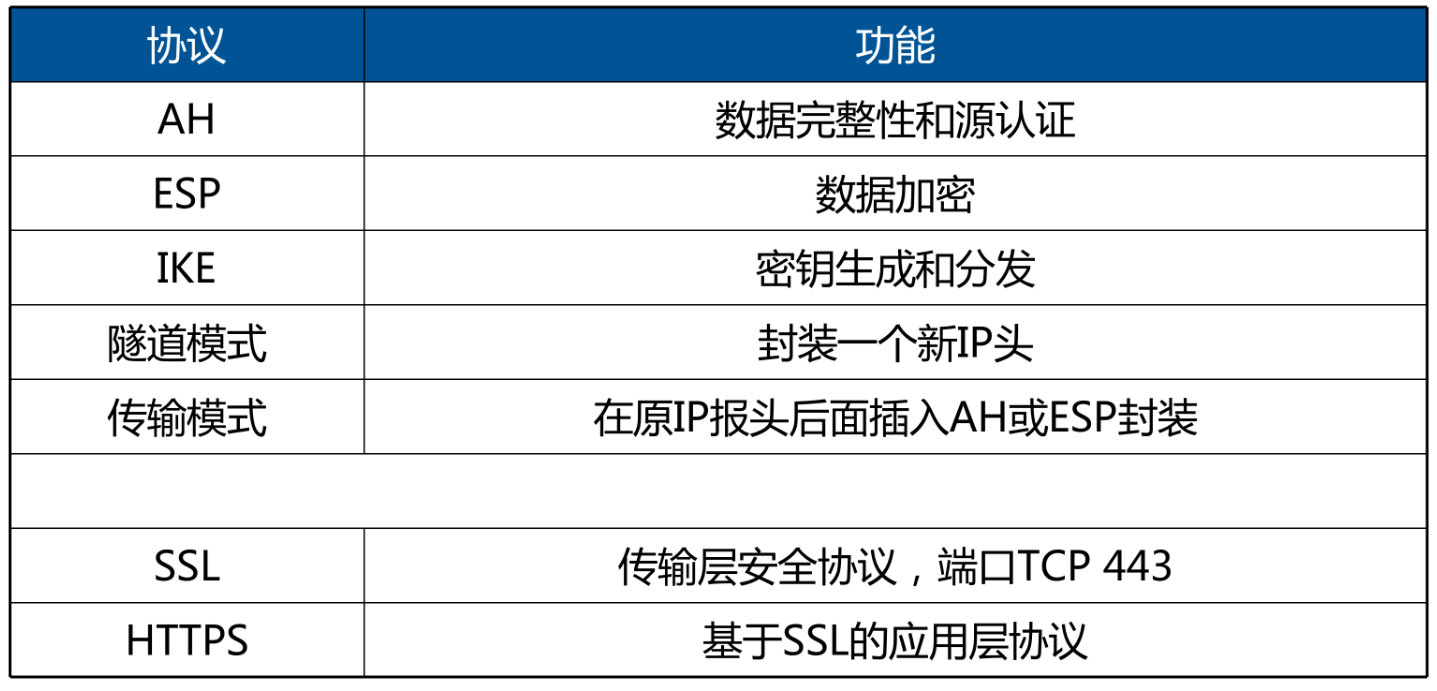
目录
字符串
字符串常用方法:
格格式化字符串的三种方式:
格式化字符串的详细格式:
字符串的编码:
字符串的解码:
数据的验证:
字符串拼接的几种方式:
字符串去重:
正则表达式
元字符:
限定符:
正则表达式:
re模块:
match的用法:
search的使用:
findal的使用:
sud的使用:
split的使用:
字符串
字符串常用方法:


格格式化字符串的三种方式:
1.占位符:%s :字符串格式 %d :十进制整数格式 %f :浮点数格式
2.f-string:Python3.6引入的格式化字符串的方式,比{}标明被替换的字符
3.str.format()方法:模板字符串.format(逗号分隔的参数)
formatted_string = "{1} is from {0}.".format("New York", "Bob")
print(formatted_string)
格式化字符串的详细格式:

字符串的编码:
将str类型转换成bytes类型,需要使用到字符串的encode()方法
str.encode(encoding=‘utf-8’,errors=‘strict/ignore/replace’)
字符串的解码:
将bytes类型转换成str类型,需要使用到bytes类型的decode()方法
bytes.decode(encoding=‘utf-8’,errors=‘strict/ignore/replace’)
数据的验证:

字符串拼接的几种方式:
1、使用加号进行拼接
s1='hello'
s2='world'
print(s1+s2)2、使用字符串的join()进行拼接
s1='hello'
s2='world'
print(''.join([s1,s2]))
print('你好'.join(['hello','world','python','css']))3、直接拼接
print('hello''world')4、用格式化字符串进行拼接
print('%s%s'%(s1,s2))
print(f'{s1}{s2}')
print('{0}{1}'.format(s1,s2))字符串去重:
1.字符串拼接及not in
s='helloworldhelloworldadfdfdeoodllffe'
new_S=''
for item in s:if item not in new_S:new_S+=item
print(new_S)2.索引+not in
new_s2=''
for i in range(len(s)):if s[i] not in new_s2:new_s2+=s[i]
print(new_s2)3.通过集合去重
new_s3=set(s)
lst=list(new_s3)
lst.sort(key=s.index)
print(''.join(lst))正则表达式
元字符:

限定符:

正则表达式:

re模块:

match的用法:
import re
pattern='\d\.\d+'
s='I study python 3.11 every day'
match=re.match(pattern,s,re.I)
print(match)
s2='3.11Python I study every day'
match2=re.match(pattern,s2)
print(match2)
print('匹配值的起始位置:',match2.start())
print('匹配值的结束位置:',match2.end())
print('匹配区间的位置元素:',match2.span())
print('待匹配的字符串:',match2.string)
print('匹配的数据:',match2.group())search的使用:
import re
pattern='\d\.\d+'
s1=('I study Python3.11 every day Python2.7 I love you')
match=re.search(pattern,s)
print(match)findal的使用:
import re
pattern='\d\.\d+'
s='I study Python3.11 every day Python2.7 I love you'
s2='4.10 Python I study every day'
s3='I study Python every day'
lst=re.findall(pattern,s)
lst2=re.findall(pattern,s2)
lst3=re.findall(pattern,s3)
print(lst)
print(lst2)
print(lst3)sud的使用:
import re
pattern='黑客|破解|反爬'
s='我想学习Python,想破解一些VIP视频,Python可以实现无底线反爬吗?'
new_s=re.sub(pattern,repl:'xxx',s)
print(new_s)split的使用:
s2='https://www.baidu.com/s?wd=ysj&rsv_spt=1'
pattern2='[?|&]'
lst=re.split(pattern2,s2)
print(lst)