大数据的尽头是数据中台吗?">大数据的尽头是数据中台吗?
2018年末开始,原市场上各种关于大数据平台的招标突然不见,取而代之的是数据中台项目,建设数据中台俨然成为传统企业数字化转型首选,甚至不少大数据领域的专家都认为,数据中台是大数据的下站。
为啥数据中台是大数据的下站?与数仓、数据湖、大数据平台啥区别?来深入大数据发展史,先从数仓出现讲起,途径数据湖,再到大数据平台,这样才能理解大数据发展的每阶段的问题,深入理解数据中台在大数据发展中的历史定位。
1 数据仓库
BI诞生在1990s,将企业已有数据转化为知识,帮企业经营分析决策。如零售行业门店管理,如何使单门店利润max,就要分析每个商品的销售数据和库存信息,为每个商品制定销售采购计划:
- 有的商品存在滞销,应该降价促销
- 有的商品比较畅销,要根据对未来销售数据的预测,提前采购
都离不开大量数据分析。
而数据分析需聚合多个业务系统的数据,如集成交易系统、仓储系统的数据,同时需保存历史数据,进行大数据量的范围查询。传统DB面向单一业务系统,主要实现面向事务的增删改查,已不满足数分场景,于是催生数据仓库。
1991年出版的《Building the Data Warehouse》中,数据仓库之父比尔·恩门(Bill Inmon)首次给出数据仓库完整定义:
数据仓库是在企业管理和决策中面向主题的、集成的、与时间相关的,不可修改的数据集合。
1.1 深入理解数据仓库四要素-电商案例
电商有:
- DB专门存放订单数据
- 另一DB存放会员相关数据
构建数仓
先要把不同业务系统的数据同步到一个统一的数仓,然后按主题域方式组织数据。
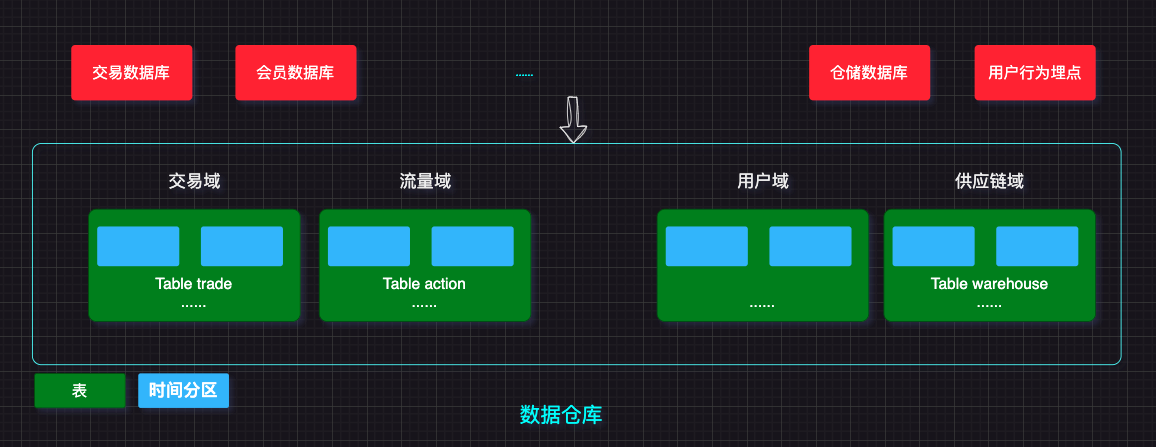
1.1.1 主题域
业务过程的一个高层抽象,像商品、交易、用户、流量都能作为一个主题域,可理解为数仓的一个目录。数仓中的数据一般按时间进行分区存放,一般保留5年以上,每个时间分区内的数据追加写,对某条记录不可更新。
1.1.2 设计方法
他和金博尔(Kimball) 共同开创的数仓建模的设计方法,对后来基于数据湖的现代数仓设计有重要意义。
自顶向下
恩门的建模方法,顶指数据来源,在传统数仓就是各业务DB。
基于业务中各实体及实体之间的关系,构建数仓。
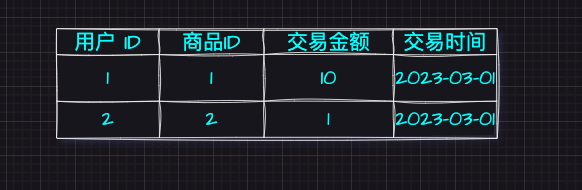
如买家购买商品,先要理清业务过程涉及的实体。
买家、商品是一个实体,买家购买商品是一个关系。得到如下模型:
买家表:

商品表:

买家商品交易表:
自底向上
金博尔建模与恩门正相反,从数据分析的需求出发,拆分维度和事实:
- 用户、商品就是维度
- 库存、用户账户余额是事实
对应刚才完全一样的表,分别叫:
- 用户维度表
- 商品维度表
- 账户余额事实表
- 商品库存事实表
对比
恩门建模从数据源开始构建,构建成本较高,适用应用场景较固定的业务,如金融领域,冗余数据少是优势
金博尔建模从分析场景出发,适用变化速度较快的业务,如互联网业务。现在业务变化都快,更推荐金博尔建模法
传统数仓,第一次明确数分的应用场景应该用单独的解决方案去实现,不再依赖业务DB。模型设计上,提出数仓模型设计的方法论,为后来数分的大规模应用奠定基础。但互联网时代后,传统数仓没落,互联网技术催生大数据时代。
2 从Hadoop到数据湖
进入互联网的
2.1 重大变化
数据规模空前
一个成功的互联网产品日活过亿,抖音每天产生几千亿用户行为。传统数仓难扩展,无法承载如此规模海量数据
数据类型变得异构化
互联网数据来自:
- 业务DB结构化数据
- App、Web前端埋点数据或业务后端埋点日志,这些数据一般是半结构化甚至无结构。传统数仓对数据模型有严格要求,在数据导入数仓前,数据模型须事先定义好,数据须按模型设计存储
所以,数据规模和数据类型的限制,导致传统数仓无法支撑互联网BI。
谷歌互联网巨头率先开始探索,2003年开始,先后发表论文:
- 《The Google File System》
- 《MapReduce:Simplified Data Processing on Large Clusters》
- 《Bigtable:A Distributed Storage System for Structed Data》
奠定现代大数据技术基础。提出新的,面向数分的海量异构数据的统一计算、存储方法。
2005年Hadoop出现,大数据技术才普及。Hadoop是论文的开源实现
2.2 Hadoop V.S 传统数仓
- 完全分布式,易扩展,可用价格低廉机器堆出计算、存储能力强的集群,满足海量数据处理要求
- 弱化数据格式,数据被集成到Hadoop后,可不保留任何数据格式,数据模型与数据存储分离,数据在被使用的时候,可按不同模型读取,满足异构数据灵活分析需求
随Hadoop成熟,2010年,Pentaho创始人兼CTO James Dixon在Hadoop World大会提出
2.3 数据湖(Data Lake)
以原始格式存储数据的存储库或系统。数据湖是Hadoop从开源走向商业化成熟的标志。企业可基于Hadoop构建数据湖,将数据作为企业核心资产。
但一个商用Hadoop包含20多种计算引擎, 数据研发流程多,技术门槛限制Hadoop商用化。如何让数据加工像工厂,直接在设备流水线完成?
大数据平台">3 数据工厂:大数据平台
3.1 数据开发流程
- 先将数据导入大数据平台
- 再按需求进行数据开发
- 开发完成后,数据验证比对,确认是否符合预期
- 把数据发布上线,提交调度
- 日常任务运维,确保任务每日能够正常产出数据
若无高效平台,就跟写代码没有IDE,别人完成十个需求,你一个需求都完成不了。
大数据平台就是为提高数据研发效率,降低数据研发门槛,让数据在一个设备流水线快速完成加工。
大数据平台面向数据研发场景,覆盖数据研发的完整链路的数据工作台

大数据平台使用场景">3.2 大数据平台使用场景
- 数据集成
- 数据开发
- 数据测试
- 发布上线
- 任务运维
大数据平台使用对象是数据开发。大数据平台底层以Hadoop为代表的基础设施,分为计算、资源调度和存储。
大数据计算引擎">3.3 大数据计算引擎
- Hive、Spark解决离线数据清洗、加工。Spark用得越来越多,性能比Hive高不少
- Flink解决实时计算
- Impala解决交互式查询
这些计算引擎统一运行在Yarn,Yarn分配计算资源。也有基于k8s实现资源调度,如Spark版本(2.4.4)能运行在k8s管理的集群,可实现在线和离线的资源混合部署,节省机器成本。
3.4 数据存储
- HDFS 不可更新,主要存全量数据
- HBase提供了一个可更新的KV,主要存一些维度表
- ck/Kudu 提供实时更新,一般用在实时数仓的构建场景中
大数据平台像一条设备流水线,经过大数据平台的加工,原始数据变成了指标,出现在各个报表或者数据产品中。随着数据需求的快速增长,报表、指标、数据模型越来越多,找不到数据,数据不好用,数据需求响应速度慢等问题日益尖锐,成为阻塞数据产生价值的绊脚石。
4 数据中台(数据价值)
2016年前后,互联网高速发展,对数据需求越来越多,数据应用场景也越来越多,大量数据产品进入运营日常工作,成为运营工作。电商业务有供应链系统,会根据各个商品的毛利、库存、销售数据以及商品的舆情,产生商品的补货决策,然后推送给采购系统。
4.1 大规模数据的应用暴露问题 - 数据割裂
不敢用数据
业务发展前期,为快速实现业务,烟囱式开发导致企业不同业务线,甚至相同业务线不同应用数据都割裂。两个数据应用的相同指标,展示结果不一致,导致运营对数据信任度下降。如你是运营,当你想看一下商品的销售额,发现两个报表都叫销售额的指标出现两值,第一反应数据算错,不敢用这数据。
大量重复计算、开发
导致的研发效率的浪费,计算、存储资源的浪费,大数据的应用成本越来越高。
- 运营想要一个数据时,开发说至少一周,能不能快?
- 数据开发面对大量需求,抱怨需求太多,干不完
- 老板看到每月账单成指数级增长,觉得这也太贵,能不能再省
这些问题根源是
4.2 数据无法共享
2016年,阿里巴巴提“数据中台”。数据中台的核心,是避免数据的重复计算,通过数据服务化,提高数据的共享能力,赋能数据应用。
- 之前,数据是要啥没啥,中间数据难于共享,无法积累
- 建设数据中台之后,要啥有啥,数据应用的研发速度不再受限于数据开发的速度,一夜就可根据场景,孵化出很多数据应用,这些应用让数据产生价值
5 总结
- 数据中台构建于数据湖之上,具备数据湖异构数据统一计算、存储的能力,同时让数据湖中杂乱的数据通过规范化的方式管理起来。
- 数据中台需要依赖大数据平台,大数据平台完成了数据研发的全流程覆盖,数据中台增加了数据治理和数据服务化的内容。
- 数据中台借鉴了传统数据仓库面向主题域的数据组织模式,基于维度建模的理论,构建统一的数据公共层。
数据中台:
- 吸收传统数仓、数据湖、大数据平台优势
- 又解决数据共享的难题,通过数据应用,实现数据价值落地
- 传统数据仓库,第一次明确数据分析的应用场景应该用单独的解决方案去实现,不再依赖业务数据库。在模型设计,提出数据仓库模型设计的方法论,为后来数据分析的大规模应用奠基
- 互联网产品的新特性:数据多、数据类型异构
- Google论文指导下的开源项目Hadoop采用分布式、弱化数据格式,来应当面临的问题
- 数据湖(Data Lake)是一个以原始格式存储数据的存储库或系统
- 大数据平台是面向数据研发场景的,覆盖数据研发的完整链路的数据工作台
- 数据中台的核心,是避免数据的重复计算,通过数据服务化,提高数据的共享能力,赋能数据应用
FAQ
数据中台的尽头是啥?
AI中台。机器学习是数据中台之上一个重要的应用领域。数据和特征决定了机器学习上限,算法和模型只是在无限逼近该上限。目前数据中台的主要应用领域还是数据智能领域,所以先不延申到机器学习,深度学习,安全、推荐等领域。
- 实时数据中台,实现批流一体
- 云上数据中台,全面拥抱K8S,实现在线、离线混合部署,进一步提高资源利用率
- 智能元数据管理+增强分析,降低数据分析的门槛,进一步释放数据智能
- 自动化代码构建,通过拖拉拽,自动化生成ETL代码的构建,进一步释放数据研发的效能,甚至让我们的非技术人员都可以完成简单的数据加工
- 数据产品的时代,面向各种行业的数据产品全面涌现,并且和中台系统联动,比如基于指标的可分析维度,自动进行指标的业务诊断等等
数据中台能看到的趋势:
可视化建模与SQL建模,不管是在建设数据中台或数据平台,这都是一种抽象、流程化的体现,大大降低数据开发成本而且清晰。不过复杂度确实高
流批一体。降低大数据架构的整体运维成本
上云。节约成本,提高资源利用率。当数据中台发展到一定程度时,数据中台或数据平台会不会成为云上的基础服务?对于中小型企业而言,建设一套这样的平台成本太大,但是通过云服务提供平台基础设施与计算能力,企业就能把资源集中于对企业内部数据价值的挖掘上面?
云上数据中台,我认为这一定是个趋势,所以我在数据中台下一站中,特意提到了云上数据中台的建设,目前数据中台是基于Hadoop体系的数据湖构建的,Hadoop是基于Yarn实现资源的调度,这与在线业务系统基于Kubernates实现的云原生是两套,我认为,后续在线和离线会统一,kubernates会成为事实的统一云,然后大数据基于kubernates实现资源调度,事实上,Spark新版本已经实现了。
公有云还是私有云。因为数据中台中的数据,往往很多涉及企业的核心机密,比如一些毛利、营业额、供应商对于企业来说,都是核心资产,企业愿不愿意,敢不敢,把数据放在公有云上,这个在国内还不好说。很多数据都要求私有化部署。
那么到时候企业对数据工程师能力要求侧重哪?是数据分析与数据挖掘的能力吗?还是说数据平台的建设与维护的能力也是很必要的一个技能?
未来,不管是私有化部署的云,还是公有云,企业都不会关注在数据平台的建设和维护能力上,因为这部分容易被标准化,而且可能后续价格会很低廉,完全没必要企业自己去搞。我觉得后续企业,还是会更强调数据的应用能力,数据如何深入业务,解决业务的问题。
Q:特征工程、AI都是数据中心较上层的应用,通过特征工程与AI计算出的模型,反馈作用于下层的ETL数据处理形成闭环,可行?
机器学习是数据中台的一个上层应用场景,至于通过模型反馈于下层的ETL数据处理,怎么反馈?如从模型设计角度,肯定可以,因为机器学习相当需求方,数据模型的设计肯定要满足需求方。但说如何基于上层模型,自动构建下层的ETL任务,目前还不成熟,可行方式是通过可视化降低开发工作量。
Q:金博尔建模设计方法的例子里面没有提到商品交易的信息,只有用户余额和库存事实表,why?
kimball建模只有事实和维度, 交易过程中涉及账户余额和库存,这都属于事实,而维度就是商品。从分析的角度,我们只关心事实在不同维度下的结果。而在商品交易中,我们需要分析的交易金额和账户余额,这都呈现在用户账户余额事实表中,只要在这个表中再关联商品的维度,就可以按照商品来分析,一个商品的交易金额。
如余额事实表中,再增加一列代表商品的ID,每一个交易,都占用一行,代表交易完成后,用户余额和交易金额的数据。就能实现从商品维度分析交易金额的需求。
传统企业是数据容量和类型是比较固定的,以前也有了数据仓库的应用,在什么场景下需要演建设数据中台?如果要建,是否须基于hadoop类大数据平台?
数据中台一定构建在数据湖之上,与传统数据仓库基于Oracle构建有本质区别。
原先数据仓库只支持简单报表,对数据加工和处理能力有限,没法支撑大规模数据应用场景。想实现数字化转型,真正让数据走入业务,让业务人员每天看数据工作,就要构建数据中台。
如零售客户构建数据中台,然后在上面做门店管家,数据应用,现在他们全国2W多家门店,每天都有大量店员在看,有哪些商品卖好,哪些卖不好,哪些商品库存大,客户比较偏好买哪些商品,然后有针对推荐商品或调整商品摆位。大幅度提高门店营业收入,这就是典型数据中台应用。
OLAP在OLTP后出现,Big Data又之后,中台体现分析时还有共享,hadoop资源损耗国内DB界一直有争议。如不同类型数据系统之间,其实都是明显的有相互学习和继承。 中台体现的数据的集中、大数据体现的分散且快;那么下一步将是再次的分散。这就如同人的行走:不可能全是之路,一本资料提出岛与海,它的上一页就是Data laker。 中台的方式方法正在摸索和打造:不过和DataSystem在中间件存储的选择不同;仿佛SRE和DevOps都是效率,可是何种是正解;每个企业应当都有自己答案。为了中台而中台就失其原本意义。数据中台要从解决问题的角度入手,不能解决问题,建中台意义就不大。
下一站是数据应用平价、爆发式的增长。数据中台仿佛是进化版的BI,传统BI采用传统的数仓设计方法,现在中台数仓设计更强调快速响应业务变化,数据研发更快速实现,更强调带来业务价值。下一站应该是数据产品的全面爆发。
数据湖 V.S ODS层数据
没啥关系,数据湖不仅有ODS,还有DWD,DWS,DM,ADS数据。数据湖指数据不管存储格式,都统一存储在一起,然后根据数据格式,读取数据,如Hadoop可看成数据湖实现。
ODS是数据分层的原始数据层,和其他层数据一样,可存储在HDFS构建的数据湖。
- 数据中台发展方向的批流一体典型代表Apache Beam,统一编程模型运行在Spark、Flink等多个引擎。批流一体构建实时数据中台
- 另一方向是多维度数据管理,典型代表Apache Kylin,构建星型或雪花数据模型以支持多维度查询操作。但需要预计算,随着多维分析引擎的性能越来越强,有可能会被取代。
- Beam关注如何高效把多个数据源数据归一,Kylin关注如何为归一后的数据建模。两者在数据处理流程上是前后关系
假设OLTP够强大,计算资源够,未来的实时分析能完全实现,数据中台会消失?取之以一种新的概念,就像数仓融进数据中台。
HTAP概念这么久,但HTAP始终对大数据量分析还是不行。至于最早提出HTAP的TIDB也实现列存的副本,用于OLAP查询。
数据中台下一站,取决于数据中台本身存在什么瓶颈,缺陷,制约了快速响应需求。流批统一,云上大数据平台,可视化开发,可视化的AI平台,但感觉没质变化,只是术变,不像大数据技术出现对数据分析冲击大。
不管是实时数据中台还是自动化ETL,都可以说是数据中台的进一步发展。说质变,我想增强分析和智能元数据管理或许是,只是时机不够成熟。如果以后可实现智能分析,你问它,为什么销售额下降,它可以直接告诉你原因,是不是够牛?
数据中台的下一站应该是对数据中台的可视化操作技术。产品经理直接拖拉数据中台中的组件即可以构造出用户满意的产品。技术还是难。
虽然你的描述有点超前,但是方向是对的,我称之为自动化代码构建的能力,就是对于一些分析师、运营,我们也可以具备一些数据加工能力。
弱化数据格式,数据被集成到 Hadoop 之后,可以不保留任何数据格式,数据模型与数据存储分离,数据在被使用的时候,可按照不同的模型读取,满足异构数据灵活分析的需求。
拿Hive举例。Hive支持location到一个目录。即数据可先存储在HDFS的一个目录,然后再建立Hive表。这样其实Schema和底层的数据实际是分离的。然后我们在用Hive读这个数据的时候,其实是根据hive中定义的表结构去读的,如果有一部分的数据字段hive中没有定义,那其实是读不出来的。
通过Hive的例子,你明白了嘛?可以具体再用hive 实践一下。
以云计算为基础,包括数据在内的各种资源能力的虚拟化资源服务生态环境体系。一切资源与能力皆服务,一切个体皆终端。会呈现“接入即获取,变更即享受”的社会化资源服务生态。
level很高,对数据应用来说,数据中台彻底解决了数据应用研发速度受限数据研发速度的问题。
运算中台,阿里之前提到过以计算代替存储。随着数据重复化的减少,数据服务的增加,往往不再需要“大”数据来满足业务需求,数据业务精简化,小型化,碎片化就跟微服务一样,定制计算模块能够更加快速的应对复杂业务的需要。
数据中台 V.S 数据仓库
数据中台相比传统数仓:
- 首先构建于数据湖之上
- 其次强调数据复用性,强调数据只加工一次,避免烟囱开发
- 最后,强调数据通过服务化的方式,实现数据应用和数据中台数据的打通
数据中台与数据仓库的联系,可以认为数据中台继承了数据仓库中维度建模的设计方法。
中台如何赋能数据应用?
数据中台在数据研发效率、数据发现效率、取数效率和数据分析效率都得到全面的提升,原先一个数据应用需求,最少需要一周研发时间,而现在可以缩短到2-3天,这样就大幅提高了数据应用的迭代速度,使得数据应用的迭代速度不再受制于数据开发的速度。
如何实现数据共享?
这问题分为两个:
- 数据的共享
- 接口的共享
原先我们存在很多分散的小数仓,同一个小数仓内,也按照应用,呈现烟囱式数据加工。但现在有个统一的数据中台,构建的是一个统一的数据中台,所以要实现模型复用,强调相同粒度的事实只加工一次。并且在模型设计度量中,也引入模型引用系数,作为衡量模型复用的度量,以推动大家尽量复用数据。
数据复用前提还依赖高效的数据发现,得快速找到数据,理解数据,与元数据管理息息相关。接口层复用是通过数据服务实现。
获取更多干货内容,记得关注我哦。
本文由博客一文多发平台 OpenWrite 发布!





