- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
一、SGAN理论基础
1.SCAN概述
SGAN(Spectral Generative Adversarial Networks)是一种生成对抗网络(GAN)的变体,它在训练过程中引入了谱正则化(spectral normalization)技术。GAN是一种深度学习模型,由生成器(Generator)和判别器(Discriminator)组成,它们通过相互对抗的方式训练,生成器试图生成逼真的样本,而判别器试图区分真实样本和生成样本。
在传统的GAN中,生成器和判别器的训练过程可能会遇到梯度消失或梯度爆炸的问题,导致训练不稳定。为了解决这个问题,SGAN通过谱正则化技术对判别器的权重进行约束,使判别器的谱范数(spectral norm)不超过一个预定义的常数,从而保证训练过程的稳定性。
SGAN的架构如下:
1. 生成器(Generator):生成器的作用是接收一个随机噪声向量,通过一系列的卷积层和激活函数生成逼真的样本。生成器的输入是一个随机噪声向量,输出是一个与真实数据具有相同形状的样本。
2. 判别器(Discriminator):判别器的作用是接收一个样本,判断它是真实样本还是生成样本。判别器的输入是一个样本,输出是一个标量,表示样本的真实性。在SGAN中,判别器的权重通过谱正则化技术进行约束,以保证训练过程的稳定性。
3. 谱正则化(Spectral Normalization):谱正则化是一种权重正则化技术,它通过对判别器的权重进行约束,使判别器的谱范数不超过一个预定义的常数。谱范数是一个矩阵的奇异值的最大值,它可以衡量矩阵的最大放大能力。通过限制谱范数,可以防止判别器在训练过程中变得过于强大,从而导致生成器无法生成逼真的样本。
在训练过程中,生成器和判别器交替进行训练。生成器尝试生成逼真的样本,而判别器尝试区分真实样本和生成样本。通过多次迭代训练,生成器和判别器的性能逐渐提高,最终生成器可以生成逼真的样本,判别器可以准确地区分真实样本和生成样本。
2.谱正则化
谱正则化(SpectralNormalization)是一种用于提高生成对抗网络(GAN)训练稳定性的技术。在GAN中,生成器(Generator)和判别器(Discriminator)相互对抗,生成器试图生成逼真的样本,而判别器试图区分真实样本和生成样本。然而,GAN的训练过程往往是不稳定的,其中一个原因是判别器可能变得过于强大,导致生成器的梯度消失,使得生成器无法有效地学习如何生成逼真的样本。
谱正则化的主要思想是对判别器的权重进行约束,以限制其 Lipschitz 常数。Lipschitz
常数是一个度量函数平滑度的指标,如果一个函数的Lipschitz常数为 L,那么对于任意的输入 x 和 x’,都有: ||f(x) -
f(x’)|| / ||x - x’|| ≤ L 这意味着函数的输出变化不会超过输入变化的 L 倍,这有助于防止梯度消失或爆炸问题。
在谱正则化中,通过对判别器的权重矩阵进行修改,使其满足谱范数(spectral
norm)小于或等于一个预定义的常数。谱范数是矩阵的奇异值的最大值,它衡量了矩阵能够放大的最大程度。通过限制谱范数,可以确保判别器的梯度不会过大,从而避免了训练过程中的不稳定问题。谱正则化的具体实现通常涉及以下步骤:
- 对于判别器的每个权重矩阵 W,计算其谱范数 σ(W),即 W 的奇异值的最大值。
- 将权重矩阵 W 替换为归一化后的矩阵 W:/σ(W)。这样,新的权重矩阵的谱范数将被限制为 1,从而保证了 Lipschitz.常数的上限。
- 在每次梯度更新后,重新计算权重矩阵的谱范数,并对其进行归一化。 通过这种方式,谱正则化有效地限制了判别器的梯度,提高了GAN训练的稳定性。这使得生成器能够接收到更有用的梯度信息,从而更有效地学习如何生成逼真的样本.
3.SGAN和GAN的对比
SCAN的优点:
提高了卷积神经网络的泛化能力和稳定性。 可以直接应用于传统的监督学习任务,如图像分类和物体检测。
SCAN的缺点:
相对于其他正则化技术,谱正则化可能会增加计算成本。 主要关注于卷积神经网络的性能改进,而不是数据生成。
GAN的优点:
能够生成逼真的图像和数据,适用于需要模拟数据的场景。 具有很高的灵活性,可以通过修改架构和损失函数来适应不同的应用。 可以用于无监督学习和半监督学习任务。
GAN的缺点:
训练过程不稳定,容易出现模式崩溃(Mode Collapse)等问题。 需要大量的数据和计算资源进行训练。 调整和优化GAN模型需要丰富的经验和实验。
二、代码选段讲解
和G6周相比,前面导入库和参数定义几乎无差异,此处先略过。
1.权重初始化函数
def weights_init_normal(m):classname = m.__class__.__name__if classname.find("Conv") != -1:torch.nn.init.normal_(m.weight.data, 0.0, 0.02)elif classname.find("BatchNorm") != -1:torch.nn.init.normal_(m.weight.data, 1.0, 0.02)torch.nn.init.constant_(m.bias.data, 0.0)这段代码是一个自定义的权重初始化函数,用于在PyTorch神经网络模型中初始化卷积层(Conv)和批量归一化层(BatchNorm)的权重和偏置。这个函数的目的是为模型中的每一层提供一个良好的初始值,这有助于模型的训练过程。
def weights_init_normal(m):
定义了一个名为weights_init_normal的函数,它接受一个参数m,代表模型的某个模块(层)。
classname = m.__class__.__name__
获取m的类名,并将其存储在变量classname中。这个类名可以帮助我们确定m是卷积层还是批量归一化层。
if classname.find("Conv") != -1:
检查classname中是否包含字符串"Conv"。如果包含,说明m是一个卷积层。
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
如果m是卷积层,使用torch.nn.init.normal_函数将m的权重(m.weight.data)初始化为均值为0.0,标准差为0.02的正态分布。
elif classname.find("BatchNorm") != -1:
检查classname中是否包含字符串"BatchNorm"。如果包含,说明m是一个批量归一化层。
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
如果m是批量归一化层,将其权重(m.weight.data)初始化为均值为1.0,标准差为0.02的正态分布。在批量归一化中,权重通常初始化为接近1的值,因为批量归一化的目的是保持数据的归一化状态,而权重用于缩放和偏移。
torch.nn.init.constant_(m.bias.data, 0.0)
将批量归一化层的偏置(m.bias.data)初始化为0.0。在批量归一化中,偏置通常初始化为0,因为层的目的是保持数据的归一化状态,而偏置会影响数据的均值。
总结来说,这个函数通过检查层的类型来决定如何初始化权重和偏置。对于卷积层,权重从均值为0的正态分布中初始化,而对于批量归一化层,权重从均值为1的正态分布中初始化,并且偏置初始化为0。这种初始化策略有助于模型在训练开始时有一个合理的起点,从而有助于模型的收敛和性能。
2.生成器模型类
class Generator(nn.Module):def __init__(self):super(Generator, self).__init__()self.label_emb = nn.Embedding(opt.num_classes, opt.latent_dim)self.init_size = opt.img_size // 4 self.l1 = nn.Sequential(nn.Linear(opt.latent_dim, 128 * self.init_size ** 2))self.conv_blocks = nn.Sequential(nn.BatchNorm2d(128),nn.Upsample(scale_factor=2),nn.Conv2d(128, 128, 3, stride=1, padding=1),nn.BatchNorm2d(128, 0.8),nn.LeakyReLU(0.2, inplace=True),nn.Upsample(scale_factor=2),nn.Conv2d(128, 64, 3, stride=1, padding=1),nn.BatchNorm2d(64, 0.8),nn.LeakyReLU(0.2, inplace=True),nn.Conv2d(64, opt.channels, 3, stride=1, padding=1),nn.Tanh(),)
这段代码定义了一个生成器模型(Generator)的类,该类是PyTorch中的nn.Module的子类。这个生成器模型用于生成与特定标签相关的图像,通常用于条件生成对抗网络(Conditional GANs)中。下面是逐行解释:
class Generator(nn.Module):
定义一个名为Generator的类,它继承自nn.Module,这是一个标准的PyTorch神经网络模块。
def __init__(self):
定义Generator类的构造函数__init__。
super(Generator, self).__init__()
调用父类nn.Module的构造函数,这是PyTorch中初始化模块的标准做法。
self.label_emb = nn.Embedding(opt.num_classes, opt.latent_dim)
创建一个嵌入层(embedding layer),用于将标签转换为与潜在空间(latent space)维度大小相同的向量。opt.num_classes指定了可能的类别数量,opt.latent_dim是潜在空间的维度。
self.init_size = opt.img_size // 4
计算初始图像尺寸,它是目标图像尺寸(opt.img_size)的四分之一。这个值用于后续的线性层和上采样操作。
self.l1 = nn.Sequential(nn.Linear(opt.latent_dim, 128 * self.init_size ** 2))
创建一个序列模块(nn.Sequential),其中包含一个线性层(nn.Linear),它将潜在空间向量(与标签嵌入向量拼接后)映射到一个较大的特征空间,大小为128 * self.init_size ** 2。这是生成器网络的第一个全连接层。
self.conv_blocks = nn.Sequential(
创建一个序列模块,包含一系列卷积层和批量归一化层,用于构建生成器的卷积块。
nn.BatchNorm2d(128),
应用批量归一化(Batch Normalization)到128个通道上,这有助于稳定训练过程。
nn.Upsample(scale_factor=2),
使用上采样(Upsampling)操作将特征图的大小加倍。
nn.Conv2d(128, 128, 3, stride=1, padding=1),
应用一个3x3的卷积层,将128个通道保持不变。
nn.BatchNorm2d(128, 0.8),
再次应用批量归一化,并设置一个小于1的参数(例如0.8),这是批量归一化的一个可选参数,用于提高模型的泛化能力。
nn.LeakyReLU(0.2, inplace=True),
应用LeakyReLU激活函数,并将计算结果直接存储在输入张量中(inplace=True),以节省内存。
nn.Upsample(scale_factor=2),
再次使用上采样操作将特征图的大小加倍。
nn.Conv2d(128, 64, 3, stride=1, padding=1),
应用一个3x3的卷积层,将128个通道减少到64个通道。
nn.BatchNorm2d(64, 0.8),
对64个通道应用批量归一化。
nn.LeakyReLU(0.2, inplace=True),
应用LeakyReLU激活函数。
nn.Conv2d(64, opt.channels, 3, stride=1, padding=1),
应用一个3x3的卷积层,将64个通道转换为与目标图像相同的通道数(例如3,对于RGB图像)。
nn.Tanh(),)
应用Tanh激活函数,这是生成器输出的最后一步,将特征图的值缩放到[-1, 1]的范围内,这是生成图像的常见做法。
总结来说,这个生成器模型首先将潜在空间向量和一个标签嵌入向量通过全连接层映射到一个较大的特征空间,然后通过一系列卷积层、批量归一化和激活函数逐步将特征空间转换为目标图像的尺寸和通道数。最后,Tanh函数确保输出图像的像素值在合适的范围内。
3.定义判别器类
class Discriminator(nn.Module):def __init__(self):super(Discriminator, self).__init__()def discriminator_block(in_filters, out_filters, bn=True):"""Returns layers of each discriminator block"""block = [nn.Conv2d(in_filters, out_filters, 3, 2, 1), nn.LeakyReLU(0.2, inplace=True), nn.Dropout2d(0.25)]if bn:block.append(nn.BatchNorm2d(out_filters, 0.8))return blockself.conv_blocks = nn.Sequential(*discriminator_block(opt.channels, 16, bn=False),*discriminator_block(16, 32),*discriminator_block(32, 64),*discriminator_block(64, 128),)# The height and width of downsampled imageds_size = opt.img_size // 2 ** 4# Output layersself.adv_layer = nn.Sequential(nn.Linear(128 * ds_size ** 2, 1), nn.Sigmoid())self.aux_layer = nn.Sequential(nn.Linear(128 * ds_size ** 2, opt.num_classes + 1), nn.Softmax())def forward(self, img):out = self.conv_blocks(img)out = out.view(out.shape[0], -1)validity = self.adv_layer(out)label = self.aux_layer(out)return validity, label
这段代码定义了一个判别器模型(Discriminator)的类,该类是PyTorch中的nn.Module的子类。这个判别器模型用于判断输入图像的真实性以及其所属的类别,通常用于条件生成对抗网络(Conditional GANs)中。
class Discriminator(nn.Module):
定义一个名为Discriminator的类,它继承自nn.Module,这是一个标准的PyTorch神经网络模块。
def __init__(self):
定义Discriminator类的构造函数__init__。
super(Discriminator, self).__init__()
调用父类nn.Module的构造函数,这是PyTorch中初始化模块的标准做法。
def discriminator_block(in_filters, out_filters, bn=True):
定义一个内部函数discriminator_block,用于创建判别器的卷积块。这个函数接受输入通道数in_filters,输出通道数out_filters,以及一个布尔值bn,指示是否应用批量归一化。
"""Returns layers of each discriminator block"""block = [nn.Conv2d(in_filters, out_filters, 3, 2, 1), nn.LeakyReLU(0.2, inplace=True), nn.Dropout2d(0.25)]
定义一个卷积块,包括一个3x3的卷积层(nn.Conv2d),步长为2,用于下采样图像;一个LeakyReLU激活函数(nn.LeakyReLU),以及一个Dropout层(nn.Dropout2d),用于防止过拟合。
if bn:block.append(nn.BatchNorm2d(out_filters, 0.8))
如果bn为True,则在卷积块中添加一个批量归一化层(nn.BatchNorm2d)。
return block
返回构建好的卷积块。
self.conv_blocks = nn.Sequential(*discriminator_block(opt.channels, 16, bn=False),*discriminator_block(16, 32),*discriminator_block(32, 64),*discriminator_block(64, 128),)
创建一个序列模块(nn.Sequential),包含一系列判别器的卷积块。这些块逐渐增加通道数,同时减小图像尺寸。
# The height and width of downsampled imageds_size = opt.img_size // 2 ** 4
计算下采样后图像的尺寸,它是原始图像尺寸(opt.img_size)除以2的4次方。
# Output layersself.adv_layer = nn.Sequential(nn.Linear(128 * ds_size ** 2, 1), nn.Sigmoid())
创建一个序列模块,包含一个全连接层(nn.Linear),用于将卷积层的输出转换为单个值,表示图像的真实性;以及一个Sigmoid激活函数,将输出压缩到[0, 1]范围内。
self.aux_layer = nn.Sequential(nn.Linear(128 * ds_size ** 2, opt.num_classes + 1), nn.Softmax())
创建另一个序列模块,包含一个全连接层,用于将卷积层的输出转换为类别预测;以及一个Softmax激活函数,用于生成类别的概率分布。
def forward(self, img):
定义判别器的前向传播函数forward,它接受一个图像img作为输入。
out = self.conv_blocks(img)
将输入图像img通过卷积块self.conv_blocks,得到特征图out。
out = out.view(out.shape[0], -1)
将特征图out展平为一个二维张量,其中第一维是批量大小,第二维是特征维度。
validity = self.adv_layer(out)
通过全连接层self.adv_layer计算图像的真实性分数validity。
label = self.aux_layer(out)
通过全连接层self.aux_layer计算图像的类别预测label。
return validity, label
返回图像的真实性分数validity和类别预测label。
4.训练模型
for epoch in range(opt.n_epochs):for i, (imgs, labels) in enumerate(dataloader):batch_size = imgs.shape[0]# Adversarial ground truthsvalid = Variable(FloatTensor(batch_size, 1).fill_(1.0), requires_grad=False)fake = Variable(FloatTensor(batch_size, 1).fill_(0.0), requires_grad=False)fake_aux_gt = Variable(LongTensor(batch_size).fill_(opt.num_classes), requires_grad=False)# Configure inputreal_imgs = Variable(imgs.type(FloatTensor))labels = Variable(labels.type(LongTensor))optimizer_G.zero_grad()# Sample noise and labels as generator inputz = Variable(FloatTensor(np.random.normal(0, 1, (batch_size, opt.latent_dim))))# Generate a batch of imagesgen_imgs = generator(z)# Loss measures generator's ability to fool the discriminatorvalidity, _ = discriminator(gen_imgs)g_loss = adversarial_loss(validity, valid)g_loss.backward()optimizer_G.step()optimizer_D.zero_grad()# Loss for real imagesreal_pred, real_aux = discriminator(real_imgs)d_real_loss = (adversarial_loss(real_pred, valid) + auxiliary_loss(real_aux, labels)) / 2# Loss for fake imagesfake_pred, fake_aux = discriminator(gen_imgs.detach())d_fake_loss = (adversarial_loss(fake_pred, fake) + auxiliary_loss(fake_aux, fake_aux_gt)) / 2# Total discriminator lossd_loss = (d_real_loss + d_fake_loss) / 2# Calculate discriminator accuracypred = np.concatenate([real_aux.data.cpu().numpy(), fake_aux.data.cpu().numpy()], axis=0)gt = np.concatenate([labels.data.cpu().numpy(), fake_aux_gt.data.cpu().numpy()], axis=0)d_acc = np.mean(np.argmax(pred, axis=1) == gt)d_loss.backward()optimizer_D.step()batches_done = epoch * len(dataloader) + iif batches_done % opt.sample_interval == 0:save_image(gen_imgs.data[:25], "images/%d.png" % batches_done, nrow=5, normalize=True)print("[Epoch %d/%d] [Batch %d/%d] [D loss: %f, acc: %d%%] [G loss: %f]"% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), 100 * d_acc, g_loss.item()))这段代码是一个循环,用于训练生成对抗网络(GAN)。在这个循环中,生成器(Generator)和判别器(Discriminator)交替训练,每个周期包含多个批次。
for epoch in range(opt.n_epochs):
遍历指定的训练周期数opt.n_epochs。每个周期包含多个批次。
for i, (imgs, labels) in enumerate(dataloader):
遍历数据加载器dataloader中的每个批次。dataloader是一个迭代器,它返回批次中的图像imgs和对应的标签labels。enumerate函数返回当前批次索引i和批次内容(imgs, labels)。
batch_size = imgs.shape[0]
计算当前批次的图像数量,即批次大小。
valid = Variable(FloatTensor(batch_size, 1).fill_(1.0), requires_grad=False)fake = Variable(FloatTensor(batch_size, 1).fill_(0.0), requires_grad=False)fake_aux_gt = Variable(LongTensor(batch_size).fill_(opt.num_classes), requires_grad=False)
创建一些变量,用于表示真实和虚假图像的判别器输入。valid和fake用于判别器中的对抗损失,而fake_aux_gt用于判别器中的辅助损失。
real_imgs = Variable(imgs.type(FloatTensor))labels = Variable(labels.type(LongTensor))
将输入的图像imgs和标签labels转换为适合网络输入的PyTorch张量,并配置为判别器和生成器的输入。
optimizer_G.zero_grad()
清空生成器的优化器梯度。
z = Variable(FloatTensor(np.random.normal(0, 1, (batch_size, opt.latent_dim))))
从高斯分布中采样噪声z,作为生成器的输入。
gen_imgs = generator(z)
使用生成器模型generator生成一批新的图像。
validity, _ = discriminator(gen_imgs)g_loss = adversarial_loss(validity, valid)
计算生成器的损失,该损失衡量生成器生成图像的能力。adversarial_loss是一个对抗损失函数,用于评估生成器生成的图像与真实图像的差异。
g_loss.backward()optimizer_G.step()
计算生成器损失的梯度,并更新生成器的权重。
optimizer_D.zero_grad()
清空判别器的优化器梯度。
real_pred, real_aux = discriminator(real_imgs)d_real_loss = (adversarial_loss(real_pred, valid) + auxiliary_loss(real_aux, labels)) / 2
计算判别器在真实图像上的损失。adversarial_loss用于对抗损失,而auxiliary_loss用于辅助损失,后者用于判断图像的真实类别。
fake_pred, fake_aux = discriminator(gen_imgs.detach())d_fake_loss = (adversarial_loss(fake_pred, fake) + auxiliary_loss(fake_aux, fake_aux_gt)) / 2
计算判别器在生成图像上的损失。detach()函数用于从计算图中分离生成图像,使其不会影响判别器的梯度计算。
d_loss = (d_real_loss + d_fake_loss) / 2
计算判别器的总损失,它是真实和生成图像损失的平均值。
pred = np.concatenate([real_aux.data.cpu().numpy(), fake_aux.data.cpu().numpy()], axis=0)
将判别器在真实图像和生成图像上的辅助输出(real_aux和fake_aux)合并成一个数组,并将其从PyTorch张量转换为NumPy数组。
gt = np.concatenate([labels.data.cpu().numpy(), fake_aux_gt.data.cpu().numpy()], axis=0)
将真实图像的标签(labels)和生成图像的辅助标签(fake_aux_gt)合并成一个数组,并将其从PyTorch张量转换为NumPy数组。
d_acc = np.mean(np.argmax(pred, axis=1) == gt)
计算判别器的准确率,即判别器在辅助任务(即分类任务)上的性能。这通过比较判别器的预测(pred)和真实标签(gt)来完成。
d_loss.backward()optimizer_D.step()
计算判别器损失的梯度,并使用梯度下降法更新判别器的权重。
batches_done = epoch * len(dataloader) + iif batches_done % opt.sample_interval == 0:save_image(gen_imgs.data[:25], "images/%d.png" % batches_done, nrow=5, normalize=True)
计算已经完成的批次数量,并检查是否达到了保存生成图像的间隔。如果满足条件,则保存生成器生成的前25个图像。save_image函数用于保存图像,nrow参数用于设置图像的行数,normalize参数用于将图像的像素值缩放到[0, 1]范围内。
三、学习过程中遇到的问题及其解决方案
在源代码运行过程中我遇到这样一个报错

这个我在网上搜了很多解决方案但是都不行,其实仔细看他们解释的原因不难发现其实就是一个路径错误导致的权限无效,把前面的递归删掉这样就在当前目录下创建data文件夹(这里我目录下已经有一个data文件夹所以我改成了data1)

使用源代码设置的参数,训练出来的acc老是在百分之五十之间徘徊。简单缩小一下bs,提升了一下lr,效果不是很明显,只是波动变大了。
本来想继续调参的,但是从这个图片可以看出来到第九个epoch时acc上来了,我决定再观察一会会,可能会继续增大,但是我觉得是波动范围变大的可能性也很大。波动范围大应该是lr翻倍的原因。说到这里我又去搜索了一下学习率对训练的影响(当一个知识点模糊的时候,去得到答案比用很久的时间思考要好很多)
在训练模型时,学习率的调整是一个关键的优化参数。学习率控制着梯度下降算法中每次参数更新的步长。学习率的选择直接影响模型的训练速度和最终性能。以下是提升学习率可能带来的影响:
- 训练速度:提升学习率可以加快训练速度,因为模型会在每一步都更新更多参数。
- 过拟合风险:如果学习率过高,模型可能会在训练数据上过拟合,导致在测试数据上的性能下降。
- 收敛速度:过高的学习率可能导致模型无法收敛到最优解,而是
发散到不稳定的解。- 梯度爆炸或消失:在某些情况下,高学习率可能导致梯度爆炸或消失,这会影响模型的训练过程。
- 稳定性:高学习率可能会导致训练过程不稳定,使得模型在不同批次之间的表现不一致。
- 局部最优解:高学习率可能导致模型错过全局最优解,而停留在局部最优解。
- 参数更新:学习率过高时,模型参数的更新可能会变得过大,这可能会破坏模型的结构和稳定性。 因此,提升学习率并不是一个简单的操作,它需要根据具体问题和模型来调整。通常,在训练过程中会采用一种策略来逐渐增加学习率,如学习率衰减(learning
rate decay),或者使用更先进的学习率调整技术,如学习率预热(learning rate warmup)和余弦退火(cosine
annealing)。
总的来说,提升学习率可以加快训练速度,但也可能带来过拟合、收敛不稳定和局部最优解的风险。因此,在调整学习率时,需要仔细考虑模型的特性、数据分布和训练目标,以找到一个平衡点。
不过说到这里我又要去反思一下G6我为了提升训练速度做的工作
- 直接砍epoch(bushi)(开玩笑的哈,拔苗助长的行为不可取,但是上周那个任务作为学习确实没必要训200个epoch)
- 提升学习率和bs: 这里我需要好好说一下,虽然都说这样可以提速,但是我在实践中认为,这样其实没什么用,至少对我这种用卑微的3060单卡训练的小小笔记本来说没用。这两者都是一样的道理,提升bs,相当于吃一个苹果一口咬的更大了,确实需要的总口数就降低了, 但是这样咬一口需要的力气和咀嚼的时间也变长了啊。实际训练中,就是[Batch 0/1875] 一秒的时间内0变到了4。然后batchsize翻倍后变成了[Batch 0/937],但是一秒只能从0变到2了。这有区别么?我个人的直观感受是这样的,要是我说的不对,还请在评论区指正。
四、结果及其可视化
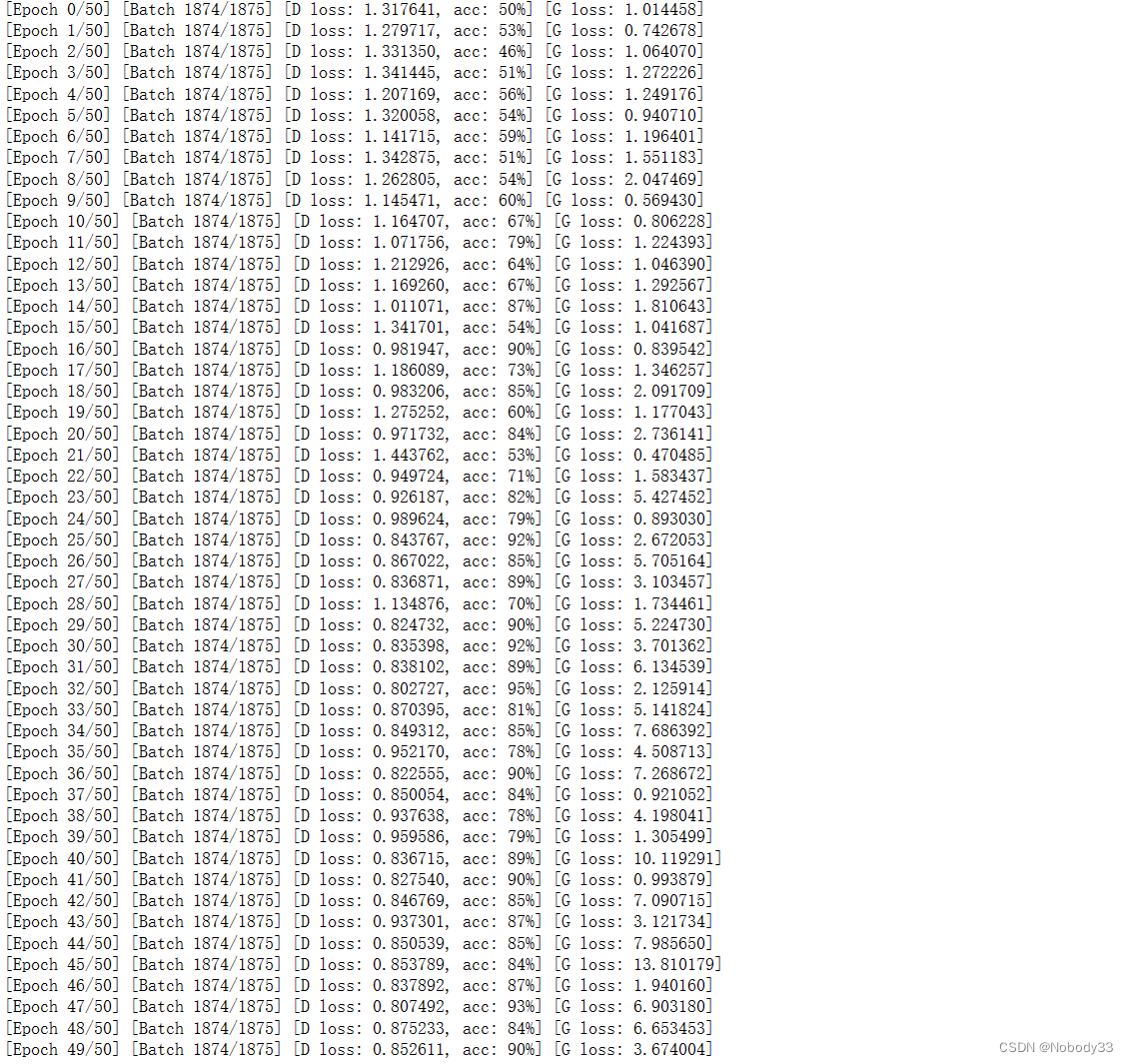



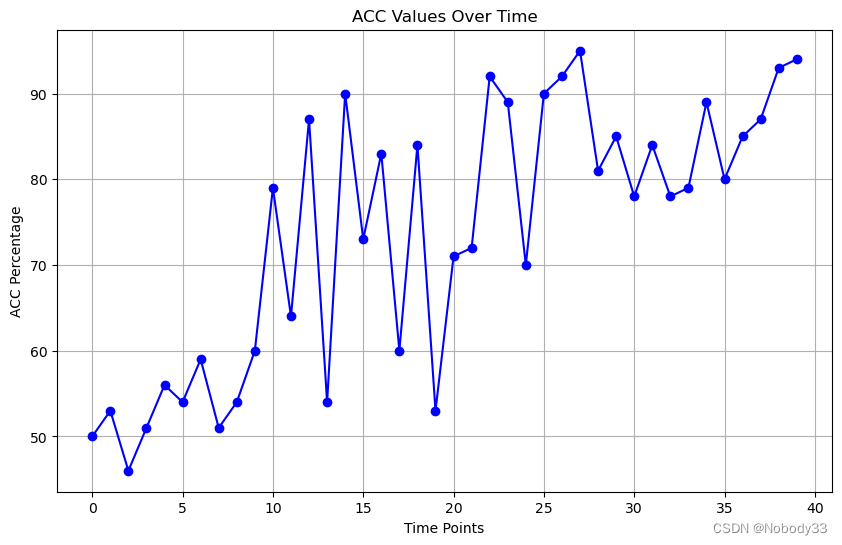
我们已经知道了acc波动变化比较大,但是还好总体呈现上升趋势,并且后面趋于稳定了很多
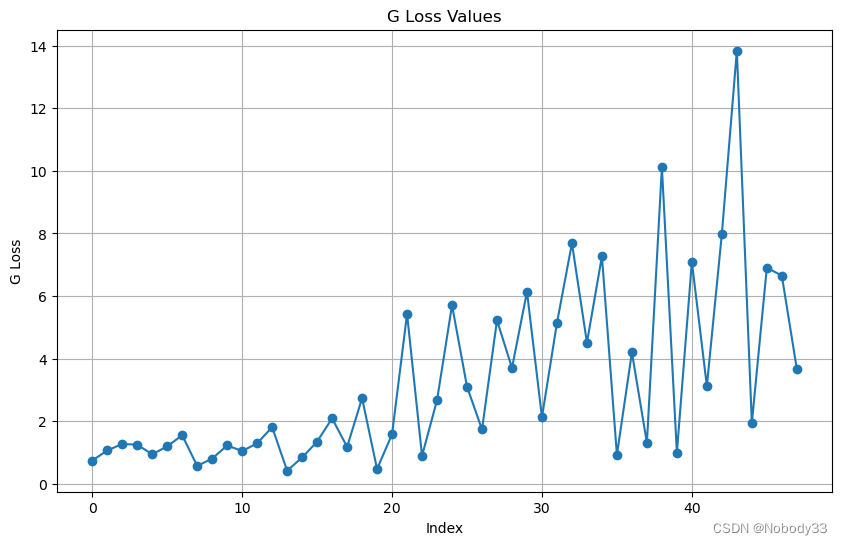
而损失则相反了,这点我还没搞得很懂需要再研究一下。最高值居然达到了14,离散度太高了。