前言
哈喽哈喽,这里是zyll~,北浊.(大家可以亲切的呼唤我叫小北)智慧龙阁的创始人,一个在大数据和全站领域不断深耕的技术创作者。今天,我想和大家分享一些关于华为昇腾CANN训练营以及AI技术创新的最新资讯和实践经验~(初级证书还没拿到的小伙伴,可以先参考小北的这篇技术博客先考一下理论题)小北的技术博客:探索华为昇腾CANN训练营与AI技术创新——Ascend C算子开发能力认证考试(初级)-CSDN博客![]() https://blog.csdn.net/Zhiyilang/article/details/142783789?spm=1001.2014.3001.5501
https://blog.csdn.net/Zhiyilang/article/details/142783789?spm=1001.2014.3001.5501
一、华为昇腾CANN训练营2024第二季介绍
近期,小北参与了华为昇腾CANN训练营2024第二季的学习,这次训练营聚焦于Ascend C算子开发能力认证(中级),为我提供了一个深入学习昇腾AI基础软硬件平台的机会。通过系统的课程学习和实践操作,我不仅掌握了算子开发的基本技能,还了解了昇腾原生开发的全流程,这对于小北在大数据和AI领域的进一步研究具有重要意义。
二、CANN训练营代金券领取与使用指南
为了让更多的友友能够参与到CANN训练营中来,小北教学大家如何获取华为提供的代金券领取福利。以下是具体的领取和使用指南:

代金券领取方式:
步骤一:点击链接进入昇腾社区主页并登录:昇腾社区官网-昇腾万里 让智能无所不及昇腾社区是基于昇腾系列处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,包括昇腾系列处理器、系列硬件、CANN异构计算架构、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链。![]() https://www.hiascend.com/
https://www.hiascend.com/
步骤二:点击右上角头像框进入用户个人中心
步骤三:点击成长值进入成长空间,可以领取对应级别张数代金券
 步骤四:点击左下角微认证代金券进入领取
步骤四:点击左下角微认证代金券进入领取



方式二
点击学习-认证进入微认证列表,直接点击微认证代金券领取,每周限领1张

- 领取代金券后,可在CANN训练营报名页面使用。选择相应的课程或认证项目,进入支付环节,系统会自动识别并抵扣代金券金额。
- 请注意代金券的有效期和使用范围,确保在有效期内使用并避免浪费。
二、代金券使用指南:

步骤一:进入微认证考核界面
1、点击个人中心-我的券码中查看代金券,直接在个人中心点击代金券即可进入微认证考核界
2、通过昇腾社区点击学习-认证进入
步骤二:直接点击进入Ascend C算子开发能力认证(中级)
步骤三:
方式一
直接点击立即认证进行考试


方式二
1、点击立即兑换
2、前往用户个人中心-我的券码-微认证代金券界面,点击复制券码

3、点击输入微认证券码-立即兑换
4、点击立即认证-开始考核进行Ascend C算子中级认证考核

原题:
1、考试类型:编程题
2、考试时长
不限(下方考试时间仅2小时,请做好题目合成文件包后,再进考试上传!)
3、考试环境搭建要求:
环境上要有昇腾NPU,且CANN版本为8.0.RC2.alpha003。请开发者自行准备。
典型场景举例:
- 开发者套件(Atlas200I DK A2,或香橙派)部署方式
- 华为云-ModelArts-Notebook部署方式
4、考试题目:
实现Ascend C算子Sinh,算子命名为SinhCustom,编写其kernel侧代码、host侧代码,并完成aclnn算子调用测试。
相关算法:sinh(x) = (exp(x) - exp(-x)) / 2.0
要求:
4.1 完成Sinh算子kernel侧核函数相关代码补齐。
4.2 完成Sinh算子host侧Tiling结构体成员变量创建,以及Tiling实现函数的补齐。
4.3 要支持Float16类型输入输出。
4.4 不要使用Sinh高阶API,使用高阶API不得分
5、考题代码工程:
SinhCustom.tar.gz https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/AscendC/SinhCustom.tar.gz
https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/AscendC/SinhCustom.tar.gz
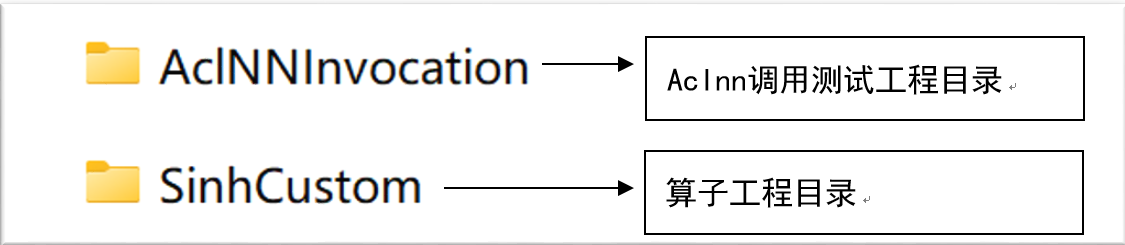
注意:若选用非开发者套件环境,请自行确认算子工程目录中以下两个文件正确性:
- CmakePresets.json,确认该文件中此处配置的是正确的CANN开发包安装路径:

以及确认该文件中此处配置的芯片名称与您的开发环境相匹配:

- op_host/sinh_custom.cpp,确认该文件中此处的芯片名称配置与您的开发环境相匹配:

6、考试说明:
6.1 提供的考题代码工程中,SinhCustom目录为算子工程目录,依次打开下图红框所示的三个源码文件,并根据注释提示补全相关代码,可参考示例。
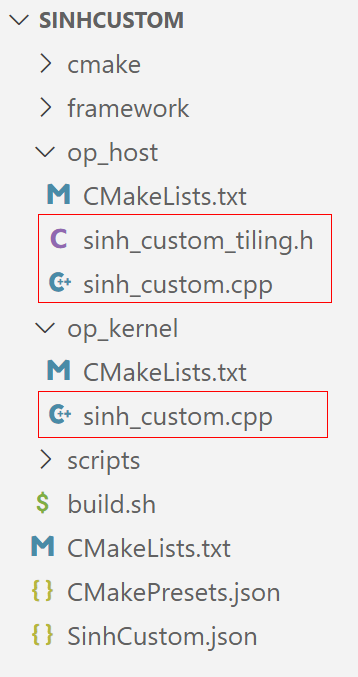
一、op_host文件夹下的sinh_custom_tiling.h文件
原题:
#include "register/tilingdata_base.h"
/**
这里定义了tiling数据结构的字段totalLength和tileNum,它们分别表示输入数据的总长度和分块数目。通过REGISTER_TILING_DATA_CLASS将SinhCustomTilingData与算子SinhCustom进行绑定。
**/
namespace optiling {BEGIN_TILING_DATA_DEF(SinhCustomTilingData)//考生自行定义tiling结构体成员变量TILING_DATA_FIELD_DEF(uint32_t, totalLength);TILING_DATA_FIELD_DEF(uint32_t, tileNum);END_TILING_DATA_DEF;REGISTER_TILING_DATA_CLASS(SinhCustom, SinhCustomTilingData)
}答案:
#include "register/tilingdata_base.h"
namespace optiling {
BEGIN_TILING_DATA_DEF(SinhCustomTilingData)//考生自行定义 tiling 结构体成员变量
TILING_DATA_FIELD_DEF(uint32_t, totalLength);
TILING_DATA_FIELD_DEF(uint32_t, tileNum);
END_TILING_DATA_DEF;
REGISTER_TILING_DATA_CLASS(SinhCustom, SinhCustomTilingData)
}二、op_host文件夹下的sinh_custom.cpp文件
原题:
#include "kernel_operator.h"
using namespace AscendC;constexpr int32_t BUFFER_NUM = 2; // 定义缓冲区的数量为2// 定义自定义的 KernelSinh 类,用于实现 sinh 运算的自定义内核
class KernelSinh {
public:// 内核类的构造函数,使用 `__aicore__` 关键词表示这是在 AI Core 上执行的代码__aicore__ inline KernelSinh() {}/*** @brief Init 函数负责初始化全局内存、局部缓存以及块和Tile的长度。** @param x 输入数据的全局内存地址* @param y 输出数据的全局内存地址* @param totalLength 输入数据的总长度* @param tileNum 每个块内的数据将被进一步划分为多少个Tile*/__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, uint32_t totalLength, uint32_t tileNum){// 确保块的数量不为0,否则输出错误信息ASSERT(GetBlockNum() != 0 && "block dim can not be zero!");// 计算每个块需要处理的数据长度this->blockLength = totalLength / GetBlockNum();this->tileNum = tileNum;// 确保tile的数量不为0,否则输出错误信息ASSERT(tileNum != 0 && "tile num can not be zero!");// 计算每个Tile的数据长度this->tileLength = this->blockLength / tileNum / BUFFER_NUM;// 初始化全局内存中输入和输出数据的缓存区域xGm.SetGlobalBuffer((__gm__ DTYPE_X*)x + this->blockLength * GetBlockIdx(),this->blockLength);yGm.SetGlobalBuffer((__gm__ DTYPE_Y*)y + this->blockLength * GetBlockIdx(),this->blockLength);// 初始化队列和缓冲区,用于存储计算中间数据pipe.InitBuffer(inQueueX, BUFFER_NUM, this->tileLength * sizeof(DTYPE_X));pipe.InitBuffer(outQueueY, BUFFER_NUM, this->tileLength * sizeof(DTYPE_Y));pipe.InitBuffer(tmpBuffer1, this->tileLength * sizeof(DTYPE_X));pipe.InitBuffer(tmpBuffer2, this->tileLength * sizeof(DTYPE_X));pipe.InitBuffer(tmpBuffer3, this->tileLength * sizeof(DTYPE_X));pipe.InitBuffer(tmpBuffer4, this->tileLength * sizeof(DTYPE_X));}/*** @brief Process 函数负责执行主循环,包括数据拷贝和计算。*/__aicore__ inline void Process(){// 计算循环次数,等于 tileNum 乘以缓冲区数量int32_t loopCount = this->tileNum * BUFFER_NUM;for (int32_t i = 0; i < loopCount; i++) {// 依次进行输入数据拷贝、计算以及输出数据拷贝CopyIn(i);Compute(i);CopyOut(i);}}private:/*** @brief CopyIn 函数从全局内存将数据拷贝到局部内存** @param progress 当前处理进度*/__aicore__ inline void CopyIn(int32_t progress){// 从输入队列中分配一个局部张量,用于存储输入数据LocalTensor<DTYPE_X> xLocal = inQueueX.AllocTensor<DTYPE_X>();// 将全局内存中的数据拷贝到局部张量中DataCopy(xLocal, xGm[progress * this->tileLength], this->tileLength);// 将局部张量加入到输入队列中inQueueX.EnQue(xLocal);}/*** @brief Compute 函数执行具体的sinh计算操作** @param progress 当前处理进度*/__aicore__ inline void Compute(int32_t progress){// 从输入队列中获取一个局部张量LocalTensor<DTYPE_X> xLocal = inQueueX.DeQue<DTYPE_X>();// 为输出分配一个局部张量LocalTensor<DTYPE_Y> yLocal = outQueueY.AllocTensor<DTYPE_Y>();// 为中间计算结果分配临时张量LocalTensor<DTYPE_X> tmpTensor1 = tmpBuffer1.Get<DTYPE_X>();LocalTensor<DTYPE_X> tmpTensor2 = tmpBuffer2.Get<DTYPE_X>();LocalTensor<DTYPE_X> tmpTensor3 = tmpBuffer3.Get<DTYPE_X>();LocalTensor<DTYPE_X> tmpTensor4 = tmpBuffer4.Get<DTYPE_X>();// 定义计算过程中的常量DTYPE_X inputVal1 = -1;DTYPE_X inputVal2 = 0.5;// sinh(x) = (exp(x) - exp(-x)) / 2.0// 具体计算过程如下:// 1. 将输入张量 xLocal 乘以 -1,得到 -xMuls(tmpTensor1, xLocal, inputVal1, this->tileLength);// 2. 计算 exp(-x)Exp(tmpTensor2, tmpTensor1, this->tileLength);// 3. 计算 exp(x)Exp(tmpTensor3, xLocal, this->tileLength);// 4. 计算 exp(x) - exp(-x)Sub(tmpTensor4, tmpTensor3, tmpTensor2, this->tileLength);// 5. 将结果乘以 0.5,得到 sinh(x)Muls(yLocal, tmpTensor4, inputVal2, this->tileLength);// 将输出张量放入输出队列outQueueY.EnQue<DTYPE_Y>(yLocal);// 释放局部张量inQueueX.FreeTensor(xLocal);}/*** @brief CopyOut 函数将局部内存中的结果拷贝回全局内存** @param progress 当前处理进度*/__aicore__ inline void CopyOut(int32_t progress){// 从输出队列中获取一个局部张量LocalTensor<DTYPE_Y> yLocal = outQueueY.DeQue<DTYPE_Y>();// 将局部内存中的结果拷贝到全局内存DataCopy(yGm[progress * this->tileLength], yLocal, this->tileLength);// 释放局部张量outQueueY.FreeTensor(yLocal);}private:// 定义用于存储数据的管道和队列TPipe pipe;// 输入和输出队列,深度为缓冲区数量TQue<QuePosition::VECIN, BUFFER_NUM> inQueueX;TQue<QuePosition::VECOUT, BUFFER_NUM> outQueueY;// 全局张量,用于存储全局内存中的输入和输出GlobalTensor<half> xGm;GlobalTensor<half> yGm;// 定义临时缓冲区,用于中间计算TBuf<QuePosition::VECCALC> tmpBuffer1, tmpBuffer2, tmpBuffer3, tmpBuffer4;// 存储块的长度、Tile数量和Tile长度uint32_t blockLength;uint32_t tileNum;uint32_t tileLength;
};/**
* @brief 自定义的内核函数,通过 Init 初始化操作,并调用 Process 执行计算
*
* @param x 输入数据的全局内存地址
* @param y 输出数据的全局内存地址
* @param workspace 工作空间的地址
* @param tiling 分块信息的地址
*/
extern "C" __global__ __aicore__ void sinh_custom(GM_ADDR x, GM_ADDR y, GM_ADDR workspace, GM_ADDR tiling) {// 获取分块数据GET_TILING_DATA(tiling_data, tiling);// 创建 KernelSinh 对象KernelSinh op;// 调用 Init 和 Process 函数,进行初始化和计算op.Init(x, y, tiling_data.totalLength, tiling_data.tileNum);op.Process();
}答案:
#include "sinh_custom_tiling.h"
#include "register/op_def_registry.h"
namespace optiling {
static ge::graphStatus TilingFunc(gert::TilingContext* context)
{SinhCustomTilingData tiling;//考生自行填充const uint32_t BLOCK_DIM = 8;const uint32_t TILE_NUM = 8;uint32_t totalLength = context->GetInputShape(0)->GetOriginShape().GetShapeSize();context->SetBlockDim(BLOCK_DIM);tiling.set_totalLength(totalLength);tiling.set_tileNum(TILE_NUM);tiling.SaveToBuffer(context->GetRawTilingData()->GetData(),
context->GetRawTilingData()->GetCapacity());context->GetRawTilingData()->SetDataSize(tiling.GetDataSize());size_t *currentWorkspace = context->GetWorkspaceSizes(1);currentWorkspace[0] = 0;return ge::GRAPH_SUCCESS;
}
}
namespace ge {
static ge::graphStatus InferShape(gert::InferShapeContext* context)
{const gert::Shape* x1_shape = context->GetInputShape(0);gert::Shape* y_shape = context->GetOutputShape(0);*y_shape = *x1_shape;return GRAPH_SUCCESS;
}
}
namespace ops {
class SinhCustom : public OpDef {
public:explicit SinhCustom(const char* name) : OpDef(name){this->Input("x").ParamType(REQUIRED).DataType({ge::DT_FLOAT16}).Format({ge::FORMAT_ND}).UnknownShapeFormat({ge::FORMAT_ND});this->Output("y").ParamType(REQUIRED).DataType({ge::DT_FLOAT16}).Format({ge::FORMAT_ND}).UnknownShapeFormat({ge::FORMAT_ND});this->SetInferShape(ge::InferShape);this->AICore().SetTiling(optiling::TilingFunc);this->AICore().AddConfig("ascend310b");}
};
OP_ADD(SinhCustom);
}3、op_kernel文件夹下的sinh_custom.cpp文件
原题:
#include "kernel_operator.h"
using namespace AscendC;constexpr int32_t BUFFER_NUM = 2; // 定义缓冲区的数量为2// 定义自定义的 KernelSinh 类,用于实现 sinh 运算的自定义内核
class KernelSinh {
public:// 内核类的构造函数,使用 `__aicore__` 关键词表示这是在 AI Core 上执行的代码__aicore__ inline KernelSinh() {}/*** @brief Init 函数负责初始化全局内存、局部缓存以及块和Tile的长度。** @param x 输入数据的全局内存地址* @param y 输出数据的全局内存地址* @param totalLength 输入数据的总长度* @param tileNum 每个块内的数据将被进一步划分为多少个Tile*/__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, uint32_t totalLength, uint32_t tileNum){// 确保块的数量不为0,否则输出错误信息ASSERT(GetBlockNum() != 0 && "block dim can not be zero!");// 计算每个块需要处理的数据长度this->blockLength = totalLength / GetBlockNum();this->tileNum = tileNum;// 确保tile的数量不为0,否则输出错误信息ASSERT(tileNum != 0 && "tile num can not be zero!");// 计算每个Tile的数据长度this->tileLength = this->blockLength / tileNum / BUFFER_NUM;// 初始化全局内存中输入和输出数据的缓存区域xGm.SetGlobalBuffer((__gm__ DTYPE_X*)x + this->blockLength * GetBlockIdx(),this->blockLength);yGm.SetGlobalBuffer((__gm__ DTYPE_Y*)y + this->blockLength * GetBlockIdx(),this->blockLength);// 初始化队列和缓冲区,用于存储计算中间数据pipe.InitBuffer(inQueueX, BUFFER_NUM, this->tileLength * sizeof(DTYPE_X));pipe.InitBuffer(outQueueY, BUFFER_NUM, this->tileLength * sizeof(DTYPE_Y));pipe.InitBuffer(tmpBuffer1, this->tileLength * sizeof(DTYPE_X));pipe.InitBuffer(tmpBuffer2, this->tileLength * sizeof(DTYPE_X));pipe.InitBuffer(tmpBuffer3, this->tileLength * sizeof(DTYPE_X));pipe.InitBuffer(tmpBuffer4, this->tileLength * sizeof(DTYPE_X));}/*** @brief Process 函数负责执行主循环,包括数据拷贝和计算。*/__aicore__ inline void Process(){// 计算循环次数,等于 tileNum 乘以缓冲区数量int32_t loopCount = this->tileNum * BUFFER_NUM;for (int32_t i = 0; i < loopCount; i++) {// 依次进行输入数据拷贝、计算以及输出数据拷贝CopyIn(i);Compute(i);CopyOut(i);}}private:/*** @brief CopyIn 函数从全局内存将数据拷贝到局部内存** @param progress 当前处理进度*/__aicore__ inline void CopyIn(int32_t progress){// 从输入队列中分配一个局部张量,用于存储输入数据LocalTensor<DTYPE_X> xLocal = inQueueX.AllocTensor<DTYPE_X>();// 将全局内存中的数据拷贝到局部张量中DataCopy(xLocal, xGm[progress * this->tileLength], this->tileLength);// 将局部张量加入到输入队列中inQueueX.EnQue(xLocal);}/*** @brief Compute 函数执行具体的sinh计算操作** @param progress 当前处理进度*/__aicore__ inline void Compute(int32_t progress){// 从输入队列中获取一个局部张量LocalTensor<DTYPE_X> xLocal = inQueueX.DeQue<DTYPE_X>();// 为输出分配一个局部张量LocalTensor<DTYPE_Y> yLocal = outQueueY.AllocTensor<DTYPE_Y>();// 为中间计算结果分配临时张量LocalTensor<DTYPE_X> tmpTensor1 = tmpBuffer1.Get<DTYPE_X>();LocalTensor<DTYPE_X> tmpTensor2 = tmpBuffer2.Get<DTYPE_X>();LocalTensor<DTYPE_X> tmpTensor3 = tmpBuffer3.Get<DTYPE_X>();LocalTensor<DTYPE_X> tmpTensor4 = tmpBuffer4.Get<DTYPE_X>();// 定义计算过程中的常量DTYPE_X inputVal1 = -1;DTYPE_X inputVal2 = 0.5;// sinh(x) = (exp(x) - exp(-x)) / 2.0// 具体计算过程如下:// 1. 将输入张量 xLocal 乘以 -1,得到 -xMuls(tmpTensor1, xLocal, inputVal1, this->tileLength);// 2. 计算 exp(-x)Exp(tmpTensor2, tmpTensor1, this->tileLength);// 3. 计算 exp(x)Exp(tmpTensor3, xLocal, this->tileLength);// 4. 计算 exp(x) - exp(-x)Sub(tmpTensor4, tmpTensor3, tmpTensor2, this->tileLength);// 5. 将结果乘以 0.5,得到 sinh(x)Muls(yLocal, tmpTensor4, inputVal2, this->tileLength);// 将输出张量放入输出队列outQueueY.EnQue<DTYPE_Y>(yLocal);// 释放局部张量inQueueX.FreeTensor(xLocal);}/*** @brief CopyOut 函数将局部内存中的结果拷贝回全局内存** @param progress 当前处理进度*/__aicore__ inline void CopyOut(int32_t progress){// 从输出队列中获取一个局部张量LocalTensor<DTYPE_Y> yLocal = outQueueY.DeQue<DTYPE_Y>();// 将局部内存中的结果拷贝到全局内存DataCopy(yGm[progress * this->tileLength], yLocal, this->tileLength);// 释放局部张量outQueueY.FreeTensor(yLocal);}private:// 定义用于存储数据的管道和队列TPipe pipe;// 输入和输出队列,深度为缓冲区数量TQue<QuePosition::VECIN, BUFFER_NUM> inQueueX;TQue<QuePosition::VECOUT, BUFFER_NUM> outQueueY;// 全局张量,用于存储全局内存中的输入和输出GlobalTensor<half> xGm;GlobalTensor<half> yGm;// 定义临时缓冲区,用于中间计算TBuf<QuePosition::VECCALC> tmpBuffer1, tmpBuffer2, tmpBuffer3, tmpBuffer4;// 存储块的长度、Tile数量和Tile长度uint32_t blockLength;uint32_t tileNum;uint32_t tileLength;
};/**
* @brief 自定义的内核函数,通过 Init 初始化操作,并调用 Process 执行计算
*
* @param x 输入数据的全局内存地址
* @param y 输出数据的全局内存地址
* @param workspace 工作空间的地址
* @param tiling 分块信息的地址
*/
extern "C" __global__ __aicore__ void sinh_custom(GM_ADDR x, GM_ADDR y, GM_ADDR workspace, GM_ADDR tiling) {// 获取分块数据GET_TILING_DATA(tiling_data, tiling);// 创建 KernelSinh 对象KernelSinh op;// 调用 Init 和 Process 函数,进行初始化和计算op.Init(x, y, tiling_data.totalLength, tiling_data.tileNum);op.Process();
}答案:
#include "kernel_operator.h"
using namespace AscendC;
constexpr int32_t BUFFER_NUM = 2;
class KernelSinh {
public:__aicore__ inline KernelSinh() {}__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, uint32_t totalLength, uint32_t
tileNum){//考生补充初始化代码ASSERT(GetBlockNum() != 0 && "block dim can not be zero!");this->blockLength = totalLength / GetBlockNum();this->tileNum = tileNum;ASSERT(tileNum != 0 && "tile num can not be zero!");this->tileLength = this->blockLength / tileNum / BUFFER_NUM;xGm.SetGlobalBuffer((__gm__ DTYPE_X *)x + this->blockLength * GetBlockIdx(),
this->blockLength);yGm.SetGlobalBuffer((__gm__ DTYPE_Y *)y + this->blockLength * GetBlockIdx(),
this->blockLength);pipe.InitBuffer(inQueueX, BUFFER_NUM, this->tileLength * sizeof(DTYPE_X));pipe.InitBuffer(outQueueY, BUFFER_NUM, this->tileLength * sizeof(DTYPE_Y));pipe.InitBuffer(tmpBuffer1, this->tileLength * sizeof(DTYPE_X));pipe.InitBuffer(tmpBuffer2, this->tileLength * sizeof(DTYPE_X));pipe.InitBuffer(tmpBuffer3, this->tileLength * sizeof(DTYPE_X));pipe.InitBuffer(tmpBuffer4, this->tileLength * sizeof(DTYPE_X));}__aicore__ inline void Process(){//考生补充对“loopCount”的定义,注意对 Tiling 的处理int32_t loopCount = this->tileNum * BUFFER_NUM;for (int32_t i = 0; i < loopCount; i++) {CopyIn(i);Compute(i);CopyOut(i);}}
private:__aicore__ inline void CopyIn(int32_t progress){//考生补充算子代码LocalTensor<DTYPE_X> xLocal = inQueueX.AllocTensor<DTYPE_X>();DataCopy(xLocal, xGm[progress * this->tileLength], this->tileLength);inQueueX.EnQue(xLocal);}__aicore__ inline void Compute(int32_t progress){//考生补充算子计算代码LocalTensor<DTYPE_X> xLocal = inQueueX.DeQue<DTYPE_X>();LocalTensor<DTYPE_Y> yLocal = outQueueY.AllocTensor<DTYPE_Y>();LocalTensor<DTYPE_X> tmpTensor1 = tmpBuffer1.Get<DTYPE_X>();LocalTensor<DTYPE_X> tmpTensor2 = tmpBuffer2.Get<DTYPE_X>();LocalTensor<DTYPE_X> tmpTensor3 = tmpBuffer3.Get<DTYPE_X>();LocalTensor<DTYPE_X> tmpTensor4 = tmpBuffer4.Get<DTYPE_X>();DTYPE_X inputVal1 = -1;DTYPE_X inputVal2 = 0.5;//sinh(x) = (exp(x) - exp(-x)) / 2.0Muls(tmpTensor1, xLocal, inputVal1, this->tileLength);Exp(tmpTensor2, tmpTensor1, this->tileLength);Exp(tmpTensor3, xLocal, this->tileLength);Sub(tmpTensor4, tmpTensor3, tmpTensor2, this->tileLength);Muls(yLocal, tmpTensor4, inputVal2, this->tileLength);outQueueY.EnQue<DTYPE_Y>(yLocal);inQueueX.FreeTensor(xLocal);}__aicore__ inline void CopyOut(int32_t progress){//考生补充算子代码LocalTensor<DTYPE_Y> yLocal = outQueueY.DeQue<DTYPE_Y>();DataCopy(yGm[progress * this->tileLength], yLocal, this->tileLength);outQueueY.FreeTensor(yLocal);}
private:TPipe pipe;//create queue for input, in this case depth is equal to buffer numTQue<QuePosition::VECIN, BUFFER_NUM> inQueueX;//create queue for output, in this case depth is equal to buffer numTQue<QuePosition::VECOUT, BUFFER_NUM> outQueueY;GlobalTensor<half> xGm;GlobalTensor<half> yGm;//考生补充自定义成员变量TBuf<QuePosition::VECCALC> tmpBuffer1, tmpBuffer2, tmpBuffer3, tmpBuffer4;uint32_t blockLength;uint32_t tileNum;uint32_t tileLength;
};
extern "C" __global__ __aicore__ void sinh_custom(GM_ADDR x, GM_ADDR y, GM_ADDR
workspace, GM_ADDR tiling) {GET_TILING_DATA(tiling_data, tiling);KernelSinh op;//补充 init 和 process 函数调用内容op.Init(x, y, tiling_data.totalLength, tiling_data.tileNum);op.Process();
}6.2 代码补齐完成后,请在算子工程目录下执行如下命令进行编译构建:
bash build.sh当命令行显示如下信息证明构建成功:

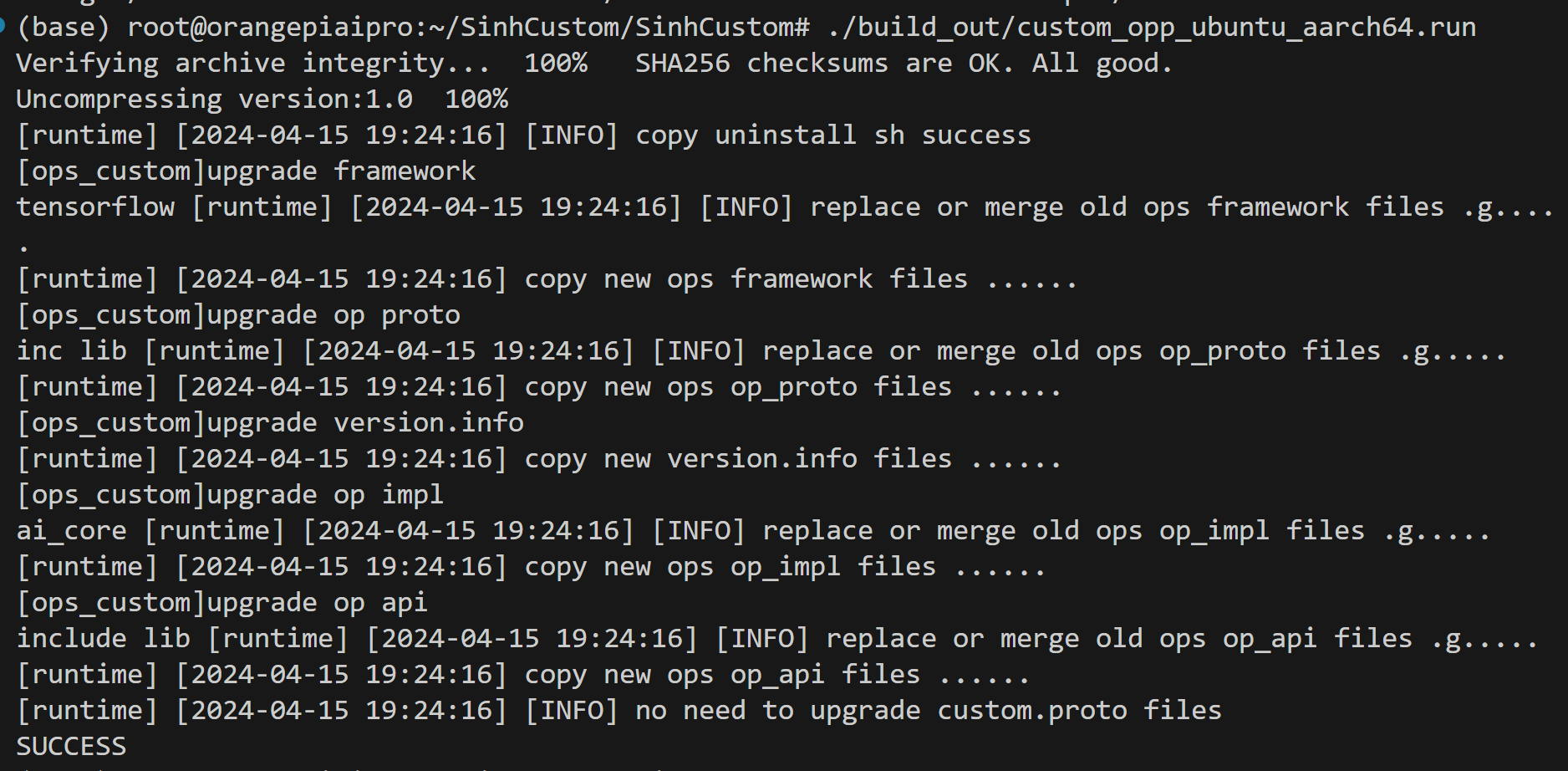
6.3 构建成功后,请在算子工程目录下执行如下命令将构建成功的算子包安装到环境中(实际run包文件名视编译结果而定,请自行甄别):
cd build_out./custom_opp_ubuntu_aarch64.run当命令行显示如下信息证明安装成功:
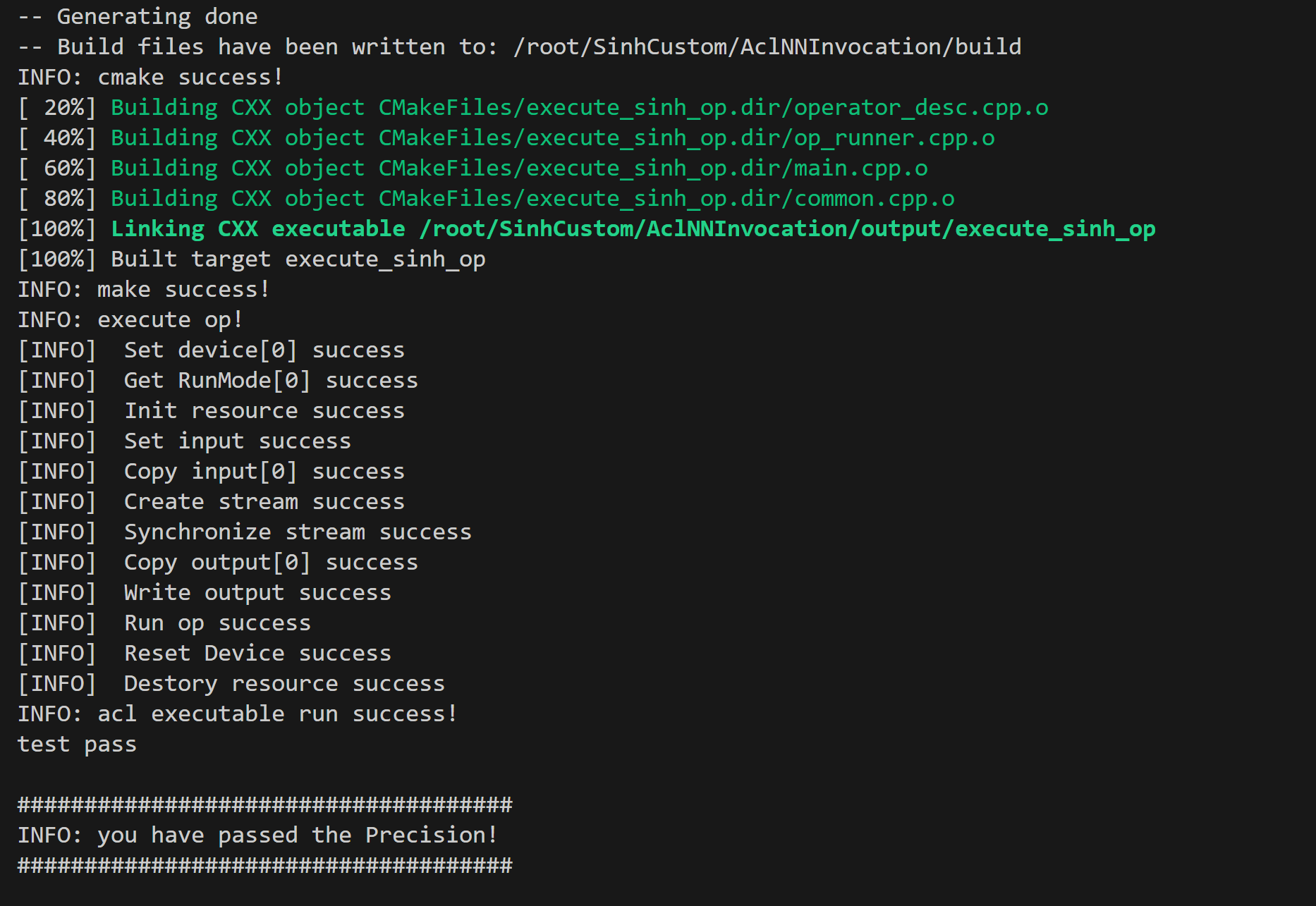
6.4 提供的考题代码工程中,AclNNInvocation目录为Aclnn单算子API调用方式调用算子的测试工程目录,请在上述操作成功完成后进入本目录并执行入下命令:
bash run.sh测试工程中的其它文件请勿修改。测试通过后最终屏显:
提交要求:完成编程后,将上述实现的工程代码(SinhCustom和AclNNInvocation两个目录)打包在zip包内提交,如SinhCustom.zip。
四、遇到错误
如果第一步就出现构建失败的提醒,说明可能是算子开发环境搭建出现问题,可以根据文档:Atlas 200I DK A2算子开发环境搭建指导-Ascendc中级认证专用.docx
重新构建一下环境,从:五、更新CANN toolkit开发包,开始进行,完成之后的全部步骤之后就可以了!
三、昇腾AI技术创新与应用实践
华为昇腾AI基础软硬件平台为开发者提供了强大的算力支持和丰富的开发工具。在CANN训练营的学习过程中,我深刻感受到了昇腾平台在算子开发、模型开发以及应用开发等方面的强大能力。
- 算子开发:通过CANN提供的API和工具,我能够轻松实现算子的开发和优化,提高了算法的执行效率和精度。
- 模型开发:借助昇腾AI框架(如MindSpore)的支持,我能够快速构建和训练深度学习模型,并进行模型的优化和部署。
- 应用开发:基于昇腾软硬件平台,我能够开发出各种行业应用解决方案,如智慧城市、金融风控、智能制造等,为实际业务场景提供智能化的解决方案。
小北的一些小经验:
认证考试需要38元报名费,但是考前领取认证优惠券可以免费认证。优惠券数量有限,先到先得。如果没领到,可以等下个周一,会补充新优惠券。
建议在认证前把题目完成,然后再开始考试。这样直接上传代码更简单。
考试有10次答题机会,机会比较多。如果想看考试系统是什么样子,直接点进去浪费一次机会也是可以的。
考前或考后进行实名认证都可以,如果是考后实名认证,要在考试后10天内认证。不进行实名认证,是没有证书的。
阅卷是人工的,所以工作日才会有老师阅卷。阅卷后,如果考试成绩通过,第二天才会有证书。个人中心可能显示【未通过】,是系统问题,不用担心。等到第二天就好了。
如何准备考试
考试要求实现一个sinh算子,本身不是很难,但是需要对Ascend算子开发有基础了解。建议先学习官网文档。
很多同学反应官方文档内容太多,不知道看哪一部分。让我给大家推荐跟考试直接相关的。
所以,大家直接看下面这个链接吧
基于自定义算子工程的算子开发考试中提供了代码原始工程,大家只需要根据原始工程中的注释完成关键代码补充即可。
主要完成的部分包括op_host和op_kernel两部分。而我上面给出的链接,就重点介绍了这两部分的功能和部分代码。
基于自定义算子工程的算子开发-快速入门-Ascend C算子开发-算子开发-开发指南-CANN商用版8.0.RC2.2开发文档-昇腾社区 (hiascend.com)![]() https://www.hiascend.com/document/detail/zh/canncommercial/80RC22/developmentguide/opdevg/Ascendcopdevg/atlas_ascendc_10_0006.html
https://www.hiascend.com/document/detail/zh/canncommercial/80RC22/developmentguide/opdevg/Ascendcopdevg/atlas_ascendc_10_0006.html
小北的学习笔记:
目标:
编写代码,在香橙派上实现Sinh运算,在SinhCustom目录下编写kernel侧代码和host侧代码,完成调用测试,考取中级微认证证书。
开发流程:
算子分析:分析算子的数学表达式、输入、输出以及计算逻辑的实现,明确需要调用的Ascend C接口。
核函数定义:定义Ascend C算子入口函数。
根据矢量变成范式实现算子类:完成核函数的内部实现。
其中:
CopyIn:将Global Memory上的输入Tensor搬运到Local Memory中。
Compute:执行计算,结果存储在Local Memory中。
CopyOut:将输出数据搬运至Global Memory上的输出Tensor中。
Sinh计算方法:
sinh(x)=(exp(x)–exp(–x))*0.5值得注意的是,不需要另外定义临时变量,计算方法如下:
y <- exp(x)
x <- -x
x <- exp(x)
y <- y-x
y <- y*0.5
代码编写
修改SinhCustom目录下,op_kernel中的一个cpp,op_host中的两个cpp。在op_host目录下的头文件中完成titling结构体定义。
在op_host目录下的cpp文件中完成titling结构体的初始化。
在op_kernel目录下的cpp文件中完成Sinh算子的实现,具体参考Add算子实现与上述计算实现方法。
编译与安装完成后,进入~/SinhCustom/AclNNInvocation目录,执行bash run.sh出现以下内容表示测试通过。
实验感想:
首先感谢华为为我们提供了这样一个实践平台。
由于我本身是做数据库的,AI中的算子概念与数据库的算子概念有许多相似之处,理解起来并不困难。因为接触比较少,操作系统中核函数等概念让我十分新奇,经过阅读文档和老师的讲解,我对计算机底层的知识有了一些初步的了解。





四、未来展望
随着AI技术的不断发展,我相信华为昇腾平台将在更多领域发挥重要作用。作为大数据和AI领域的从业者,我将继续关注昇腾平台的最新动态和技术进展,积极参与相关的学习和交流活动,不断提升自己的技术水平和创新能力。
同时,我也希望通过我的技术博客,能够为大家带来更多的技术分享和实践经验。如果你也喜欢我的文章,请点个关注吧!让我们一起在大数据和AI的道路上不断探索和前行!
以上就是小北本次的技术博客内容,希望能够为友友们提供一些有价值的信息和启示,如果友友们有任何疑问或建议,欢迎在评论区留言与小北交流~感谢友友们的阅读和支持!




