近年来,图数据库逐渐成为大数据和人工智能领域的热议话题。特别是随着 GraphRAG 技术的火爆,如何高效存储和查询大规模图数据成为很多开发者关心的问题。出于好奇,我最近尝试了 GraphRAG 并研究其存储结构,因此决定进一步探索图数据库的基本原理与实际运用。在此过程中,我发现了一个颇为有趣的开源项目——NebulaGraph。
https://github.com/vesoft-inc/nebulaNebulaGraph:颠覆传统的图数据库解决方案
项目简介
NebulaGraph 是一款开源的图数据库,专注于处理拥有千亿个顶点和万亿条边的超大规模数据集。其独特之处在于提供毫秒级查询延时的性能,使其能够在社交媒体、实时推荐、网络安全、金融风控、知识图谱和人工智能等大规模生产场景中广泛应用。
NebulaGraph 的核心特点
-
全对称分布式架构:每个节点都是对等的,避免了传统主从结构中的瓶颈问题。
-
存储与计算分离:提供更强的灵活性和可扩展性。
-
水平可扩展性:通过增加节点可以轻松扩展数据存储和计算能力。
-
RAFT 协议下的数据强一致性:数据在多个副本之间保持高度一致。
-
支持 openCypher:与广泛使用的查询语言兼容,降低学习成本。
-
用户鉴权:提供细粒度的权限控制。
-
支持多种类型的图计算算法:适应不同的业务场景和需求。
了解 NebulaGraph 的内核架构
NebulaGraph 的设计强调高性能、高可用和高扩展性。其核心架构图如下:

新手指南:如何使用 NebulaGraph
部署 NebulaGraph
-
克隆官方仓库:
git clone -b release-3.8 https://github.com/vesoft-inc/nebula-docker-compose.gitcd nebula-docker-compose/
-
使用 Docker Compose 部署:
docker-compose up -d使用 nGQL 进行数据操作
图空间和 Schema
在 NebulaGraph 中,一个实例可以包含多个图空间,每个图空间是物理隔离的。用户可以在不同的图空间中存储不同的数据集。
创建和选择图空间
图空间和 Schema
一个 NebulaGraph 实例由一个或多个图空间组成。每个图空间都是物理隔离的,用户可以在同一个实例中使用不同的图空间存储不同的数据集。

-
创建图空间:
CREATE SPACE basketballplayer(partition_num=15, replica_factor=1, vid_type=fixed_string(30));-
列出已创建的图空间:
SHOW SPACES;-
选择图空间:
USE basketballplayer;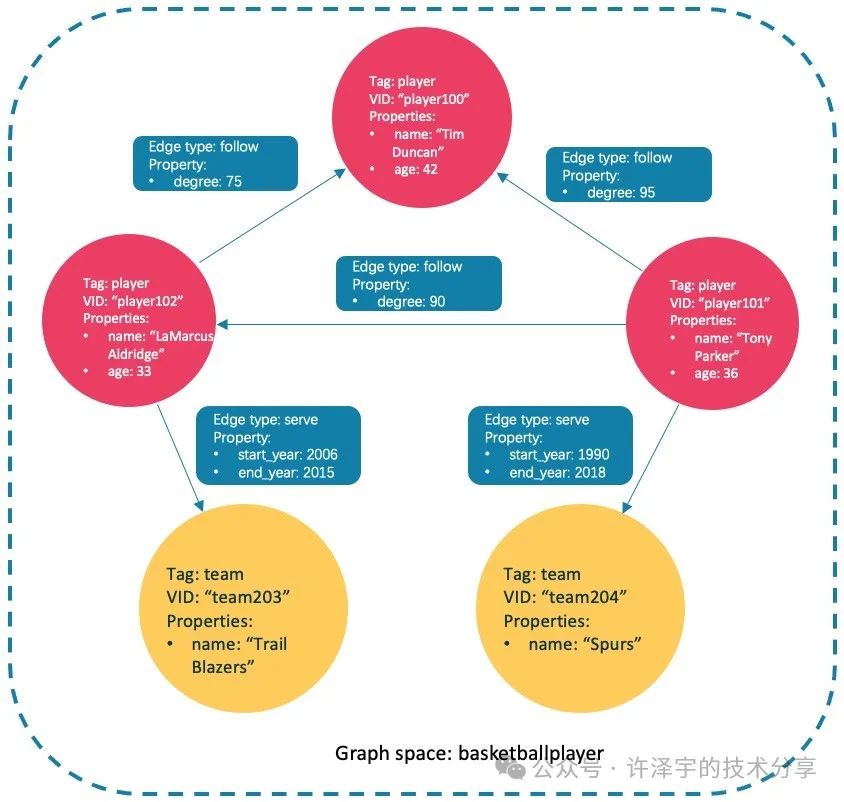
创建 Tag 和 Edge type
-
创建 Tag:
CREATE TAG player(name string, age int);CREATE TAG team(name string);
-
创建 Edge type:
CREATE EDGE follow(degree int);CREATE EDGE serve(start_year int, end_year int);
插入数据
-
插入点(Vertices):
INSERT VERTEX player(name, age) VALUES "player100":("Tim Duncan", 42);INSERT VERTEX player(name, age) VALUES "player101":("Tony Parker", 36);INSERT VERTEX player(name, age) VALUES "player102":("LaMarcus Aldridge", 33);INSERT VERTEX team(name) VALUES "team203":("Trail Blazers"), "team204":("Spurs");
-
插入边(Edges):
INSERT EDGE follow(degree) VALUES "player101" -> "player100":(95);INSERT EDGE follow(degree) VALUES "player101" -> "player102":(90);INSERT EDGE follow(degree) VALUES "player102" -> "player100":(75);INSERT EDGE serve(start_year, end_year) VALUES "player101" -> "team204":(1999, 2018), "player102" -> "team203":(2006, 2015);
查询数据
使用 nGQL,我们可以轻松地对数据进行查询:
-
使用 GO 语句:
GO FROM "player101" OVER follow YIELD id($$);-
使用 FETCH 语句:
FETCH PROP ON player "player100" YIELD properties(vertex);-
使用 MATCH 语句:
MATCH (v:player{name:"Tony Parker"}) RETURN v;其他操作
修改点和边
使用 UPDATE 或 UPSERT 语句修改数据:
-
修改点:
UPDATE VERTEX "player100" SET player.name = "Tim";-
修改边:
UPDATE EDGE ON follow "player101" -> "player100" SET degree = 96;删除点和边
-
删除点:
DELETE VERTEX "player111", "team203";-
删除边:
DELETE EDGE follow "player101" -> "team204";使用索引
为 Tag 和 Edge type 创建索引:
-
创建索引:
-
CREATE TAG INDEX player_index_1 ON player(name(20));
-
重建索引:
REBUILD TAG INDEX player_index_1;-
基于索引查询数据:
LOOKUP ON player WHERE player.name == "Tony Parker" YIELD properties(vertex).name AS name, properties(vertex).age AS age;MATCH (v:player{name:"Tony Parker"}) RETURN v;
通过以上步骤,您可以顺利开始使用 NebulaGraph 存储和查询大规模图数据。无论是在社交媒体推荐系统还是金融风控领域,NebulaGraph 都能为您提供强大的数据支持。如果您对图数据库感兴趣,不妨一试 NebulaGraph,相信您会从中发现更多有趣的应用场景。
结语
通过对 NebulaGraph 与 GraphRAG 技术的深入探索,我们可以看到图数据库在处理大规模数据集方面有明显的优势。无论是在高效的数据存储、快速的复杂查询,还是灵活的数据建模方面,NebulaGraph 都展示了其强大的能力。而 nGQL 的设计更是让开发者在处理复杂关联数据时更加得心应手。
希望这篇文章能帮助你深入理解 GraphRAG 技术及其存储原理,同时通过对 NebulaGraph 的实战介绍,让你在实际项目中实现高效的数据管理。如果你对图数据库领域感兴趣,不妨尝试一下 NebulaGraph,我相信你一定会从中获得更多的启发和收获。



