简介:本文从RNN与LSTM的原理讲起,在手写体识别上进行代码实战。同时列举了优化思路与优化结果,都是基于Tensorflow1.14.0的环境下,希望能给您的神经网络学习带来一定的帮助。如果您觉得我讲的还行,希望可以得到您的点赞收藏关注。
RNN与LSTM,通过Tensorflow在手写体识别上实战
- 1 RNN理论基础
- 1.1网络结构
- 1.2 RNN存在的问题
- 1.3衍生出LSTM
- 2 代码实现
- 2.1 导包
- 2.2 导入数据集
- 2.3 变量准备
- 2.4 准备占位符
- 2.5 初始化权重和偏置值
- 2.6 RNN网络
- 2.7 损失函数Loss
- 2.8 计算准确率
- 2.9Session训练
- 2.10运行结果
- 3 优化
- 3.1 网络结构优化
- 3.2学习率的变化
- 致谢
1 RNN理论基础
1.1网络结构
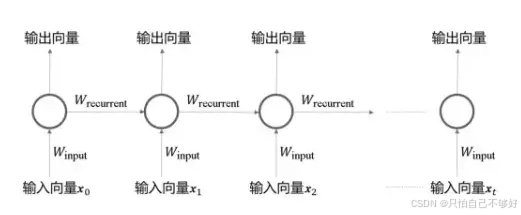
上一个神经元的输出Wrecurrent会作为下一个神经元的输入的一部分。
1.2 RNN存在的问题
第一个神经元的输出对第五个神经元的决策影响较少,存在梯度消失的问题。可以使用线性的激活函数,不会减弱。但是这个网络就没有选择性,靠谱和不靠谱的结果都会被记录
1.3衍生出LSTM
下面是LSTM的结果,看不懂没关系,下面会拆解成三个部分具体讲解,耐心看完就懂了

分为三个门,第一个门是遗忘门

第二个门是输入门

第三个门是输出门:

2 代码实现
2.1 导包
因为我是使用的jupyter运行的,所以我导入了import warnings避免一些不必要的警告,如果你使用的是pycharm就不用加跟warings相关的包了
import warnings
warnings.filterwarnings("ignore", category=FutureWarning)
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
2.2 导入数据集
mnist = input_data.read_data_sets("MNIST_DATA",one_hot=True)
2.3 变量准备
因为手写体数据集的图片大小是 28*28,他放在RNN中相当输入层一行序列有28个神经元,有28行输入
n_inputs =28 # 一行有28个数据
max_time = 28 # 一共有28行
设计隐藏层单元100,十个分类,每批次50个样本,计算批次数
lstm_size = 100
n_classes = 10
batch_size = 50
n_batch = mnist.train.num_examples // batch_size
2.4 准备占位符
x = tf.compat.v1.placeholder(tf.float32,[None,784])
y = tf.compat.v1.placeholder(tf.float32,[None,10])
2.5 初始化权重和偏置值
为了训练效果,采取生成正态分布标准差为0.1的初始权重
weights = tf.Variable(tf.random.truncated_normal([lstm_size,n_classes],stddev=0.1))
biases = tf.Variable(tf.constant(0.1,shape=[n_classes]))
2.6 RNN网络
这个函数的作用是定义网络,有几个知识点需要讲
- tf.nn.dynamic_rnn这个构建循环神经网络的函数的输入inputs 需要满足的格式[batch_size,max_time,n_inputs]
- tf.nn.dynamic_rnn返回值有两个第一个outputs他是每一次的输出,如果参数time_major = False,他的内容为[batch_size,max_time,cell.output_size],反之为[max_time,batch_size,cell.output_size]
- 另一个是final——state,他有三个维度[state,batch_size,cell.state_size]
- final_state[0] = cell state 中间信号,final_state[1] = hidden_state 一次时间序列的最后一次输出的结果,在这里就是28次时间序列因为图片是28*28
def RNN(X,weights,biases):inputs = tf.reshape(X,[-1,max_time,n_inputs])lstm_cell =tf.contrib.rnn.BasicLSTMCell(lstm_size, reuse=tf.compat.v1.AUTO_REUSE)# inputs = [batch_size,max_time,n_inputs]# final_state[state,batch_size,cell.state_size]# final_state[0] = cell state 中间信号# final_state[1] = hidden_state 一次时间序列的最后一次输出的结果,在这里就是28次时间序列# outputs # if time_major = False# [batch_size,max_time,cell.output_size]# if time_major = True# [max_time,batch_size,cell.output_size]# outputs是所有的结果outputs,final_state = tf.nn.dynamic_rnn(lstm_cell,inputs,dtype = tf.float32)results = tf.nn.softmax(tf.matmul(final_state[1],weights)+biases)return results
2.7 损失函数Loss
prediction = RNN(x,weights,biases)
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=prediction,labels=y))
2.8 计算准确率
使用adam优化器 学习率设置为0.0001然后比对正确结果在计算均值化为准确率
train_step = tf.compat.v1.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(prediction,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
2.9Session训练
init = tf.compat.v1.global_variables_initializer()
with tf.compat.v1.Session() as sess:sess.run(init)for epoch in range(6):for batch in range(n_batch):batch_xs,batch_ys = mnist.train.next_batch(batch_size)sess.run(train_step,feed_dict={x:batch_xs,y:batch_ys})acc = sess.run(accuracy,feed_dict={x:mnist.test.images,y:mnist.test.labels})print(f"第{epoch+1}次epoch,Accuracy = {str(acc)}")
2.10运行结果
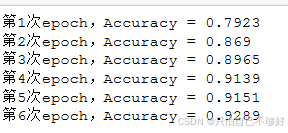
效果一般不是很理想,我们优化一下
3 优化
3.1 网络结构优化
原本只有一层lstm,现在多加一层看看,效果有没有提升
def RNN(X, weights, biases):inputs = tf.reshape(X, [-1, max_time, n_inputs])num_layers = 2 # 可以自行调整层数,比如设置为2、3等cells = [tf.contrib.rnn.BasicLSTMCell(lstm_size, reuse=tf.compat.v1.AUTO_REUSE) for _ in range(num_layers)]stacked_lstm = tf.contrib.rnn.MultiRNNCell(cells)outputs, final_state = tf.nn.dynamic_rnn(stacked_lstm, inputs, dtype=tf.float32)results = tf.nn.softmax(tf.matmul(final_state[-1][1], weights) + biases) # 注意这里取最后一层的 hidden_statereturn results

3.2学习率的变化
每经过一百步降低学习率到原来的0.96,经过20个epoch看看效
global_step = tf.Variable(0, trainable=False)
learning_rate = tf.compat.v1.train.exponential_decay(1e-4, global_step, decay_steps=100, decay_rate=0.96)with tf.variable_scope(tf.get_variable_scope(), reuse=tf.AUTO_REUSE):train_step = tf.compat.v1.train.AdamOptimizer(learning_rate).minimize(cross_entropy,global_step=global_step)
correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(prediction,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
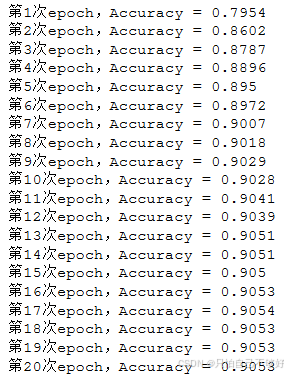
发现后面基本上学不到东西,学习率太低了 调高到 1e-3试试

相比于之前的百分之90已经算较为满意了,还是存在改良的提升空间,可以对衰减的步长decay_steps进行调整。当然了可以通过演化计算的算法去进行参数调优获得更好的结果,我推荐使用 哈里斯鹰,因为我大学做的毕业设计就是基于支持向量机和LSTM结合的使用哈里斯鹰优化参数的情感极性分析,所以我对这个比较拿手,但是这又不是毕业设计,没必要话这么多时间进行参数调优,主要就是太麻烦了。
致谢
本文参考了一些博主的文章,博取了他们的长处,也结合了我的一些经验,对他们表达诚挚的感谢,使我对 LSTM 的使用有更深入的了解,也推荐大家去阅读一下他们的文章。纸上学来终觉浅,明知此事要躬行:
LSTM从入门到精通(形象的图解,详细的代码和注释,完美的数学推导过程)