SQL_on_Hadoop
SQL on Hadoop 概述
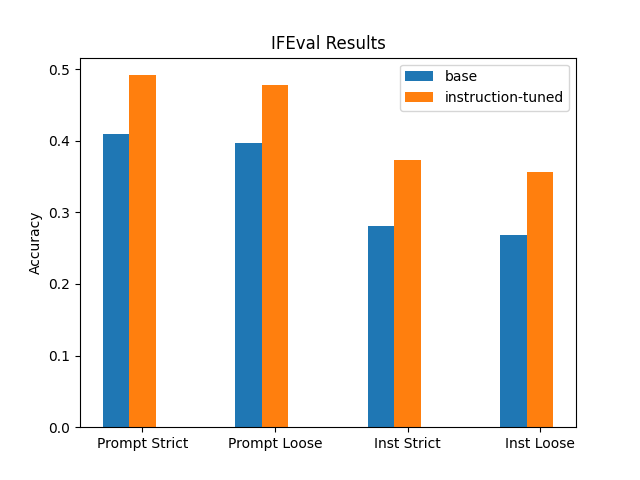
Hadoop 提供了一种分布式存储和计算的平台,为了解决传统关系型数据库无法处理海量数据的问题,通过扩展 SQL 的方式在 Hadoop 上执行分布式查询,称之为 SQL on Hadoop。根据架构的不同,分为四种主要类型:
-
Outside Hadoop
- 借助连接器实现 SQL 直接访问 Hadoop 数据。
- SQL 引擎通常运行在 Hadoop 系统外部,作为一个桥梁查询 HDFS 数据。
-
Alongside Hadoop
- 通过混合架构,在修改后的 SQL 中结合 MapReduce 引擎分担查询任务。
- 一部分查询交由 SQL 执行,另一部分通过 MapReduce 完成。
-
On Hadoop
- Hadoop 提供集中式 SQL 功能。实现方式:
- 将 SQL 转化为 MapReduce 动作来执行。
- 或基于 HDFS 上的执行计划树,分发任务到各节点,不依赖 MapReduce。
- Hadoop 提供集中式 SQL 功能。实现方式:
-
In Hadoop
SQL on Hadoop: HiveQL
HiveQL 简介
HiveQL 是 Apache Hive 提供的一种类似 SQL 的查询语言,专为在 Hadoop 上对大规模数据进行管理和查询设计。
HiveQL 支持以下主要操作:
- 查询(
SELECT、FROM、WHERE) - 分组(
GROUP BY) - 排序(
ORDER BY) - 限制(
LIMIT)
HiveQL 的特点
- 分区与排序:
- Distribute By:
类似 MapReduce 中的分区(partition),决定数据在不同分区中的分布。 - Sort By:
在每个分区中局部排序。 - Order By:
全局排序,需经过一次 reduce 操作。 - Cluster By:
将Distribute By和Sort By结合,同时按字段分区和排序。
- Distribute By:
HiveQL 示例语法
sql">SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[HAVING having_condition]
[CLUSTER BY col_list | DISTRIBUTE BY col_list [SORT BY col_list]]
[LIMIT number];
HiveQL 示例
下面是一个基于 HiveQL 的查询示例:
数据模型
假设有以下表:
customer:客户信息。orders:订单信息。lineitem:订单详情。
示例查询
sql">SELECT l_orderkey, SUM(l_extendedprice * (1 - l_discount)) AS revenue,o_orderdate, o_shippriority
FROM customer c
JOIN orders o ON c.c_custkey = o.o_orderkey
WHERE c.c_mktsegment = 'BUILDING'AND o_orderdate < '1995-03-15'AND l_shipdate > '1995-03-15'
GROUP BY l_orderkey, o_orderdate, o_shippriority
ORDER BY revenue DESC, o_orderdate;
关键操作解析
- JOIN:
- 将
customer表与orders表按指定条件进行关联。
- 将
- 过滤(
WHERE):- 限制在满足市场细分和日期范围的记录中操作。
- 聚合(
SUM):- 对订单详情表按
l_orderkey进行汇总计算。
- 对订单详情表按
- 分组(
GROUP BY):- 按订单键、订单日期和优先级分组。
- 排序(
ORDER BY):- 按收入降序排序,同时对日期进行次序排序。
这个例子展示了 HiveQL 如何通过 MAP 和 REDUCE 关键字直接调用用户自定义的 MapReduce 程序(如 Python 脚本)来实现复杂的逻辑。以下是这个例子的详细解析:
例子说明
目标
利用 HiveQL 嵌入自定义 MapReduce 程序来完成 词频统计。
数据
- 表
docs:包含两列,docid和doctext。docid:文档的唯一标识符。doctext:文档的正文。
语法分解
1. FROM docs
sql">FROM docs
- 从 Hive 表
docs中读取数据,提取所需字段(这里是doctext)。
2. MAP 操作
sql">MAP doctext
USING 'python wordcount_mapper.py' AS (word, cnt)
MAP doctext:将docs表中的doctext列传递给自定义的 Mapper 脚本。USING:指定执行 Map 操作的脚本,这里是python wordcount_mapper.py。AS (word, cnt):定义 Mapper 脚本的输出字段:word:从文本中提取的单词。cnt:对应的计数(通常是1,表示每个单词出现了一次)。
Mapper 脚本
wordcount_mapper.py:
输入:每一行的文档文本。
输出:以(word, 1)的格式输出每个单词及其初始计数。
3. CLUSTER BY
sql">CLUSTER BY word
CLUSTER BY:对 Mapper 的输出按照word字段进行分区,相同的word会被分配到同一个 Reducer。- 这是 MapReduce Shuffle 阶段的关键步骤,用于确保 Reducer 能处理分组后的数据。
4. REDUCE 操作
sql">REDUCE it.word, it.cnt
USING 'python wordcount_reduce.py'
REDUCE it.word, it.cnt:定义 Reducer 的输入。- 这里
it.word和it.cnt是 Map 阶段输出的字段。
- 这里
USING:指定执行 Reduce 操作的脚本,这里是python wordcount_reduce.py。- Reducer 的任务是对每个单词的计数进行汇总。
Reducer 脚本
wordcount_reduce.py:
输入:每个word分组及其所有cnt值。
输出:以(word, total_cnt)的格式输出单词及其总频率。
5. 嵌套子查询(FROM 子查询)
sql">FROM (FROM docsMAP doctextUSING 'python wordcount_mapper.py' AS (word, cnt)CLUSTER BY word
) it
- 这是一个嵌套子查询,命名为
it。 - 子查询的结果(Mapper 的输出经过分区)会作为输入提供给 Reduce 阶段。
完整 HiveQL 查询
sql">FROM (FROM docsMAP doctextUSING 'python wordcount_mapper.py' AS (word, cnt)CLUSTER BY word
) it
REDUCE it.word, it.cnt
USING 'python wordcount_reduce.py';
使用场景
- 复杂数据处理:如果 HiveQL 无法表达特定的逻辑(如自定义统计、数据转换),可以通过嵌入 MapReduce 程序扩展功能。
- 使用已有代码:将现有的 MapReduce 脚本直接集成到 Hive 查询中,减少开发工作量。
- 文本处理:例如日志解析、自然语言处理中的预处理步骤。
总结
HiveQL 调用 MapReduce 是扩展 Hive 功能的重要方式。通过 MAP 和 REDUCE 关键字,用户可以嵌入自己的自定义程序,将复杂的计算逻辑集成到 Hive 的查询流程中。这种机制不仅保持了 HiveQL 的简洁性,还提供了 MapReduce 的强大计算能力,非常适合处理大规模的非结构化和半结构化数据。