python">import requests
import csv# 打开CSV文件以写入数据
f = open('data.csv', mode='a', encoding='utf-8-sig', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['昵称', '性别', '归属地', '内容'])
csv_writer.writeheader()# 定义一个函数用于获取评论内容
def GetContent(max_id):# 设置请求头部信息,包括Cookie和User-Agentheaders = {"Cookie": "Your Cookie Here","User-Agent": "Your User-Agent Here"}# 构建请求的URLurl = f'https://weibo.com/ajax/statuses/buildComments?flow=0&is_reload=1&id=5024441672929516&is_show_bulletin=2&is_mix=0&max_id={max_id}&count=20&uid=2286908003&fetch_level=0&locale=zh-CN'# 发起GET请求response = requests.get(url=url, headers=headers)# 解析响应的JSON数据json_data = response.json()# 提取评论数据lis = json_data['data']# 遍历评论数据并写入CSV文件for li in lis:name = li['user']['screen_name']try:ip = li['source'].replace('来自', '')except:ip = '未知'content = li['text_raw']gender = li['user']['gender']if gender == 'f':gender = '女'elif gender == 'm':gender = '男'else:gender = '保密'dit = {'昵称': name,'性别': gender,'归属地': ip,'内容': content,}csv_writer.writerow(dit)# 获取下一页评论的max_idnext_id = json_data['max_id']print(next_id)return next_id# 初始化max_id为空字符串,并循环获取评论数据
max_id = ''
for page in range(10):max_id = GetContent(max_id=max_id)# 关闭文件
f.close()
以上展示的是爬取一则微博帖子评论前10页的代码示例,
主要包括的维度有“昵称”“性别”“归属地”“内容”,
同一个url中的“max_id”值代表不同页的数据内容
默认首页url中“max_id"为空,则其json数据“max_id”键指向的是下一页url中“max_id"
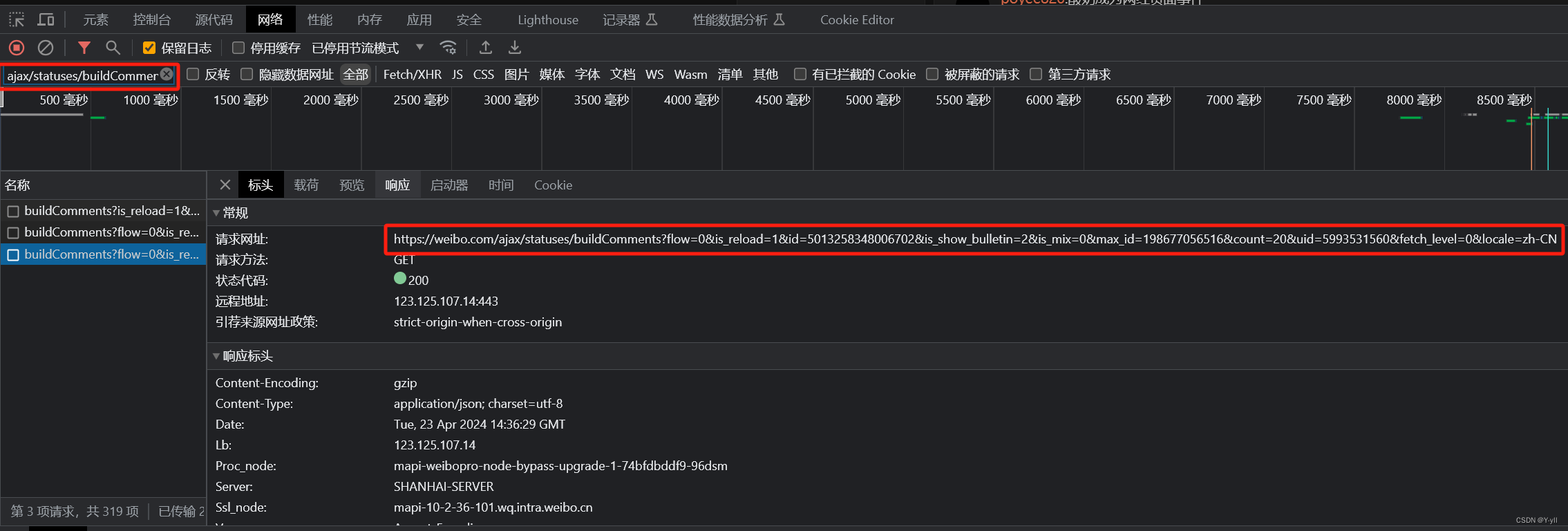
获取页面方法如下:
1.用谷歌浏览器点击进入一条微博链接
2.F12在“网络”中进行过滤“ajax/statuses/buildComments?”
3.选择其中url中带有“max_id"的链接,在代码中更换即可