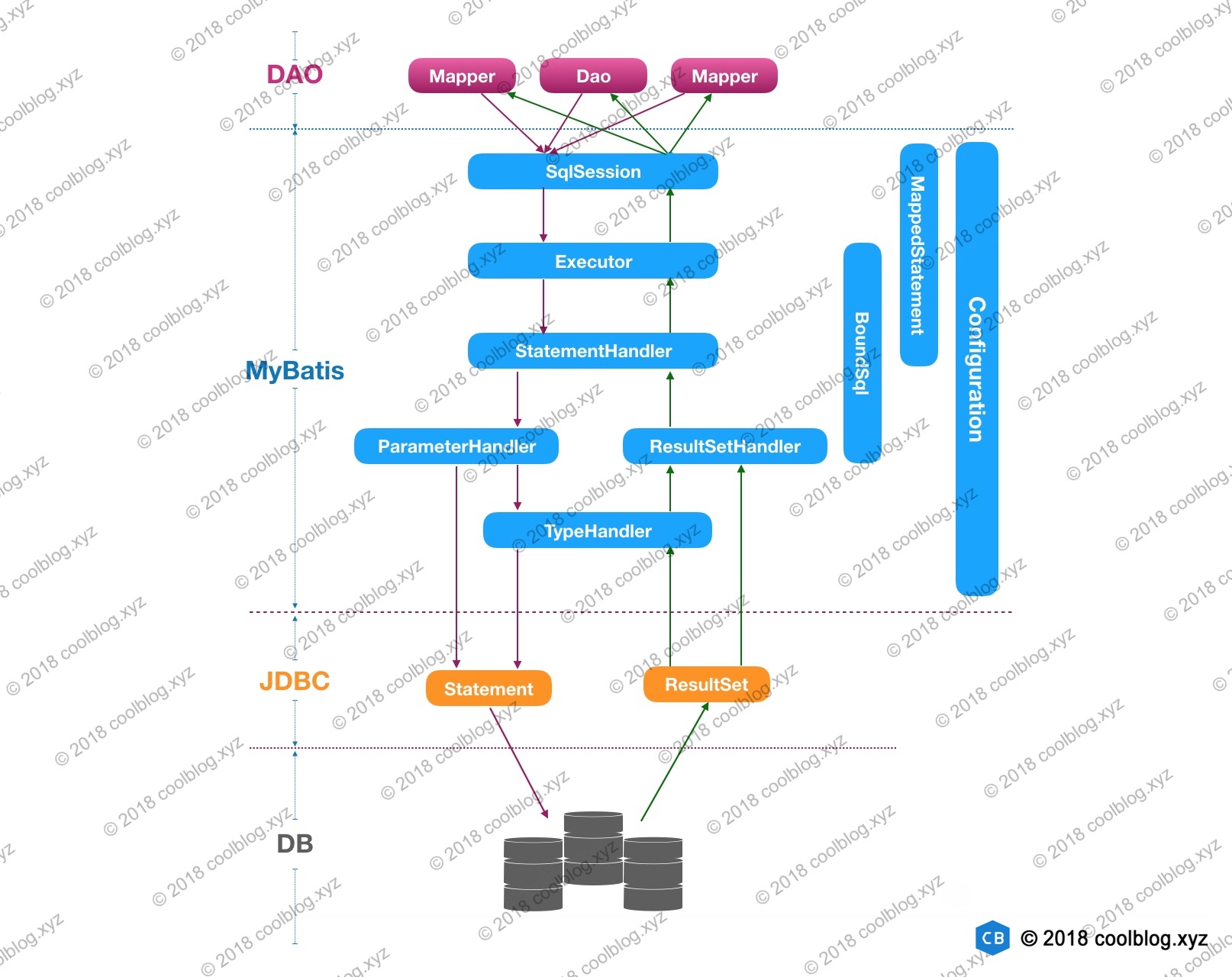
- 1. 概念
- 2. 实战
- 2.1. 新列的决定因素
- 2.2. 新列别名
- 2.3. column_list中指定多个字段
- 2.4. 多个聚合函数的使用
- 2.5. 最终出现在SQL结果中的决定因素
Spark pivot数据透视从句
1. 概念
- 描述
用于数据透视,根据特定的列获取聚合值,聚合值将转换为select子句中使用的多列。可以在表名或子查询后指定pivot子句 - 使用场景
常见的使用场景之一,对数据进行行转列操作 - 语法格式
select *
From Table
PIVOT ( { aggregate_expression [ AS aggregate_expression_alias ] } [ , ... ]FOR column_list IN ( expression_list ) )
column_list:可供选择的列为From子句中的列,将使用指定列下的值用于生成新的列。
expression_list:column_list中指定列的值。可以指定别名,指定别名后,则使用别名作为新列名,否则将直接使用列值作为新字段名。
接下来通过几个例子来理解pivot的具体用法。
2. 实战
构键测试数据
CREATE TABLE pivot1 (name STRING, subject string, score INT);
INSERT overwrite table pivot1
select inline(array(
struct('张三','语文',95),
struct('张三','英语',85),
struct('张三','数学',100),
struct('李四','语文',90),
struct('李四','英语',80),
struct('李四','数学',100),
struct('王五','语文',99),
struct('王五','数学',98)
));
2.1. 新列的决定因素
select *
from pivot1
pivot(max(score) as score1 for subject in('语文','英语','数学'));
-- 执行结果
name 语文 英语 数学
王五 99 NULL 98
李四 90 80 100
张三 95 85 100select *
from pivot1
pivot(max(score) as score1 for subject in('语文','英语'));
-- 执行结果
name 语文 英语
王五 99 NULL
李四 90 80
张三 95 85select *
from pivot1
pivot(max(score) as score1 for subject in('英语'));
-- 执行结果
name 英语
王五 NULL
李四 80
张三 85
结果中新列取决于column_list和expression_list的共同影响,在上述示例中表示将pivot1表中subject列下的值作为新的结果列,但是具体将哪些值作为新列,取决于in后面的字段值列表。
2.2. 新列别名
select name,c,e,m
from pivot1
pivot(max(score) as score1 for subject in('语文' as c,'英语' as e,'数学' as m));
-- 执行结果
name c e m
王五 99 NULL 98
李四 90 80 100
张三 95 85 100
在in中指定的别名将作为新列的名称。
2.3. column_list中指定多个字段
select *
from pivot1
pivot(max(score) as score1 for (subject,name) in(('语文','张三'),('语文','李四'),('语文','王五')));
-- 执行结果
[语文, 张三] [语文, 李四] [语文, 王五]
95 90 99
当column_list中指定多个字段时,须使用括号,并且expression_list中指定的字段值也需要使用括号,二者括号中内容顺序需要保持一致。
for (subject,name) in(('语文','张三'),('语文','李四'),('语文','王五'))最终决定测试表中只有以下数据参与计算。
'张三','语文',95
'李四','语文',90
'王五','语文',99
2.4. 多个聚合函数的使用
select *
from pivot1
pivot(max(score) as score1,avg(score) as avg for subject in('语文','英语','数学'));
-- 执行结果
name 语文_score1 语文_avg 英语_score1 英语_avg 数学_score1 数学_avg
王五 99 99.0 NULL NULL 98 98.0
李四 90 90.0 80 80.0 100 100.0
张三 95 95.0 85 85.0 100 100.0select *
from pivot1
pivot(max(score) as score1,avg(score) as avg for subject in('语文','英语'));
-- 执行结果
name 语文_score1 语文_avg 英语_score1 英语_avg
王五 99 99.0 NULL NULL
李四 90 90.0 80 80.0
张三 95 95.0 85 85.0
上述SQL1中,原始表中3个字段列,只有name列在pivot中未涉及,但是最终结果将会包含name列下的全部值。
理解聚合函数的聚合粒度是什么?
在in中指定的值将会作为聚合条件之一,同时由于name未参与pivot函数使得结果包含全部name列值,因此结合起来的聚合条件就是name+subject
这里得出部分结论
- column_list中已指定的列将不会出现在最终结果中
- 聚合函数中使用的列也不会出现在最终结果中
- 只有在column_list和聚合函数中都没有使用的列,才会原模原样出现在最终结果中,并且会将这些列作为聚合条件的一部分
2.5. 最终出现在SQL结果中的决定因素
select *
from pivot1
pivot(max(score) as score1,avg(score) as avg,count(subject) as cnt for name in('张三','李四','王五'));
-- 执行结果
张三_score1 张三_avg 张三_cnt 李四_score1 李四_avg 李四_cnt 王五_score1 王五_avg 王五_cnt
100 93.33 3 100 90.0 3 99 98.5 2select *
from pivot1
pivot(max(score) as score1,avg(score) as avg,count(score) as cnt for name in('张三','李四','王五'));
-- 执行结果
subject 张三_score1 张三_avg 张三_cnt 李四_score1 李四_avg 李四_cnt 王五_score1 王五_avg 王五_cnt
英语 85 85.0 1 80 80.0 1 NULL NULL NULL
语文 95 95.0 1 90 90.0 1 99 99.0 1
数学 100 100.0 1 100 100.0 1 98 98.0 1
上述示例1中pivot1表中所有的字段中都参与了pivot函数,或在聚合函数中或在for后,因此SQL执行结果中将不会包含测试表中的原始列,聚合条件即为name。
示例2中pivot1表中subject字段没有参与pivot函数,因此SQL执行结果中会包含subject列的全部值,然后该值会加入到聚合条件中,聚合条件为subject+name。