感知机

引言:本文通过介绍超平面引入感知机模型的基本思路,同时介绍了包括线性回归,三种梯度下降算法等相关算法,在文末对感知机模型的原始形式进行了代码实现,希望通过朴素的语言帮助刚开始学习机器学习和统计学习方法的同学快速进入机器学习的模式和思路。
参考文献:统计学习方法 (第2版)-李航,刘建平老师的博客
关键字:超平面,损失函数,线性回归,梯度下降
1.所属类别和相关概念
1.1分类
统计学习方法这本书对于机器学习的模型进行了几种分类,第一种方法是根据模型和数据提供者的关系将模型划分为:监督学习,无监督学习,强化学习,半监督学习和主动学习。第二种是根据模型所属假设空间的基本元素划分为:概率模型和非概率模型。第三种则是根据模型的决策函数将模型划分为线性模型和非线性模型。第四种则是根据模型的参数维度是否确定划分为参数化模型和非参数化模型。第五种则是根据模型学习样本的方式分为在线学习和批量学习。
感知机属于监督学习【所学习的数据是具有标注的】的一种,同时它是非概率模型【假设空间的元素是决策函数】,线性模型【决策函数是线性函数】,和参数化模型【模型的参数是确定的】
监督模型又可以根据学习的目标划分为生成方法和判别方法,而感知机是属于判别方法,直接学习分类函数F(X),同时监督学习又可以根据应用方向将意图解决的问题分为分类问题,标注问题,和回归问题。而显然感知机是属于分类问题。
通过以上机器学习算法的模型分类方式,我们基本可以了解到感知机是用于处理分类问题的算法,同时其模型是学习一个线性的决策函数,同时决策函数中的参数是固定。
1.2概念引入
统计学习方法绝大部分内容依托于微积分和概率论,同时为了优化算法还会引入矩阵,以实现更优雅的代码,但是这就对我们的学习造成了很大的困扰,或者说机器学习的学习方式重点应该放到对核心算法的数学模型理解和推导上面,往往一个很复杂的算法也许只需要一个不到一百行的方法就能完成。其实这和软件工程传统的工程化层次化的思想是非常相似的,在人工智能时代,我们可以将更多精力专注于理论的学习和创新上,而将更多重复的工作交给机器去做,通过人工智能软件去完成。在详细讲解感知机前我们引入一些数学概念去使整个学习的过程不至于卡壳。
1.2.1 超平面
如果从现象的角度去理解超平面,其实非常简单,对于一个N维无限空间,我们往往能找到一个N-1维的空间去将这个N维空间完全分割成两部分,如果这样不好理解的话我们可以用实际的案例来阐述。
对于一个一维直线来说,一个点可以将它分为两部分:

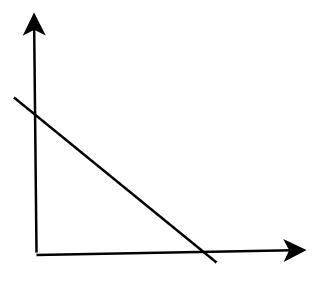
对于一个二维平面来说,一个直线y = ax+b可以将它分为两部分:
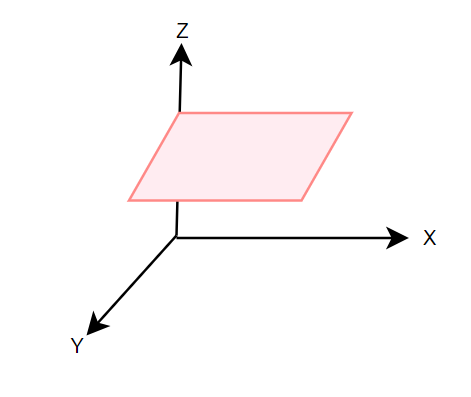
对于一个三维空间来说,一个二维平面ax + by +c = 0 可以将它分为两部分:
所以我们可以很轻松的预想到,对于一个四维空间可以由一个三维空间ax+by+cz+d =0 来分为两个部分:
那么如何用函数表达式表达出一个N维空间的N-1维的超平面呢?或者说,我们可以很轻易的写出一个二维/三维的空间表达式,那么N维空间的表达式应该是什么呢?我们一般会用以下的方程来表示N维空间,也就是N维空间的一般式:
θ 1 x 1 + θ 2 x 2 + θ 3 x 3 + . . . + θ n x n + b = 0 \theta_1x_1+\theta_2x_2+\theta_3x_3+...+\theta_{n}x_{n}+b = 0 θ1x1+θ2x2+θ3x3+...+θnxn+b=0
如果用矩阵的方式来优化一下这个表达式就是:
ω X + b = 0 其中 ω = ( θ 1 , θ 2 . . . θ n ) T X = ( x 1 , x 2 . . . x n ) T \omega X + b =0 \\其中 \\ \omega = (\theta_1,\theta_2...\theta_n)^T\\ X =(x_1,x_2...x_n)^T ωX+b=0其中ω=(θ1,θ2...θn)TX=(x1,x2...xn)T
在这个方程中 ω \omega ω 是空间/超平面的法向量,垂直于平面,同时b我们称为是截距,代表平面到原点的距离。
如果我们的点在超平面的正侧,也就是法向量的同侧方向,则代入 ω X + b > 0 \omega X +b > 0 ωX+b>0,否则则是小于0
1.2.2 空间内一点到超平面的距离
我们一般把 ∥ ω ∥ 2 \Vert\omega \Vert_2 ∥ω∥2 这样的形式称为 ω \omega ω向量的L2范数,它所代表的含义是: ω \omega ω向量的模
而空间中一点到超平面的距离是:
d = 1 ∥ ω ∥ 2 ∣ ω X + b ∣ d = \frac{1}{\Vert \omega \Vert}_{2} |\omega X +b| d=∥ω∥12∣ωX+b∣
1.2.3 Sign 函数
S i g n ( X ) = { 1 , x ≥ 0 − 1 , x < 0 Sign(X)=\begin{equation} \left\{ \begin{aligned} 1 ,x \ge 0\\ -1,x<0 \end{aligned} \right. \end{equation} Sign(X)={1,x≥0−1,x<0
1.2.4 矩阵求导公式
∂ ∂ X ( X T X ) = 2 X ∂ ∂ X f ( A X + B ) = A T ∗ ∂ f ∂ ( A X + B ) \frac{\partial}{\partial X}(X^TX) =2X \\ \frac{\partial}{\partial X}f(AX+B) = A^T*\frac{\partial f}{\partial(AX+B)} ∂X∂(XTX)=2X∂X∂f(AX+B)=AT∗∂(AX+B)∂f
1.2.5 线性回归
基本假设:y与一个或多个自变量 x 1 , x 2 . . . x n x_1,x_2...x_n x1,x2...xn中存在线性关系
则我们用线性函数去拟合y,其中b用于表示因变量中不能被自变量解释的部分
y = θ 1 x 1 + θ 2 x 2 + θ 3 x 3 + . . . + θ n x n + b y = \theta_1x_1+\theta_2x_2+\theta_3x_3+...+\theta_{n}x_{n}+b y=θ1x1+θ2x2+θ3x3+...+θnxn+b
线性回归的目的:根据样本找到一组最优的回归系数 θ \theta θ,使得模型能够准确与预测因变量
线性回归中我们一般使用的损失函数是:
1 ) 均方误差 M S E = 1 n ∑ i = 1 n ( y i − y i ^ ) 2 y i 是预测值, y i ^ 是实际值 1 n 是为了获取平均误差 2 ) 平均绝对误差: M A E = 1 n ∑ i = 1 n ∣ y i − y i ^ ∣ 1)均方误差MSE = \frac{1}{n}\sum_{i=1}^{n}(y_i - \widehat{y_i})^2 \\y_i是预测值,\widehat{y_i}是实际值 \\\frac{1}{n}是为了获取平均误差 \\2)平均绝对误差: MAE=\frac{1}{n}\sum_{i=1}^{n}|y_i - \widehat{y_i}| 1)均方误差MSE=n1i=1∑n(yi−yi )2yi是预测值,yi 是实际值n1是为了获取平均误差2)平均绝对误差:MAE=n1i=1∑n∣yi−yi ∣
线性回归的优缺点:
-
优点:简单高效的拟合因变量变化
-
缺点:
- 线性假设限制:因变量可以被线性拟合在实际中往往不成立,这个时候就需要非线性关系的模型
- 对异常值敏感:一个异常值往往会极大情况影响参数变化
- 只能对数值建模:无法对数值以外的其他数据有效果
线性回归的应用场景:
- 趋势预测
- 趋势分析
通常对于线性回归算法损失函数的最小化策略有两种,一是最小二乘法,二就是梯度下降法
2.模型
2.1输入,输出,假设空间
输入空间【特征空间】:$ {{x{(m)}_1,x{(m)}_2…x{(m)}_n,y{(m)}}}^T$
其中x代表特征,表示数据中有n个特征,同时n也代表超平面是n维的,而被分割空间是n+1维的,也代表m代表样本个数
输出空间:{+1,-1}
我们的目标是为了找出一个超平面即: θ 0 + θ 1 x 1 + . . . + θ n x n = 0 \theta_0 + \theta_{1}x_1 + ... + \theta_{n}x_{n} = 0 θ0+θ1x1+...+θnxn=0,使得这个超平面可以将空间分给为两部分
这个超平面可以表示为:$ \omega X +b$
我们不妨处理一下,补充一个特征x0=1,此时超平面可以表示为: θ 0 x 0 + θ 1 x 1 + . . . + θ n x n = 0 − > ∑ i = 0 n θ i x i = 0 \theta_0x_0 + \theta_{1}x_1 + ... + \theta_{n}x_{n} = 0 -> \sum_{i=0}^{n}\theta_ix_i=0 θ0x0+θ1x1+...+θnxn=0−>∑i=0nθixi=0
输入空间到输出空间的函数也就是我们假设空间中的决策函数是: f ( x ) = s i g n ( ∑ i = 0 n θ i x i ) f(x) = sign(\sum_{i=0}^{n}\theta_ix_i) f(x)=sign(∑i=0nθixi) ,进一步我们可以用向量的形式表示为 f ( x ) = s i g n ( θ X ) f(x) = sign(\theta X) f(x)=sign(θX)
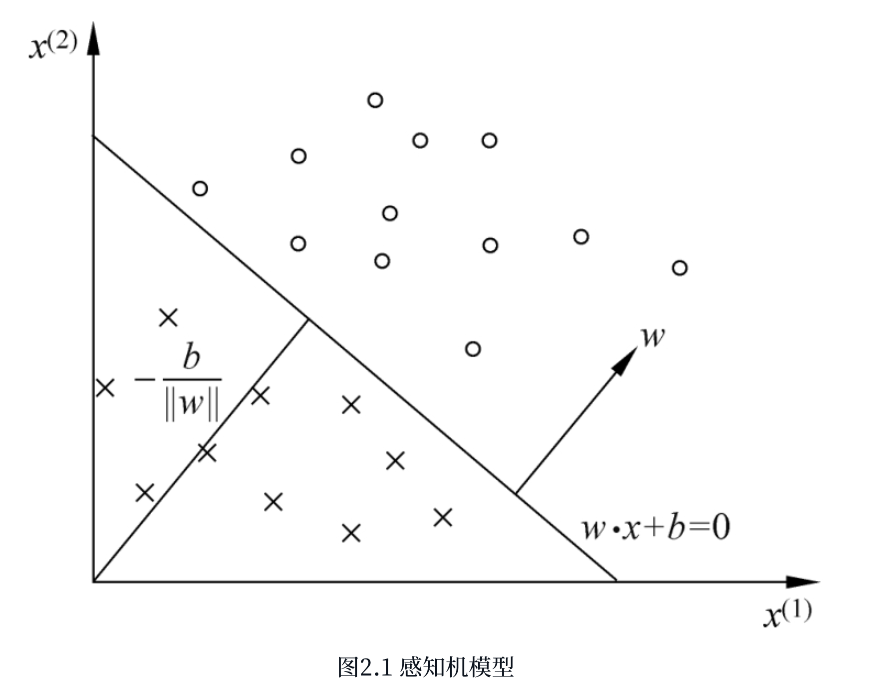
2.2 损失函数
感知机有一个极大前提就是数据必须可分,也就是数据可以被分为两个部分,对应的就是空间可以分为两个部分,如果数据不可分我们往往需要多个感知机模型进行训练或者更换其他模型
假设训练数据集是线性可分的,感知机学习的目标是求得一个能够将训练集正实例点和负实例点完全正确分开的分离超平面。为了找出这样的超平面,即确定感知机模型参数w,b,需要确定一个学习策略,即定义(经验)损失函数并将损失函数极小化。
显然我们可以通过误分类点的个数来表示损失函数,但是这样会存在一个问题,也就是损失函数不是 θ \theta θ的连续可导函数,不易于优化。
同时我们选择另一个策略来表示误差,从而只当损失函数,也就是误分类点到超平面的距离,我们可以将每一个误分类点到超平面的距离求和从而得到总误差:
1 ∥ θ ∥ 2 ∑ i = 0 m ∣ θ X ∣ \frac{1}{\Vert \theta \Vert_2}\sum_{i=0}^{m} |\theta X| ∥θ∥21i=0∑m∣θX∣
我们将满足 θ ∙ x > 0 θ∙x>0 θ∙x>0的样本类别输出值取为1,满足 θ ∙ x < 0 θ∙x<0 θ∙x<0的样本类别输出值取为-1, 这样取y的值有一个好处,就是方便定义损失函数。因为正确分类的样本满足$ yθ∙x>0$,而错误分类的样本满足 y θ ∙ x < 0 yθ∙x<0 yθ∙x<0。
这个东西怎么去理解呢,比如我现在输入向量是(1,1,1)和(-1,-1,-1)
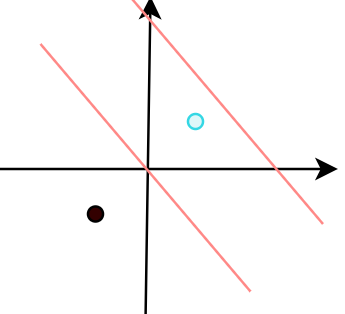
如果现在的超平面是x1+x2-3=0,那么显然(1,1,1)这个点就被误分类了,此时模型的输出x1+x2-3<0,点被分到了负侧,而我们实际的情况应该是>0,所以此时被误分类了, θ ∙ x < 0 θ∙x<0 θ∙x<0,输出的yi也是小于0的,则 θ ∙ x < 0 θ∙x<0 θ∙x<0在值上就等于 y θ ∙ x yθ∙x yθ∙x,而绝对值就等于 − y θ ∙ x -yθ∙x −yθ∙x
所以我们的损失函数就可以变形为:
− 1 ∥ θ ∥ 2 ∑ i = 0 m y ( i ) θ x ( i ) -\frac{1}{\Vert \theta \Vert_2}\sum_{i=0}^{m} y^{(i)}\theta x^{(i)} −∥θ∥21i=0∑my(i)θx(i)
我们研究可以发现,分子和分母都含有θ,当分子的θ扩大N倍时,分母的L2范数也会扩大N倍。也就是说,分子和分母有固定的倍数关系。那么我们可以固定分子或者分母为1,然后求另一个即分子自己或者分母的倒数的最小化作为损失函数,这样可以简化我们的损失函数。所以我们将上面这个公式放缩为: − ∑ i = 0 m y ( i ) θ x ( i ) -\sum_{i=0}^{m} y^{(i)}\theta x^{(i)} −∑i=0my(i)θx(i)
由此我们得到损失函数:
L ( θ ) = − ∑ i = 0 m y ( i ) θ x ( i ) L(\theta)= -\sum_{i=0}^{m} y^{(i)}\theta x^{(i)} L(θ)=−i=0∑my(i)θx(i)
3.策略
现在我们将问题转变为损失函数的最小化问题,通常对于线性回归算法损失函数的最小化策略有两种,一是最小二乘法,二就是梯度下降法。
一般来说梯度下降法有三种:
- BGD 批量梯度下降
- SGD 随机梯度下降
- MBGD 小批量梯度下降
三种方法的核心区别就在于每一次下降,用于计算梯度的样本个数不同。
对于批量梯度下降来说,更新参数需要用到所有的样本,但是显然在感知机模型中这种方案是不合适的,因为感知机是误分类点驱动的,也就是说,我们只根据误分类点来进行梯度下降,显然不符合批量梯度下降和小批量梯度下降的要求。所以我们求解损失函数最小化通过随机梯度下降来实现,每一次进行下降随机选取一个误分类样本点更新参数。
损失函数基于$\theta $向量的的偏导数为:
∂ ∂ θ J ( θ ) = − ∑ x i ∈ M y ( i ) x ( i ) \frac{\partial}{\partial \theta}J(\theta) = - \sum\limits_{x_i \in M}y^{(i)}x^{(i)} ∂θ∂J(θ)=−xi∈M∑y(i)x(i)
则$\theta $的梯度下降迭代公式应该为:
θ = θ + α ∑ x i ∈ M y ( i ) x ( i ) \theta = \theta + \alpha\sum\limits_{x_i \in M}y^{(i)}x^{(i)} θ=θ+αxi∈M∑y(i)x(i)
由于我们采用随机梯度下降,所以每次仅仅采用一个误分类的样本来计算梯度,假设采用第i个样本来更新梯度,则简化后的 θ \theta θ 向量的梯度下降迭代公式为:
θ = θ + α y ( i ) x ( i ) \theta = \theta + \alpha y^{(i)}x^{(i)} θ=θ+αy(i)x(i)
4.算法:感知机的原始形式
4.1算法过程
算法的输入为m个样本,每个样本对应于n维特征和一个二元类别输出1或者-1,如下:
( x 1 ( 1 ) , x 2 ( 1 ) , . . . x n ( 1 ) , y ( 1 ) ) ( x 1 ( 2 ) , x 2 ( 2 ) , . . . x n ( 2 ) , y ( 2 ) ) . . . ( x 1 ( m ) , x 2 ( m ) , . . . x n ( m ) , y ( m ) ) (x^{(1)}_1,x^{(1)}_2,...x^{(1)}_n,y^{(1)})\\ (x^{(2)}_1,x^{(2)}_2,...x^{(2)}_n,y^{(2)})\\ ...\\ (x^{(m)}_1,x^{(m)}_2,...x^{(m)}_n,y^{(m)}) (x1(1),x2(1),...xn(1),y(1))(x1(2),x2(2),...xn(2),y(2))...(x1(m),x2(m),...xn(m),y(m))
输出为分离超平面的模型系数 θ \theta θ向量
算法的执行步骤如下:
- 定义所有x_0为1。选择 θ \theta θ向量的初值和步长α的初值。可以将 θ \theta θ向量置为0向量,步长设置为1。要注意的是,由于感知机的解不唯一,使用的这两个初值会影响 θ \theta θ向量的最终迭代结果。
- 在训练集里面选择一个误分类的点$ (x{(1)}_1,x{(1)}_2,…x{(1)}_n,y{(1)}) , 用向量表示即 , 用向量表示即 ,用向量表示即(x{(i)}_1,y{(1)}) ,这个点应该满足: ,这个点应该满足: ,这个点应该满足:y^{(i)}\theta \bullet x^{(i)} \leq 0$
- 对 θ \theta θ向量进行一次随机梯度下降的迭代: θ = θ + α y ( i ) x ( i ) \theta = \theta + \alpha y^{(i)}x^{(i)} θ=θ+αy(i)x(i)
- 检查训练集里是否还有误分类的点,如果没有,算法结束,此时的 θ \theta θ向量即为最终结果。如果有,继续第2步。
4.2实现代码
# -*- coding: UTF-8 -*-
'''
@File :perceptron.py
@Author :Jeffrey Wang
@Date :2024/10/18 9:11
'''
import numpy as np
import matplotlib.pyplot as pltclass Perceptron:def __init__(self, learning_rate=1, max_iter=100):self.learning_rate = learning_rate # 学习率self.max_iter = max_iter # 最大迭代次数self.theta = None # 模型参数向量# 训练模型def fit(self, X, y):m, n = X.shape #训练集中的样本数m和特征数nX = np.c_[np.ones(m), X] # 添加偏置项bself.theta = np.zeros(n + 1) #theta 初始值全为0,一共n+1维for _ in range(self.max_iter):'''因为随机梯度下降找到一个误分类点就可以,所以这里通过随机迭代所有样本来修改梯度遇到误分类点则修改为了防止过拟合同时以最大迭代次数为循环边界'''i = np.random.randint(m)x_i = X[i] # 第一行n个数据y_i = y[i] # 期望值yif y_i * np.dot(self.theta, x_i) <= 0: #是误分类点self.theta += self.learning_rate * y_i * x_i #修改梯度else:continueprint(f"超平面方程为:{self.theta[0]} + {self.theta[1]}x1 + {self.theta[2]}x2 = 0")# 可视化数据和超平面x1_min, x1_max = np.min(X[:, 1]), np.max(X[:, 1])x2_min, x2_max = np.min(X[:, 2]), np.max(X[:, 2])xx1, xx2 = np.meshgrid(np.linspace(x1_min, x1_max, 100), np.linspace(x2_min, x2_max, 100))Z = self.theta[0] + self.theta[1] * xx1 + self.theta[2] * xx2Z = np.where(Z > 0, 1, -1)plt.contourf(xx1, xx2, Z, cmap='coolwarm', alpha=0.6)plt.scatter(X[:, 1][y == 1], X[:, 2][y == 1], c='dodgerblue', label='Class 1')plt.scatter(X[:, 1][y == -1], X[:, 2][y == -1], c='crimson', label='Class -1')plt.xlabel('Feature 1')plt.ylabel('Feature 2')plt.legend()plt.show()# 预测模型def predict(self, X):m = X.shape[0]X = np.c_[np.ones(m), X]return np.sign(np.dot(X, self.theta))if __name__ == '__main__':# X = np.array([[1, 2], [2, 3], [3, 1], [4, 2]])# y = np.array([1, 1, -1, -1])# perceptron = Perceptron()# perceptron.fit(X, y)# predictions = perceptron.predict(X)# print("Predictions:", predictions)# 生成 100 个测试数据点np.random.seed(42)num_points = 100X = np.random.randn(num_points, 2)y = np.sign(X[:, 0] + X[:, 1])perceptron = Perceptron()perceptron.fit(X, y)predictions = perceptron.predict(X)print("Predictions:", predictions)




