一、前文回顾 🔍
在前面的ELK系列中,我们已经搭建了ELK的核心组件,包括:
- ELK系列-(一)Docker部署ELK核心组件
- ELK系列-(二)LogStash数据处理的瑞士军刀
- ELK系列-(三)Kibana 数据可视化的艺术家
- ELK系列-(四)轻量级的日志收集助手-Beat家族
- ELK系列-(五)指标收集-MetricBeat(上)
有关整个系统架构的部署,您可以回顾前面的文章。今天,我们将继续探讨如何将指标数据通过MetricBeat进行采集并传输到ELK。 🚀
尤其是带有新方法哦:MetricBeat如何采集显卡数据!全网都少见相关的攻略!
系统架构图 📊

本篇内容:指标收集(MetricBeat) 📈
完成了上一篇的安装和基本使用之后,我们要做一些特殊的准备,更好地接入ELK。 💡
💥 还不清楚Beat家族的朋友,快回第四篇看一眼哦!
二、System参数调整 🔧
system模块采集默认是打开的,为了适应当前的监控需要,我们需要:
- 关注磁盘占用 💽
- 降低采集间隔 ⏱️
- 去除不必要的采集项 🧹
调整System监控目标 🎯
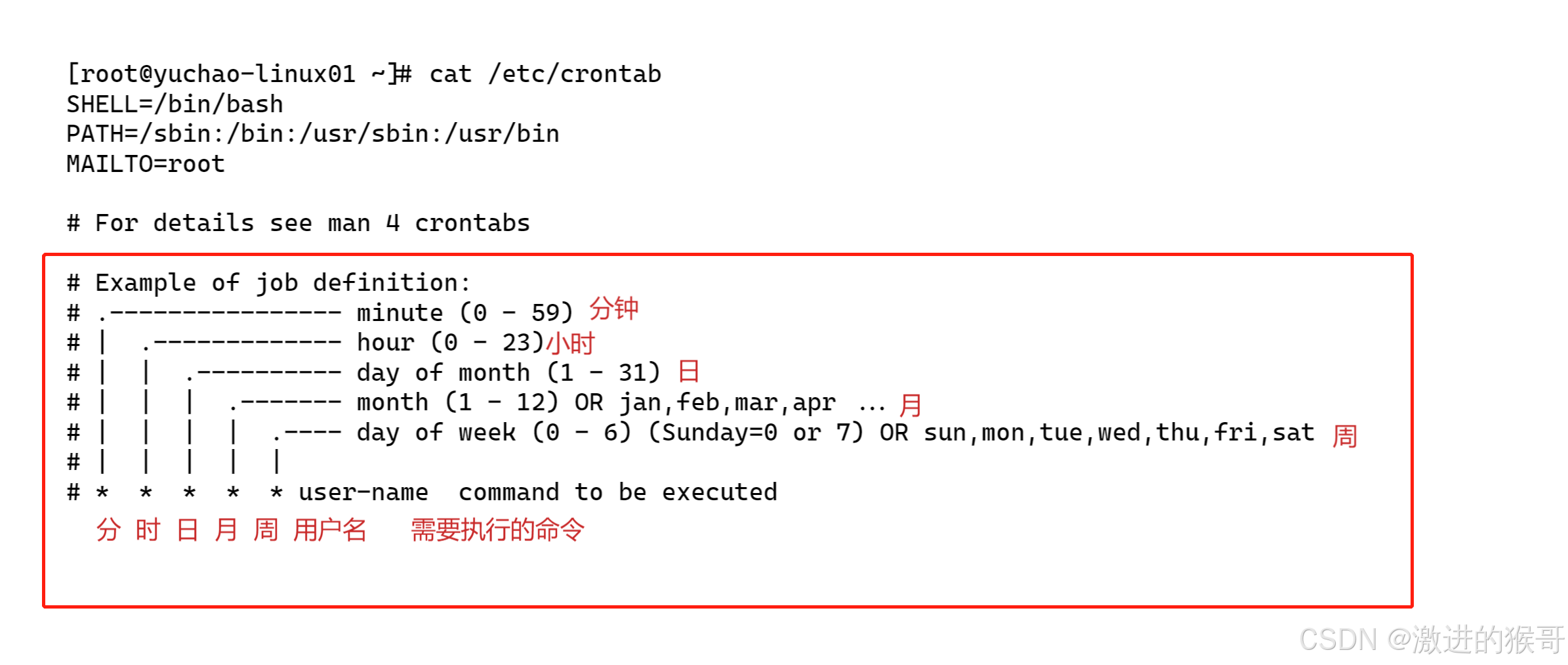
编辑配置文件:
sudo vim /etc/metricbeat/modules.d/system.yml
修改配置如下:
# 模块: system
# 文档: https://www.elastic.co/guide/en/beats/metricbeat/main/metricbeat-module-system.html- module: systemperiod: 10s # 采集数据的时间间隔为10秒metricsets:- cpu # CPU使用情况- load # 系统负载信息- memory # 内存使用情况- network # 网络流量信息- process # 进程信息- process_summary # 进程摘要信息process.include_top_n:by_cpu: 5 # 根据CPU使用率包含前5个进程by_memory: 5 # 根据内存使用率包含前5个进程- module: systemperiod: 10m # 采集数据的时间间隔为10分钟metricsets:- fsstat # 文件系统统计信息processors:- drop_event.when.not.regexp:system.filesystem.mount_point: '^/$' # 只保留挂载点为 / 的文件系统事件- module: systemperiod: 15m # 采集数据的时间间隔为15分钟metricsets:- uptime # 系统运行时间
三、开启GPU指标收集 💻
在现代计算环境中,GPU监控变得越来越重要!但是Metricbeat竟然没有原生支持,经过深入探索,我找到了一个绝佳解决方案。
其原理是使用DCGM采集数据,最后将数据伪装为Promethues的格式,MetricBeats通过采集Promethues数据采集到显卡数据
(一)、安装数据中心管理器 🛠️
# 自动获取发行版本
distribution=$(. /etc/os-release;echo $ID$VERSION_ID | sed -e 's/\.//g')# 下载并安装CUDA密钥环
wget https://developer.download.nvidia.com/compute/cuda/repos/$distribution/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb# 更新并安装数据中心GPU管理器
sudo apt-get update
sudo apt-get install -y datacenter-gpu-manager
💡 备选方案:
echo "deb [signed-by=/usr/share/keyrings/cuda-archive-keyring.gpg] https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/ /" | sudo tee /etc/apt/sources.list.d/cuda.list
dockerdcgmexporter__100">(二)、docker部署dcgm-exporter 🐳
集成显卡信息 🖥️
# 安装NVIDIA Container Toolkit
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart docker# 运行dcgm-exporter
docker run -d --rm \--gpus all \-p 30099:9400 \--cap-add SYS_ADMIN \nvcr.io/nvidia/k8s/dcgm-exporter:3.3.7-3.5.0-ubuntu22.04 \-f /etc/dcgm-exporter/dcp-metrics-included.csv
(三)、配置MetricBeat 📝
# 开启prometheus模块
sudo metricbeat modules enable prometheus# 修改配置文件
cd /etc/metricbeat/modules.d
sudo vim prometheus.yml# 添加以下配置
- module: prometheusperiod: 10shosts: ["localhost:30099"]metrics_path: /metricsmetrics_filters:include: ["DCGM_FI_DEV_MEMORY_TEMP", # 显存温度"DCGM_FI_DEV_GPU_TEMP", # GPU温度"DCGM_FI_DEV_POWER_USAGE", # 功耗"DCGM_FI_DEV_GPU_UTIL", # GPU利用率"DCGM_FI_DEV_MEM_COPY_UTIL" # 内存拷贝利用率]# 重启MetricBeat
sudo systemctl restart metricbeat
🧪 测试命令:
dcgmproftester12 --no-dcgm-validation -t 1004 -d 30
附录 📚
(一)、dcp-metrics-included.csv-中文注释版
# 格式,,
# 如果行以 '#' 开头,则被视为注释,,
# DCGM 字段, Prometheus 指标类型, 帮助信息# 时钟(Clocks),,
DCGM_FI_DEV_SM_CLOCK, gauge, SM 时钟频率(单位:MHz)
DCGM_FI_DEV_MEM_CLOCK, gauge, 内存时钟频率(单位:MHz)# 温度(Temperature),,
DCGM_FI_DEV_MEMORY_TEMP, gauge, 内存温度(单位:摄氏度)
DCGM_FI_DEV_GPU_TEMP, gauge, GPU 温度(单位:摄氏度)# 功率(Power),,
DCGM_FI_DEV_POWER_USAGE, gauge, 功率消耗(单位:瓦特)
# DCGM_FI_DEV_TOTAL_ENERGY_CONSUMPTION, counter, 自启动以来的总能耗(单位:毫焦耳)# PCIe,,
# DCGM_FI_DEV_PCIE_TX_THROUGHPUT, counter, 通过 PCIe 发送的数据总字节数(单位:KB)通过 NVML 采集
# DCGM_FI_DEV_PCIE_RX_THROUGHPUT, counter, 通过 PCIe 接收的数据总字节数(单位:KB)通过 NVML 采集
# DCGM_FI_DEV_PCIE_REPLAY_COUNTER, counter, PCIe 重试次数总计# 利用率(Utilization,采样周期根据产品而异),,
DCGM_FI_DEV_GPU_UTIL, gauge, GPU 利用率(单位:百分比)
DCGM_FI_DEV_MEM_COPY_UTIL, gauge, 内存利用率(单位:百分比)
# DCGM_FI_DEV_ENC_UTIL, gauge, 编码器利用率(单位:百分比)
# DCGM_FI_DEV_DEC_UTIL , gauge, 解码器利用率(单位:百分比)# 错误和违规(Errors and violations),,
# DCGM_FI_DEV_XID_ERRORS, gauge, 最后一个 XID 错误的值
# DCGM_FI_DEV_POWER_VIOLATION, counter, 由于功率限制引起的节流时间(单位:微秒)
# DCGM_FI_DEV_THERMAL_VIOLATION, counter, 由于温度限制引起的节流时间(单位:微秒)
# DCGM_FI_DEV_SYNC_BOOST_VIOLATION, counter, 由于同步加速限制引起的节流时间(单位:微秒)
# DCGM_FI_DEV_BOARD_LIMIT_VIOLATION, counter, 由于板卡限制引起的节流时间(单位:微秒)
# DCGM_FI_DEV_LOW_UTIL_VIOLATION, counter, 由于低利用率引起的节流时间(单位:微秒)
# DCGM_FI_DEV_RELIABILITY_VIOLATION, counter, 由于可靠性限制引起的节流时间(单位:微秒)# 内存使用(Memory usage),,
DCGM_FI_DEV_FB_FREE, gauge, 帧缓冲器空闲内存(单位:MiB)
DCGM_FI_DEV_FB_USED, gauge, 帧缓冲器已使用内存(单位:MiB)# ECC,,(错误纠正码)
# DCGM_FI_DEV_ECC_SBE_VOL_TOTAL, counter, 单位元易失性 ECC 错误总数
# DCGM_FI_DEV_ECC_DBE_VOL_TOTAL, counter, 双位元易失性 ECC 错误总数
# DCGM_FI_DEV_ECC_SBE_AGG_TOTAL, counter, 单位元持久性 ECC 错误总数
# DCGM_FI_DEV_ECC_DBE_AGG_TOTAL, counter, 双位元持久性 ECC 错误总数# 退役页面(Retired pages),,
# DCGM_FI_DEV_RETIRED_SBE, counter, 由于单位元错误引起的退役页面总数
# DCGM_FI_DEV_RETIRED_DBE, counter, 由于双位元错误引起的退役页面总数
# DCGM_FI_DEV_RETIRED_PENDING, counter, 正在等待退役的页面总数# NVLink,,
# DCGM_FI_DEV_NVLINK_CRC_FLIT_ERROR_COUNT_TOTAL, counter, NVLink 流控制 CRC 错误总数
# DCGM_FI_DEV_NVLINK_CRC_DATA_ERROR_COUNT_TOTAL, counter, NVLink 数据 CRC 错误总数
# DCGM_FI_DEV_NVLINK_REPLAY_ERROR_COUNT_TOTAL, counter, NVLink 重试总数
# DCGM_FI_DEV_NVLINK_RECOVERY_ERROR_COUNT_TOTAL, counter, NVLink 恢复错误总数
# DCGM_FI_DEV_NVLINK_BANDWIDTH_TOTAL, counter, 所有通道的 NVLink 带宽计数总数
# DCGM_FI_DEV_NVLINK_BANDWIDTH_L0, counter, 活动 NVLink RX 或 TX 数据的字节数,包括报头和有效负载# 虚拟GPU许可证状态(VGPU License status),,
# DCGM_FI_DEV_VGPU_LICENSE_STATUS, gauge, vGPU 许可证状态# 重新映射的行(Remapped rows),,
# DCGM_FI_DEV_UNCORRECTABLE_REMAPPED_ROWS, counter, 由于不可修复错误导致的重新映射行数
# DCGM_FI_DEV_CORRECTABLE_REMAPPED_ROWS, counter, 由于可修复错误导致的重新映射行数
# DCGM_FI_DEV_ROW_REMAP_FAILURE, gauge, 行重新映射是否失败# DCP 指标(DCP metrics),,
# DCGM_FI_PROF_GR_ENGINE_ACTIVE, gauge, 图形引擎活动时间的比率(单位:百分比)
# DCGM_FI_PROF_SM_ACTIVE, gauge, SM 至少分配一个线程块的周期比率(单位:百分比)
# DCGM_FI_PROF_SM_OCCUPANCY, gauge, SM 上驻留线程块的数量比率(单位:百分比)
# DCGM_FI_PROF_PIPE_TENSOR_ACTIVE, gauge, 张量(HMMA)管道活动周期的比率(单位:百分比)
# DCGM_FI_PROF_DRAM_ACTIVE, gauge, 设备内存接口发送或接收数据时活动周期的比率(单位:百分比)
# DCGM_FI_PROF_PIPE_FP64_ACTIVE, gauge, fp64 管道活动周期的比率(单位:百分比)
# DCGM_FI_PROF_PIPE_FP32_ACTIVE, gauge, fp32 管道活动周期的比率(单位:百分比)
# DCGM_FI_PROF_PIPE_FP16_ACTIVE, gauge, fp16 管道活动周期的比率(单位:百分比)
# DCGM_FI_PROF_PCIE_TX_BYTES, counter, 活动 PCIe 传输数据的字节数,包括报头和有效负载
# DCGM_FI_PROF_PCIE_RX_BYTES, counter, 活动 PCIe 接收数据的字节数,包括报头和有效负载