GPU在科研深度学习中的核心价值
在科研深度学习的范畴内,模型训练是核心环节。面对大规模参数的模型训练,这往往是科研过程中最具挑战性的部分。传统CPU的计算模式在处理复杂模型时,训练时间会随着模型复杂度的增加而急剧增长,这不仅延长了科研项目周期,消耗了宝贵的时间资源,还导致了计算成本的飙升,形成了资源的巨大浪费。更为严重的是,这极大地阻碍了模型的迭代优化进程,科研工作的进展因此受阻。

GPU的引入为科研深度学习训练带来了革命性的改变。GPU凭借强大的并行计算能力,在处理大规模数据时表现出色。它能将复杂的训练任务分割成众多小任务,并分配给多个核心同时处理,从而显著提升模型训练速度。此外,GPU的硬件架构针对矩阵运算和浮点运算进行了深度优化,这两种运算恰好是深度学习的核心需求。因此,在处理复杂算法和大规模数据的深度学习应用中,GPU发挥着至关重要的作用,为科研工作者提供了强大的计算支持。
科研服务器GPU优选解析
对于大型项目和科研机构而言,NVIDIA Tesla系列GPU在科研深度学习服务器领域占据重要地位。其强大的并行计算能力、丰富的软件生态以及广泛的适应性,能够满足科研项目中多样化的业务需求。

同时,Google TPU作为专为TensorFlow框架设计的AI加速器,也是深度学习领域的佼佼者。作为ASIC芯片,其架构和指令集针对TensorFlow进行了高度优化,仅在Google Cloud平台上可用。在TensorFlow模型训练和推理方面,TPU展现出显著优势。其单个设备的浮点运算性能高达420 TFLOPS,配备128GB高带宽内存(HBM),TPU Pod配置更是以超大规模集群形式提供超过100 PetaFLOPS的计算性能、32TB HBM及2D环形网状网络设计,适用于大规模并行计算的超大规模科研AI模型训练任务,如大规模科学模拟和复杂生物信息学研究。

对于个人深度学习爱好者、研究人员和开发者而言,他们更倾向于选择性能、显存和性价比相平衡的GPU。这些GPU通常搭载在个人电脑或小型工作站上,适用于小规模的深度学习任务,如模型开发、调试和小型项目的训练。
科研服务器中GPU与CPU的协同工作及GPU选择考量
科研服务器是专为深度学习计算任务构建的高性能计算机系统。在这个系统中,GPU和CPU等硬件相互协作,共同为复杂的深度学习算法提供算力支持。CPU主要负责处理操作系统相关任务、调度科研计算任务以及执行串行计算任务,是科研服务器系统的指挥中心。而GPU则专注于大规模并行计算,特别是在深度学习中大量涉及的矩阵运算和浮点运算方面,这对于科研项目中常见的复杂模型训练和大规模数据处理至关重要。

算力是衡量科研服务器处理能力的重要指标,它综合考虑了CPU和GPU的计算能力,以及服务器的内存、存储和网络等因素。强大的算力能够加速模型训练和推理过程,提高科研效率。因此,在为科研服务器选择GPU时,需要充分考虑服务器的整体算力需求以及GPU与其他硬件之间的协同工作能力。
科研机构级与终端用户级服务器GPU选择建议
在科研服务器环境下,高性能GPU和TPU的选择应根据科研项目的具体需求进行。例如,A100和V100适合需要高浮点性能的分布式深度学习科研任务;P100适合中等计算需求的HPC应用相关科研项目;K80更适合数据密集但计算强度适中的科研任务。若科研项目在Google Cloud上进行TensorFlow模型训练,则TPU是极具性价比的选择。

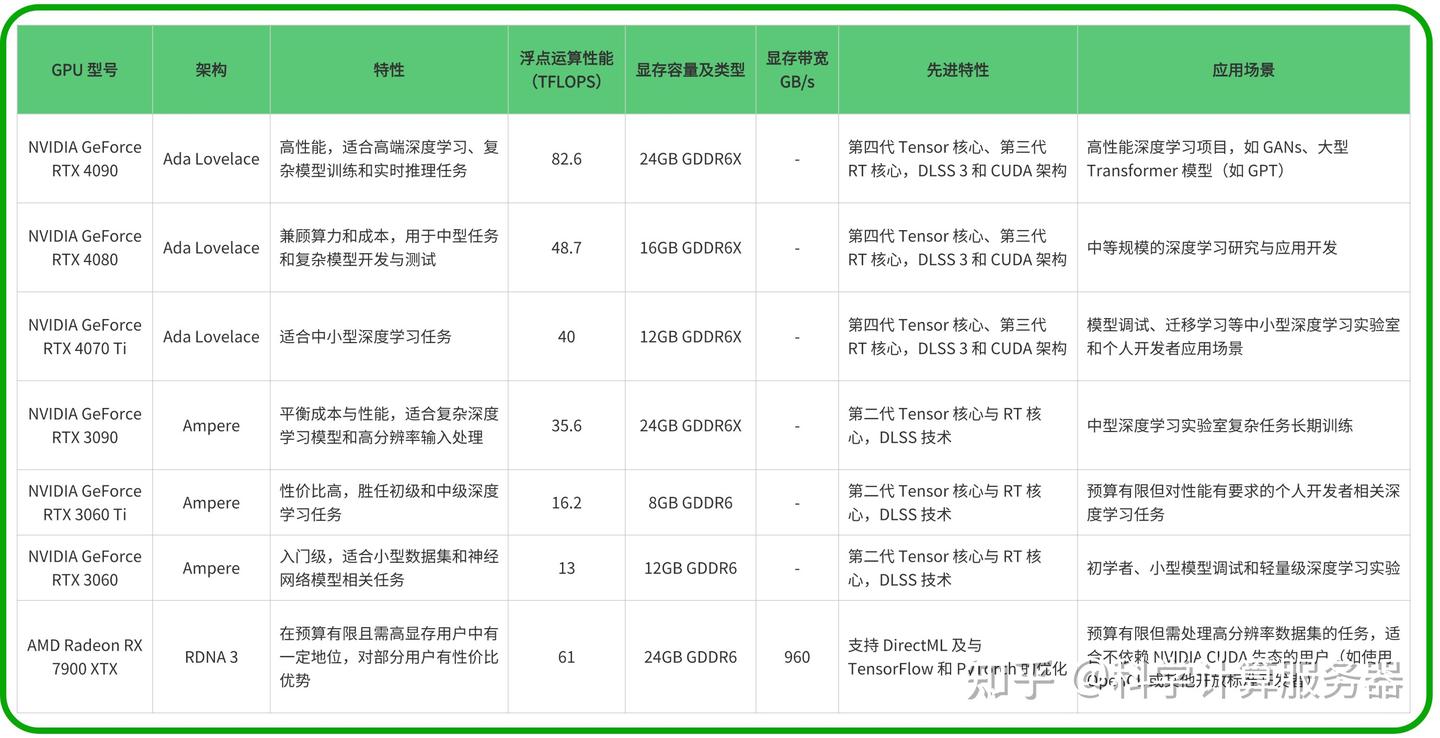
对于消费级GPU的选择,应综合考虑预算、深度学习任务的规模和复杂程度等因素。旗舰级的NVIDIA RTX 4090、RTX 3090适合高预算、处理复杂模型的大型项目;高性价比的NVIDIA RTX 4080、RTX 4070 Ti适合对性能有要求但预算有限的用户;入门级的NVIDIA RTX 3060 Ti、RTX 3060适合初学者、小型模型训练和调试任务;AMD Radeon RX 7900 XTX则适合高显存需求、预算较低且不依赖NVIDIA CUDA生态的用户。
总之,无论是科研服务器还是消费级场景,为深度学习选择GPU时都应全面考虑计算需求、数据规模、预算以及显存容量、计算性能和软件支持等因素。这样才能挑选到最合适的GPU,从而助力科研工作和深度学习实践的顺利开展。
#科研服务器##科学计算服务器##计算服务器##服务器##GPU服务器#






