背景
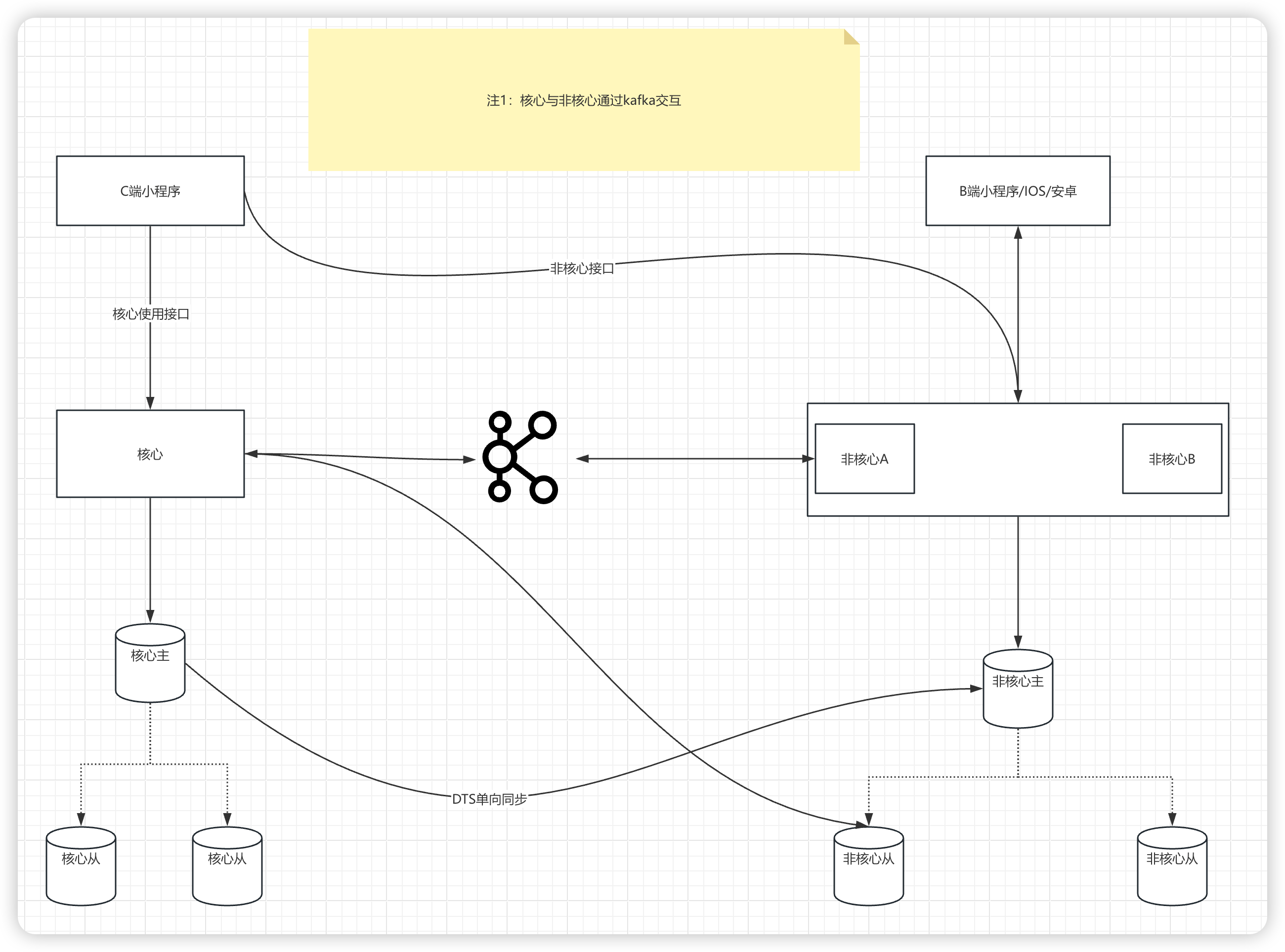
在最近进行的项目架构升级中,我们对原有的核心项目结构进行了细致的拆分。
现在,核心项目与非核心项目之间的通信和数据交换主要通过Kafka这一中间件来实现。
这种设计主要体现在核心项目向非核心项目发送通知,这些通知大致可以分为三个主要类别:
- 在设备租借流程中,订单状态发生变化时需要进行的额外业务处理,这是我们所说的核心消息
- 与用户相关的各类消息。
- 设备的心跳信号以及业务数据的上报消息。
针对这三类关键消息,从业务连续性和数据完整性的角度来看,我们的目标是确保它们的传递尽可能不受损失。如果出现异常情况,系统应自动触发重试机制,以保障消息的送达。同时,任何消息消费过程中的异常都不应影响到后续业务流程的执行,否则可能会对整个业务造成不利影响。
鉴于该项目已经在使用Kafka作为消息传递的基础设施,我们决定在当前场景下不更换为RocketMQ,尽管后者在某些方面可能更适合我们的需求。这一决定是基于对现有系统的依赖和对迁移成本的考虑,旨在保持系统的稳定性和减少不必要的复杂性。
死信队列:由于某些原因消息无法被正确的投递,为了确保消息不会被无故丢地丢弃,一般将其置于一个特殊角色的队列,这个队列一般称为死信队列。
后续分析程序可以通过消费这个死信队列中的内容来分析当时遇到的异常情况,进而可以改善优化系统。
看完这段介绍,死信队列简直就是我们当下最所需的功能,而对于RabbitMQ、RocketMQ来说,死信消息一般通过 broker 存入,
而在kafka中原本并无死信队列的概念,所以当需要自行封装这一层概念的时候,就可以脱离既定思维的约束,
根据应用情况选择合适的实现方式,理解死信的本质进而懂得如何实现死信队列的功能。
在实践中,我们对消息队列(MQ)的业务期望如下:
- 异常消费后的重试机制
我们期望在消息消费过程中遇到异常时,系统能够自动进行重试,确保消息的可靠性。目前,Spring Kafka已经提供了异常重试的支持,并且能够在达到最大重试次数后将消息写入死信队列,以便于后续处理。
为了进一步增强异常处理能力,我们可以通过自行编码,在消费异常时将相关信息写入日志,或者在消费后立即写入消息,待后续消费成功后再更新其状态。 - 异常消费与正常消费的隔离
我们希望异常消费不会影响其他业务的正常进行。为此,MQ中的三类消息应该各自独立处理,互不干扰。这里可以采用线程池技术,为不同类型的消息分配专门的处理线程,从而实现并行处理和隔离。 - 发版期间的消息可靠性
在发版期间,我们要求消息传递的高可靠性,确保消息不会丢失。为此,我们可以配置消费线程池的优雅停止机制,通过设置有限的等待时间来尽可能保证消息被完全消费。虽然这种方式无法100%保证所有消息都能在停止前消费完毕,但它可以在一定程度上减少消息丢失的风险。
在进行技术选型时,我们考虑了以下方案:
- 自动提交与手动提交:
我们选择了自动提交模式,并将其时间间隔设置为30秒。这样做允许在发生异常或宕机后出现重复消费的情况,但需要业务逻辑自身实现幂等性以保证数据的一致性。 - Spring Kafka的使用:
由于选择了自动提交,我们发现Sp
ring Kafka中的重试机制缺乏持久化支持。这可能导致在发版过程中丢失消息,因此我们决定不采用这一方案。 - 重平衡期间的消息丢失问题:
为了解决重平衡期间可能出现的消息丢失问题,我们计划引入JVM钩子,在发版时对当前工作线程池中的消息进行快照,并在后续重新推送这些消息。 - 本地消息处理:
我们不采用在消息消费之初立即落库,在消费后修改状态的做法,以此减少对数据库的压力。
在消费异常时,我们选择将消息落库,而在消费成功时则不进行写入。虽然在极端情况下这可能导致消息丢失,但对于这种极端情况业务层面是可以接受的。 - 业务之间的隔离:
为了确保不同业务之间的相互独立性,我们将为三大类业务各自配置独立的线程池。如果某类业务的事件量特别大,我们还会考虑为其单独配置线程池,以实现更好的资源隔离和处理效率。
消费流程图
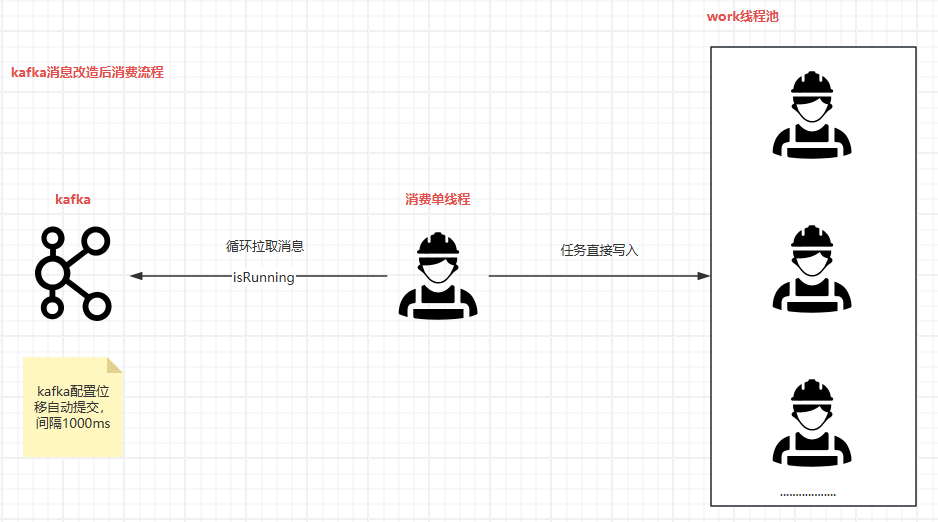
我们的最终技术方案如下:
- Kafka自动提交设置:
我们将Kafka的自动提交间隔设定为30秒,这有助于在发生异常或服务重启时减少消息的重复处理。 - 异常处理机制:
当工作线程在消费消息时遇到异常,系统将会自动记录这些异常信息到本地日志中。这些日志将用于后续的消息重推操作。此外,我们增加了一个Web端的手动重推功能,以便于在需要时手动触发消息的重新处理,若后续异常消息多时可以考虑自动的定时调度。 - 线程池的优雅关闭:
为了确保在服务停止时已拉取的消息能够被完全消费,我们配置了工作线程池的优雅关闭机制。在JVM关闭钩子执行时,系统将等待30到60秒,以确保当前已拉取的消息能够被完全消费。在此期间,系统将快照当前工作线程池队列中的所有消息,以便在必要时进行恢复。 - 双重保障机制:
为了提供额外的保障,我们在JVM关闭钩子执行时再次快照工作线程池队列中的所有消息。这一双重快照机制确保了即使在极端情况下,消息也不会丢失,从而保障了系统的高可靠性和数据的完整性。
写到最后
通过这些细致的技术选型和策略,我们旨在构建一个既高效又稳定的系统,以支持业务的持续发展和创新。




