开源项目
auto-log 自动日志输出
分布式链路追踪简介
随着业务系统的不断发展、微服务架构的演进,从原来的单体应用架构、垂直应用架构、分布式 SOA 架构到现在的微服务架构,系统逐步走向微服务化以适应用户高并发请求等需求。
在微服务架构中,一个业务操作往往需要多个服务间协同操作,而在一个复杂的系统中出现问题的时候,需要我们能够快速的分析并定位到问题的原因,这就需要我们对业务进行一次还原,正是分布式链路追踪需要解决的问题。
分布式链路追踪就是将一次请求还原成完整的链路,将一次分布式请求的调用情况集中展示,例如请求耗时、请求节点的名称、响应状态等。
分布式链路跟踪主要功能: 故障快速定位:可以通过调用链结合业务日志快速定位错误信息,包括请求时间、响应的状态、节点名称等信息,用于到达故障定位的能力;
链路性能可视化:各个阶段链路耗时、服务依赖关系通过可视化界面展现出来;
链路分析:通过分析链路耗时、服务依赖关系可以得到用户的行为路径,汇总分析应用在很多业务场景。
分布式链路追踪的基本原理
2.1 Dapper 模型
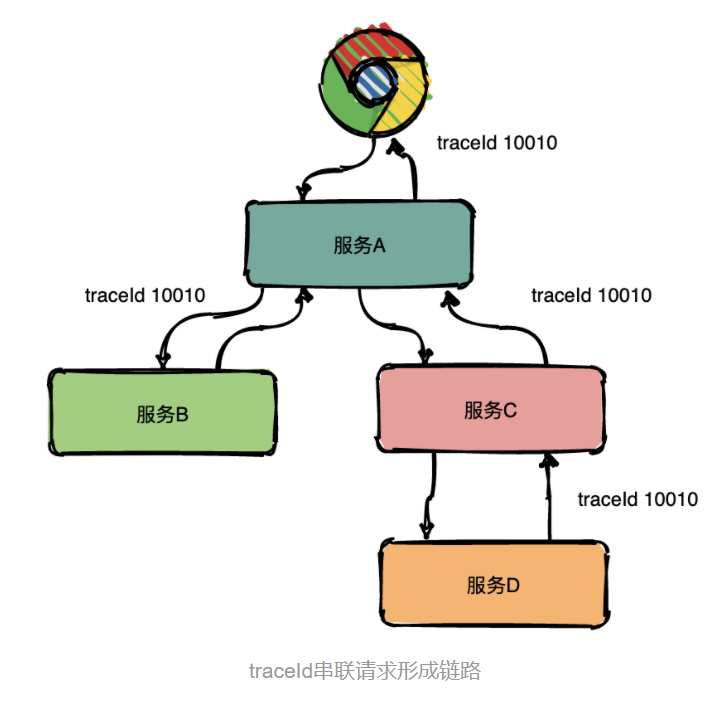
链路追踪系统最早是由Goggle公开发布的一篇论文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》,这篇论文讲述了 Dapper 链路追踪系统的基本原理和关键技术点,通过一个分布式全局唯一的 id(即traceId),将分布在各个服务节点上的同一次请求串联起来,还原调用关系、追踪系统问题、分析调用数据、统计系统指标。
图中一条完整的链路是:user -> 服务A -> 服务B -> 服务C -> 服务D -> 服务E -> 服务C -> 服务A -> user,服务之间经过的每一条链路构成了一条完整的链路,并且每一条局部的链路都可以用唯一的 trace id标识。
通过唯一的 trace id无法知道先是调用了服务A还是先调用了服务B,因此为了去表达这种父子关系引入了 span 的概念,相同层的 parent id 相同,span id不同,并且 span id 由小到大来表示请求的顺序。
除此之外,还可以记录其他的一些信息,比如发起服务的名称、IP、被调用服务的名称、返回结果、网络耗时等。
疑问Q1:平级的节点之间,如何知道先后,来生成不同大小的 spanid 呢?
如果上游节点,只是把 parent_sid(简称 psid) 传入下去。
那么,下游可以根据 psid 直接得到上游的 sid 信息,然后生成自己的 sid。
这样可以保证层级关系。
但是如果 psid 同时调用了两个下游 A / B。两个服务如果是独立的,各自生成 sid,又如何保证大小呢?
引入一个新的变量,request_time 请求的时间戳?
如果在上游,可以把下游节点的 sid 生成呢?也不合适
疑问Q2: 跨进程传递-上游的 traceId 与 psid 要如何传递?
在 Dubbo 中的 attachment 就相当于 header,所以我们把 context 放在 attachment 中,这样就解决了 context 的传递问题。
类似的,http 与 mq 又如何传递?
疑问Q3:生命周期如何管理?
一个链路中的 traceId 是在什么时候设置,又是在什么时候清空的?
类似的, psid 应该在什么时候设置,又在什么时候清空?是不是类似于 mdc 的生命周期?
2.2 OpenTracing 模型
OpenTracing 是一个中立的分布式追踪的 API 规范,提供了统一接口方便开发者在自己的服务中集成一种或者多种分布式追踪的实现,使得开发人员能够方便的添加或更换追踪系统的实现。
OpenTracing 可以解决不同的分布式追踪系统 API 不兼容的问题,各个分布式追踪系统都来实现这套接口。
OpenTracing 的数据模型,主要有以下三个:
Trace:可以理解为一个完整请求链路,也可以认为是由多个 span 组成的有向无环图(DAG);
Span:span 代表系统中具有开始时间和执行时长的逻辑运行单元,只要是一个完整生命周期的程序访问都可以认为是一个 span,比如一次数据库访问,一次方法的调用,一次 MQ 消息的发送等;每个 span 包含了操作名称、起始时间、结束时间、阶段标签集合(Span Tag)、阶段日志(Span Logs)、阶段上下文(SpanContext)、引用关系(Reference);
SpanContext:Trace 的全局上下文信息,span 的状态通过 SpanContext 跨越进程边界进行传递,比如包含 trace id,span id,Baggage Items(一个键值对集合)。
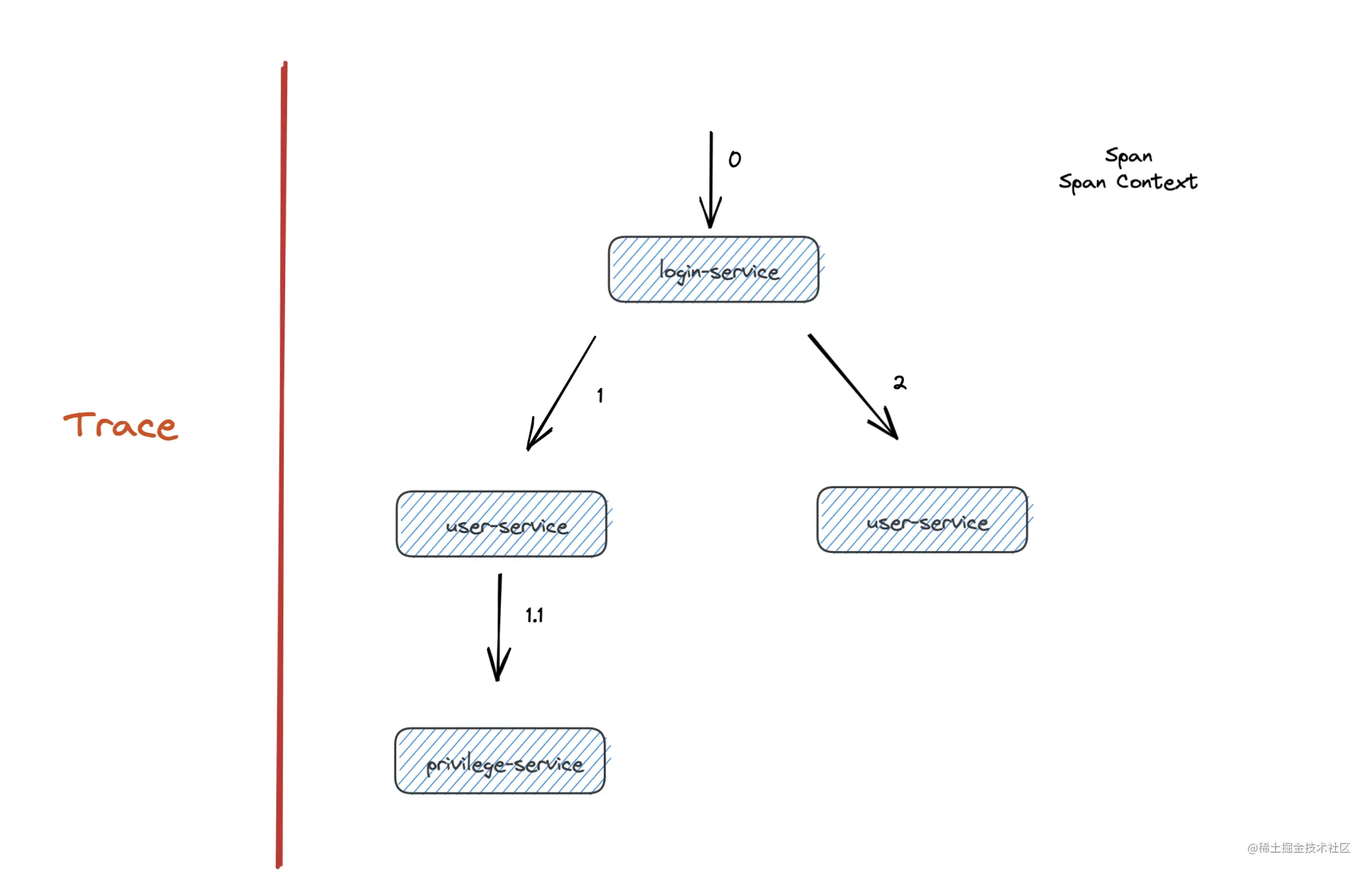
对于一次完整的登录请求就是一个 Trace,显然需要一个全局的 trace id 来标识,每次服务间的调用就称为一个 span,通过对应协议将 span context 进行传输。
据此调用链路信息画出调用链的可视化视图如下:

链路追踪基本原理
链路追踪系统(可能)最早是由Goggle公开发布的一篇论文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》被大家广泛熟悉,所以各位技术大牛们如果有黑武器不要藏起来赶紧去发表论文吧。
在这篇著名的论文中主要讲述了Dapper链路追踪系统的基本原理和关键技术点。
接下来挑几个重点的技术点详细给大家介绍一下。
Trace
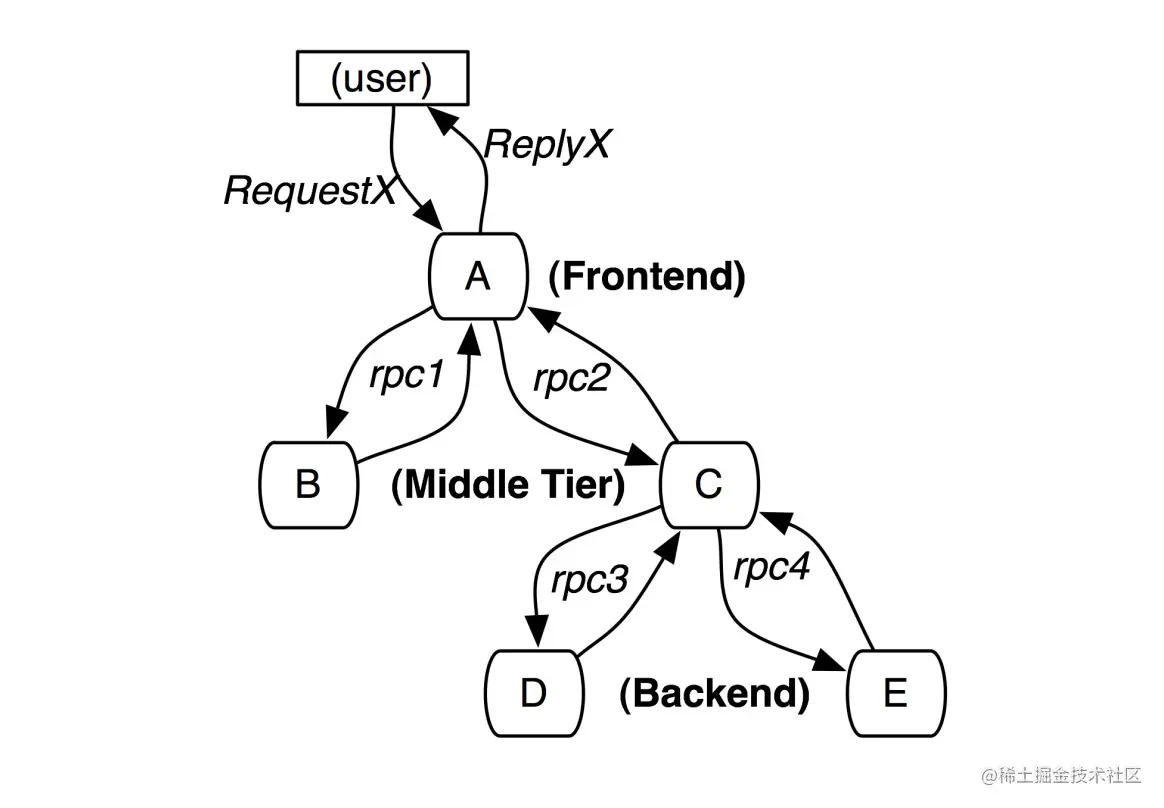
Trace的含义比较直观,就是链路,指一个请求经过所有服务的路径,可以用下面树状的图形表示。
图中一条完整的链路是:chrome -> 服务A -> 服务B -> 服务C -> 服务D -> 服务E -> 服务C -> 服务A -> chrome。
服务间经过的局部链路构成了一条完整的链路,其中每一条局部链路都用一个全局唯一的traceid来标识。
Span
在上图中可以看出来请求经过了服务A,同时服务A又调用了服务B和服务C,但是先调的服务B还是服务C呢?
从图中很难看出来,只有通过查看源码才知道顺序。
为了表达这种父子关系引入了Span的概念。
同一层级parent id相同,span id不同,span id从小到大表示请求的顺序,从下图中可以很明显看出服务A是先调了服务B然后再调用了C。
上下层级代表调用关系,如下图服务C的span id为2,服务D的parent id为2,这就表示服务C和服务D形成了父子关系,很明显是服务C调用了服务D。
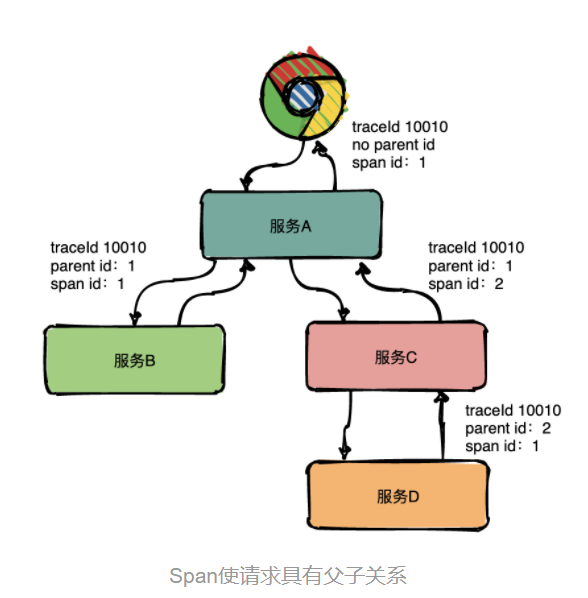
总结:通过事先在日志中埋点,找出相同traceId的日志,再加上parent id和span id就可以将一条完整的请求调用链串联起来。
Annotations
Dapper中还定义了annotation的概念,用于用户自定义事件,用来辅助定位问题。
通常包含四个注解信息:
cs:Client Start,表示客户端发起请求;
sr:ServerReceived,表示服务端收到请求;
ss: Server Send,表示服务端完成处理,并将结果发送给客户端;
cr:ClientReceived,表示客户端获取到服务端返回信息;
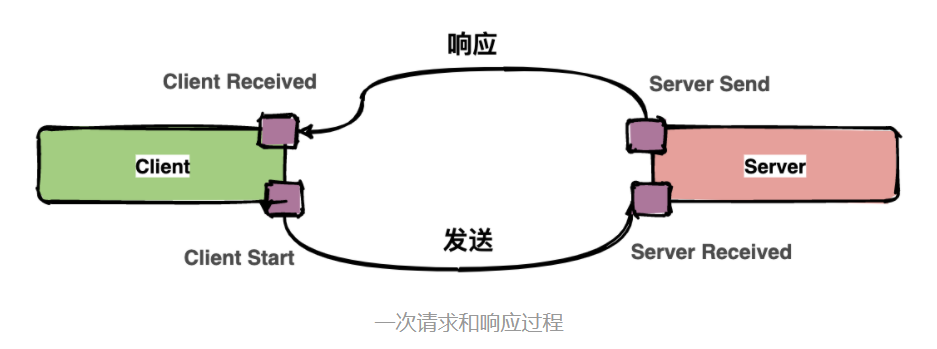
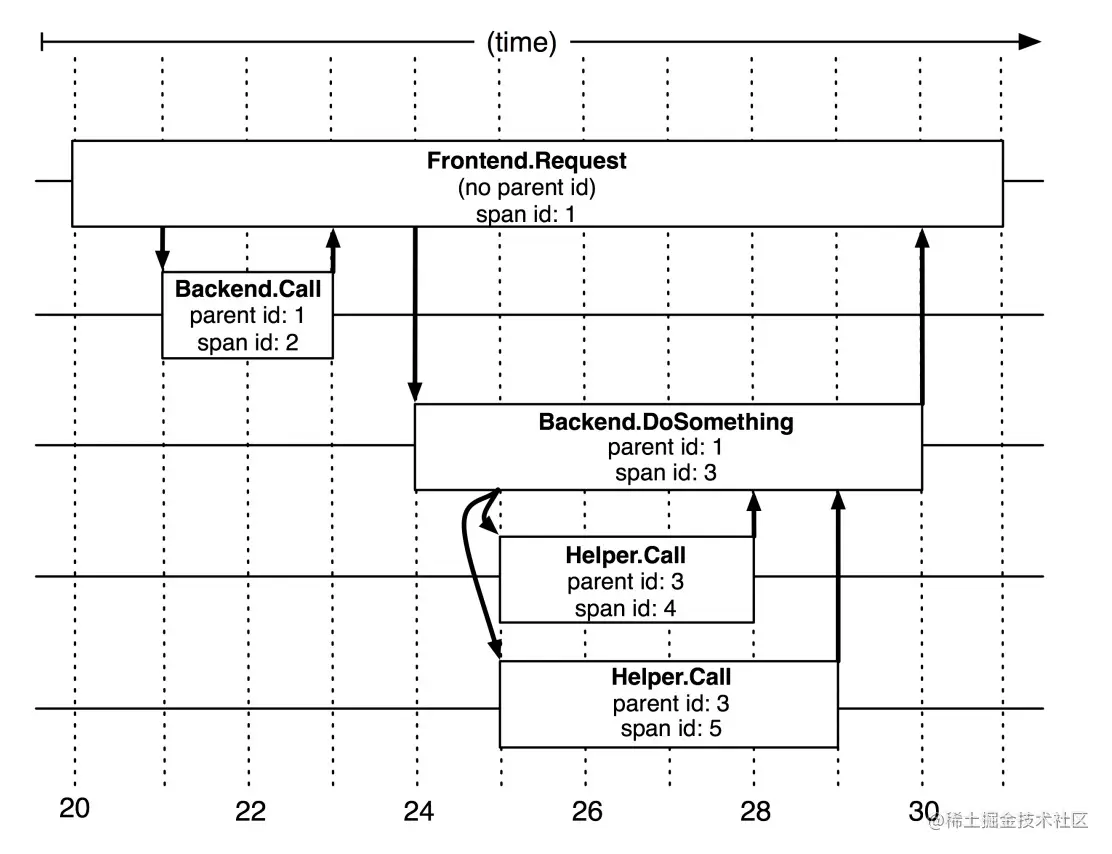
一次请求和响应过程
上图中描述了一次请求和响应的过程,四个点也就是对应四个Annotation事件。
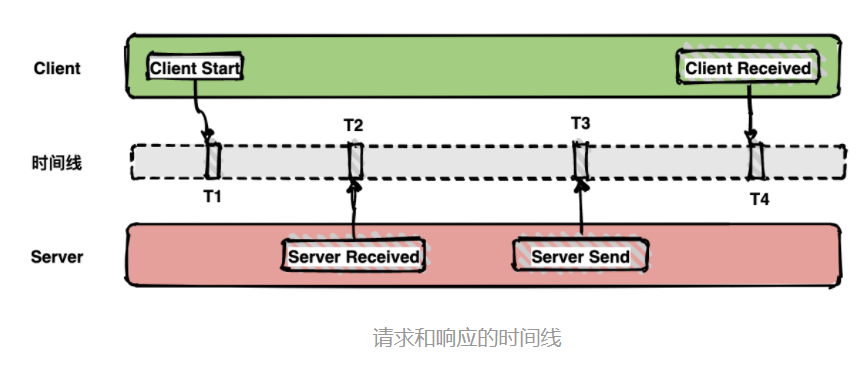
如下面的图表示从客户端调用服务端的一次完整过程。如果要计算一次调用的耗时,只需要将客户端接收的时间点减去客户端开始的时间点,也就是图中时间线上的T4 - T1。
如果要计算客户端发送网络耗时,也就是图中时间线上的T2 - T1,其他类似可计算。
带内数据与带外数据
链路信息的还原依赖于带内和带外两种数据。
带外数据是各个节点产生的事件,如cs,ss,这些数据可以由节点独立生成,并且需要集中上报到存储端。
通过带外数据,可以在存储端分析更多链路的细节。
带内数据如traceid,spanid,parentid,用来标识trace,span,以及span在一个trace中的位置,这些数据需要从链路的起点一直传递到终点。
通过带内数据的传递,可以将一个链路的所有过程串起来。
采样
由于每一个请求都会生成一个链路,为了减少性能消耗,避免存储资源的浪费,dapper并不会上报所有的span数据,而是使用采样的方式。
举个例子,每秒有1000个请求访问系统,如果设置采样率为1/1000,那么只会上报一个请求到存储端。
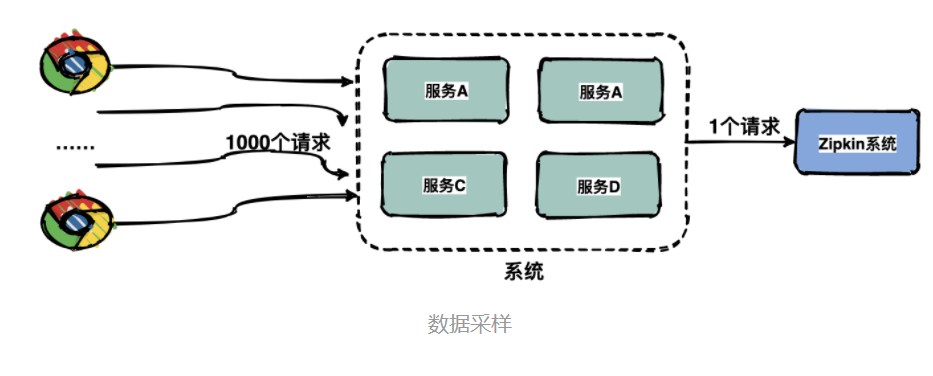
通过采集端自适应地调整采样率,控制span上报的数量,可以在发现性能瓶颈的同时,有效减少性能损耗。
存储
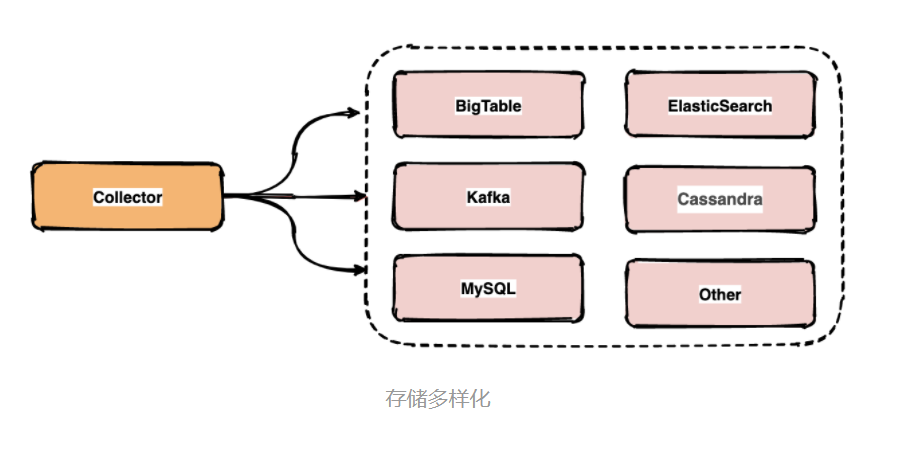
链路中的span数据经过收集和上报后会集中存储在一个地方,Dapper使用了BigTable数据仓库,常用的存储还有ElasticSearch, HBase, In-memory DB等。
小结
希望本文对你有所帮助,如果喜欢,欢迎点赞收藏转发一波。
我是老马,期待与你的下次相遇。




