❝人的本事靠自己,人的成长靠网络
大家好,我是柒八九。一个专注于前端开发技术/Rust及AI应用知识分享的Coder
❝此篇文章所涉及到的技术有
Rust(Rust接收json对象并解析/Rust生成xml)WebAssembly表格合并(静态/动态) React/Vue表格导出excelRspack
因为,行文字数所限,有些概念可能会一带而过亦或者提供对应的学习资料。请大家酌情观看。
前言
自从上次更文Rust赋能前端: 给我0.02秒,生成一套Vite/Rsbuild前端项目已过去半个月之久了。
不是偷懒和懈怠了。而是年底了,工作有点多。所以,导致更文的速度和频率有点下降。
想必大家在平时业务开发的时候,或多或少都有过将前端页面中的table导出excel的需求。
常规的方案有几种
-
纯后端处理,也就是发起一个异步任务,然后将 excel生成移步到后端。-
优点:这种情况,针对那种 数据量大的情况,是一种可选方案。如果数据过于庞大,我们还可以在用一个 导出页面来展示各种导出任务。(已导出/正在导出...) -
缺点:我们无法做到导出任务的时效性。当然,我们可以借助 websockt/sse等方案来接收后端的导出结果。但是呢,这种方式无疑增加业务的复杂度。
-
-
纯前端处理,我们可以借助一些第三方的库例如 SheetJS [1]来执行数据的导出。 -
优点:导出结果能够及时看到。 -
缺点:处理数据量大的表格,性能就有点慢。同时,比如做一些表格合并(静态/动态)就有点麻烦,然后如果我们想对导出的 excel某些cell做样式处理,这块也有很大的上手难度。
-
而,今天呢,我们提供一种方案,用Rust来处理前端表格的导出(excel)。最后的效果就是,我们既可以实时得到导出结果,也能针对大数据表格实现高性能导出。并且还可以实现表格合并(静态/动态)。
运行效果
静态表格
静态长表格(1万条数据)
静态表格合并
动态表格合并
好了,天不早了,干点正事哇。

我们能所学到的知识点
❝
初衷 案例展示 源码解析 TODO
1. 初衷
其实呢,我们公司对于前端表格的导出,是走的纯后端处理的模式。也就是
-
在前端页面中发起一个异步任务 -
后端将特定的数据填充到 excel中 -
后端向前端在返回一个 Blob对象export const exportxxRecord = (data) => {
return axiosInstance<Blob>({
url: `xxx`,
data,
responseType: 'blob',
method: 'POST',
});
}; -
前端生成一个 a标签来执行下载任务export const downLoad = (blob: Blob, fileName: string) => {
const url = window.URL.createObjectURL(blob);
const a = document.createElement('a');
a.href = url;
a.download = fileName;
a.click();
window.URL.revokeObjectURL(url);
};
但是呢,最近接到一个需求。这个需求可谓是Buff叠满。
-
表格列( columns)是动态生成的 -
表格数据也是动态的(非静态表格) -
表格数据中特定列的数据需要执行合并处理,并且列和列之前是有包含关系的 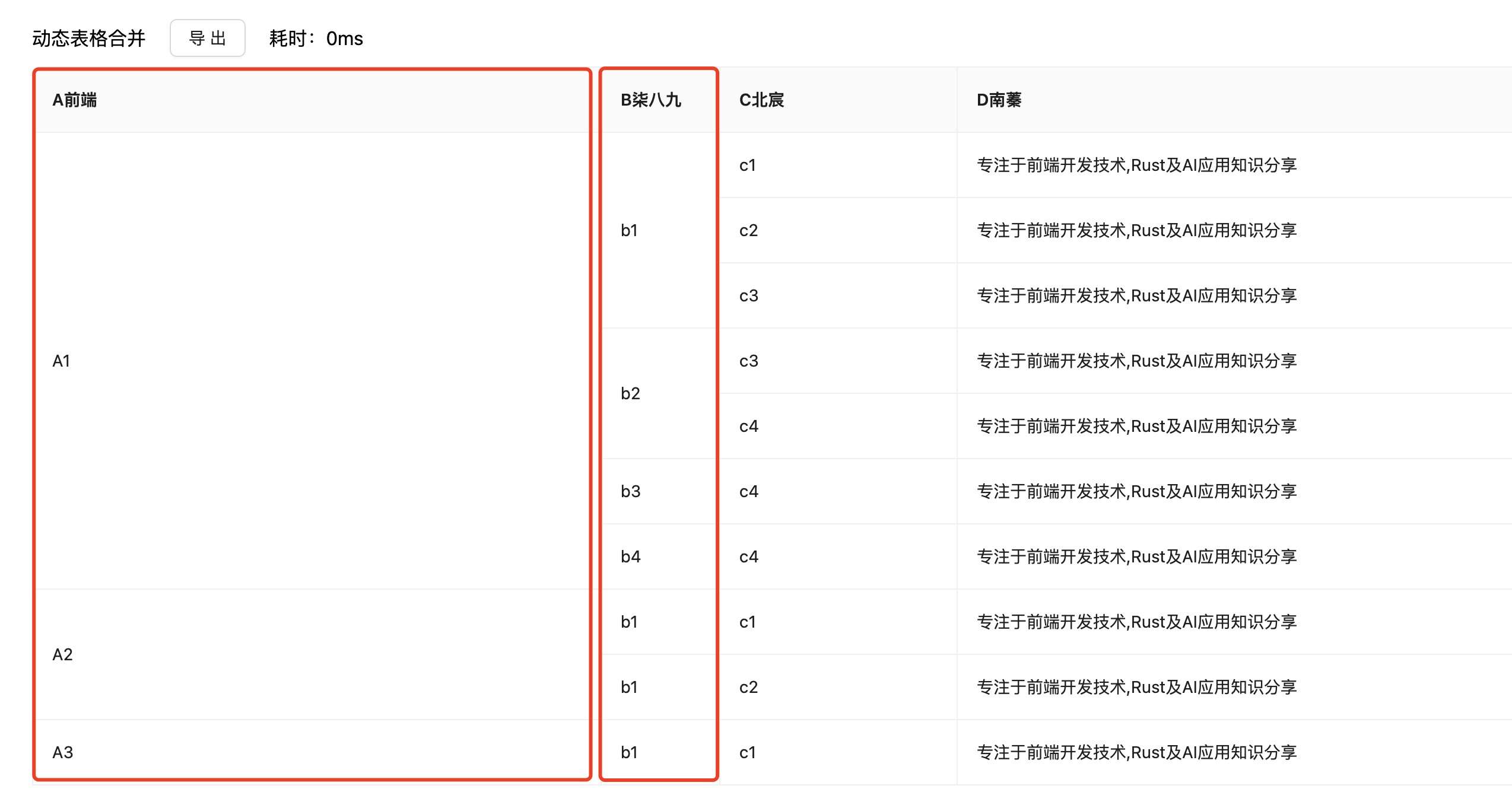
-
last but not least,表格导出的excel也是需要进行列合并的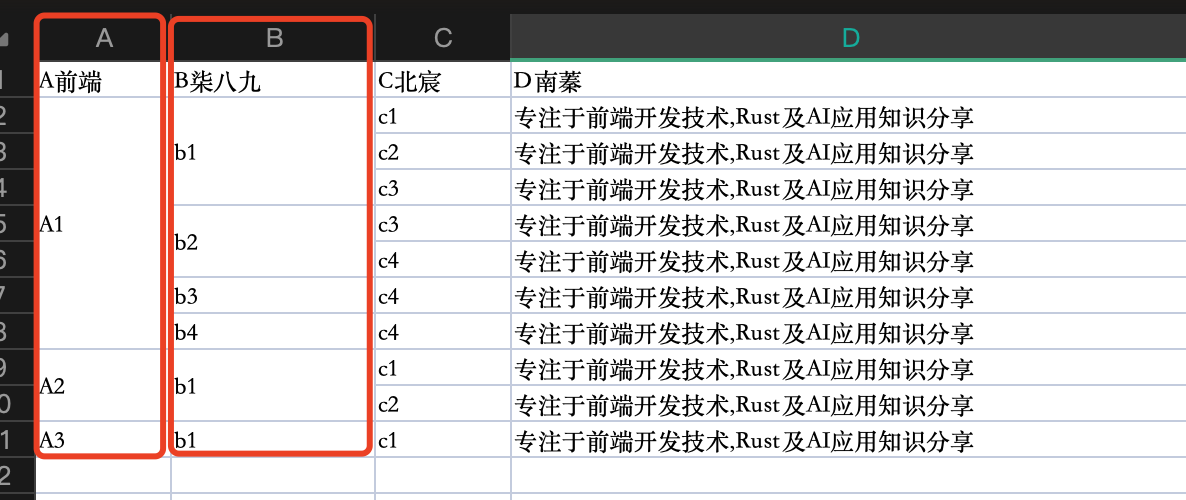
然后,更诡异的是,后端同学说他实现不了excel的动态合并。 这你能受的了吗。
既然,锅已经甩过来了,那没有不接的道理。正所谓,我不入地狱,谁入地狱?。那还是由我来哇。
更深的逻辑
其实,大部分业务场景中,大家对导出Table为Excel的常规做法都是通过异步接口来实现的。这样做也是有一定的好处的。对于部分业务场景,我们需要记录用户的导出记录,这个操作就需要后端将记录入库。
但是呢,对于一些非后端记录的导出,我们就可以使用纯前端的方式了。其实针对这类的业务处理,是有很多好处的。
-
针对导出,无非就是将前端页面中展示的 Table导出为Excel。此时,在前端环境中,我们在利用Antd/Element等前端组件库展示的时候,这块导出数据前端已经知晓了。我们要做的就是对于这些数据再次拼装或者直接一股脑的扔给Excel导出引擎(我们就是采用这种方式) -
通过异步方式处理,无论数据多少,都会产生 网络时延。如果在弱网情况下,就算是数据量小的情况下,导出效果也不尽人意。我们在 22023面试真题之网络篇中讲过。
❝最好最快的请求就是没有请求
-
就算网络时延不是主要的性能损耗点,但是对于一些统计类型的表格,对于后端同学是需要进行 多表关联的查询。有些看似简单的数据值,可能需要跨越很多表去查询。这也是一个性能损耗点。
❝所以,如果上天给我一种能够在前端环境中,又快又好的导出
excel。我会毫不犹豫的使用它
2. 案例展示
写在最前面
因为,我们是先讲我们wasm的能力,后面才会涉及到源码部分。但是呢,因为我们这个wasm兼容了很多情况,所以参数也是有很多传人方式和格式。所以,我们在讲示例之前,先讲讲参数的含义。
我们在Rust中定义了和参数相关的Struct用于收集相关信息。
#[derive(Deserialize)]
pub struct CellCoords {
pub column: u32,
pub row: u32,
}
#[derive(Deserialize)]
pub struct MergedCell {
pub from: CellCoords,
pub to: CellCoords,
}
#[derive(Debug, Serialize, Deserialize)]
struct Column {
title: String,
width: serde_json::Value,
dataIndex: String,
}
#[derive(Deserialize)]
struct InputJson {
name: String,
columns: Vec<Column>,
source: Vec<std::collections::HashMap<String, serde_json::Value>>,
merge: Option<Vec<MergedCell>>,
correlation: Option<Vec<String>>,
}
-
name:接收一个String类型的数据,用于配置生成excel的sheetName。 -
columns:看Struct我们得知,它接收的是Column的数组,而Column是用于定义我们每列的具体信息。-
可以看到,类似 title/width/dataIndex都是我们在前端构建Table(Antd)中用到的字段。(当然,当使用Element时,你可以将对应的结构转换成此种类型) -
其实这里有一个警告,在 Rust中我们定义变量名,都是使用 蛇形命名法(snake_case)是指每个空格皆以底线(_)取代的书写风格,且每个单字的第一个字母皆为 小写。 但是,我们为最大程度的兼容前端的数据,不需要再转换,这里就使用了驼峰命名法 -
当然,我们也不需要在传人的时候,在前端处理 columns相关字段,无脑传即可 -
这里还有一点需要说明,在前端 columns我们定义width时候,是可以接收number和string类型,在Rust中我们使用serde_json::Value来定义类型
-
-
source:这里我们用Vec<std::collections::HashMap<String, serde_json::Value>>定义,对标前端数据的数据类型就是 对象。-
也就是说,我们 source传人对象即可,也是无脑传即可
-
-
merge: 是一个可选项,用于接收静态表格合并的信息-
其中 MergedCell接收from和to的相关信息。
-
-
correlation:这也是一个可选项,用于接收对于针对 列合并时对应列的dataIndex信息。-
如果传人多个字段,那么这些字段默认有 关联关系,后面的字段会以前面字段分组后,才会执行合并操作。
-
❝关于在
Rust中如何操作JSON相关的,可以看我们之前写的如何在Rust中操作JSON
项目初始化
还是熟悉的套路,我们使用npx f_cli_f create table2excel的前端项目。(发布到npm的f_cli_f的rspack版本的.gitignore缺失了,有空我重新发布一版)
我们选择rspack+antd+react+tailwind的前端模板。(下面的方案,其实和框架无关,也就是说我们可以在React/Vue中无痛使用该方案)
然后,我们将项目中的pages/Home中的替换为下面的代码。
import init, { generate_excel } from "@/wasm/table2excel";
import { Button, Table } from "antd";
import { useCallback, useEffect, useState } from "react";
import { mergeDynamicTable, mergeTable, staticTable } from "./data.js";
const Home = () => {
const [time, setTime] = useState(0);
useEffect(() => {
const initWasmInstance = async () => {
await init();
};
initWasmInstance();
}, []);
const handleExcelBlob = (res: Blob) => {
const blob = new Blob([res], {
type: "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet;base64,",
});
const a = document.createElement("a");
a.href = URL.createObjectURL(blob);
a.download = "data.xlsx";
document.body.append(a);
a.click();
};
const handleExport4Static = async () => {
const startTime = performance.now();
const res = await generate_excel({
columns: staticTable.columns,
source: staticTable.source,
name: "front789",
merge: [],
});
const endTime = performance.now();
const duration = endTime - startTime;
setTime(duration);
handleExcelBlob(res);
};
return (
<section className="h-screen w-screen overflow-auto flex flex-col gap-10 p-20">
<div className="flex flex-col gap-2">
<div className="flex items-center gap-5">
静态表格 <Button onClick={handleExport4Static}>导出</Button> <span>耗时:{time}ms</span>
</div>
<Table
columns={staticTable.columns}
bordered
dataSource={staticTable.source}
pagination={false}
/>
</div>
</section>
);
};
export default Home;
其中,有几个外部文件,我们简单说描述一下
-
data.js用于定义columns/source等数据 -
wasm就是存放我们Rust编译好的文件(这个后面会讲)
我们在组件初始化中执行了table2excel的初始化操作。
useEffect(() => {
const initWasmInstance = async () => {
await init();
};
initWasmInstance();
}, []);
随后,我们就可以直接在事件回调中执行wasm的相关操作了。
我们还抽象了一个执行下载的操作方法(handleExcelBlob)
const handleExcelBlob = (res: Blob) => {
const blob = new Blob([res], {
type: "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet;base64,",
});
const a = document.createElement("a");
a.href = URL.createObjectURL(blob);
a.download = "data.xlsx";
document.body.append(a);
a.click();
};
静态表格导出
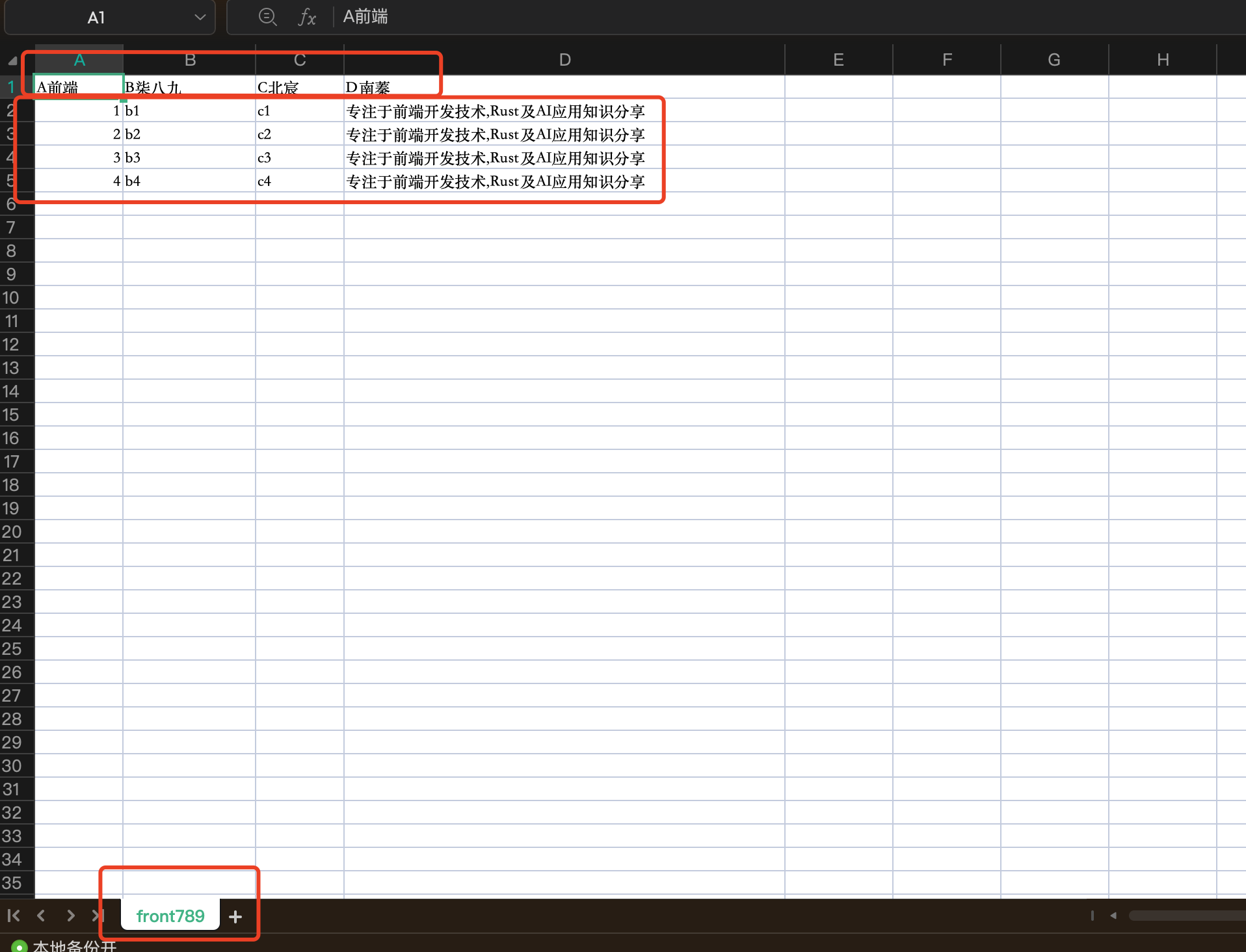
当我们运行yarn dev的时候,在Home路径下,就会展现如下页面
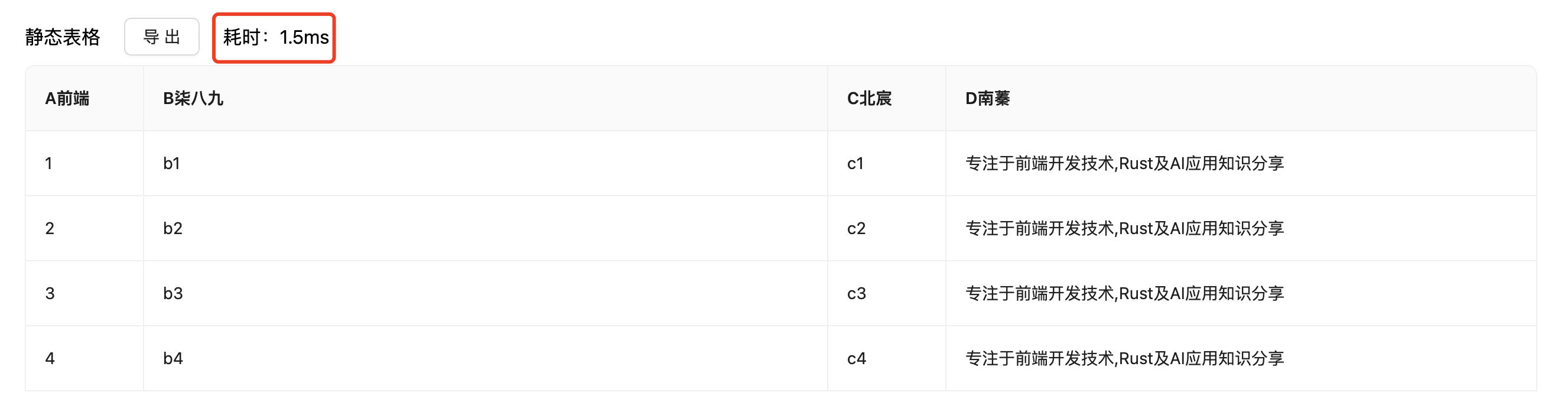
在这种情况下,我们是用data.js中的staticTable的信息。
export const staticTable = {
"columns":[
{
"title": "A前端",
"width": 100,
"dataIndex": "a"
},
{
"title": "B柒八九",
"width": "150",
"dataIndex": "b"
},
{
"title": "C北宸",
"width": 100,
"dataIndex": "c"
},
{
"title": "D南蓁",
"width": "500px",
"dataIndex": "d"
}
],
"source":[
{
"a": 1,
"b": "b1",
"c": "c1",
"d": "专注于前端开发技术,Rust及AI应用知识分享"
},
{
"a": 2,
"b": "b2",
"c": "c2",
"d": "专注于前端开发技术,Rust及AI应用知识分享"
},
{
"a": 3,
"b": "b3",
"c": "c3",
"d": "专注于前端开发技术,Rust及AI应用知识分享"
},
{
"a": 4,
"b": "b4",
"c": "c4",
"d": "专注于前端开发技术,Rust及AI应用知识分享"
}
]
}
上面的这个信息,其实就是Antd-Table中的相关配置。
在导出按钮的事件,我们执行相关的数据导出操作。
const handleExport4Static = async () => {
const startTime = performance.now();
const res = await generate_excel({
columns: staticTable.columns,
source: staticTable.source,
name: "front789",
});
const endTime = performance.now();
const duration = endTime - startTime;
setTime(duration);
handleExcelBlob(res);
};
其中,最主要的就是generate_excel。这就是wasm导出的相关函数。(import init, { generate_excel } from "@/wasm/table2excel";)
其中,有几个重要的参数,我们需要解释一下
-
columns:该参数就是定义antd-table中的columns配置。我们可以无脑传。 -
source:该参数就是定义antd-table中的dataSource配置。我们可以无脑传。 -
name:该参数用于生成excel的sheetName。
效果展示
当我们在页面中,触发导出任务后,我们就会得到如下的excel。
导出耗时
❝我们还通过
performance.now()的计算耗时任务。执行多次会发现当执行一个简单的静态表格时,平均耗时为2ms左右。(当然这还和本机环境和数据量多少有关系)
大数据表格导出
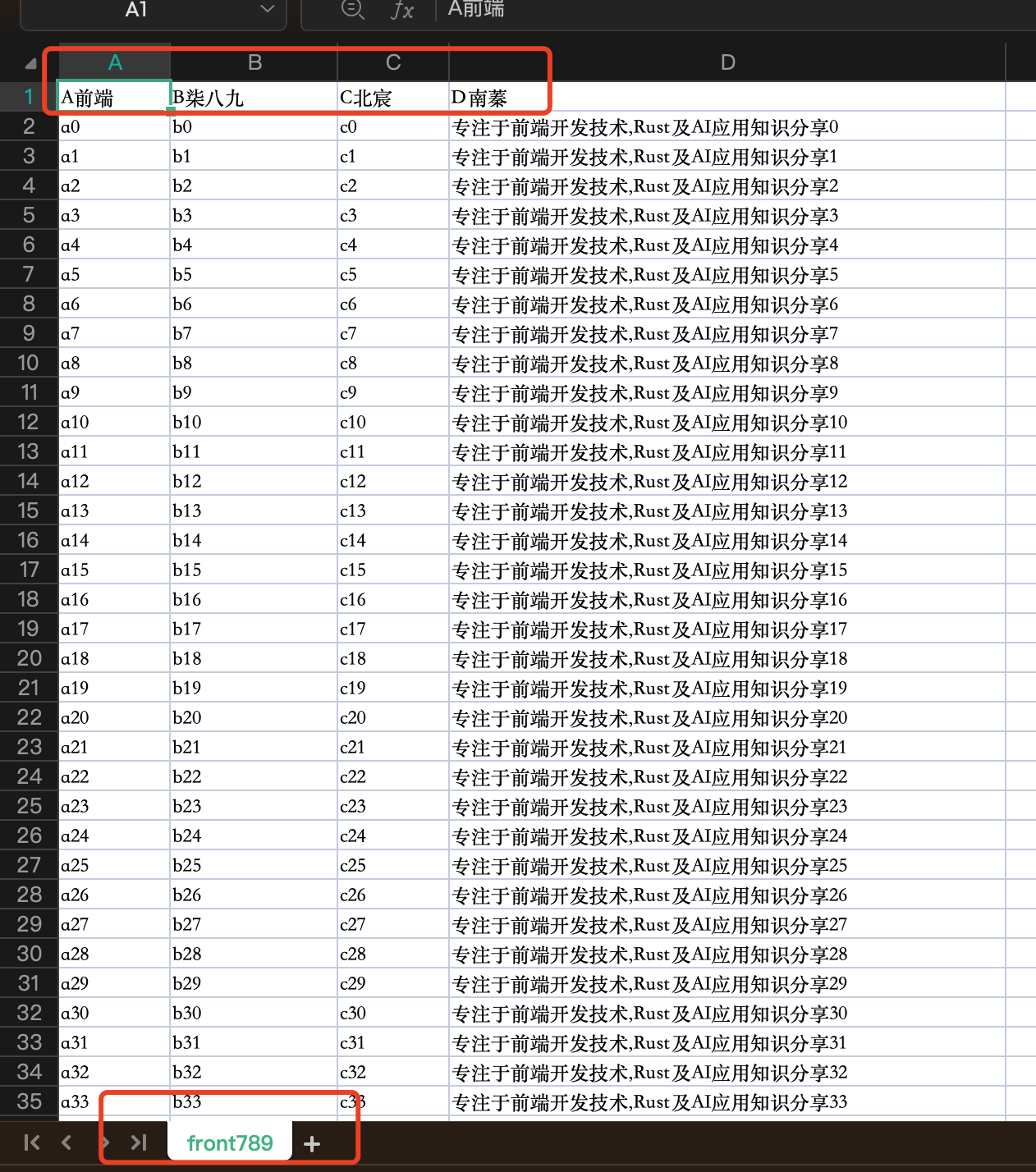
对于简单静态表格,我们已经展示过了。现在我们来展示一下对于大数据表格的导出情况。
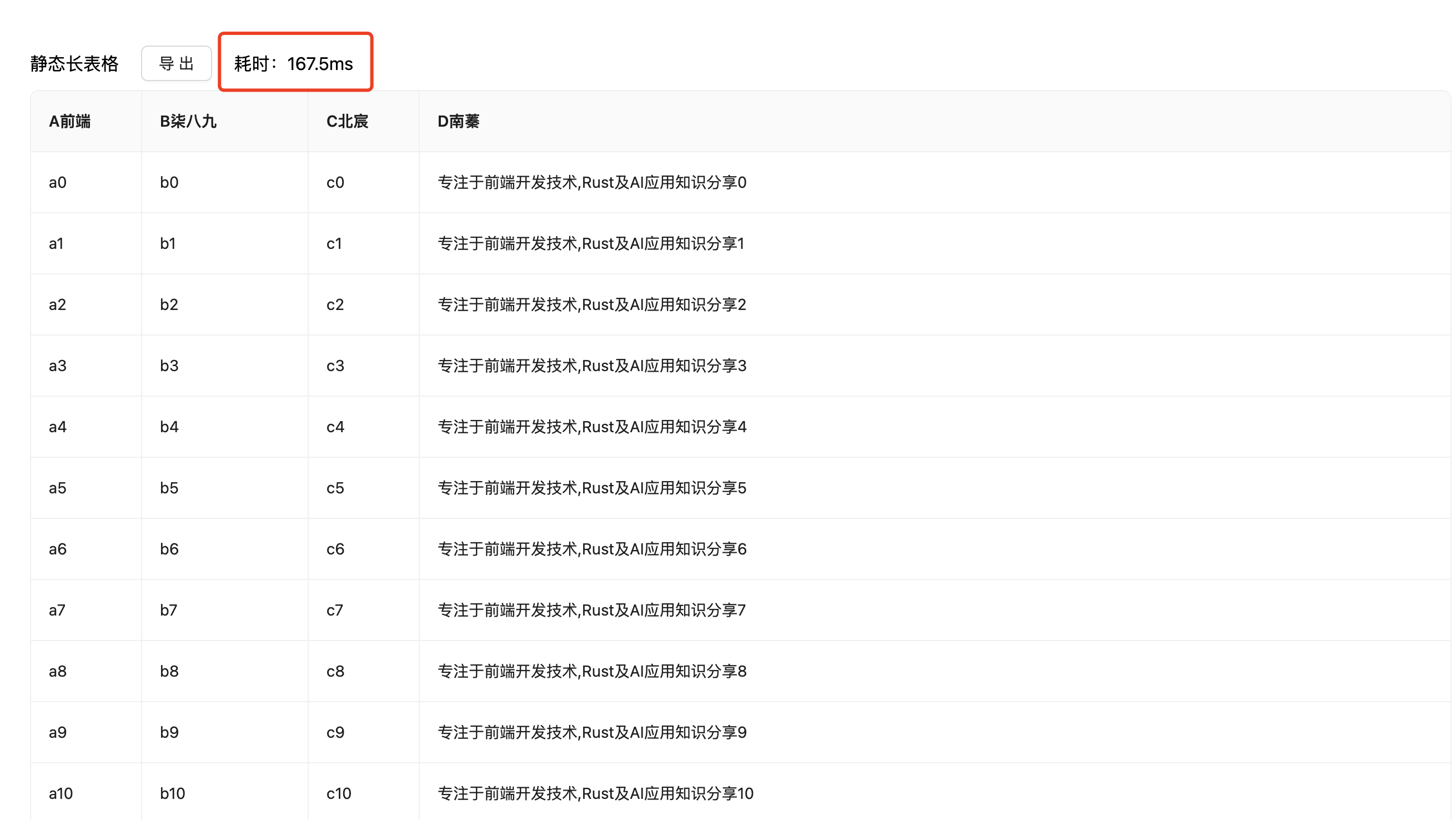
我们用node来生成一个10000条数据(其实10万条也是可以的,这个自行研究,我自己实验下,导出也不超过1秒,大部分都维持在500ms左右)
const fs = require('fs');
const dataStructure = {
columns: [
{
title: "A前端",
width: 100,
dataIndex: "a"
},
{
title: "B柒八九",
width: 150,
dataIndex: "b"
},
{
title: "C北宸",
width: 100,
dataIndex: "c"
},
{
title: "D南蓁",
width: "500px",
dataIndex: "d"
}
],
source: (() => {
const data = new Array(10000).fill(0).map((_, index) => ({
a: `a${index}`,
b: `b${index}`,
c: `c${index}`,
d: `专注于前端开发技术,Rust及AI应用知识分享 ${index}`,
}));
return data;
})()
};
fs.writeFileSync('data.json', JSON.stringify(dataStructure, null, 2), 'utf-8');
这样,我们就可以在组件中导入json数据。
import init, { generate_excel } from "@/wasm/table2excel";
import { Button, Table } from "antd";
import { useCallback, useEffect, useState } from "react";
import json from './data.json' with { type: 'json' };
const Home = () => {
const [time, setTime] = useState(0);
useEffect(() => {
// 省略部分代码
}, []);
const handleExcelBlob = (res: Blob) => {
// 省略部分代码
};
const handleExport4LongStatic = async () => {
const startTime = performance.now();
const res = await generate_excel({
columns: json.columns,
source: json.source,
name: "front789",
merge: [],
});
const endTime = performance.now();
const duration = endTime - startTime;
setTime(duration);
handleExcelBlob(res);
};
return (
<section className="h-screen w-screen overflow-auto flex flex-col gap-10 p-20">
<div className="flex flex-col gap-2">
<div className="flex items-center gap-5">
静态长表格 <Button onClick={handleExport4LongStatic}>导出</Button> <span>耗时:{time}ms</span>
</div>
<Table
columns={json.columns}
bordered
dataSource={json.source}
pagination={false}
virtual
/>
</div>
</section>
);
};
export default Home;
针对上面的代码,我们也有几点需要说明
-
JSON是Rspack的一等公民,我们可以直接导入。import json from './data.json' with { type: 'json' }; -
在使用 generate_excel时,传人的参数和之前示例是一样的,只不过我们接收的数据是json维护的。
导出耗时
❝执行多次会发现当执行一个长静态表格时,平均耗时为
160ms左右。(当然这还和本机环境和数据量多少有关系)
效果展示
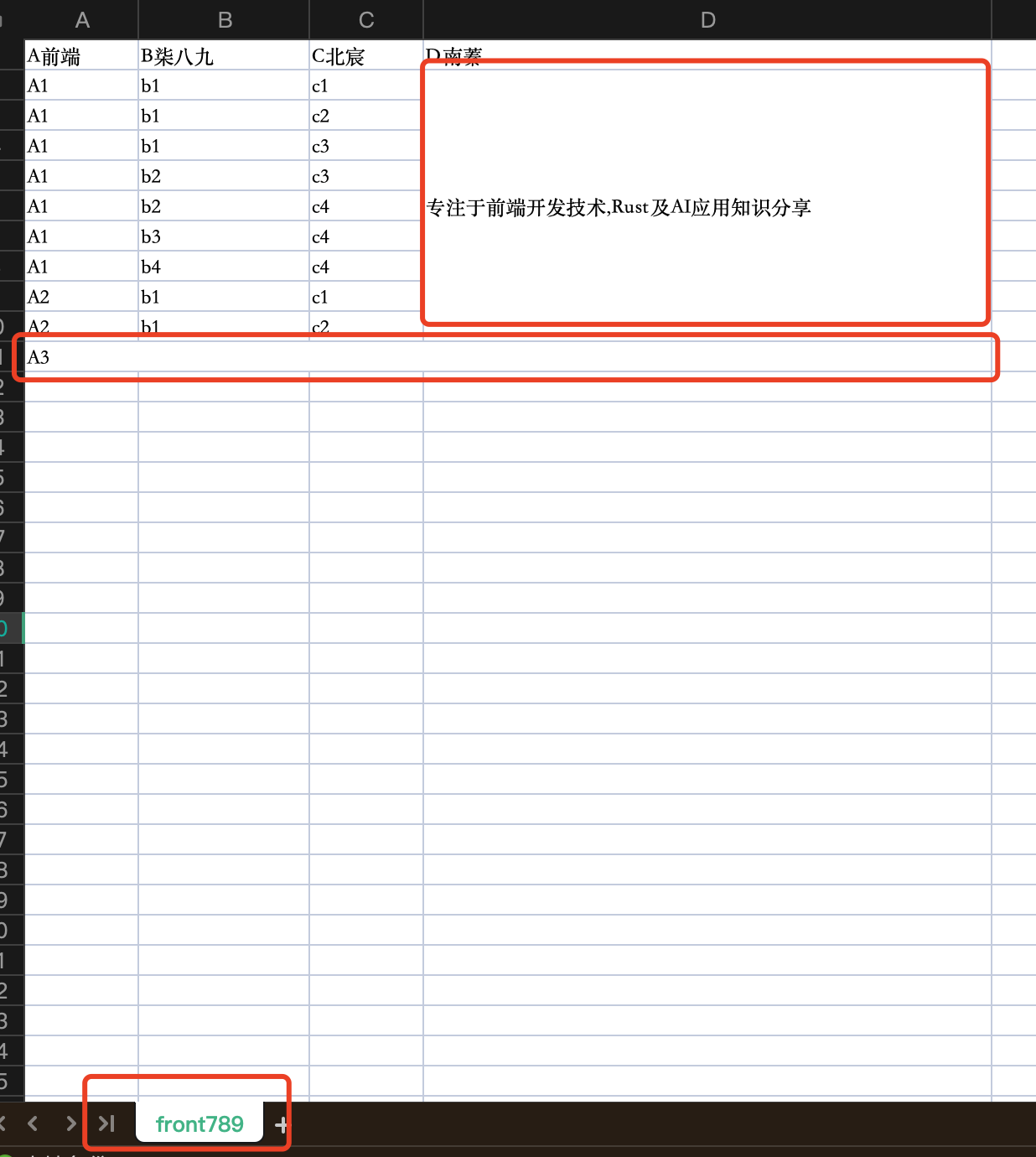
静态表格合并导出
❝何为静态表格?其实就是表格的
列/行数据都是不变的。
当需要进行表格合并时,我们是可以提前知晓,哪些行或者哪些列是需要合并操作的。
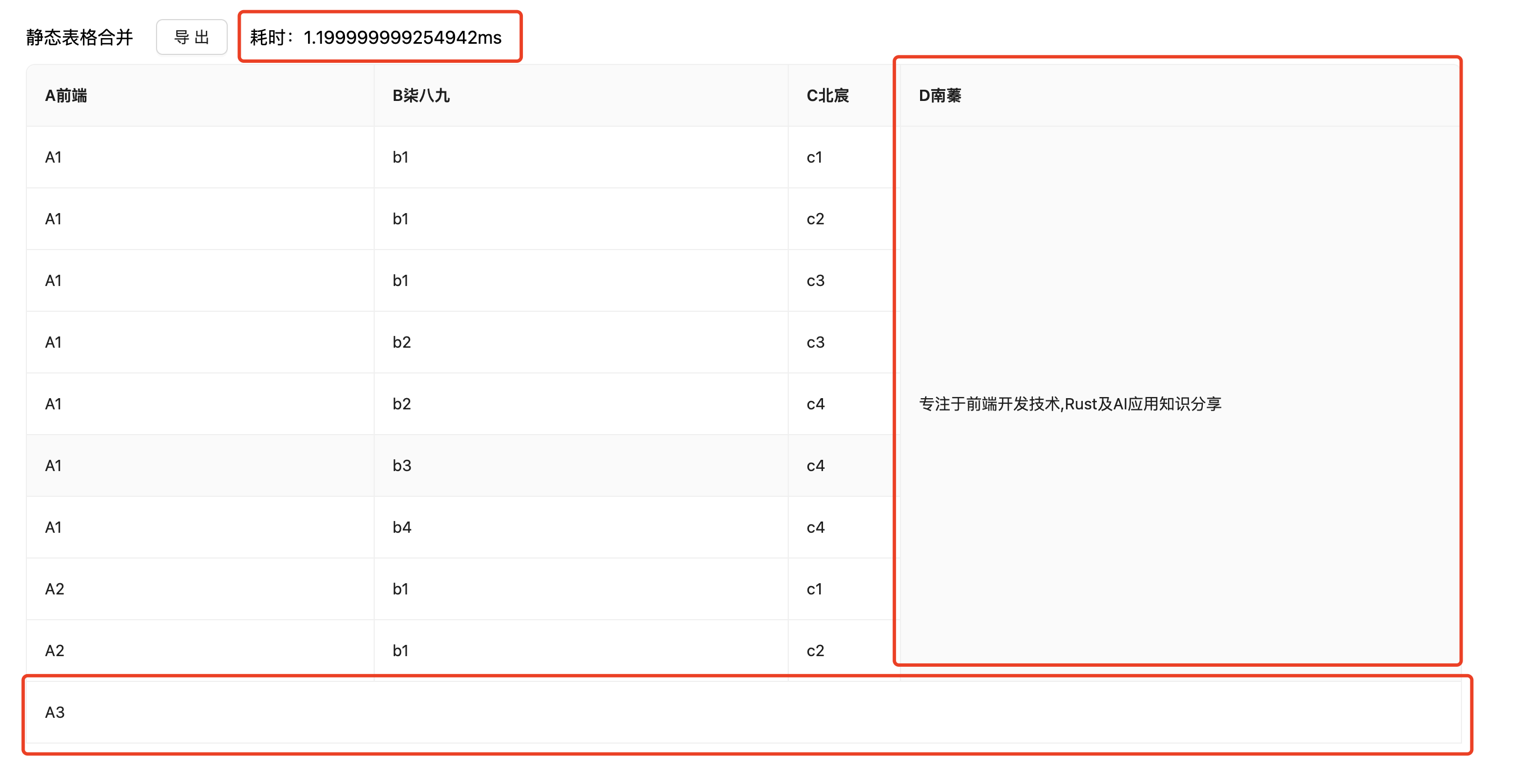
我们使用data.js中的mergeTable的信息。
因为,表格是静态的,所以我们可以提前在columns中定义onCell来控制行和列的合并。
下面是我们在还用Antd-Table进行合并时的相关配置。这块可以参考antd-table表格行/列合并[2]
const sharedOnCell = (_, index) => {
if (index === 9) {
return { colSpan: 0 };
}
return {};
};
export const mergeTable = {
"columns":[
{
"title": "A前端",
"width": "100",
"dataIndex": "a",
onCell: (_, index) => {
if (index == 9) {
return {
colSpan:4
}
}
}
},
{
"title": "B柒八九",
"width": "150",
"dataIndex": "b",
onCell:sharedOnCell
},
{
"title": "C北宸",
"width": 100,
"dataIndex": "c",
onCell:sharedOnCell
},
{
"title": "D南蓁",
"width": 500,
"dataIndex": "d",
onCell: (_, index)=>{
if (index == 9) {
return {
colSpan:0
}
}
if (index == 0) {
return {
rowSpan:9
}
}
if (index > 0) {
return {rowSpan:0}
}
return {};
}
}
],
"source":[
// 省略部分代码
]
}
然后,我们更新Home组件。
import init, { generate_excel } from "@/wasm/table2excel";
import { Button, Table } from "antd";
import { useCallback, useEffect, useState } from "react";
import { mergeDynamicTable, mergeTable, staticTable } from "./data.js";
const Home = () => {
const [time, setTime] = useState(0);
useEffect(() => {
// 省略部分代码
}, []);
const handleExcelBlob = (res: Blob) => {
// 省略部分代码
};
const handleExport4StaticMerge = async () => {
const startTime = performance.now();
const res = await generate_excel({
columns: mergeTable.columns,
source: mergeTable.source,
name: "front789",
merge: [
{
from: {
column: 0,
row: 10,
},
to: {
column: 3,
row: 10,
},
},
{
from: {
column: 3,
row: 1,
},
to: {
column: 3,
row: 9,
},
},
],
});
const endTime = performance.now();
const duration = endTime - startTime;
setTime(duration);
handleExcelBlob(res);
};
return (
<section className="h-screen w-screen overflow-auto flex flex-col gap-10 p-20">
<div className="flex flex-col gap-2">
<div className="flex items-center gap-5">
静态表格合并 <Button onClick={handleExport4StaticMerge}>导出</Button> <span>耗时:{time}ms</span>
</div>
<Table
columns={mergeTable.columns}
bordered
dataSource={mergeTable.source}
pagination={false}
/>
</div>
</section>
);
};
export default Home;
相比较之前针对静态表格的导出,我们在调用generate_excel时候,多传了一个merge字段。
merge: [
{
from: {
column: 0,
row: 10,
},
to: {
column: 3,
row: 10,
},
},
{
from: {
column: 3,
row: 1,
},
to: {
column: 3,
row: 9,
},
},
],
该字段就是用于处理excel合并的字段信息。它接收一个对象数组,其中对象是一个用于标识哪些cell是合并的。
-
from:用于标识 起始的cell位置 -
to:用于标识 结束的cell位置 -
column和row就不必多解释了
还有一点需要说明,由于我们在处理的时候,将columns中的title也抽离出来作为了excel的cell。所以在merge列的时候,针对row的配置,是以1开始的。
导出耗时
❝执行多次会发现当执行一个静态表格合并时,平均耗时为
2ms左右。(当然这还和本机环境和数据量多少有关系)
效果展示
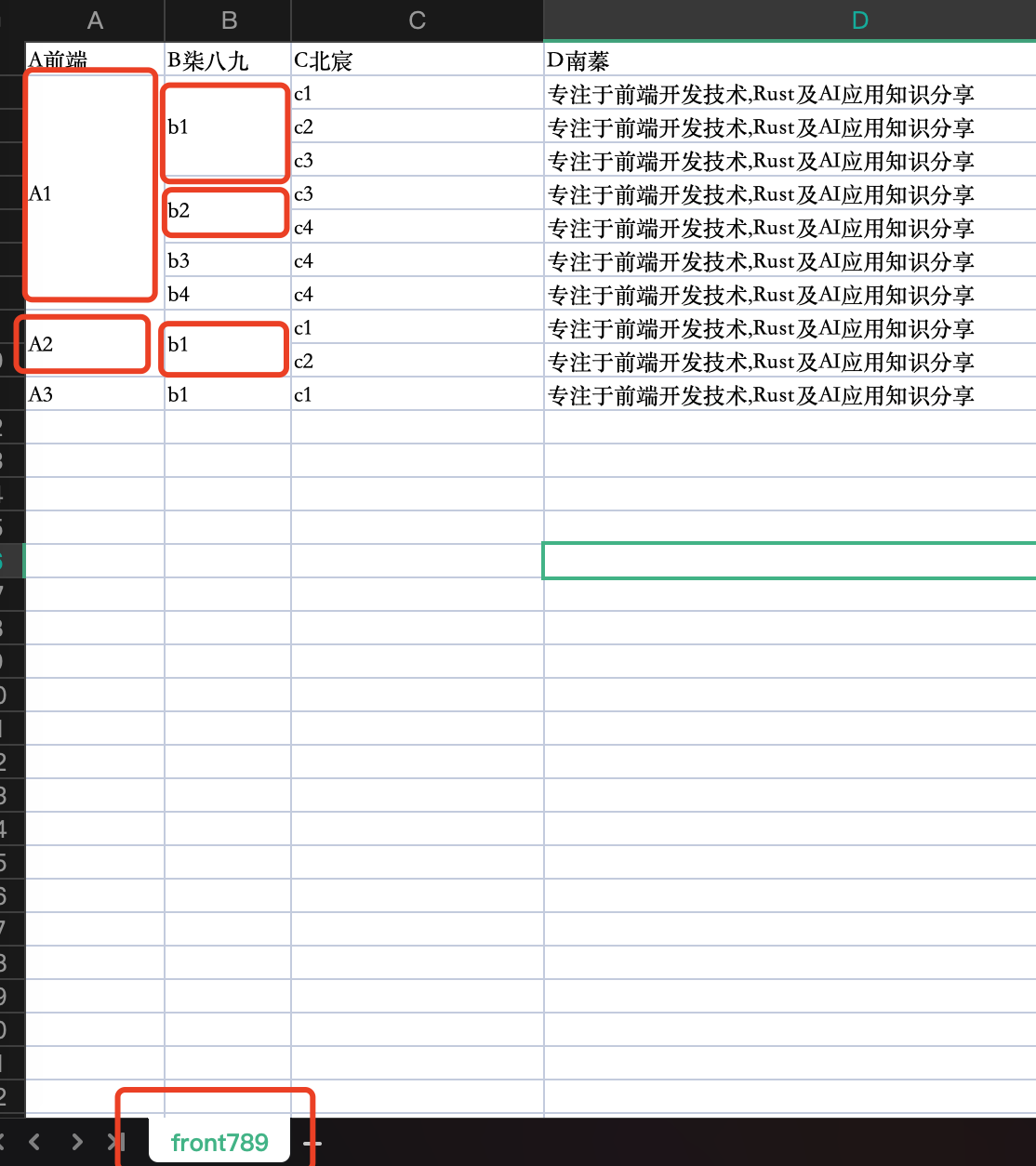
动态表格合并导出
❝何为动态表格?其实就是表格的
列/行数据都是可变的。
这个也是我们此次要做的初衷。
对于这个案例,有点复杂。
我们稍微用较多篇幅来讲讲。
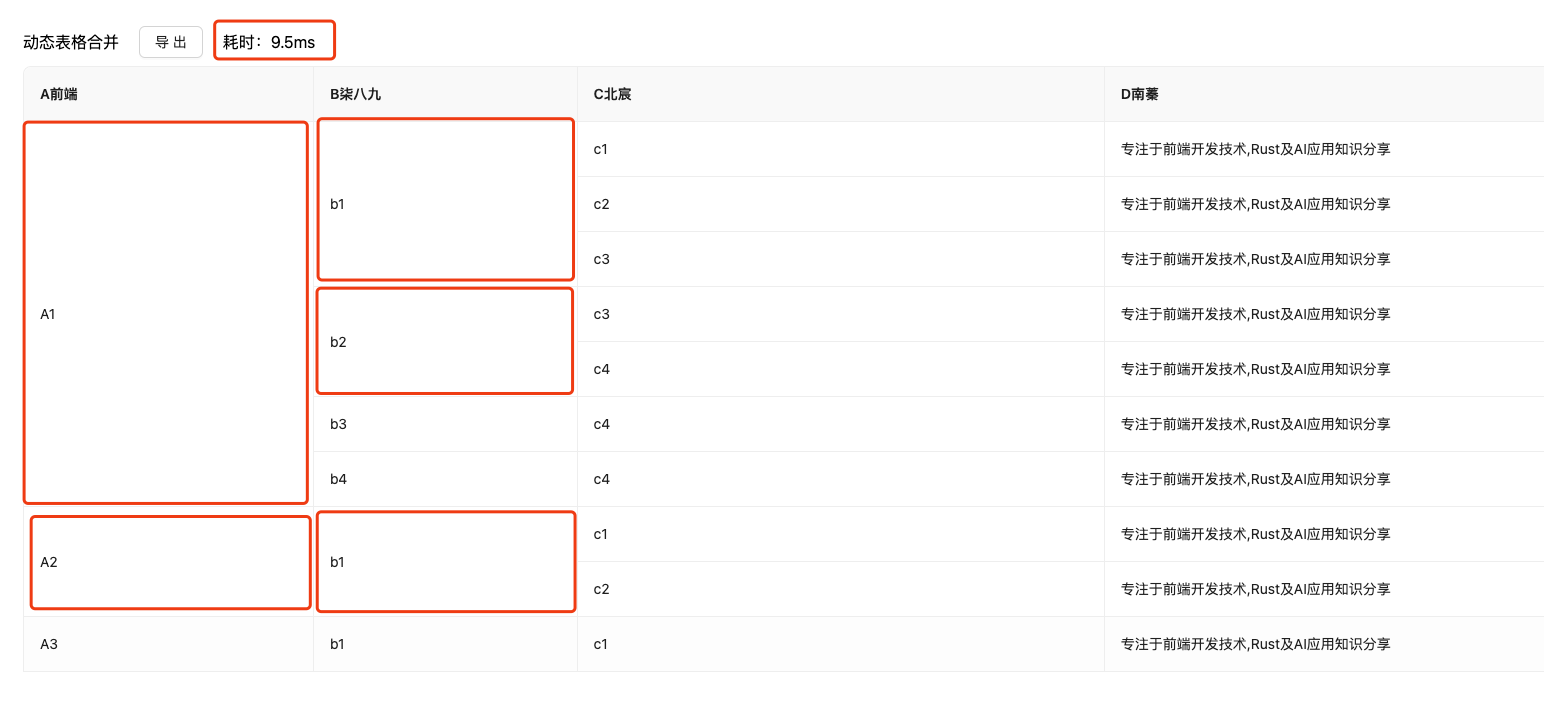
我们为了讲主要的逻辑,我们暂时将columns设定为定值。其实,真实业务中,columns也是动态变化的。可以从上图看到,我们对于第一列/第二列是依据数据来计算合并的。
在data.js中我们定义如下的数据类型。
export const mergeDynamicTable = {
"columns":[
{
"title": "A前端",
"width": "110px",
"dataIndex": "a",
},
{
"title": "B柒八九",
"width": 100,
"dataIndex": "b",
},
{
"title": "C北宸",
"width": 200,
"dataIndex": "c",
},
{
"title": "D南蓁",
"width": "500px",
"dataIndex": "d",
}
],
"source":[
// 省去部分代码
]
}
主要代码
import init, { generate_excel } from "@/wasm/table2excel";
import { Button, Table } from "antd";
import { useCallback, useEffect, useState } from "react";
import { mergeDynamicTable, mergeTable, staticTable } from "./data.js";
export type ListItem = {
id?: string;
a: string;
b: string;
c: string;
d: string;
};
type RowSpanTuple = [number, number];
const Home = () => {
const [columns, setColumns] = useState(mergeDynamicTable.columns);
const [source, setSource] = useState([]);
const [rowMergeMaps, setRowMergeMaps] = useState<Map<string, Map<string, RowSpanTuple>>>(new Map());
const [time, setTime] = useState(0);
const calculateRowMerge = useCallback((data: ListItem[], field: keyof ListItem, parentField?: keyof ListItem) => {
// 省略部分代码
}, []);
useEffect(() => {
//省去部分代码
}, []);
useEffect(() => {
const emulateAsync = async () => {
return new Promise((resolve) =>
setTimeout(
() => resolve(mergeDynamicTable.source),
Math.random() * 1000 + 1000,
),
);
};
emulateAsync().then((source) => {
if (!source || !Array.isArray(source)) {
console.error("Invalid source data");
return;
}
const data = [...source];
const map = new Map();
map.set("a", calculateRowMerge(data, "a"));
if (data[0]?.b) {
map.set("b", calculateRowMerge(data, "b", "a"));
}
setRowMergeMaps(map);
setSource(source);
});
}, [calculateRowMerge]);
useEffect(() => {
// 省去部分逻辑,在下面会讲到
}, [source, rowMergeMaps]);
const handleExport4DynamicMerge = async () => {
const startTime = performance.now();
const res = await generate_excel({
columns: mergeTable.columns,
source: mergeTable.source,
name: "front789",
correlation: ["a", "b"],
});
console.timeEnd('generate_excel_duration');
const endTime = performance.now();
const duration = endTime - startTime;
setTime(duration);
handleExcelBlob(res);
};
const handleExcelBlob = (res: Blob) => {
//省去部分代码
};
return (
<section className="h-screen w-screen overflow-auto flex flex-col gap-10 p-20">
<div className="flex flex-col gap-2">
<div className="flex items-center gap-5">
动态表格合并 <Button onClick={handleExport4DynamicMerge}>导出</Button> <span>耗时:{time}ms</span>
</div>
<Table
columns={columns}
bordered
dataSource={source}
pagination={false}
/>
</div>
</section>
);
};
export default Home;
这里有几点需要特别说明一下:
-
我们在 useEffect中通过emulateAsync来模拟一个异步任务。 -
随后,我们通过 calculateRowMerge来计算data和columns中dataIndex的相关的合并信息。
const calculateRowMerge = useCallback((data: ListItem[], field: keyof ListItem, parentField?: keyof ListItem) => {
const keyIndexMap = new Map<string, RowSpanTuple>();
const getKey = (item: ListItem) => (parentField ? `${item[parentField]}-${item[field]}` : `${item[field]}`);
data.reduce(
(acc, item, index) => {
const prevItem = data[index - 1] || data[0];
const isSameGroup = parentField
? prevItem[parentField] === item[parentField] && prevItem[field] === item[field]
: prevItem[field] === item[field];
if (isSameGroup) {
acc[1] = index;
} else {
if (acc[0] !== null) {
keyIndexMap.set(getKey(prevItem), acc);
}
acc = [index, index];
}
if (index === data.length - 1) {
keyIndexMap.set(getKey(item), acc);
}
return acc;
},
[0, 0] as RowSpanTuple
);
return keyIndexMap;
}, []);
这一步其实,就是通过遍历data(data.reduce)来收集每列中数据相同的信息。然后,存放到一个Map<string, Map<string, RowSpanTuple>>的state中。
-
随后,我们在 useEffect中监听rowMergeMaps用以动态计算每一列的onCell的相关逻辑.
if (source?.length) {
const baseColumns = [...mergeDynamicTable.columns];
// 处理第一行的行合并
const userNameMap = rowMergeMaps.get("a");
baseColumns[0].onCell = (value, index) => {
const indexSpan = userNameMap.get(value.a);
if (indexSpan) {
if (indexSpan[0] === index) {
return { rowSpan: indexSpan[1] - indexSpan[0] + 1 };
}
if (
(index as number) > indexSpan[0] &&
(index as number) <= indexSpan[1]
)
return { rowSpan: 0 };
}
return { rowSpan: 0 };
};
const typeMap = rowMergeMaps.get("b");
baseColumns[1].onCell = (value: ListItem, index: number) => {
const indexSpan = typeMap.get(`${value.a}-${value.b}`);
if (indexSpan) {
if (indexSpan[1] !== indexSpan[0] && indexSpan[0] === index) {
return { rowSpan: indexSpan[1] - indexSpan[0] + 1 };
}
if (index > indexSpan[0] && index <= indexSpan[1])
return { rowSpan: 0 };
}
return {};
};
setColumns(baseColumns);
}
-
last but not least,我们在handleExport4DynamicMerge中执行导出任务。-
其中最为显眼的就是 correlation字段。该字段就是为wasm传递,说明到底是哪几个列基于数据进行列合并。 -
同时这里还有一个默认的规则。如果传人的是多个字段,那么后面的字段会按照前面的字段进行分组合并
-
导出耗时
❝执行多次会发现当执行一个动态表格合并时,平均耗时为
10ms左右。(当然这还和本机环境和数据量多少有关系)
效果展示
3. 源码解析
项目初始化
我们通过cargo new --lib table2excel来构建一个项目。
同时呢,我们在项目根目录中创建用于打包优化的文件。
-
build.sh -
tools/optimize-rust.sh -
tools/optimize-wasm.sh
这个我们在之前的Rust赋能前端:为WebAssembly 瘦身中介绍过相关概念,这里就不在赘述了。
核心参数
在之前呢,我们解释了从前端环境传人到wasm的参数的含义。其实呢,之前的InputJson只是为了能够方便的收集前端的Table信息。基于这些信息去拼装最后要生成excel必须的数据格式。
type Dict = HashMap<String, String>;
#[derive(Debug, Deserialize)]
pub struct ColumnData {
pub width: f32,
}
#[derive(Deserialize)]
pub struct SheetData {
name: Option<String>,
plain: Option<Vec<Vec<Option<String>>>>,
cols: Option<Vec<Option<ColumnData>>>,
merged: Option<Vec<MergedCell>>,
}
#[derive(Deserialize)]
pub struct SpreadsheetData {
data: SheetData,
}
如上面所示,我们定义了一个SpreadsheetData。
-
data:就是用于构建我们excel的数据信息`
在data中,我们接收一个SheetData类型的结构体。其中每个字段的含义如下
-
name:和之前一样,用于设置每个sheet的名称 -
plain:承载每个cell的值 -
cols:用于配置每个col的宽度 -
merged:用于配置合并信息
数据转换函数
那么,我们现在要做的最核心的部分就是将从前端环境接收的json对象转换为SpreadsheetData。
函数 process_json 的作用是:
-
接收一个 JsValue类型的JSON数据。 -
将其解析为特定的 Rust结构体InputJson。 -
根据解析后的数据,构造一个 SpreadsheetData类型的对象,包含处理后的表格数据及其样式等信息。
fn process_json(raw_data: &JsValue) -> SpreadsheetData {
let input: InputJson = match raw_data.into_serde() {
Ok(data) => data,
Err(err) => {
// 记录日志或返回默认值
utils::log!("Failed to parse JSON: {:?}", err);
return SpreadsheetData {
data: vec![],
styles: None,
};
}
};
let mut plain = vec![
input.columns
.iter()
.map(|col| Some(col.title.clone()))
.collect::<Vec<Option<String>>>()
];
for source_row in &input.source {
let mut row = Vec::new();
for column in &input.columns {
let value = source_row.get(&column.dataIndex).map(|v| {
match v {
serde_json::Value::String(s) => s.clone(),
serde_json::Value::Number(n) => n.to_string(),
serde_json::Value::Bool(b) => b.to_string(),
_ => String::new(),
}
});
row.push(value);
}
plain.push(row);
}
let cols = extract_width(&input.columns);
let merged: Option<Vec<MergedCell>> = match input.merge {
Some(merge) if !merge.is_empty() => Some(merge),
None =>
match input.correlation {
Some(ref correlation) if !correlation.is_empty() =>
Some(handle_merge_info(correlation.clone(), &input.source, &input.columns)),
_ => None,
}
_ => None,
};
// 构造输出数据
let output_data = SheetData {
name: Some(input.name.clone()),
plain: Some(plain),
merged: merged,
cells: None,
rows: None,
cols: Some(cols),
};
SpreadsheetData {
data: vec![output_data],
styles: None,
}
}
1. JSON 解析
let input: InputJson = match raw_data.into_serde() {
Ok(data) => data,
Err(err) => {
// 记录日志或返回默认值
utils::log!("Failed to parse JSON: {:?}", err);
return SpreadsheetData {
data: vec![],
styles: None,
};
}
};
-
作用: -
将传入的 raw_data转换为 Rust 的InputJson结构体。 -
使用了 serde_wasm_bindgen::from_value(通过into_serde方法),将 JavaScript 的JsValue转为 Rust 的结构体。 -
如果解析失败,记录日志并返回一个空的默认值。
-
2. 构造表格的标题行
let mut plain = vec![
input.columns
.iter()
.map(|col| Some(col.title.clone()))
.collect::<Vec<Option<String>>>()
];
-
作用: -
plain是最终表格数据的二维数组,第一行用于存储列的标题。 -
遍历 input.columns,提取每一列的标题col.title,并存储在一个Vec<Option<String>>中。 -
使用 Some(col.title.clone())包装标题,表示每个单元格的值可能为Option<String>。
-
3. 构造表格的每一行数据
for source_row in &input.source {
let mut row = Vec::new();
for column in &input.columns {
let value = source_row.get(&column.dataIndex).map(|v| {
match v {
serde_json::Value::String(s) => s.clone(),
serde_json::Value::Number(n) => n.to_string(),
serde_json::Value::Bool(b) => b.to_string(),
_ => String::new(),
}
});
row.push(value);
}
plain.push(row);
}
-
作用:
-
遍历每一行的源数据 input.source。 -
对每个列的 dataIndex进行查找,如果找到相应值,将其转换为字符串形式,并存储在row中。 -
将每一行的 row数据加入到plain。
-
-
核心逻辑:
-
动态数据处理:根据列的 dataIndex从source_row中提取对应的值。 -
类型处理:处理可能的 JSON数据类型,包括字符串、数字、布尔值等,将它们统一转换为字符串。 -
默认值处理:如果数据类型不匹配或数据不存在,返回空字符串。
-
4. 提取列宽信息
let cols = extract_width(&input.columns);
-
作用: -
提取每一列的宽度信息。 -
extract_width应该是一个自定义函数,用于从columns中获取列的width属性或其默认值。
-
5. 合并单元格的处理
let merged: Option<Vec<MergedCell>> = match input.merge {
Some(merge) if !merge.is_empty() => Some(merge),
None => match input.correlation {
Some(ref correlation) if !correlation.is_empty() =>
Some(handle_merge_info(correlation.clone(), &input.source, &input.columns)),
_ => None,
},
_ => None,
};
-
作用:
-
处理表格的合并单元格信息。 -
如果 input.merge提供了明确的合并信息,则直接使用。 -
如果未提供 merge信息但存在correlation信息,则通过handle_merge_info动态生成合并信息。
-
-
核心逻辑:
-
优先级: merge的优先级高于correlation。 -
处理了合并信息的多种来源,确保灵活性。
-
提取列宽信息
extract_width 这个函数的主要功能是从一组列(columns)中提取每列的宽度信息,并以 ColumnData 的形式返回。返回的宽度值是以 f32 类型表示的,并且该函数处理了几种不同的数据格式(数值、字符串等)。如果某列没有明确的宽度或格式错误,默认宽度为 100.0。
fn extract_width(columns: &Vec<Column>) -> Vec<Option<ColumnData>> {
let mut cols = Vec::new();
for column in columns {
utils::log!("width {}", column.width);
let width: f32 = match &column.width {
serde_json::Value::Number(num) => {
num.as_f64()
.map(|n| n as f32)
.unwrap_or(100.0)
}
serde_json::Value::String(s) => {
if s.ends_with("px") {
s.trim_end_matches("px").parse::<f32>().unwrap_or(100.0)
} else {
s.parse::<f32>().unwrap_or(100.0)
}
}
_ => 100.0,
};
cols.push(Some(ColumnData { width }));
}
cols
}
其中最核心的部分就是解析列宽
let width: f32 = match &column.width {
serde_json::Value::Number(num) => {
num.as_f64()
.map(|n| n as f32)
.unwrap_or(100.0)
}
serde_json::Value::String(s) => {
if s.ends_with("px") {
s.trim_end_matches("px").parse::<f32>().unwrap_or(100.0)
} else {
s.parse::<f32>().unwrap_or(100.0)
}
}
_ => 100.0,
};
-
作用: -
这部分代码处理不同格式的列宽数据,并将其统一转换为 f32类型的宽度。 -
详细步骤: -
serde_json::Value::Number(num):-
如果 column.width是一个数字类型(如100),则尝试将其转换为f64类型,再转换为f32。 -
如果转换失败,则使用默认值 100.0。
-
-
serde_json::Value::String(s):-
如果 column.width是字符串类型(如"100px"或"100"),首先检查字符串是否以"px"结尾。-
如果是 px,去掉"px"后缀,再尝试将剩余的部分转换为f32。 -
如果字符串没有 px后缀,则直接尝试将其转换为f32。
-
-
如果解析失败,则使用默认值 100.0。
-
-
其他类型: -
如果 column.width既不是数字也不是字符串,则返回默认宽度100.0。
-
-
-
合并单元格的处理
这段代码的功能是根据给定的列索引和相关联的列数据,计算出需要合并的单元格信息。具体来说,它依据 correlation 中的列和行的值,确定哪些单元格的内容是相同的,并根据这些相同的值来决定哪些单元格需要合并。最后,返回一个 MergedCell 的集合,其中包含了所有需要合并的单元格区域。
fn handle_merge_info(
correlation: Vec<String>,
source: &[HashMap<String, serde_json::Value>],
columns: &[Column]
) -> Vec<MergedCell> {
let mut merged_cells = Vec::new();
// 找到所有 correlation 对应的列索引
let column_index_map: HashMap<&String, usize> = columns
.iter()
.enumerate()
.map(|(idx, col)| (&col.dataIndex, idx))
.collect();
// 遍历 correlation 列,按顺序依次处理
for (level, correlation_key) in correlation.iter().enumerate() {
if let Some(&col_idx) = column_index_map.get(correlation_key) {
let mut row_span_start = None; // 记录当前合并区域的起始行
for (row_idx, item) in source.iter().enumerate() {
// 当前行该列的值
let current_value = item.get(correlation_key).cloned();
// 上一行该列的值
let previous_value = if row_idx > 0 {
source[row_idx - 1].get(correlation_key).cloned()
} else {
None
};
// 检查当前列是否需要合并
let is_same_value = current_value == previous_value;
// 如果是多列(level > 0),检查前置列的值是否也一致
let is_parent_matching = if level > 0 {
(0..level).all(|parent_level| {
if let Some(parent_key) = correlation.get(parent_level) {
let parent_current = item.get(parent_key);
let parent_previous = if row_idx > 0 {
source[row_idx - 1].get(parent_key)
} else {
None
};
parent_current == parent_previous
} else {
false
}
})
} else {
true
};
if is_same_value && is_parent_matching {
// 如果满足合并条件,继续处理
if row_span_start.is_none() {
row_span_start = Some(row_idx); // 记录合并起点
}
} else {
// 如果不满足条件,结束当前合并区域
if let Some(start_row) = row_span_start {
merged_cells.push(MergedCell {
from: CellCoords::new(start_row, col_idx),
to: CellCoords::new(row_idx, col_idx),
});
row_span_start = None; // 重置合并起点
}
}
}
// 处理最后一个合并区域
if let Some(start_row) = row_span_start {
merged_cells.push(MergedCell {
from: CellCoords::new(start_row, col_idx),
to: CellCoords::new(source.len(), col_idx),
});
}
}
}
merged_cells
}
以下是比较重要的点
1. 创建列索引映射 column_index_map
let column_index_map: HashMap<&String, usize> = columns
.iter()
.enumerate()
.map(|(idx, col)| (&col.dataIndex, idx))
.collect();
-
作用: -
创建一个映射,将列的 dataIndex映射到其对应的索引位置。这个映射用于快速查找每个列的索引。 -
column_index_map以&String(列的dataIndex)为键,列的索引usize为值。
-
2. 遍历 correlation 中的每个关联列
for (level, correlation_key) in correlation.iter().enumerate() {
if let Some(&col_idx) = column_index_map.get(correlation_key) {
let mut row_span_start = None; // 记录当前合并区域的起始行
-
作用: -
遍历 correlation列表中的每个correlation_key,表示需要根据该列的数据来判断是否合并单元格。 -
如果当前列的 dataIndex在column_index_map中存在,表示可以找到该列的索引col_idx。 -
row_span_start用于标记当前合并区域的起始行,初始值为None。
-
3. 遍历 source 中的数据行
for (row_idx, item) in source.iter().enumerate() {
let current_value = item.get(correlation_key).cloned();
let previous_value = if row_idx > 0 {
source[row_idx - 1].get(correlation_key).cloned()
} else {
None
};
let is_same_value = current_value == previous_value;
-
作用: -
遍历表格的每一行 source,在每一行中,根据当前的correlation_key获取该列的值 (current_value),并与上一行相同列的值进行比较 (previous_value)。 -
is_same_value用来判断当前行与上一行该列的值是否相同。
-
4. 检查前置列是否匹配(多级合并)
let is_parent_matching = if level > 0 {
(0..level).all(|parent_level| {
if let Some(parent_key) = correlation.get(parent_level) {
let parent_current = item.get(parent_key);
let parent_previous = if row_idx > 0 {
source[row_idx - 1].get(parent_key)
} else {
None
};
parent_current == parent_previous
} else {
false
}
})
} else {
true
};
-
作用: -
如果 level > 0,表示这是一个多级合并,需要检查前置列的数据是否也相同。具体来说,检查在correlation中的前置列是否满足合并条件。 -
使用 (0..level).all()检查correlation列表中前level个列是否都满足合并条件,即当前行的前置列与上一行的值是否一致。 -
is_parent_matching表示当前行是否符合前置列的匹配条件。
-
5. 合并条件判断与合并区域记录
if is_same_value && is_parent_matching {
if row_span_start.is_none() {
row_span_start = Some(row_idx); // 记录合并起点
}
} else {
if let Some(start_row) = row_span_start {
merged_cells.push(MergedCell {
from: CellCoords::new(start_row, col_idx),
to: CellCoords::new(row_idx, col_idx),
});
row_span_start = None; // 重置合并起点
}
}
-
作用: -
如果当前行与上一行在 correlation_key列的数据值相同,并且所有前置列(parent)的值也一致,则认为满足合并条件。 -
如果 row_span_start是None,则表示当前合并区域还没有开始,记录下合并的起始行(row_idx)。 -
如果当前行的数据值与上一行不相同,说明合并区域结束,记录当前合并区域,生成一个 MergedCell对象,表示从start_row到row_idx的合并区域。 -
重置 row_span_start为None。
-
6. 处理最后一个合并区域
if let Some(start_row) = row_span_start {
merged_cells.push(MergedCell {
from: CellCoords::new(start_row, col_idx),
to: CellCoords::new(source.len(), col_idx),
});
}
-
作用: -
在遍历结束后,如果 row_span_start仍然存在,说明最后一个合并区域没有被处理,使用该区域的起始行和最后一行(source.len())来生成最后一个合并区域,并将其添加到merged_cells中。
-
4. 将构造好的函数,扔给我们的excel渲染引擎
pub fn generate_excel(raw_data: &JsValue) -> Vec<u8> {
utils::set_panic_hook();
let data = process_json(raw_data);
// 省略部分代码
}
❝由于这块的篇幅有点冗长,为了行文的方便,这里就不在继续介绍了。
最后,我们会为大家提供编译好的wasm。然后以供大家使用。(由于文章是多平台发布的,如果大家找不到相关的资源,可以在评论区或者后台私聊我,要前端项目代码和wasm)
4. TODO
其实呢,无论是上面的使用示例还是代码,我们还有很多的未完善的部分。
-
表头合并 -
设置样式 -
多表导出(一次导出多个 sheet) -
支持 excel公式 -
....
后记
分享是一种态度。
全文完,既然看到这里了,如果觉得不错,随手点个赞和“在看”吧。

SheetJS: https://docs.sheetjs.com/docs/
[2]antd-table表格行/列合并: https://ant-design.antgroup.com/components/table-cn#table-demo-colspan-rowspan
本文由 mdnice 多平台发布



