之计, 治标不治本.
3.2 NAT 机制 [主力方案]
那么, NAT 机制的具体实现是怎样的呢??
首先, 把所有的 IP 分成两个大类:
- 公网 IP / 外网 IP
- 私网 IP / 内网 IP
其中, 公网 IP 是唯一的.
而私网 IP 在不同的局域网中, 可以重复. 以下特定的 IP 地址, 为私网 IP:
- 10.*
- 172.16 - 172.31.*
- 192.168.*

有了以上知识的了解, 我们接下来聊一聊在 NAT 背景下, 网络通信是如何进行的:
- 情况1: 同一个局域网下, 设备 A 访问设备 B ??
答: 允许访问.
在一个同局域网下, IP 本身就不允许重复, 故通信时不受任何影响, 且 NAT 不起作用, A 和 B 就能正常通信.
- 情况2: 公网设备 A 访问公网设备 B ??
答: 允许访问.
公网 IP 本身也不允许重复, 故通信也不受影响, 且 NAT 不起作用, A 和 B 就能正常通信.
- 情况3: 局域网设备 A 访问局域网设备 B ??(不同局域网下)
答: 不允许访问!! NAT 是禁止这样的方式来访问的.
为啥在不同局域网下的两条设备不允许访问呢??
举个例子: 比如我们之前写的 TCP/UDP 回显服务器系统, 我们只能在本机上进行访问, 而别人是无法访问的.
这是因为我们写的服务器的 IP 地址(我们电脑的 IP 地址)是一个内网 IP, 而这个内网 IP 在世界上存在着无数多个, 当目的 IP 的存在不唯一时, 数据包就是不知道要发给谁了, 当然也就无法访问目标设备了~
把我们的电脑设置为内网 IP 的作用是什么??
- 其实, 内网 IP 这样的限制, 是对我们的设备进行了保护. 虽然其他人无法访问我们的设备, 但是黑客也无法访问了~
- 而如果将我们的电脑设置为公网 IP, 那么任何人都可以访问我们的设备, 这显然存在安全问题.
- 情况4: 局域网设备 A 访问公网设备 B ??
答: 允许访问. 使用 NAT 网络地址映射进行访问.
- 情况5: 公网设备 A 访问局域网设备 B ??
答: 不允许访问!! 除非通过内网穿透或者 VPN(虚拟私人网络) 等特殊手段. (只能局域网设备主动访问外网设备, 外网设备被动返回响应. 但是外网设备不能主动访问局域网设备)
"内网设备" 可以近似认为处于局域网中, 局域网中的设备具有内网 IP.
"公网设备" 可以近似认为处于广域网中, 广域网中的设备具有公网 IP.
3.2.1 NAT 网络地址映射
那么, 在情况4下(局域网设备 A 访问公网设备 B), NAT 是如何进行网络地址的映射的呢??
假如我的电脑是局域网设备 A, 要访问 MDD 的服务器(公网设备 B), 在请求的传输过程中, 会通过带有公网 IP 的路由器的转发(该路由器具有 NAT 功能).
在路由器转发时, 路由器就会进行 NAT 网络地址的替换: 将请求 IP 数据报中的源 IP(设备 A 的内网 IP)替换为该路由器的公网 IP, 替换完后, 此时数据包中的源 IP 是路由器的公网 IP, 目的 IP 是 MDD 的公网 IP, 都是公网 IP, 就可以进行通信了.
并且, 路由器在进行 NAT 网络地址替换的时候, 会维护一个类似于 "哈希表" 的结构, 将地址替换前后的映射关系记录下来, 这张表称为 NAT 表.
注意: NAT 表中映射的信息不单单是 IP 之间的信息, 而是 IP 和端口号共同组成的信息.(以便给多台设备返回响应时, 能够找到对应的内网 IP)
所以, 公网设备 B 返回的响应报文中的目的 IP 也是该路由器的公网 IP, 而当该响应到达该路由器后, 该路由器会根据 NAT 表中 IP 地址和端口号的信息, 找到对应的内网 IP(局域网设备 A 的内网 IP), 再次进行替换, 将目的 IP(路由器的公网 IP)替换为原先的内网 IP, 最终达到局域网设备 A.
流程图如下:

注意: 数据报在传输的过程中, 是会经过多个 NAT 设备的转发的, 但不一定就会触发 NAT, 只有当 IP 数据报中的源 IP 是内网 IP 时, 才会触发 NAT.
(若是源 IP 是公网 IP, 则说明已经进行了 NAT 替换, 将不会再次触发 NAT)
该路由器中维护的 NAT 表如下:

因此, 局域网中的若干个设备, 共同使用一个公网 IP, 这样可以大大减少 IP 的使用量, 解决了 IP 地址短缺的问题.
(并且现实中, 往往是成千上万个局域网设备共用一个外网 IP).
3.3 IPv6
除 NAT 方案以外, 还有一个终极方案能够解决 IP 地址短缺的问题 --- IPv6.
IPv4 是 4 个字节, 而 IPv6 直接升级到了 16 个字节(128 bit), 能够容纳 2^128 个不同的 IP 地址.
大家可能对 2^128 不敏感, 举个例子, 就算给地球上的每一粒沙子都分配一个 IPv6 地址, 都绰绰有余!!
但是, 目前 IPv6 在世界上的普及成都非常非常的低, 而我国是 IPv6 普及程度最高的国家(没有之一, 约 80% 的覆盖程度).

为啥, IPv6 能够容纳这么多的地址量, 但普及程度这么低呢??
因为 IPv4 换 IPv6 的成本很高, 需要换路由器, 要花很多钱~ 而 NAT 只需升级软件即可, 成本低, 所以 NAT 是目前世界上解决 IPv4 地址短缺的主流方案.
既然 NAT 是主流方案, 那为啥咱国使用 IPv6 呢??
这就上升到国家战略上了, 感兴趣可以观看以下视频.
电子监听、全国断网,棱镜门背后,中国如何从末路狂奔到世界之巅_哔哩哔哩_bilibili
3.4 网段划分
解决完 IP 地址不够用的问题后, 接下来介绍一下 IP 地址中的网段划分规则.
"网段划分" 主要应用于组建网络环境.
3.4.1 网络号和主机号
网段划分, 就是将一个IP 地址划分为两个部分:
- 网络号(前半部分)
- 主机号(后半部分)

假如有两台设备:
- 如果在同一个局域网中, 网络号必须相同, 主机号必须不同.

- 如果是在两个相邻的局域网中, 网络号必须不同, 主机号无要求. (如果手动把两个相邻局域网的 IP 网络号设置成一样的, 那么就会导致网络冲突, 网络不通)

路由器具有两个接口(WAN 口和 LAN 口) , 这两个接口有着不同的 IP, 并且处于不同的局域网中, 路由器的功能就是把这两个局域网连接起来, 这样就构成了两个相邻的局域网, 并且他们的网络号必须不同.

3.4.2 子网掩码
对于当前的时代来讲, IP 地址中哪些是网络号, 哪些是主机号, 都是可以手动配置的(不固定).
那么, 给我们一个 IP 地址, 我们该如何判断哪些是网络号, 哪些是主机号呢??
这就需要用到子网掩码了, 子网掩码中, 数值为 1 的部分为网络号, 数值为 0 的部分为主机号:

家用网络的子网掩码一般都为: 255.255.255.0
也可以将 IP 地址写为: 192.168.1.6/24 (表示前 24 位为网络号)
子网掩码, 是当前时代网段划分的方式.
而在 "远古时期" 的分类编址方式下是没有子网掩码的(它明确规定了哪些位是网络号, 哪些位是主机号):(开发中用不到, 学校考试会考~)

3.5 特殊的 IP 地址
有以下三种特殊的 IP 地址:
- IP 地址中的主机号全部设为 0 时, 表示当前局域网的网络号, 代表这个局域网 => 192.168.1.0
- IP 地址中的主机号全部设为 1 时, 表示广播地址 => 192.168.1.255
- 127.* 的 IP 地址表示环回 IP, 用于测试, 习惯上通常为 127.0.0.1 (不管你本机的真实 IP 为多少, 127.0.0.1 都可以代表本机)
啥叫广播地址呢??
上面说了, 主机号全为 1 时, 为广播地址.
当一个数据报的目的地址为广播地址时, 就会给所在局域网中所有的设备都发送该数据报.
举个例子:
当我们使用手机往电视上投屏时, 手机就会搜索所有能够投屏的设备(前提是在同一个 WiFi 下, 也就是同一个局域网中), 然后我们就可以选择我们想要投屏的设备了.
这里手机搜索的过程, 就是在向局域网中的设备发送广播地址的请求, 询问哪个设备能投屏.
注意: 广播地址只能通过 UDP 来进行传输, TCP 是不能广播的.
除了上述的特殊 IP 之外, 我们还有一个习惯用法:
- 将主机号设为 1, 表示网关 IP => 192.168.1.1 (只是习惯用法, 并非强制)
网关, 就是网络的出口/入口.
家庭中, 网关就是指路由器; 大型企业/网络结构 中, 网关通常是单独的设备.
4. 路由选择
路由选择是 IP 协议的第二个主要工作, 就是通过 IP 协议, 进行数据的转发工作.
路由器的路由选择, 采用的是 启发式/探索式 的方式, 简单来说就是 "问路的方式".
什么是 "问路的方式" 呢??
举个例子:
我要去一个很远的地方(假设没有导航), 我不知道咋走, 我就会向别人问路, 而由于路程太复杂了, 我一下子记不住咋走, 所以每次我只能记住一点, 而每到一个地方我就会再问路, 一点一点的接近目的地.
路由器的路由选择也是一样的, 由于网络上的情况太复杂了, 路由器无法一下存储所有的网络信息, 只能记住和它相连的网络的情况.
而当数据报到达一个路由器时, 就会去匹配这个路由器的 "路由表"(路由表中记录了该路由器周围设备的 IP, 以及每台设备要从路由器的哪个接口转发出去):
- 如果该数据报的目的 IP 在路由表中有记录, 则直接按照对应的接口的转发出去
- 如果目的 IP 没有在路由表中记录, 则会将该数据报转发给路由表中 "下一跳" 指向的设备("下一跳" 是路由表中的特殊表项, 指向的是上一级路由器所在的位置)
路由器越往上, 涵盖的范围就越广, 存在数据报目的 IP 的记录的概率就越大.
注意: 在路由表中进行 IP 地址的匹配时, 匹配的不是精确相等, 而是 IP 的部分网段.

至于路由表是咋来的, 路由表的具体内容是啥, 以及路由表背后广域网的网络架构是啥, 作为 Java 开发来讲就不必深入学习了(本篇文章仅为简单讨论)~
END