目录
1.分表
2.分库
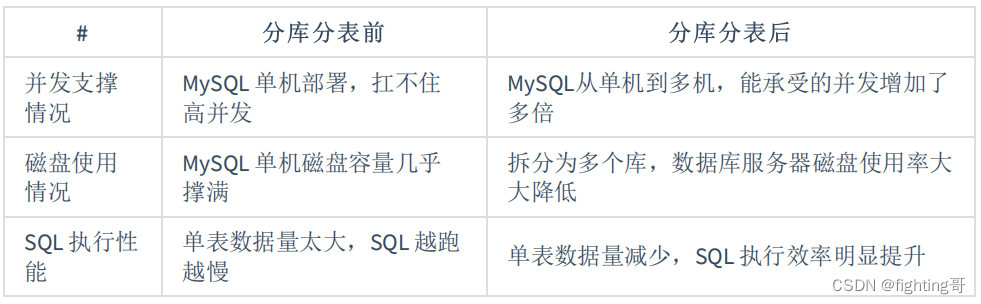
说白了,分库分表是两回事儿,大家可别搞混了,可能是光分库不分表,也可能是光分表不分库,都有可能。
我先给大家抛出来一个场景。
假如我们现在是一个小创业公司(或者是一个 BAT 公司刚兴起的一个新部门),现在注册用户就 20 万,每天活跃用户就1万,每天单表数据量就1000,然后高峰期每秒钟并发请求最多就10个。就这种系统,随便找一个有工作经验的,然后带几个刚培训出来的,随便干干都可以。
结果没想到我们运气居然这么好,碰上个CEO 带着我们走上了康庄大道,业务发展迅猛,过了几个月,注册用户数达到了2000万!每天活跃用户数 100 万!每天单表数据量10 万条!高峰期每秒最大请求达到 1000!同时公司还顺带着融资了两轮,进账了几个亿人民币啊!公司估值达到了惊人的几亿美金!这是小独角兽的节奏!
好吧,没事,现在大家感觉压力已经有点大了,为啥呢?因为每天多 10 万条数据,一个月就多300万条数据,现在咱们单表已经几百万数据了,马上就破千万了,但是勉强还能撑着。高峰期请求现在是1000,咱们线上部署了几台机器,负载均衡搞了一下,数据库撑1000QPS 也还凑合。但是大家现在开始感觉有点担心了,接下来咋整呢……
再接下来几个月,我的天,CEO太牛逼了,公司用户数已经达到1亿,公司继续融资几十亿人民币啊!公司估值达到了惊人的几十亿美金,成为了国内今年最牛逼的明星创业公司!
但是我们同时也是不幸的,因为此时每天活跃用户数上千万,每天单表新增数据多达 50万,目前一个表总数据量都已经达到了两三千万了!扛不住啊!数据库磁盘容量不断消耗掉,高峰期并发达到惊人的 5000~8000 !我跟你保证,你的系统支撑不到现在,已经挂掉了!
好吧,所以你看到这里差不多就理解分库分表是怎么回事儿了,实际上这是跟着你的公司业务发展走的,你公司业务发展越好,用户就越多,数据量越大,请求量越大,那你单个数据库一定扛不住。
1.分表
比如你单表都几千万数据了,你确定能扛住么?绝对不行,单表数据量太大,会极大影响你的 sql 执行的性能,到了后面你的 sql 可能就跑的很慢了。一般来说,就以我的经验来看,单表到几百万的时候,性能就会相对差一些了,你就得分表了。
分表是啥意思?就是把一个表的数据放到多个表中,然后查询的时候你就査一个表。比如按照用户 id 来分表,将一个用户的数据就放在一个表中。然后操作的时候你对一个用户就操作那个表就好了。这样可以控制每个表的数据量在可控的范围内,比如每个表就固定在 200 万以内。
2.分库
分库是啥意思?就是你一个库一般我们经验而言,最多支撑到并发 2000,一定要扩容了,而且一个健康的单库并发值你最好保持在每秒 1000 左右,不要太大。那么你可以将一个库的数据拆分到多个库中,访问的时候就访问一个库好了。
这就是所谓的分库分表,为啥要分库分表?你明白了吧。