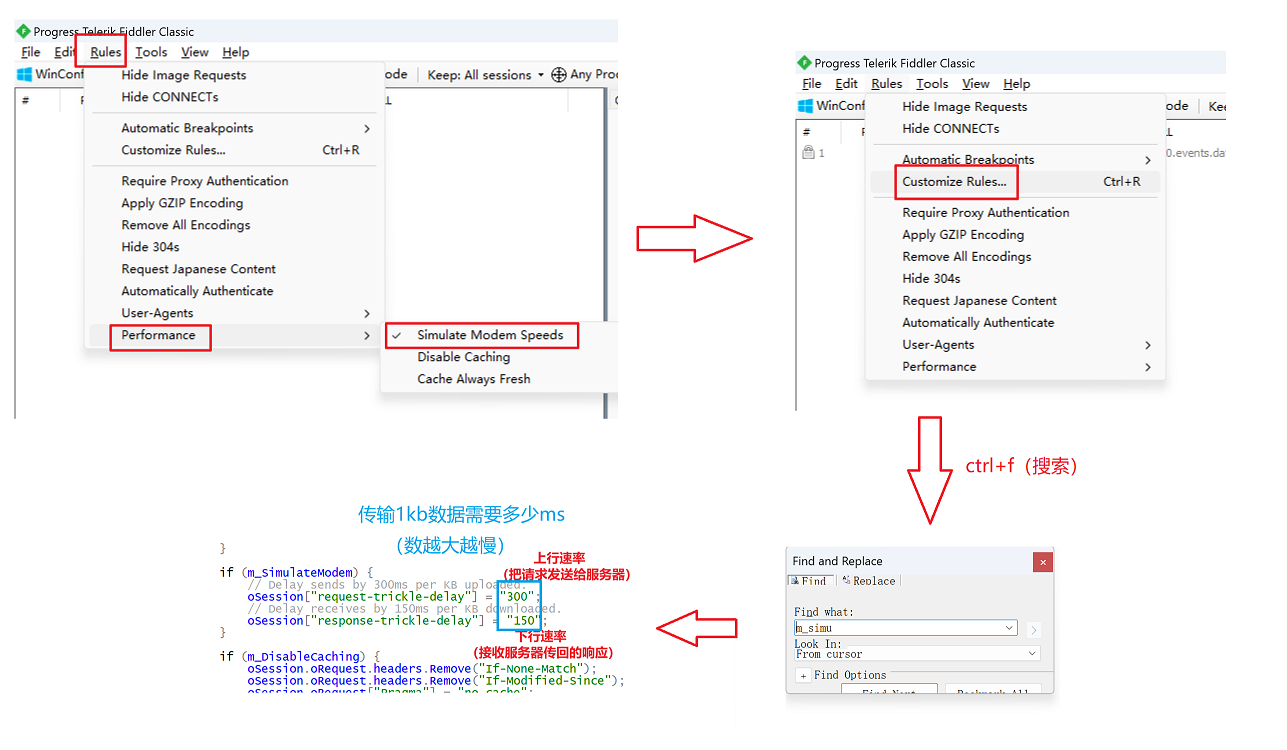
《Python OpenCV从菜鸟到高手》带你进入图像处理与计算机视觉的大门!
词向量是自然语言处理中的关键技术之一,将词语转换为向量表示能够捕捉语义信息并应用于机器学习模型中。本文将介绍词向量的基本概念,通过从零实现Word2Vec模型帮助读者掌握词向量的生成过程。同时,本文还将探讨FastText模型的优势,特别是在低频词处理上的改进。通过Python代码的实现和详解,我们将一步步展示如何构建词向量模型,并对比Word2Vec和FastText的性能,以便读者能够深入理解词嵌入技术及其在不同场景中的应用。
目录
- 词向量的基本概念
- Word2Vec模型简介
- 词袋模型与Word2Vec的差异
- Word2Vec的两种训练方法:CBOW与Skip-gram
- 使用Python实现Word2Vec模型
- FastText模型概述与优势
- 使用Python实现FastText模型
- Word2Vec与FastText的对比分析
- 实验与性能评估
- 总结与展望
正文
1. 词向量的基本概念
词向量(Word Embedding)是一种将单词转换为向量的技术,旨在用固定长度的向量表示自然语言中的词语,同时保留词语间的语义关系。词向量模型通过在大规模语料库中学习词语的上下文关系,生成包含语义信息的向量表示。词向量模型广泛应用于情感分析、机器翻译、问答系统和信息检索等任务中。
在词向量中,相似含义的词往往具有相似的向量表示。例如,“国王”和“王后”的词向量在空间中可能非常接近,而“狗”和“猫”之间的距离也会较近。
2. Word2Vec模型简介
Word2Vec是由Google在2013年提出的一种高效的词向量训练方法,旨在捕捉词语间的语义关系。Word2Vec的目标是通过学习一个大的文本语料库,使得词向量在低维空间中能够保留语义信息。Word2Vec有两种主要的训练方法:连续词袋模型(CBOW)和Skip-gram模型。
3. 词袋模型与Word2Vec的差异
在早期的自然语言处理任务中,词袋模型(Bag of Words,BOW)是一种简单且常见的表示方法。然而,词袋模型存在一些缺点:
- 无法保留词序信息。
- 无法捕捉词语之间的语义关系。
- 词向量的维度等于词汇表大小,容易导致稀疏向量。
相比之下,Word2Vec通过神经网络来生成密集的词向量,能够更好地保留词语的上下文和语义关系。
4. Word2Vec的两种训练方法:CBOW与Skip-gram
Word2Vec的核心思想是基于上下文来预测中心词或基于中心词来预测上下文。具体来说:
- 连续词袋模型(CBOW):利用上下文词语来预测目标词。例如,给定句子“我喜欢吃苹果”,CBOW模型会用“我”、“喜欢”、“吃”来预测“苹果”。
- Skip-gram模型:利用目标词来预测上下文词。例如,在“我喜欢吃苹果”中,Skip-gram会用“苹果”来预测“我”、“喜欢”、“吃”。
在数学上,CBOW和Skip-gram的目标可以通过最大化以下公式来实现:
对于CBOW模型,目标是最大化以下条件概率:
P ( w t ∣ w t − 2 , w t − 1 , w t + 1 , w t + 2 ) P(w_t | w_{t-2}, w_{t-1}, w_{t+1}, w_{t+2}) P(wt∣wt−2,wt−1,wt+1