在实际的生产应用中,基于高质量的有监督指令数据进行指令微调(Instruction Tuning)是一种提升大语言模型可控性和准确率的重要方法。指令微调是一种通过在包括指令-输出对(也称为问答对)的数据集上进一步训练大型语言模型的过程,其特殊之处在于其数据集的结构,即由人类指令和期望的输出组成的配对。这种结构使得指令微调专注于通过理解和遵循人类指令来增强大语言模型的能力和可控性。
然而,高质量有监督指令数据的稀缺性限制了指令微调在各行各业的应用。尽管学术界和业界已经在不断构建和发布新的指令微调数据集,但是大部分数据集由人工构建,成本高昂,效率低下,数量和相关度也仍远远达不到实际生产应用的要求。因此,学术界和业界迫切地需要一种高效、灵活、可复制的大规模指令数据构建方法。
为了解决这些问题,提出一种基于大语言模型上下文学习的指令微调数据构建方法,全自动地从数据库中挖掘出和应用场景高度相关的原始素材,大语言模型凭借强大的上下文学习能力可以从示例样本和原始素材中快速构建出高质量的指令-输出对,形成种类多样、内容翔实的指令微调数据集,有力地提升了指令数据的数量、质量、可控性,基于这些指令数据微调后的模型其性能表现也得到了大幅增强。
1.现有的数据构建方案
常见的指令微调数据构建技术方案包括人工构建、人-机混合构建、模型生成、用户共享等。以下是具体的案例,以详细解释这些方案。
人工构建:这种方案主要依赖于人工专家的知识和经验。例如,在医疗领域,可以请医疗专家为大语言模型构建指令微调数据集。他们可以根据医疗领域的特点和需求,设计出一系列具有代表性的指令和对应的输出,如指令“解释心脏病的症状”和对应的输出“心脏病的常见症状包括胸痛、呼吸困难、心悸等”。人工构建数据集需要大量的时间和人力投入,尤其是在涉及到专业领域时,可能需要聘请领域专家,成本较高。其次,人工构建的数据集规模相对较小,可能无法满足大语言模型训练的需求。另外,人工构建的数据集可能受到构建者个人知识和经验的影响,导致数据集存在偏见和局限性。
人机混合:这种方案结合了人的创造性和机器的效率。例如,可以先使用大语言模型生成一些初步的指令和输出,然后请人工专家进行筛选和优化。这样既可以利用模型的大规模生成能力,又可以保证指令和输出的质量和适用性。在人机混合的过程中,需要对模型生成的数据进行筛选和优化,这可能导致质量不一致的问题。虽然人机混合方法可以提高数据生成的效率,但仍然需要人工参与,可能无法完全解决时间和成本问题。
模型生成:这种方法主要依赖于预训练的大语言模型。例如,可以输入一些简单的指令,如“写一篇关于全球变暖的文章”,然后让模型生成更具体、更复杂的指令和对应的输出,如指令“写一篇关于全球变暖对极地生态影响的文章”和对应的输出“全球变暖对极地生态产生了深远影响,包括冰川融化、物种数量减少等”。模型生成的数据可能存在质量问题,如重复、逻辑错误、缺乏多样性等,需要进行后期筛选和修正。另外,模型生成的数据受到预训练模型的影响,可能继承了模型的偏见和局限性。
用户共享:这种方法主要依赖于用户的参与和分享。例如,可以建立一个平台,经用户同意后,由用户分享他们在使用大语言模型时的指令和输出。这样不仅可以获取到大量的实际使用场景,也可以让用户直接参与到模型的训练过程中,提高模型的实用性和用户满意度。用户共享的数据可能包含个人及个人敏感信息 ,需要进行脱敏处理,以保护用户隐私。其次,用户共享的数据质量参差不齐,需要进行筛选和清洗。另外,用户共享的数据可能受到用户群体的偏见影响,导致数据集存在偏见。
不同的方法有各自的优缺点和适用场景,通常在实际操作中会结合使用,以达到更好的效果。
2.方案介绍
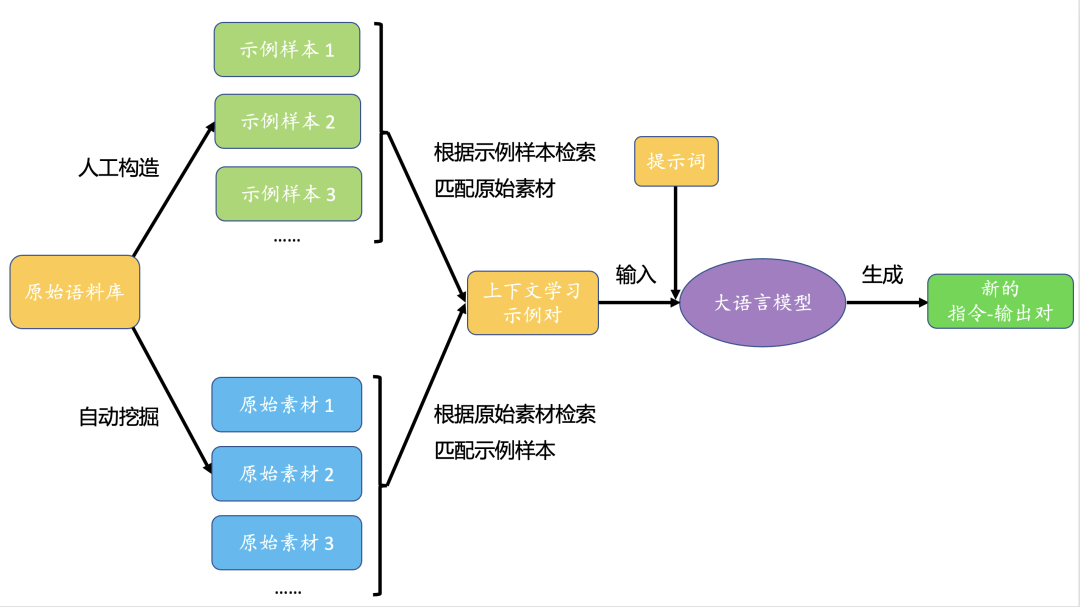
在从数据库中挖掘出和应用场景高度相关的原始素材,利用性能先进大语言模型从示例样本和原始素材中快速构建出高质量的指令-输出对,形成种类多样、内容翔实的指令微调数据集。针对某一个应用场景,首先需要基于原始语料库人工构造一系列符合应用需求的示例样本作为参考,示例样本由“素材-指令-输出”三部分组成。然后利用模式匹配的方法从数据库进行数据挖掘,得到一批原始素材,例如税务场景中的个人所得税计算方法等。接着,分别提取示例样本中的素材和原始素材的文本特征,基于特征进行示例样本素材和原始素材的相似度计算,匹配出若干个最相似的配对形成“上下文学习示例对”,其由示例样本的“素材-指令-输出”和原始素材组合而成。最后,基于“上下文学习示例对”设计一个数据构建任务和对应的提示词,输入大语言模型后生成新的指令-输出对。
2.1 示例样本构建
下面以税务场景的一道数值计算题目为例来说明如何构建示例样本:
示例
"素材:小规模纳税人,适用3%的简易征收办法,不享受增值税专用发票抵扣。"
"指令:农户张大爷种植蔬菜,张大娘开小卖部。今年一季度,张大爷销售自己种植的大白菜31万;张大娘的小卖部销售商品29万。张大爷和张大娘一共需要缴纳多少增值税?"
"输出:根据已知信息,张大爷和张大娘均属于小规模纳税人,适用3%的简易征收办法。因此,他们需要缴纳的增值税分别为:
张大爷:31万元 × 3% = 0.93万元
张大娘:29万元 × 3% = 0.87万元
他们两人一共需要缴纳的增值税为:0.93万元 + 0.87万元 = 1.8万元。"
其中素材为某条涉及数值计算的税务法规条例,需要保持条例的完整,指令为人工设想的一个具体应用案例,该案例与条例内容相关,最后根据素材和指令,可以人工列出分析过程、算式,进行计算后得到最后的输出结果。
2.2 场景计算推理评测数据集
本方案基于不同的应用场景从原始数据库中人工构造了100个示例样本,形成一个用于自测的场景计算推理评测数据集,该数据集的场景分布和题型分布如下:
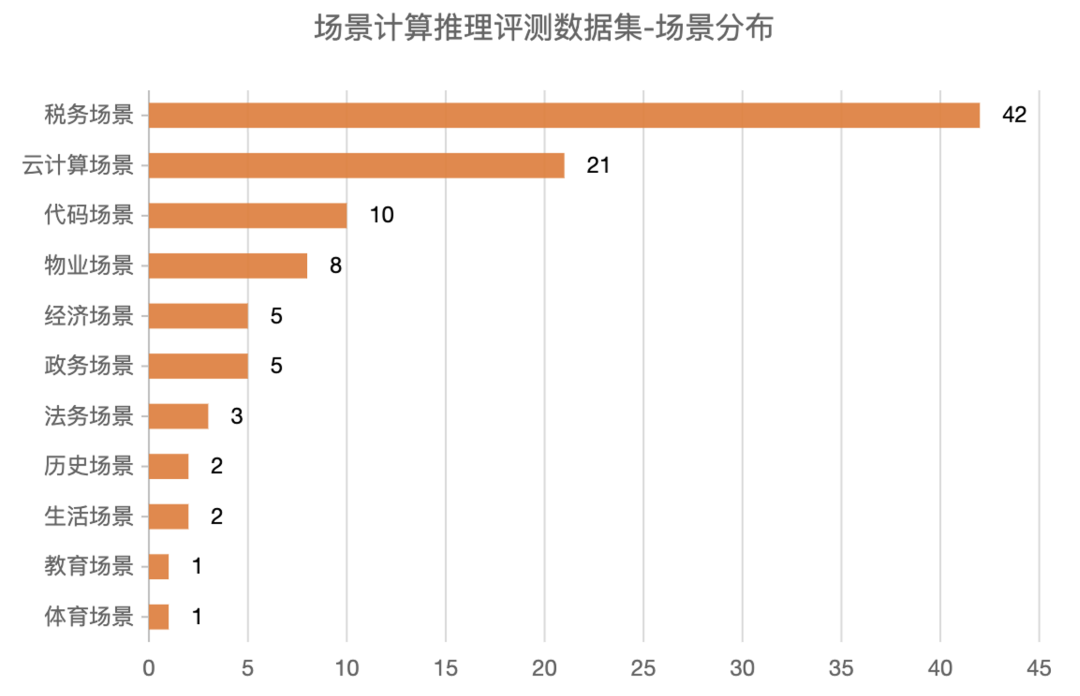
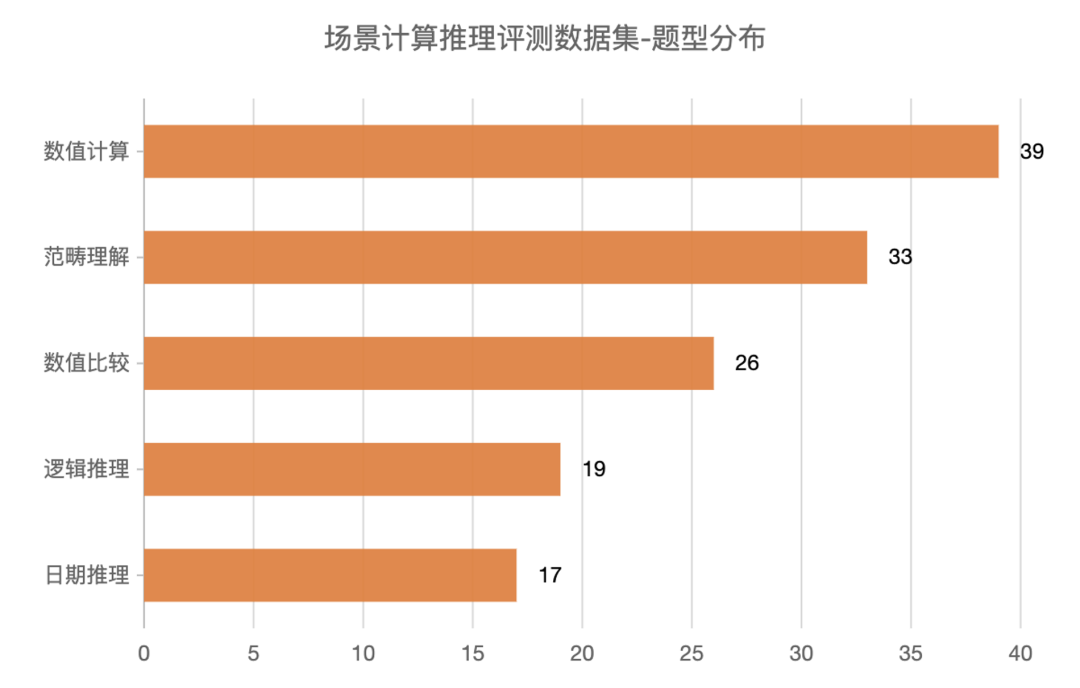
使用者既可以直接使用场景计算推理评测数据集中的示例样本,也可以根据实际场景模仿该数据集的构建方式重新构建新的示例样本。
在使用场景计算推理评测数据集时,待评测大语言模型需要根据素材和指令输出相应的内容。本方案设计了四个维度来系统地评测大语言模型在场景计算推理方面的性能,分别是:
语义理解:指大语言模型是否正确理解了素材和指令的含义,是否曲解了指令的意图或者拒绝作出回答。
内容定位:指大语言模型是否引用复述素材中的相关内容,以此为基础进行计算和推理。
计算推理:指大语言模型是否正确地完成了计算和推理的步骤。
答案总结:指大语言模型是否正确地得出了结论和答案。
2.3 原始素材挖掘
构建指令微调数据的关键一步是获取到丰富的原始素材,例如税务场景中的个人所得税计算方法、云计算的服务器收费标准等等。本方案采用模式匹配的方法从数据库里面挖掘出原始素材。
对于一些有明确章条结构的语料文本来说,本方案采取正则表达式的方法定位章条结构,进行段落和句子的切分,从而提取出逐条的原始素材。
对于没有明确章条结构的语料文本来说,本方案采取正则表达式匹配语料中的标志性符号/具有特殊含义的字符,例如法律法规通常用书名号“《》”包括起来,某些句子提及计算方法或者计算公式,再对本段落或者本句子进行切分。
在挖掘出原始素材后,对原始素材进行了场景分类和题型分类。其中,场景分类可以根据原始语料文本的来源来判定,例如某段原始素材来自《个体工商户建账管理暂行办法》,则归为“税务场景”。而题型分类可以根据原始素材中出现的某些关键词进行判定,例如原始素材中出现了['年', '月', '日', '天']等表示日期的关键词,则归为“日期推理”题型,出现了['元', '人民币']等表示金额的关键词,则归为“数值计算”或者“数值比较”题型。为了确保原始素材的质量,本方案还对过短或者过长的素材进行了过滤。
值得注意的是,仅对本方案在实践过程中的部分情况进行了示例,由于不同场景下的数据库差别巨大,因此需要综合考虑各种思路进行相应的数据挖掘,在此不再赘述。
2.4 根据原始素材检索匹配示例样本
完成原始素材挖掘以后,下一步是构建“上下文学习示例对”。考虑到大语言模型对于相似程度高的示例能够给出更可靠的生成结果,为了在保持素材相关性的同时尽可能提升示例对的数量,本方案提出了两种并行的思路来进行相似性文本检索,即在目标素材中检索匹配与待检索素材相近的素材。
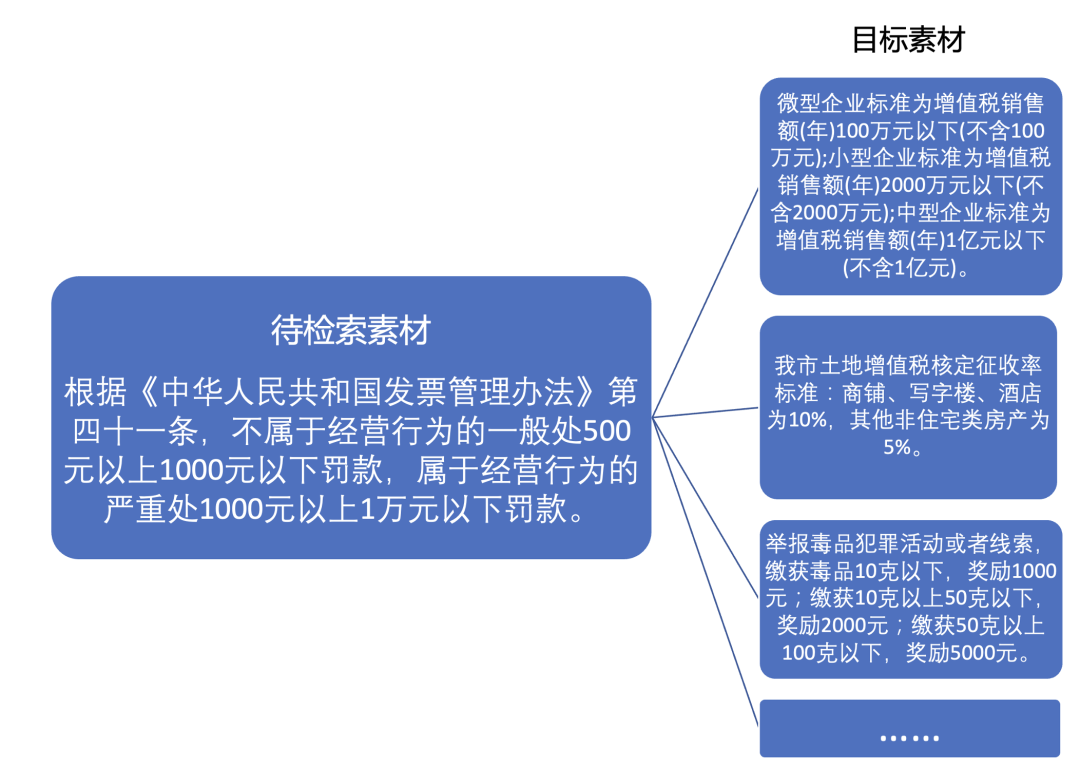
本节先介绍“根据原始素材检索匹配示例样本”。对于某个应用场景下的某类题型,本方案使用预训练完毕的文本表征模型分别提取原始素材和示例样本中的素材的文本特征。对于每一个原始素材的文本特征,分别计算其与每一个示例样本素材的文本特征的余弦相似度。在实际的应用过程中,本方案可以使用faiss等工具库对特征向量进行矩阵运算,快速得到所有特征之间的相似度。然后,本方案对于每一个原始素材选取topM个与之最相似的示例样本中的素材。本方案设置一个相似度的阈值范围[min_sim, max_sim],从topM个示例样本中保留相似度落在阈值范围的样本,相似度低于min_sim的样本为差异过大的样本,会影响大语言模型的生成效果,相似度高于max_sim的样本为高度近似的样本,存在测试数据泄漏的风险,因此都需要进行过滤。通过过滤的示例样本可与原始素材进行一一配对,形成“上下文学习示例对”,保存于储存区。
2.5 大语言模型生成指令-输出对
在得到了一系列“上下文学习示例对”之后,本方案使用性能先进的大语言模型生成新的指令-输出对,从而获得新的指令微调数据集。具体来说,本方案构建了一个数据构建任务和对应的提示词,并将“上下文学习示例对”进行重新组合。下面的例子将说明如何构建一个“数值比较”的数据构建任务和对应的提示词,用{原始素材}指代提示词中可替换的原始素材,{示例样本}指代提示词中可替换的{示例样本}:
示例
你是一个经验丰富的出题老师,你会根据给定的材料,寻找到包含数量和数字的内容,以此构思出有关于【数值比较】的问题,并给出相应的答案。输出的内容包括素材、指令和输出三部分,以JSON格式输出,确保输出能被json.loads加载。以下为一个示例。
{示例样本}
以下是正式的出题环节。
{原始素材}。
请写出指令和输出。
在这个例子中,为大语言模型设置了一个“出题老师”的角色,向其提出了出题的操作流程、题目类型和具体要求,并提供了一个示例样本作为大语言模型上下文学习的参考案例,然后给出匹配的原始素材,让大语言模型写出指令-输出对。
上述的提示词为进行了多次调整后得到的较优结果,在实际的应用过程中可以进一步开展提示词工程获得更优的提示词。
通过上述操作,大语言模型可快速产生批量的指令微调数据,这些数据受到示例样本的约束,与示例样本同属一个类型,因此可控性得到了显著的提升。同时,不局限于某一个应用场景或者指令类型,使用者可参照以上示例快速迁移到新的场景和类型中,因此也体现了方案的灵活性。
3.方案效果
3.1 不同指令微调数据构建方法的效果比较
下面以税务场景的一道数值计算题型的例子说明本方案中基于上下文学习的数据构建方法与直接的数据构建方法之间的效果差异。在该实验中选择某性能先进的大模型作为预设的大语言模型。
以下是方案设计的数据构建任务和对应的提示词,包含了上下文学习的示例样本:
示例
“你是一个经验丰富的出题老师,你会根据给定的材料,寻找到包含数量和数字的内容,以此构思出有关于【数值计算】的问题,并给出相应的答案。输出的内容包括素材、指令和输出三部分,以JSON格式输出,确保输出能被json.loads加载。以下为一个示例。
{'素材': '计算个人所得税:根据《中华人民共和国个人所得税法》的规定,股票授予属于工资、薪金所得,按照累进税率计算个人所得税。具体的税率是:
月应纳税所得额不超过3000元的,税率为3%; 超过3000元至12000元的部分,税率为10%; 超过12000元至25000元的部分,税率为20%; 超过25000元至35000元的部分,税率为25%; 超过35000元至55000元的部分,税率为30%; 超过55000元至80000元的部分,税率为35%; 超过80000元的部分,税率为45%。',
'指令': '今天公司发了10万元的工资,请问我需要缴纳多少钱的个人所得税呢?',
'输出': '根据已知信息,您的应纳税所得额为10万元。按照累进税率计算,您需要缴纳的个人所得税为:
(3000元 × 3%) + (9000元 × 10%) + (13000元 × 20%) + (10000元 × 25%) + (20000元 × 30%) + (25000元 × 35%) + (20000元 × 45%) = 90元 + 900元 + 2600元 + 2500元 + 6000元 + 8750元 + 9000元 = 29840元
所以,您需要缴纳的个人所得税为29840元。'}。
以下是正式的出题环节。
{'素材': '政府信息公开申请处理按件计收收费标准:
(一)同一申请人一个自然月内累计申请10件以下(含10件)的,不收费。
(二)同一申请人一个自然月内累计申请11—30件(含30件)的部分:100元/件。 (三)同一申请人一个自然月内累计申请31件以上的部分:以10件为一档,每增加一档,收费标准提高100元/件。'}。
请写出指令和输出。“
该大语言模型输出的指令-输出对如下所示:
示例
{"指令":
"一个自然月内,某申请人累计申请了50件政府信息公开申请,请问他需要支付多少费用?",
"输出":
"根据收费标准,前10件不收费,第11件至第30件每件收费100元,第31件至第40件每件收费200元,第41件至第50件每件收费300元。所以,该申请人需要支付的费用为:
(30-10) × 100元 + (40-30) × 200元 + (50-40) × 300元 = 20 × 100元 + 10 × 200元 + 10 × 300元 = 2000元 + 2000元 + 3000元 = 7000元。"}
如果将示例部分去除,则该大语言模型输出的指令-输出对如下所示:
示例
{"指令": "如果一个人在一个自然月内申请了20件政府信息公开申请,需要支付多少费用?",
"输出": "根据收费标准,该申请人需要支付100元/件 * 20件 = 2000元。" }
从上述的结果中可以看出,在第一次输出的指令-输出对中,由于示例样本中包含了一道分段计算的题目,并且在输出的回答中进行了详细的分析和列式计算,所以该大语言模型会仿照示例样本生成一道题型近似的数据,同时也给出了分析、列式计算和最终的正确答案。而在第二次输出的指令-输出对中,由于缺乏了参考的示例样本,该大语言模型跳过了中间的分析推理步骤,直接给出了列式计算的答案,但是答案并不正确。诸多研究表明了指令微调数据中包含的完整分析推理步骤有助于激活大语言模型的思维链能力,从而显著提高其计算和推理的性能,而这正是本方案构建的数据的优势所在。
3.2 大语言模型经过不同数据训练后的性能比较
为了进一步验证方案构建的指令微调数据能够显著提升大语言模型的性能,我们开展了另一个实验。在实验中,先使用性能先进的大模型按照本方案的思路构建了约12000道指令微调数据,原始素材来自税务、金融、教育、云计算等多个场景下的数据库,示例样本来自场景计算推理评测数据集。然后,选择Baichuan-2[1]作为基线模型,使用12000道指令微调数据进行了1个epoch的全参数有监督指令微调。最后,在场景计算推理评测数据集上评测了Baichuan-2的原始版本和微调版本的指标,其结果如下:
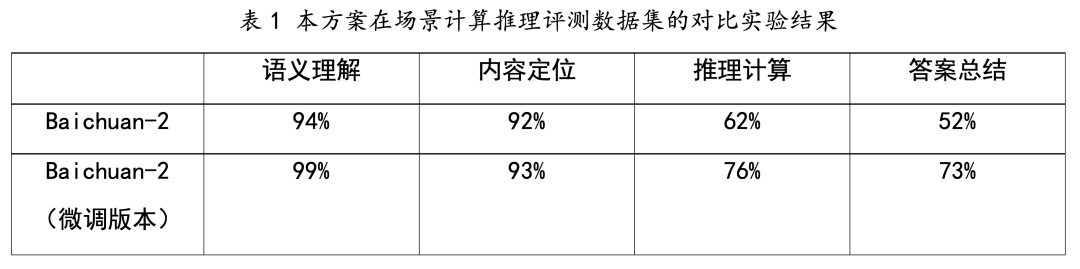
从上表中可以看出,构建的训练数据能够显著地帮助大语言模型提升其性能,尤其是推理计算(+14%)和答案总结(+21%)两个维度,这验证了方案在增强大语言模型的能力方面带来了明显的有益效果,也为今后进一步优化大语言模型的性能提供了一种可靠的参考方向。




