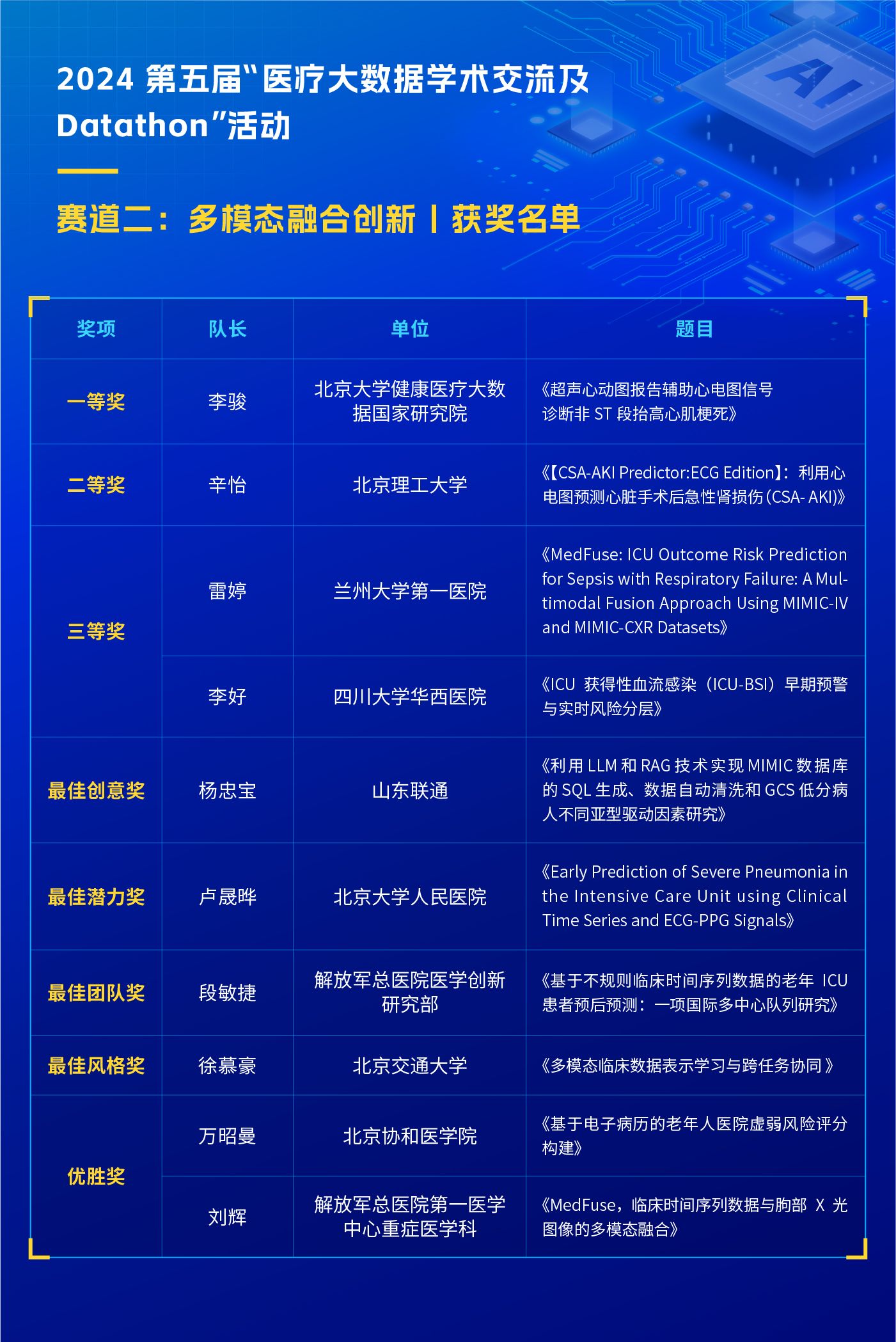
人工智能学习框架在机器学习、深度学习和其他AI任务中发挥着关键作用。
一、TensorFlow
TensorFlow是由Google开发的开源机器学习框架,广泛应用于学术界和工业界。它支持多种编程语言,包括Python、C++和Java,并具有强大的社区支持和丰富的文档资源。
1. 特点
- 灵活性:支持多种类型的机器学习任务,包括深度学习、强化学习等。
- 可扩展性:可以在单个CPU、GPU或多台机器上运行,支持分布式训练。
- 生产环境友好:提供了多种工具和库,如TensorBoard用于可视化训练过程,TF Serving用于模型部署。
2. 应用场景
- 大规模数据处理和分布式训练
- 生产环境中的模型部署
- 高性能计算和科研项目
3. 实例:使用TensorFlow构建简单的神经网络
以下是使用TensorFlow构建并训练一个简单神经网络,用于手写数字识别(MNIST数据集)的示例代码:
python复制代码
import tensorflow as tf | |
from tensorflow.keras import layers, models | |
from tensorflow.keras.datasets import mnist | |
from tensorflow.keras.utils import to_categorical | |
# 加载数据 | |
(train_images, train_labels), (test_images, test_labels) = mnist.load_data() | |
# 数据预处理 | |
train_images = train_images.reshape((60000, 28, 28, 1)).astype('float32') / 255 | |
test_images = test_images.reshape((10000, 28, 28, 1)).astype('float32') / 255 | |
train_labels = to_categorical(train_labels) | |
test_labels = to_categorical(test_labels) | |
# 构建模型 | |
model = models.Sequential([ | |
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)), | |
layers.MaxPooling2D((2, 2)), | |
layers.Conv2D(64, (3, 3), activation='relu'), | |
layers.MaxPooling2D((2, 2)), | |
layers.Conv2D(64, (3, 3), activation='relu'), | |
layers.Flatten(), | |
layers.Dense(64, activation='relu'), | |
layers.Dense(10, activation='softmax') | |
]) | |
# 编译模型 | |
model.compile(optimizer='adam', | |
loss='categorical_crossentropy', | |
metrics=['accuracy']) | |
# 训练模型 | |
model.fit(train_images, train_labels, epochs=5, batch_size=64) | |
# 评估模型 | |
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2) | |
print(f'Test accuracy: {test_acc}') |
二、PyTorch
PyTorch是由Facebook开发的开源机器学习框架,以其动态计算图和易于使用的API而著称。它在自然语言处理和计算机视觉领域有广泛的应用。
1. 特点
- 动态计算图:支持动态图的构建和修改,适合复杂的模型和研究项目。
- 易于调试:提供了丰富的调试工具,方便开发者调试模型。
- 社区活跃:拥有庞大的开发者社区和丰富的第三方库。
2. 应用场景
- 研究和实验项目
- 自然语言处理和计算机视觉
- 动态图模型的构建和训练
3. 实例:使用PyTorch进行图像分类(卷积神经网络)
以下是使用PyTorch构建并训练一个简单的卷积神经网络,用于CIFAR-10数据集的分类任务的示例代码:
python复制代码
import torch | |
import torch.nn as nn | |
import torch.optim as optim | |
from torchvision import datasets, transforms | |
# 定义一个简单的卷积神经网络 | |
class Net(nn.Module): | |
def __init__(self): | |
super(Net, self).__init__() | |
self.conv1 = nn.Conv2d(3, 32, 3, 1) | |
self.conv2 = nn.Conv2d(32, 64, 3, 1) | |
self.fc1 = nn.Linear(64 * 8 * 8, 128) | |
self.fc2 = nn.Linear(128, 10) | |
def forward(self, x): | |
x = self.conv1(x) | |
x = nn.functional.relu(x) | |
x = self.conv2(x) | |
x = nn.functional.relu(x) | |
x = nn.functional.max_pool2d(x, 2) | |
x = nn.functional.max_pool2d(x, 2) | |
x = torch.flatten(x, 1) | |
x = self.fc1(x) | |
x = nn.functional.relu(x) | |
x = self.fc2(x) | |
output = nn.functional.log_softmax(x, dim=1) | |
return output | |
# 初始化模型、损失函数和优化器 | |
model = Net() | |
criterion = nn.CrossEntropyLoss() | |
optimizer = optim.Adam(model.parameters(), lr=0.001) | |
# 加载CIFAR-10数据集 | |
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]) | |
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) | |
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True) | |
# 训练模型 | |
for epoch in range(5): | |
for batch_idx, (data, target) in enumerate(train_loader): | |
optimizer.zero_grad() | |
output = model(data) | |
loss = criterion(output, target) | |
loss.backward() | |
optimizer.step() | |
if batch_idx % 100 == 0: | |
print(f'Epoch {epoch}, Batch {batch_idx}, Loss {loss.item()}') |
三、Scikit-learn
Scikit-learn是一个开源的Python机器学习库,它提供了大量的算法和工具,用于数据挖掘和数据分析。Scikit-learn的设计哲学是简单、一致和可扩展,使得开发人员可以快速构建和部署机器学习模型。
1. 特点
- 简单:提供了易于使用的API,使得机器学习模型的构建和训练变得简单。
- 一致:遵循一致的设计哲学,使得不同算法之间的接口保持一致。
- 可扩展:支持自定义算法和模型,方便研究人员和开发者进行扩展。
2. 应用场景
- 数据挖掘
- 数据分析
- 快速原型设计
3. 实例:使用Scikit-learn进行鸢尾花数据集分类
以下是使用Scikit-learn对鸢尾花(Iris)数据集进行分类的示例代码:
python复制代码
from sklearn.datasets import load_iris | |
from sklearn.model_selection import train_test_split | |
from sklearn.preprocessing import StandardScaler | |
from sklearn.neighbors import KNeighborsClassifier | |
from sklearn.metrics import classification_report, confusion_matrix | |
# 加载数据 | |
iris = load_iris() | |
X = iris.data | |
y = iris.target | |
# 划分数据集 | |
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) | |
# 数据标准化 | |
scaler = StandardScaler() | |
X_train = scaler.fit_transform(X_train) | |
X_test = scaler.transform(X_test) | |
# 创建KNN分类器 | |
knn = KNeighborsClassifier(n_neighbors=3) | |
# 训练模型 | |
knn.fit(X_train, y_train) | |
# 预测测试集 | |
y_pred = knn.predict(X_test) | |
# 输出分类报告和混淆矩阵 | |
print(classification_report(y_test, y_pred)) | |
print(confusion_matrix(y_test, y_pred)) |