
目录
一、Zeppelin简介
二、实现步骤
2.1 Zeppelin包下载
2.2 work配置文件
三、配置常用解释器
3.1配置Hive解释器
3.2 配置trino解释器
spark-toc" style="margin-left:40px;">3.3 配置Spark解释器
一、Zeppelin简介
Zeppelin是Apache基金会下的一个开源框架,它提供了一个数据可视化的框架,是一个基于web的notebook。后台支持接入多种数据引擎,比如jdbc、spark、hive等。同时也支持多种语言进行交互式的数据分析,比如Scala、SQL、Python等等。本文从安装和使用两部分来介绍Zeppelin。

二、实现步骤
官网安装参考文档:datasophon/docs/zh/datasophon集成zeppelin.md at dev · datavane/datasophon · GitHub
2.1 Zeppelin包下载
https://dlcdn.apache.org/zeppelin/zeppelin-0.10.1/zeppelin-0.10.1-bin-all.tgz
# 创建配置存放目录
mkdir -p /opt/datasophon/DDP/packages/datasophon-manager-1.2.1/conf/meta/DDP-1.2.1/ZEPPELIN将配置json文件和启停脚本准备好,还需要将启动脚本复制到安装包根目录下

control_zeppelin.sh
#!/bin/bashSCRIPT_DIR=$(cd "$(dirname "$0")" && pwd)
ZEPPELIN_HOME=$SCRIPT_DIR # 当前目录即为 Zeppelin 安装目录
ZEPPELIN_DAEMON=$ZEPPELIN_HOME/bin/zeppelin-daemon.shstart_zeppelin() {echo "Starting Zeppelin..."$ZEPPELIN_DAEMON start
}stop_zeppelin() {echo "Stopping Zeppelin..."$ZEPPELIN_DAEMON stop
}check_zeppelin_status() {echo "Checking Zeppelin status..."$ZEPPELIN_DAEMON statusif [ $? -eq 0 ]; thenecho "Zeppelin is running."exit 0elseecho "Zeppelin is not running."exit 1fi
}case "$1" instart)start_zeppelin;;stop)stop_zeppelin;;restart)stop_zeppelinsleep 5 # 等待一些时间确保Zeppelin完全停止start_zeppelin;;status)check_zeppelin_status;;*)echo "Usage: $0 {start|stop|restart|status}"exit 1;;
esac
control_zeppelin.sh
#!/bin/bashSCRIPT_DIR=$(cd "$(dirname "$0")" && pwd)
ZEPPELIN_HOME=$SCRIPT_DIR # 当前目录即为 Zeppelin 安装目录
ZEPPELIN_DAEMON=$ZEPPELIN_HOME/bin/zeppelin-daemon.shstart_zeppelin() {echo "Starting Zeppelin..."$ZEPPELIN_DAEMON start
}stop_zeppelin() {echo "Stopping Zeppelin..."$ZEPPELIN_DAEMON stop
}check_zeppelin_status() {echo "Checking Zeppelin status..."$ZEPPELIN_DAEMON statusif [ $? -eq 0 ]; thenecho "Zeppelin is running."exit 0elseecho "Zeppelin is not running."exit 1fi
}case "$1" instart)start_zeppelin;;stop)stop_zeppelin;;restart)stop_zeppelinsleep 5 # 等待一些时间确保Zeppelin完全停止start_zeppelin;;status)check_zeppelin_status;;*)echo "Usage: $0 {start|stop|restart|status}"exit 1;;
esacservice_ddl.json
{"name": "ZEPPELIN","label": "ZEPPELIN","description": "交互式数据分析notebook","version": "0.10.1","sortNum": 1,"dependencies": [],"packageName": "zeppelin-0.10.1.tar.gz","decompressPackageName": "zeppelin-0.10.1","roles": [{"name": "ZeppelinServer","label": "ZeppelinServer","roleType": "master","cardinality": "1+","runAs": {},"logFile": "logs/zeppelin-root-${host}.log","startRunner": {"timeout": "60","program": "control_zeppelin.sh","args": ["start"]},"stopRunner": {"timeout": "600","program": "control_zeppelin.sh","args": ["stop"]},"statusRunner": {"timeout": "60","program": "control_zeppelin.sh","args": ["status"]},"externalLink": {"name": "ZeppelinServer UI","label": "ZeppelinServer UI","url": "http://${host}:8889"}}],"configWriter": {"generators": [{"filename": "zeppelin-env.sh","configFormat": "custom","outputDirectory": "conf","templateName": "zeppelin-env.ftl","includeParams": ["custom.zeppelin.env"]},{"filename": "zeppelin-site.xml","configFormat": "custom","outputDirectory": "conf","templateName": "zeppelin-site.ftl","includeParams": ["jobmanagerEnable","custom.zeppelin.site.xml"]}]},"parameters": [{"name": "jobmanagerEnable","label": "jobmanagerEnable","description": "The Job tab in zeppelin page seems not so useful instead it cost lots of memory and affect the performance.Disable it can save lots of memory","configType": "map","required": true,"type": "switch","value": true,"configurableInWizard": true,"hidden": false,"defaultValue": true},{"name": "custom.zeppelin.env","label": "自定义配置 zeppelin-env.sh","description": "自定义配置","configType": "custom","required": false,"type": "multipleWithKey","value": [{"HADOOP_CONF_DIR":"${HADOOP_CONF_DIR}"}],"configurableInWizard": true,"hidden": false,"defaultValue": [{"HADOOP_CONF_DIR":"${HADOOP_CONF_DIR}"}]},{"name": "custom.zeppelin.site.xml","label": "自定义配置 zeppelin-site.xml","description": "自定义配置","configType": "custom","required": false,"type": "multipleWithKey","value": [],"configurableInWizard": true,"hidden": false,"defaultValue": ""}]
}
2.2 work配置文件
work下需要准备两个配置文件zeppelin-env.ftl和zeppelin-site.ftl

zeppelin-env.ftl
#!/bin/bashexport ZEPPELIN_ADDR=0.0.0.0
export ZEPPELIN_PORT=8889
parent_dir=$(dirname "$(cd "$(dirname "$0")" && pwd)")
export JAVA_HOME=$parent_dir/jdk1.8.0_333<#list itemList as item>
export ${item.name}=${item.value}
</#list>
zeppelin-site.ftl
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--Licensed to the Apache Software Foundation (ASF) under one or morecontributor license agreements. See the NOTICE file distributed withthis work for additional information regarding copyright ownership.The ASF licenses this file to You under the Apache License, Version 2.0(the "License"); you may not use this file except in compliance withthe License. You may obtain a copy of the License athttp://www.apache.org/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, softwaredistributed under the License is distributed on an "AS IS" BASIS,WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.See the License for the specific language governing permissions andlimitations under the License.
--><configuration><property><name>zeppelin.server.addr</name><value>127.0.0.1</value><description>Server binding address</description>
</property><property><name>zeppelin.server.port</name><value>8080</value><description>Server port.</description>
</property><property><name>zeppelin.cluster.addr</name><value></value><description>Server cluster address, eg. 127.0.0.1:6000,127.0.0.2:6000,127.0.0.3:6000</description>
</property><property><name>zeppelin.server.ssl.port</name><value>8443</value><description>Server ssl port. (used when ssl property is set to true)</description>
</property><property><name>zeppelin.server.context.path</name><value>/</value><description>Context Path of the Web Application</description>
</property><property><name>zeppelin.war.tempdir</name><value>webapps</value><description>Location of jetty temporary directory</description>
</property><property><name>zeppelin.notebook.dir</name><value>notebook</value><description>path or URI for notebook persist</description>
</property><property><name>zeppelin.interpreter.include</name><value></value><description>All the inteprreters that you would like to include. You can only specify either 'zeppelin.interpreter.include' or 'zeppelin.interpreter.exclude'. Specifying them together is not allowed.</description>
</property><property><name>zeppelin.interpreter.exclude</name><value></value><description>All the inteprreters that you would like to exclude. You can only specify either 'zeppelin.interpreter.include' or 'zeppelin.interpreter.exclude'. Specifying them together is not allowed.</description>
</property><property><name>zeppelin.notebook.homescreen</name><value></value><description>id of notebook to be displayed in homescreen. ex) 2A94M5J1Z Empty value displays default home screen</description>
</property><property><name>zeppelin.notebook.homescreen.hide</name><value>false</value><description>hide homescreen notebook from list when this value set to true</description>
</property><property><name>zeppelin.notebook.collaborative.mode.enable</name><value>true</value><description>Enable collaborative mode</description>
</property><!-- Google Cloud Storage notebook storage -->
<!--
<property><name>zeppelin.notebook.gcs.dir</name><value></value><description>A GCS path in the form gs://bucketname/path/to/dir.Notes are stored at {zeppelin.notebook.gcs.dir}/{notebook-id}/note.json</description>
</property><property><name>zeppelin.notebook.gcs.credentialsJsonFilePath</name><value>path/to/key.json</value><description>Path to GCS credential key file for authentication with Google Storage.</description>
</property><property><name>zeppelin.notebook.storage</name><value>org.apache.zeppelin.notebook.repo.GCSNotebookRepo</value><description>notebook persistence layer implementation</description>
</property>
--><!-- Amazon S3 notebook storage -->
<!-- Creates the following directory structure: s3://{bucket}/{username}/{notebook-id}/note.json -->
<!--
<property><name>zeppelin.notebook.s3.user</name><value>user</value><description>user name for s3 folder structure</description>
</property><property><name>zeppelin.notebook.s3.bucket</name><value>zeppelin</value><description>bucket name for notebook storage</description>
</property><property><name>zeppelin.notebook.s3.endpoint</name><value>s3.amazonaws.com</value><description>endpoint for s3 bucket</description>
</property><property><name>zeppelin.notebook.s3.timeout</name><value>120000</value><description>s3 bucket endpoint request timeout in msec.</description>
</property><property><name>zeppelin.notebook.storage</name><value>org.apache.zeppelin.notebook.repo.S3NotebookRepo</value><description>notebook persistence layer implementation</description>
</property>--><!-- Additionally, encryption is supported for notebook data stored in S3 -->
<!-- Use the AWS KMS to encrypt data -->
<!-- If used, the EC2 role assigned to the EMR cluster must have rights to use the given key -->
<!-- See https://aws.amazon.com/kms/ and http://docs.aws.amazon.com/kms/latest/developerguide/concepts.html -->
<!--
<property><name>zeppelin.notebook.s3.kmsKeyID</name><value>AWS-KMS-Key-UUID</value><description>AWS KMS key ID used to encrypt notebook data in S3</description>
</property>
--><!-- provide region of your KMS key -->
<!-- See http://docs.aws.amazon.com/general/latest/gr/rande.html#kms_region for region codes names -->
<!--
<property><name>zeppelin.notebook.s3.kmsKeyRegion</name><value>us-east-1</value><description>AWS KMS key region in your AWS account</description>
</property>
--><!-- Use a custom encryption materials provider to encrypt data -->
<!-- No configuration is given to the provider, so you must use system properties or another means to configure -->
<!-- See https://docs.aws.amazon.com/AWSJavaSDK/latest/javadoc/com/amazonaws/services/s3/model/EncryptionMaterialsProvider.html -->
<!--
<property><name>zeppelin.notebook.s3.encryptionMaterialsProvider</name><value>provider implementation class name</value><description>Custom encryption materials provider used to encrypt notebook data in S3</description>
</property>
--><!-- Server-side encryption enabled for notebooks -->
<!--
<property><name>zeppelin.notebook.s3.sse</name><value>true</value><description>Server-side encryption enabled for notebooks</description>
</property>
--><!-- Path style access for S3 bucket -->
<!--
<property><name>zeppelin.notebook.s3.pathStyleAccess</name><value>true</value><description>Path style access for S3 bucket</description>
</property>
--><!-- S3 Object Permissions (Canned ACL) for notebooks -->
<!--
<property><name>zeppelin.notebook.s3.cannedAcl</name><value>BucketOwnerFullControl</value><description>Saves notebooks in S3 with the given Canned Access Control List.</description>
</property>
--><!-- Optional override to control which signature algorithm should be used to sign AWS requests -->
<!-- Set this property to "S3SignerType" if your AWS S3 compatible APIs support only AWS Signature Version 2 such as Ceph. -->
<!--
<property><name>zeppelin.notebook.s3.signerOverride</name><value>S3SignerType</value><description>optional override to control which signature algorithm should be used to sign AWS requests</description>
</property>
--><!-- Aliyun OSS notebook storage -->
<!-- Creates the following directory structure: oss://{bucket}/{notebook_dir}/note_path -->
<!--<property><name>zeppelin.notebook.oss.bucket</name><value>zeppelin</value><description>bucket name for notebook storage</description>
</property><property><name>zeppelin.notebook.oss.endpoint</name><value>http://oss-cn-hangzhou.aliyuncs.com</value><description>endpoint for oss bucket</description>
</property><property><name>zeppelin.notebook.oss.accesskeyid</name><value></value><description>Access key id for your OSS account</description>
</property><property><name>zeppelin.notebook.oss.accesskeysecret</name><value></value><description>Access key secret for your OSS account</description>
</property><property><name>zeppelin.notebook.storage</name><value>org.apache.zeppelin.notebook.repo.OSSNotebookRepo</value><description>notebook persistence layer implementation</description>
</property>--><!-- If using Azure for storage use the following settings -->
<!--
<property><name>zeppelin.notebook.azure.connectionString</name><value>DefaultEndpointsProtocol=https;AccountName=<accountName>;AccountKey=<accountKey></value><description>Azure account credentials</description>
</property><property><name>zeppelin.notebook.azure.share</name><value>zeppelin</value><description>share name for notebook storage</description>
</property><property><name>zeppelin.notebook.azure.user</name><value>user</value><description>optional user name for Azure folder structure</description>
</property><property><name>zeppelin.notebook.storage</name><value>org.apache.zeppelin.notebook.repo.AzureNotebookRepo</value><description>notebook persistence layer implementation</description>
</property>
--><!-- Notebook storage layer using local file system
<property><name>zeppelin.notebook.storage</name><value>org.apache.zeppelin.notebook.repo.VFSNotebookRepo</value><description>local notebook persistence layer implementation</description>
</property>
--><!-- Notebook storage layer using hadoop compatible file system
<property><name>zeppelin.notebook.storage</name><value>org.apache.zeppelin.notebook.repo.FileSystemNotebookRepo</value><description>Hadoop compatible file system notebook persistence layer implementation, such as local file system, hdfs, azure wasb, s3 and etc.</description>
</property><property><name>zeppelin.server.kerberos.keytab</name><value></value><description>keytab for accessing kerberized hdfs</description>
</property><property><name>zeppelin.server.kerberos.principal</name><value></value><description>principal for accessing kerberized hdfs</description>
</property>
--><!-- For connecting your Zeppelin with ZeppelinHub -->
<!--
<property><name>zeppelin.notebook.storage</name><value>org.apache.zeppelin.notebook.repo.GitNotebookRepo, org.apache.zeppelin.notebook.repo.zeppelinhub.ZeppelinHubRepo</value><description>two notebook persistence layers (versioned local + ZeppelinHub)</description>
</property>
--><!-- MongoDB notebook storage -->
<!--
<property><name>zeppelin.notebook.storage</name><value>org.apache.zeppelin.notebook.repo.MongoNotebookRepo</value><description>notebook persistence layer implementation</description>
</property><property><name>zeppelin.notebook.mongo.uri</name><value>mongodb://localhost</value><description>MongoDB connection URI used to connect to a MongoDB database server</description>
</property><property><name>zeppelin.notebook.mongo.database</name><value>zeppelin</value><description>database name for notebook storage</description>
</property><property><name>zeppelin.notebook.mongo.collection</name><value>notes</value><description>collection name for notebook storage</description>
</property><property><name>zeppelin.notebook.mongo.autoimport</name><value>false</value><description>import local notes into MongoDB automatically on startup, reset to false after import to avoid repeated import</description>
</property>
--><property><name>zeppelin.notebook.storage</name><value>org.apache.zeppelin.notebook.repo.GitNotebookRepo</value><description>versioned notebook persistence layer implementation</description>
</property><property><name>zeppelin.notebook.one.way.sync</name><value>false</value><description>If there are multiple notebook storages, should we treat the first one as the only source of truth?</description>
</property><property><name>zeppelin.interpreter.dir</name><value>interpreter</value><description>Interpreter implementation base directory</description>
</property><property><name>zeppelin.interpreter.localRepo</name><value>local-repo</value><description>Local repository for interpreter's additional dependency loading</description>
</property><property><name>zeppelin.interpreter.dep.mvnRepo</name><value>https://repo1.maven.org/maven2/</value><description>Remote principal repository for interpreter's additional dependency loading</description>
</property><property><name>zeppelin.dep.localrepo</name><value>local-repo</value><description>Local repository for dependency loader</description>
</property><property><name>zeppelin.helium.node.installer.url</name><value>https://nodejs.org/dist/</value><description>Remote Node installer url for Helium dependency loader</description>
</property><property><name>zeppelin.helium.npm.installer.url</name><value>https://registry.npmjs.org/</value><description>Remote Npm installer url for Helium dependency loader</description>
</property><property><name>zeppelin.helium.yarnpkg.installer.url</name><value>https://github.com/yarnpkg/yarn/releases/download/</value><description>Remote Yarn package installer url for Helium dependency loader</description>
</property><!--
<property><name>zeppelin.helium.registry</name><value>helium,https://s3.amazonaws.com/helium-package/helium.json</value><description>Location of external Helium Registry</description>
</property>
--><property><name>zeppelin.interpreter.group.default</name><value>spark</value><description></description>
</property><property><name>zeppelin.interpreter.connect.timeout</name><value>60000</value><description>Interpreter process connect timeout in msec.</description>
</property><property><name>zeppelin.interpreter.output.limit</name><value>102400</value><description>Output message from interpreter exceeding the limit will be truncated</description>
</property><property><name>zeppelin.ssl</name><value>false</value><description>Should SSL be used by the servers?</description>
</property><property><name>zeppelin.ssl.client.auth</name><value>false</value><description>Should client authentication be used for SSL connections?</description>
</property><property><name>zeppelin.ssl.keystore.path</name><value>keystore</value><description>Path to keystore relative to Zeppelin configuration directory</description>
</property><property><name>zeppelin.ssl.keystore.type</name><value>JKS</value><description>The format of the given keystore (e.g. JKS or PKCS12)</description>
</property><property><name>zeppelin.ssl.keystore.password</name><value>change me</value><description>Keystore password. Can be obfuscated by the Jetty Password tool</description>
</property><!--
<property><name>zeppelin.ssl.key.manager.password</name><value>change me</value><description>Key Manager password. Defaults to keystore password. Can be obfuscated.</description>
</property>
--><property><name>zeppelin.ssl.truststore.path</name><value>truststore</value><description>Path to truststore relative to Zeppelin configuration directory. Defaults to the keystore path</description>
</property><property><name>zeppelin.ssl.truststore.type</name><value>JKS</value><description>The format of the given truststore (e.g. JKS or PKCS12). Defaults to the same type as the keystore type</description>
</property><!--
<property><name>zeppelin.ssl.truststore.password</name><value>change me</value><description>Truststore password. Can be obfuscated by the Jetty Password tool. Defaults to the keystore password</description>
</property>
--><!--
<property><name>zeppelin.ssl.pem.key</name><value></value><description>This directive points to the PEM-encoded private key file for the server.</description>
</property>
--><!--
<property><name>zeppelin.ssl.pem.key.password</name><value></value><description>Password of the PEM-encoded private key.</description>
</property>
--><!--
<property><name>zeppelin.ssl.pem.cert</name><value></value><description>This directive points to a file with certificate data in PEM format.</description>
</property>
--><!--
<property><name>zeppelin.ssl.pem.ca</name><value></value><description>This directive sets the all-in-one file where you can assemble the Certificates of Certification Authorities (CA) whose clients you deal with. These are used for Client Authentication. Such a file is simply the concatenation of the various PEM-encoded Certificate files.</description>
</property>
--><property><name>zeppelin.server.allowed.origins</name><value>*</value><description>Allowed sources for REST and WebSocket requests (i.e. http://onehost:8080,http://otherhost.com). If you leave * you are vulnerable to https://issues.apache.org/jira/browse/ZEPPELIN-173</description>
</property><property><name>zeppelin.username.force.lowercase</name><value>false</value><description>Force convert username case to lower case, useful for Active Directory/LDAP. Default is not to change case</description>
</property><property><name>zeppelin.notebook.default.owner.username</name><value></value><description>Set owner role by default</description>
</property><property><name>zeppelin.notebook.public</name><value>true</value><description>Make notebook public by default when created, private otherwise</description>
</property><property><name>zeppelin.websocket.max.text.message.size</name><value>10240000</value><description>Size in characters of the maximum text message to be received by websocket. Defaults to 10240000</description>
</property><property><name>zeppelin.server.default.dir.allowed</name><value>false</value><description>Enable directory listings on server.</description>
</property><property><name>zeppelin.interpreter.yarn.monitor.interval_secs</name><value>10</value><description>Check interval in secs for yarn apps monitors</description>
</property><!--
<property><name>zeppelin.interpreter.lifecyclemanager.class</name><value>org.apache.zeppelin.interpreter.lifecycle.TimeoutLifecycleManager</value><description>LifecycleManager class for managing the lifecycle of interpreters, by default interpreter willbe closed after timeout</description>
</property><property><name>zeppelin.interpreter.lifecyclemanager.timeout.checkinterval</name><value>60000</value><description>Milliseconds of the interval to checking whether interpreter is time out</description>
</property><property><name>zeppelin.interpreter.lifecyclemanager.timeout.threshold</name><value>3600000</value><description>Milliseconds of the interpreter timeout threshold, by default it is 1 hour</description>
</property>
--><property><name>zeppelin.server.jetty.name</name><value> </value><description>Hardcoding Application Server name to Prevent Fingerprinting</description>
</property><!--
<property><name>zeppelin.server.send.jetty.name</name><value>false</value><description>If set to false, will not show the Jetty version to prevent Fingerprinting</description>
</property>
--><!--
<property><name>zeppelin.server.jetty.request.header.size</name><value>8192</value><description>Http Request Header Size Limit (to prevent HTTP 413)</description>
</property>
--><!--
<property><name>zeppelin.server.jetty.thread.pool.max</name><value>400</value><description>Max Thread pool number for QueuedThreadPool in Jetty Server</description>
</property>
-->
<!--
<property><name>zeppelin.server.jetty.thread.pool.min</name><value>8</value><description>Min Thread pool number for QueuedThreadPool in Jetty Server</description>
</property>
-->
<!--
<property><name>zeppelin.server.jetty.thread.pool.timeout</name><value>30</value><description>Timeout number for QueuedThreadPool in Jetty Server</description>
</property>
--><!--
<property><name>zeppelin.server.authorization.header.clear</name><value>true</value><description>Authorization header to be cleared if server is running as authcBasic</description>
</property>
--><property><name>zeppelin.server.xframe.options</name><value>SAMEORIGIN</value><description>The X-Frame-Options HTTP response header can be used to indicate whether or not a browser should be allowed to render a page in a frame/iframe/object.</description>
</property><!--
<property><name>zeppelin.server.strict.transport</name><value>max-age=631138519</value><description>The HTTP Strict-Transport-Security response header is a security feature that lets a web site tell browsers that it should only be communicated with using HTTPS, instead of using HTTP. Enable this when Zeppelin is running on HTTPS. Value is in Seconds, the default value is equivalent to 20 years.</description>
</property>
--><property><name>zeppelin.server.xxss.protection</name><value>1; mode=block</value><description>The HTTP X-XSS-Protection response header is a feature of Internet Explorer, Chrome and Safari that stops pages from loading when they detect reflected cross-site scripting (XSS) attacks. When value is set to 1 and a cross-site scripting attack is detected, the browser will sanitize the page (remove the unsafe parts).</description>
</property><property><name>zeppelin.server.xcontent.type.options</name><value>nosniff</value><description>The HTTP X-Content-Type-Options response header helps to prevent MIME type sniffing attacks. It directs the browser to honor the type specified in the Content-Type header, rather than trying to determine the type from the content itself. The default value "nosniff" is really the only meaningful value. This header is supported on all browsers except Safari and Safari on iOS.</description>
</property><!--
<property><name>zeppelin.server.html.body.addon</name><value><![CDATA[<script defer src="https://url/to/my/lib.min.js" /><script defer src="https://url/to/other/lib.min.js" />]]></value><description>Addon html code to be placed at the end of the html->body section in index.html delivered by zeppelin server.</description>
</property><property><name>zeppelin.server.html.head.addon</name><value></value><description>Addon html code to be placed at the end of the html->head section in index.html delivered by zeppelin server.</description>
</property>
--><!--
<property><name>zeppelin.interpreter.callback.portRange</name><value>10000:10010</value>
</property>
--><!--
<property><name>zeppelin.recovery.storage.class</name><value>org.apache.zeppelin.interpreter.recovery.LocalRecoveryStorage</value><description>ReoveryStorage implementation based on java native local file system</description>
</property><property><name>zeppelin.recovery.storage.class</name><value>org.apache.zeppelin.interpreter.recovery.FileSystemRecoveryStorage</value><description>ReoveryStorage implementation based on hadoop FileSystem</description>
</property>
--><!--
<property><name>zeppelin.recovery.dir</name><value>recovery</value><description>Location where recovery metadata is stored</description>
</property>
--><!-- GitHub configurations
<property><name>zeppelin.notebook.git.remote.url</name><value></value><description>remote Git repository URL</description>
</property><property><name>zeppelin.notebook.git.remote.username</name><value>token</value><description>remote Git repository username</description>
</property><property><name>zeppelin.notebook.git.remote.access-token</name><value></value><description>remote Git repository password</description>
</property><property><name>zeppelin.notebook.git.remote.origin</name><value>origin</value><description>Git repository remote</description>
</property><property><name>zeppelin.notebook.cron.enable</name><value>false</value><description>Notebook enable cron scheduler feature</description>
</property>
<property><name>zeppelin.notebook.cron.folders</name><value></value><description>Notebook cron folders</description>
</property>
--><property><name>zeppelin.run.mode</name><value>auto</value><description>'auto|local|k8s|docker'</description>
</property><property><name>zeppelin.k8s.portforward</name><value>false</value><description>Port forward to interpreter rpc port. Set 'true' only on local development when zeppelin.k8s.mode 'on'</description>
</property><property><name>zeppelin.k8s.container.image</name><value>apache/zeppelin:0.9.0-SNAPSHOT</value><description>Docker image for interpreters</description>
</property><property><name>zeppelin.k8s.spark.container.image</name><value>apache/spark:latest</value><description>Docker image for Spark executors</description>
</property><property><name>zeppelin.k8s.template.dir</name><value>k8s</value><description>Kubernetes yaml spec files</description>
</property><property><name>zeppelin.docker.container.image</name><value>apache/zeppelin:0.8.0</value><description>Docker image for interpreters</description>
</property><property><name>zeppelin.search.index.rebuild</name><value>false</value><description>Whether rebuild index when zeppelin start. If true, it would read all notes and rebuild the index, this would consume lots of memory if you have large amounts of notes, so by default it is false</description>
</property><property><name>zeppelin.search.use.disk</name><value>true</value><description>Whether using disk for storing search index, if false, memory will be used instead.</description>
</property><property><name>zeppelin.search.index.path</name><value>/tmp/zeppelin-index</value><description>path for storing search index on disk.</description>
</property><property><name>zeppelin.jobmanager.enable</name><value>${jobmanagerEnable}</value><description>The Job tab in zeppelin page seems not so useful instead it cost lots of memory and affect the performance.Disable it can save lots of memory</description>
</property><property><name>zeppelin.spark.only_yarn_cluster</name><value>false</value><description>Whether only allow yarn cluster mode</description>
</property><property><name>zeppelin.note.file.exclude.fields</name><value></value><description>fields to be excluded from being saved in note files, with Paragraph prefix mean the fields in Paragraph, e.g. Paragraph.results</description>
</property><#list itemList as item>
<property><name>${item.name}</name><value>${item.value}</value>
</property>
</#list></configuration>配置完成后需要重启,work也需要重启
/opt/datasophon/DDP/packages/datasophon-manager-1.2.1/bin/datasophon-api.sh start api
重启完成后,我们完成安装。
登录页面 http://192.168.2.100:8889/
三、配置常用解释器
3.1配置Hive解释器
前提条件我们需要启动HiverServer2。
 复制hive-site.xml到zeppline中
复制hive-site.xml到zeppline中
cp /opt/datasophon/hive-3.1.0/conf/hive-site.xml /opt/datasophon/zeppelin-0.10.1/conf/将如下jar包拷贝到目录:/opt/datasophon/zeppelin-0.10.1/interpreter/jdbc
commons-lang-2.6.jar
curator-client-2.12.0.jar
guava-19.0.jar
hadoop-common-3.3.3.jar
hive-common-3.1.0.jar
hive-exec-3.1.0.jar
hive-jdbc-3.1.0.jar
hive-serde-3.1.0.jar
hive-service-3.1.0.jar
hive-service-rpc-3.1.0.jar
httpclient-4.5.2.jar
httpcore-4.4.4.jar
libfb303-0.9.3.jar
libthrift-0.9.3.jar
mysql-connector-java-5.1.46-bin.jar
mysql-connector-java.jar
protobuf-java-2.5.0.jar jar包拷贝完成后,重启zeppline。
jar包拷贝完成后,重启zeppline。
web界面配置集成hive
新建一个继承jdbc的解释器,命名为hive,如下图所示
 配置默认jdbc URL和USER
配置默认jdbc URL和USER
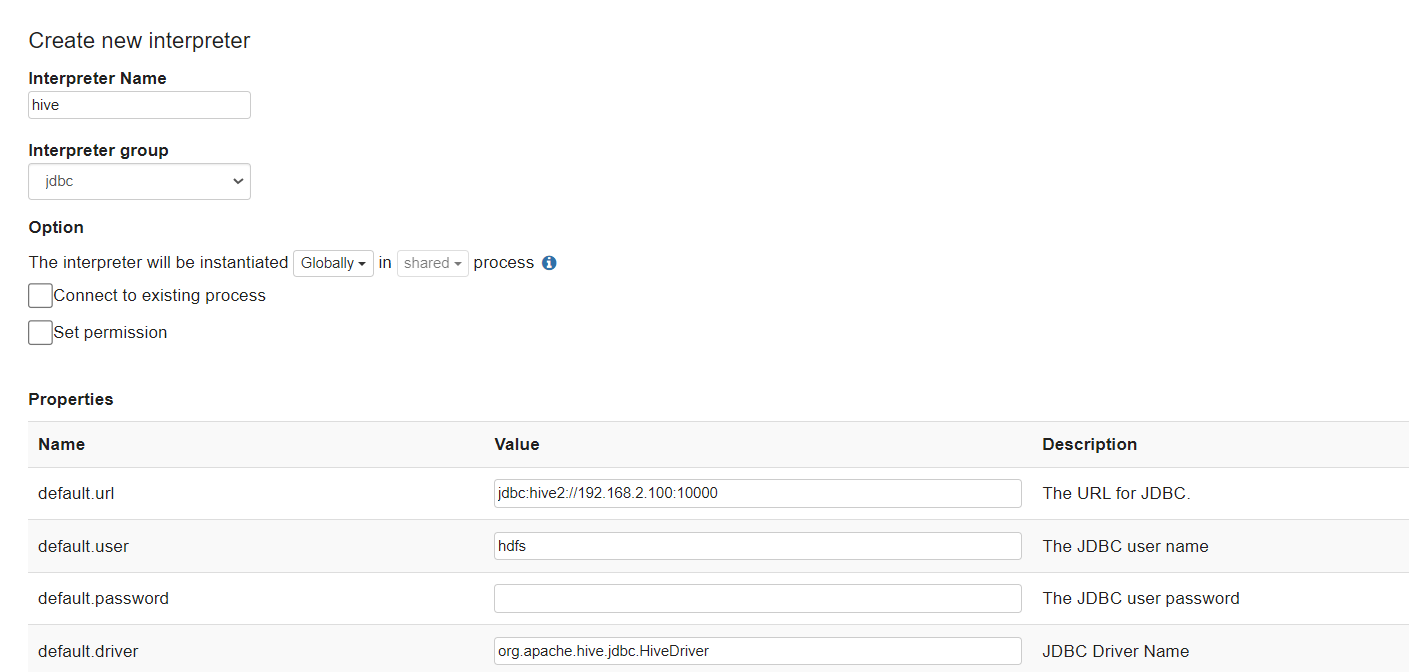
我的配置如下:
| 属性名称 | 属性值 |
| default.url | jdbc:hive2://192.168.21.102:10000 |
| default.user | hdfs |
| default.driver | org.apache.hive.jdbc.HiveDriver |
创建新的notebook
 Interpreter选择:hive
Interpreter选择:hive
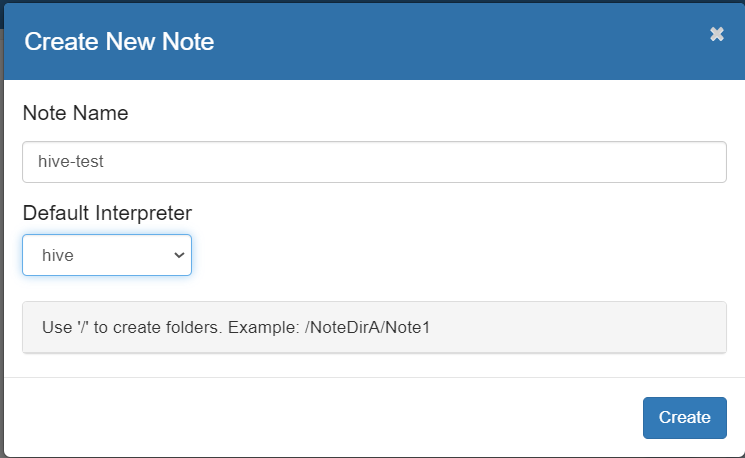
测试使用
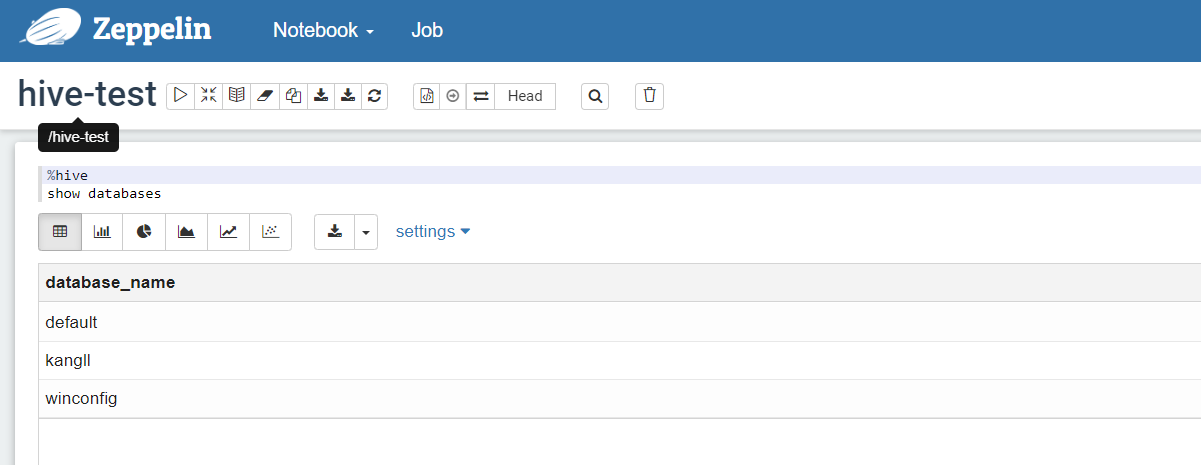
3.2 配置trino解释器
将trino服务启动
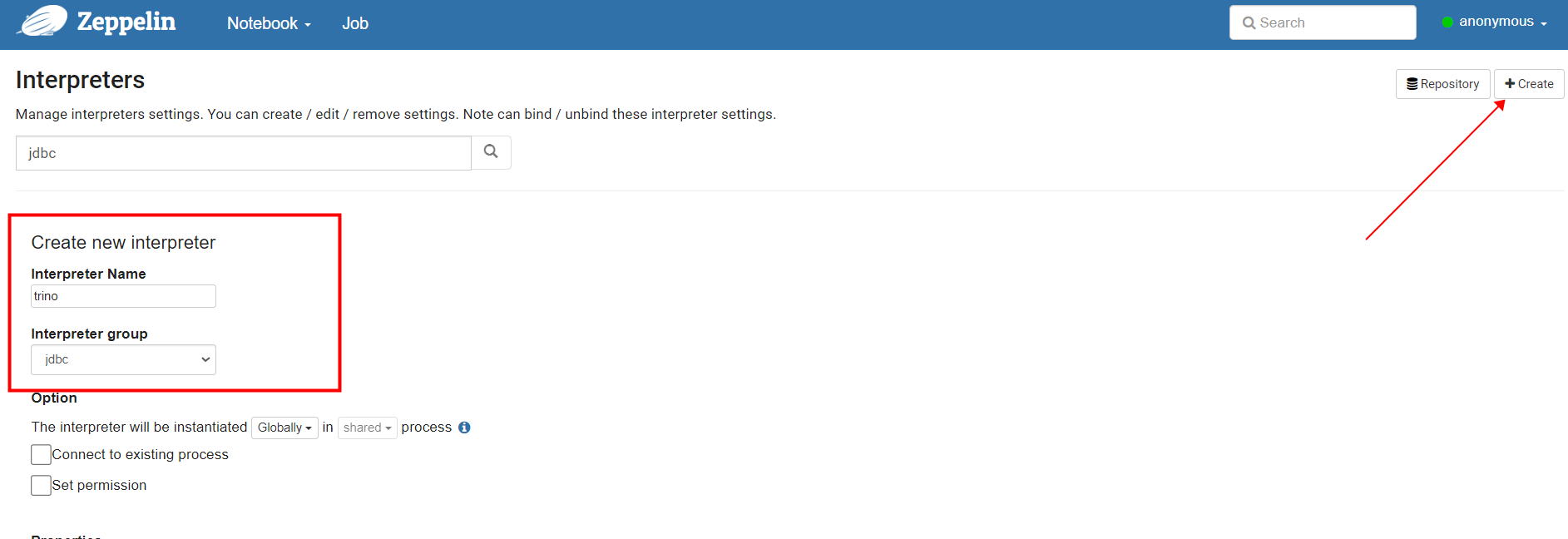
 新增拦截器
新增拦截器
拦截器名字为trino,group设置为jdbc
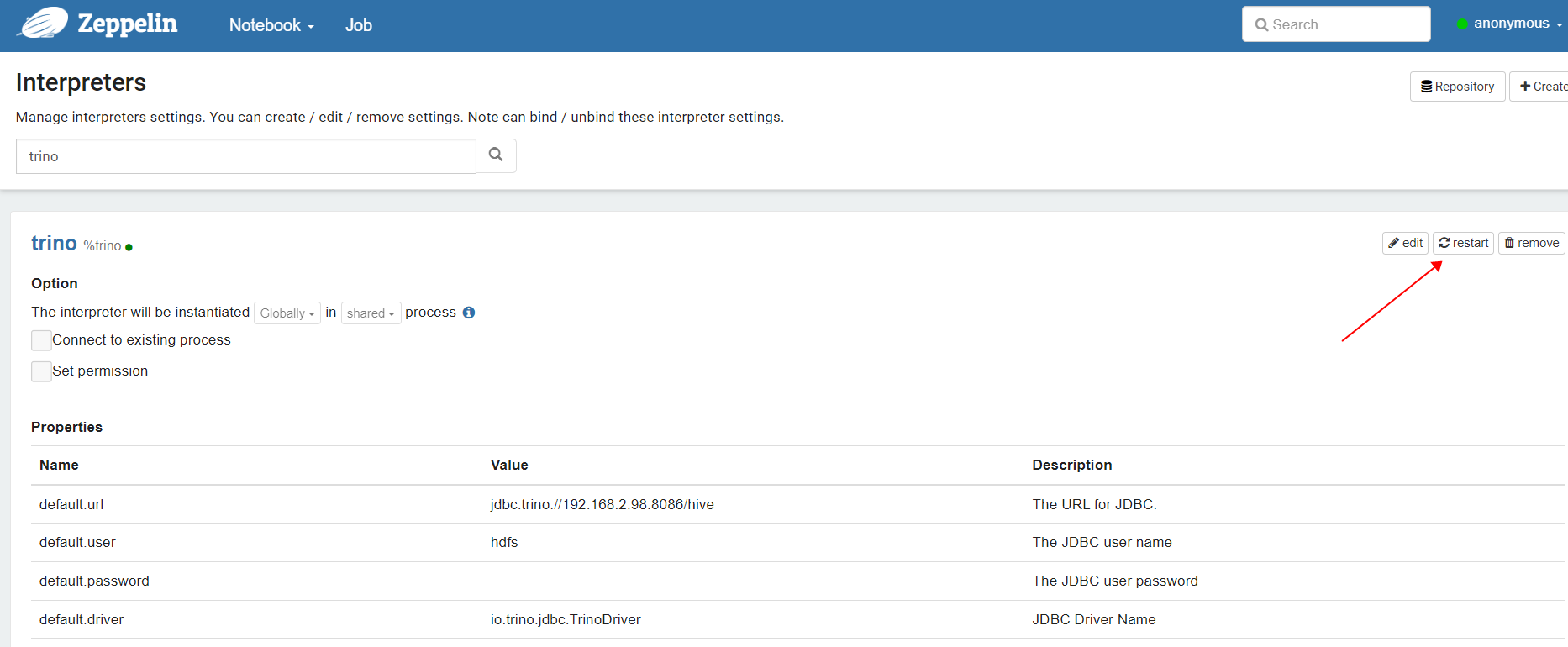
设置属性,添加url和driver,用户名可以随便填,trino默认没有启动用户校验
jdbc:trino://192.168.21.102:10000
| 属性名称 | 属性值 |
| default.url | jdbc:trino://192.168.2.98:8086/hive |
| default.user | hdfs |
| default.driver | io.trino.jdbc.TrinoDriver |
配置完成后我们选择重启
创建一个 new note
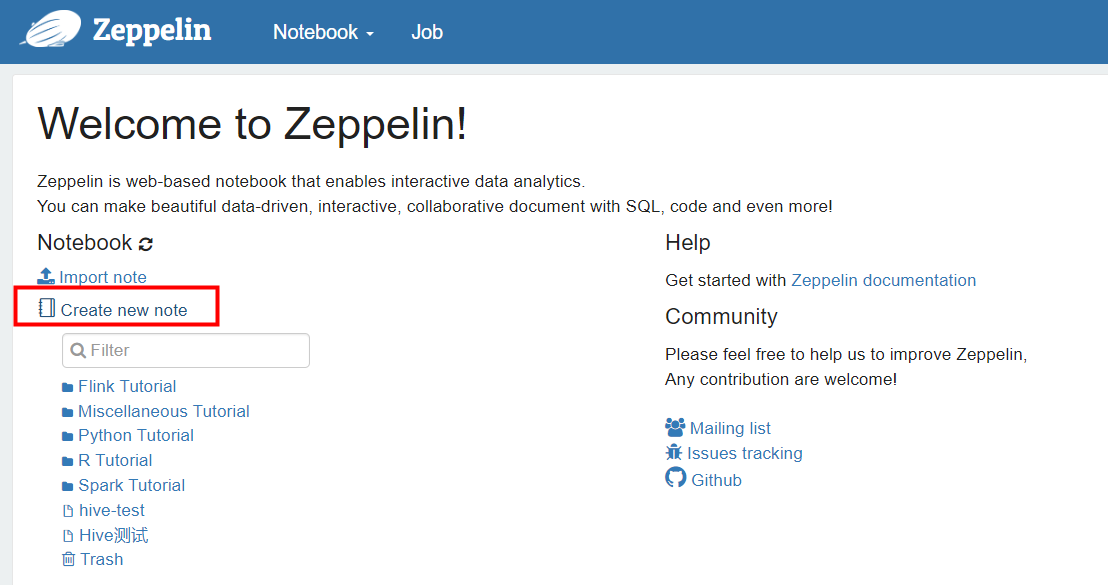
Interpreter选择:trino
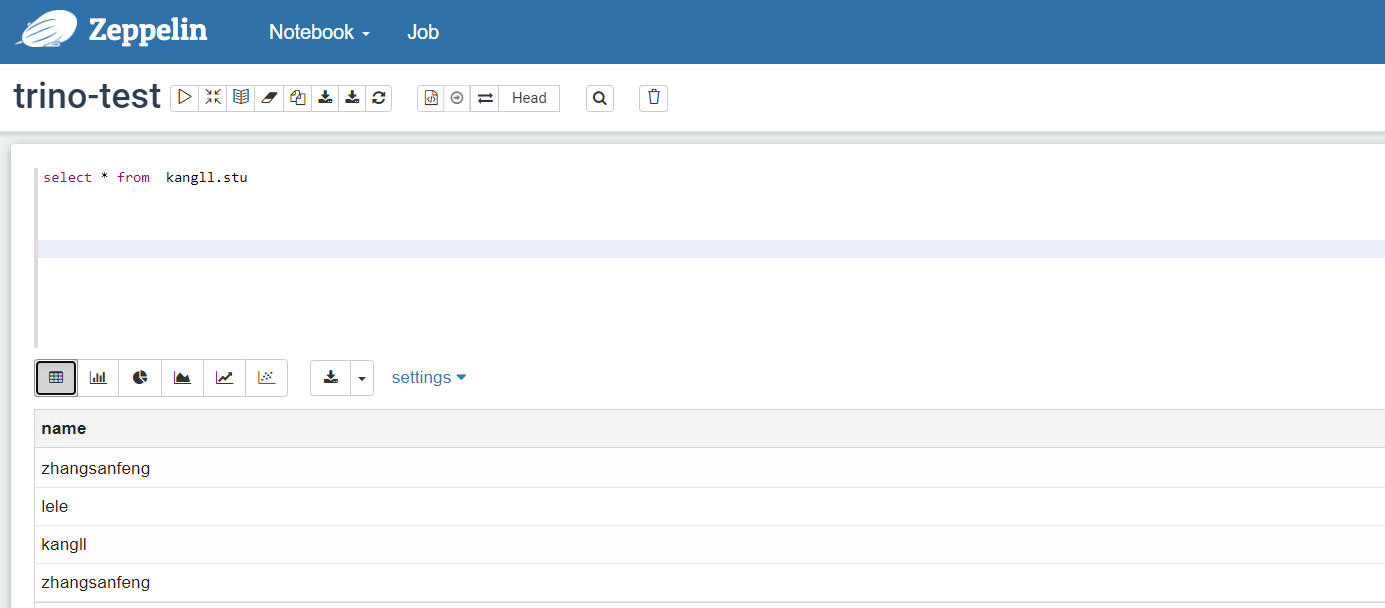
测试查询hive表中数据
spark">3.3 配置Spark解释器
Zeppelin默认的spark解释器包括%spark , %sql , %dep , %pyspark , %ipyspark , %r等子解释器,在实际应用中根据spark集群的参数修改具体的属性进入解释器配置界面,默认为local[*],Spark采用何种运行模式,参数配置信息如下。
- local模式:使用local[*],[]中为线程数,*代表线程数与计算机的CPU核心数一致。
- standalone模式: 使用spark://master:7077
- yarn模式:使用yarn-client或yarn-cluster
- mesos模式:使用mesos://zk://zk1:2181,zk2:2182,zk3:2181/mesos或mesos://host:5050
进入编辑spark拦截器
选择编辑配置SPARK_HOME和spark.master,具体参数含义看官网。

创建note
解释器选择"spark"
 测试运行note
测试运行note
%spark
// create DataFrame from scala Seq. It can infer schema for you.
val df1 = spark.createDataFrame(Seq((1, "andy", 20, "USA"), (2, "jeff", 23, "China"), (3, "james", 18, "USA"))).toDF("id", "name", "age", "country")
df1.printSchema
df1.show()// create DataFrame from scala case class
case class Person(id:Int, name:String, age:Int, country:String)
val df2 = spark.createDataFrame(Seq(Person(1, "andy", 20, "USA"), Person(2, "jeff", 23, "China"), Person(3, "james", 18, "USA")))
df2.printSchema
df2.show()import spark.implicits._
// you can also create Dataset from scala case class
val df3 = spark.createDataset(Seq(Person(1, "andy", 20, "USA"), Person(2, "jeff", 23, "China"), Person(3, "james", 18, "USA")))
df3.printSchema
df3.show()点击 运行
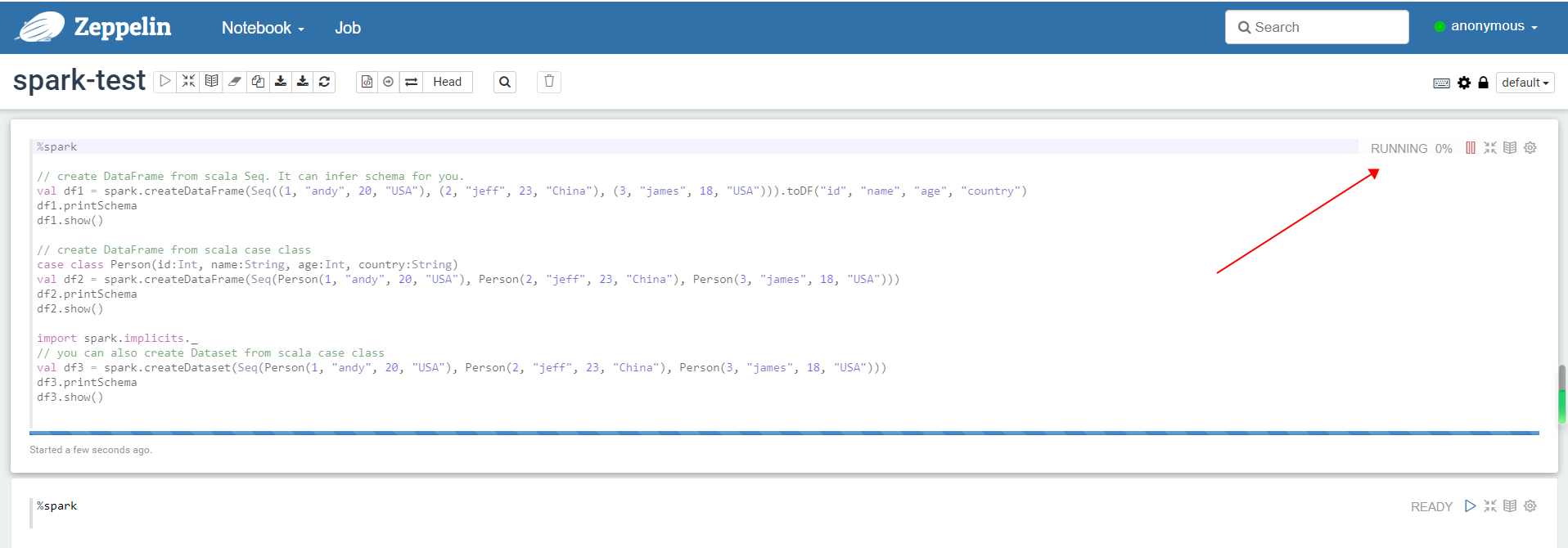
运行结果输出

Apache Zeppelin 一文打尽




